如何使用 Ultralytics YOLO 模型进行训练、验证、预测、导出和基准测试
学习如何使用 Ultralytics YOLO 模型进行训练、验证、预测、导出和基准测试!

让我们深入了解 Ultralytics 的世界,探索不同 YOLO 模型所提供的各种模式。无论你是在训练自定义 object detection 模型,还是在进行 segmentation 工作,了解这些模式都是至关重要的一步。让我们直接开始吧!
通过 Ultralytics documentation,你会发现多种可供你使用的模型 modes,无论是 train、validate、predict、export、benchmark 还是 track。这些模式中的每一种都有其独特的作用,可以帮助你优化模型的性能和部署。
Link to this sectionTrain 模式#
首先,让我们来看看 train 模式。这是你构建和改进模型的地方。你可以在文档中找到详细的说明和 video guides,让你能轻松上手训练自定义模型。
模型训练涉及为模型提供新的数据集,让它学习各种模式。一旦训练完成,该模型就可以在实时环境中使用,以检测它所训练过的新对象。在开始训练过程之前,务必按照 YOLO 格式对数据集进行标注。
Link to this sectionValidate 模式#
接下来,让我们深入探讨 validate 模式。验证对于调整超参数并确保模型表现良好至关重要。Ultralytics 提供了多种验证选项,包括自动化设置、多指标支持以及与 Python API 的兼容性。你甚至可以通过下方的命令直接在命令行界面 (CLI) 中运行验证。
Link to this section为什么要验证?#
验证对于以下方面至关重要:
- Precision:确保你的模型能够准确地检测到对象。
- Convenience:简化验证流程。
- Flexibility:提供多种验证方法。
- Hyperparameter Tuning:优化你的模型以获得更好的性能。
Ultralytics 还提供了一些用户示例,你可以直接复制并粘贴到你的 Python 脚本中。这些示例包含了诸如图像大小、批处理大小、设备 (CPU 或 GPU) 和交并比 (IoU) 等参数。
Link to this sectionPredict 模式#
一旦你的模型经过训练和验证,就该进行预测了。Predict 模式允许你在新数据上运行推理,并直观地看到模型的运行效果。此模式非常适合在真实世界数据上测试模型的性能。通过下方的 Python 代码片段,你将能够对图像运行预测!
Link to this sectionExport 模式#
在验证和预测之后,你可能需要部署你的模型。Export 模式使你能够将模型转换为各种格式,如 ONNX 或 TensorRT,从而更轻松地跨不同平台进行部署。
Link to this sectionBenchmark 模式#
最后,我们有 benchmark 模式。基准测试对于评估模型在各种场景下的表现至关重要。此模式有助于你在资源分配、优化和成本效率方面做出明智的决策。
Link to this section如何进行基准测试#
要运行基准测试,你可以使用文档中提供的用户示例。这些示例涵盖了关键指标和导出格式,包括 ONNX 和 TensorRT。你还可以指定诸如整数定点量化 (INT8) 或浮点量化 (FP16) 等参数,以查看不同设置如何影响性能。
Link to this section真实世界的基准测试示例#
让我们看看一个真实的基准测试示例。当我们对我们的 PyTorch 模型进行基准测试时,我们注意到在 RTX 3070 GPU 上的推理速度为 68 毫秒。在导出为 TorchScript 后,推理速度降至 4 毫秒,表现出显著的提升。
对于 ONNX 模型,我们实现了 21 毫秒的推理速度。在 CPU (Intel i9 第 13 代) 上测试这些模型时,我们看到了不同的结果。TorchScript 的运行速度为 115 毫秒,而 ONNX 的表现更好,为 84 毫秒。最后,针对 Intel 硬件优化的 OpenVINO 达到了惊人的 23 毫秒。
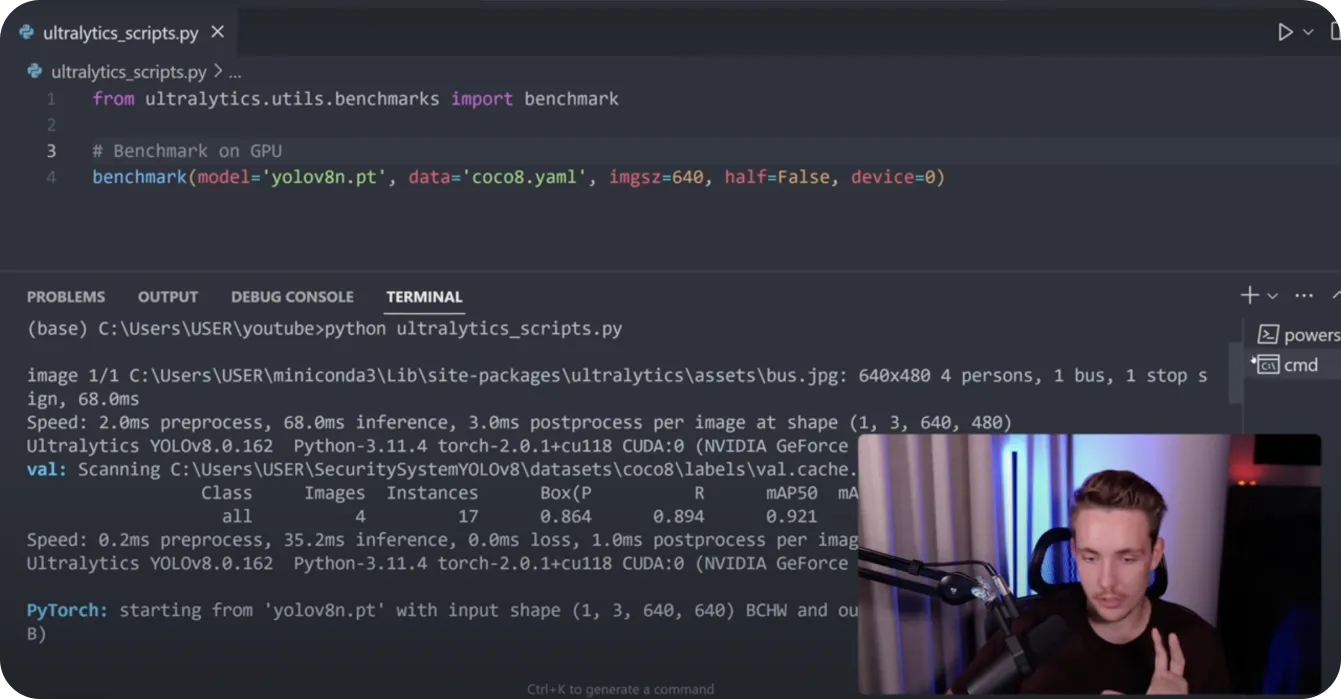
图 1. Nicolai Nielsen 展示如何使用 Ultralytics YOLO 模型运行基准测试。
Link to this section基准测试的重要性#
基准测试展示了不同的硬件和导出格式如何影响模型的性能。对你的模型进行基准测试至关重要,特别是如果你计划将它们部署在自定义硬件或边缘设备上。此过程可确保你的模型针对目标环境进行了优化,从而提供尽可能最好的性能。
Link to this section结论#
总之,Ultralytics 文档中的这些模式是训练、验证、预测、导出和基准测试你的 YOLO 模型的强大工具。每种模式在优化模型并为其部署做好准备的过程中都起着至关重要的作用。
别忘了探索并加入我们的 community,并在你的项目中尝试所提供的代码片段。借助这些工具,你可以创建高性能模型,并确保它们在任何环境中都能高效运行。






