理解少样本、零样本和迁移学习
探索计算机视觉中少样本学习、零样本学习和迁移学习的区别,以及这些范式如何塑造 AI 模型训练。

人工智能(AI)系统只需极少量的人工输入,即可处理复杂的任务,如人脸识别、图像分类和自动驾驶。它们通过研究数据、识别模式并利用这些模式进行预测或决策来实现这一目标。随着AI的发展,我们见证了AI模型在学习、适应和执行任务方面日益精巧且高效的方式。
例如,计算机视觉是AI的一个分支,致力于使机器能够解释和理解来自世界的视觉信息。传统的计算机视觉模型开发在很大程度上依赖大型标注数据集进行训练。收集和标注此类数据可能既耗时又昂贵。
为应对这些挑战,研究人员引入了创新的方法,例如:从有限示例中学习的少样本学习(FSL);识别未见对象的零样本学习(ZSL);以及将预训练模型的知识应用到新任务中的迁移学习(TL)。
在本文中,我们将探讨这些学习范式的工作原理,重点介绍它们的主要区别,并查看其现实应用。让我们开始吧!
Link to this section学习范式概述#
让我们探讨少样本学习、零样本学习和迁移学习在计算机视觉方面的定义及其工作原理。
Link to this section少样本学习#
少样本学习是一种系统通过极少量示例学习识别新对象的方法。例如,如果你向模型展示几张企鹅、鹈鹕和海鹦的照片(这一小群图像被称为“支持集”),它就能学会这些鸟类的样子。
稍后,如果你向模型展示一张新照片(如企鹅),它会将这张新照片与支持集中的照片进行对比,并挑选出最接近的匹配项。当收集大量数据很困难时,这种方法非常有益,因为系统仍然可以仅通过少量示例进行学习和适应。
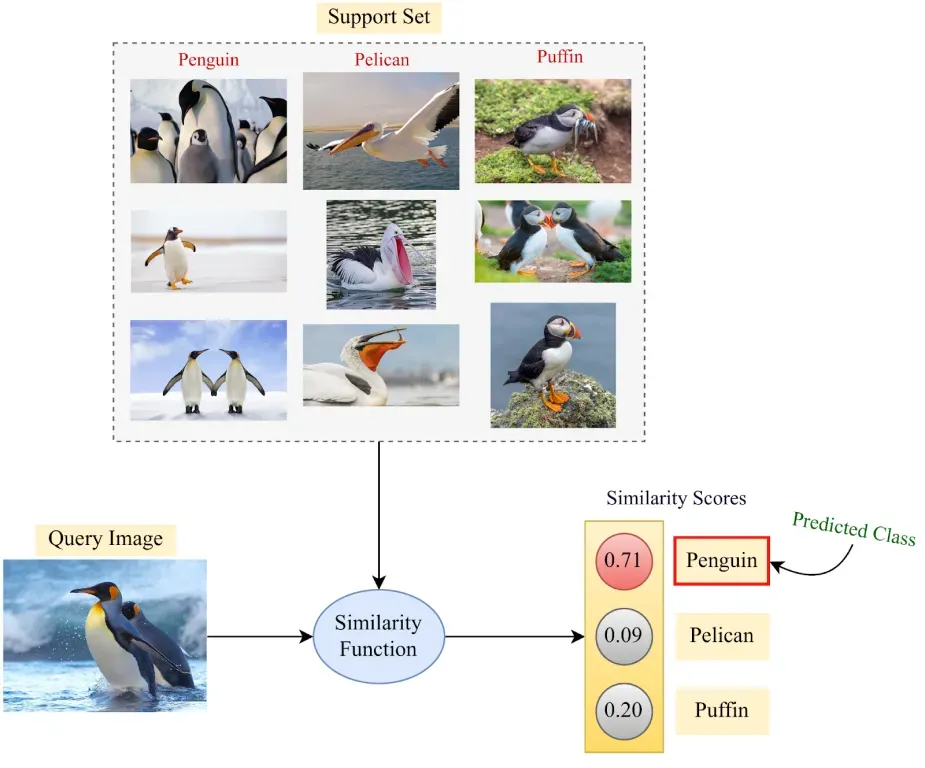
图 1. 少样本学习工作原理概述。
Link to this section零样本学习#
零样本学习是一种让机器在无需示例的情况下识别其从未见过事物的方法。它利用语义信息(如描述)来帮助建立联系。
例如,如果机器通过理解诸如“小而毛茸茸”、“大型野生猫科动物”或“长脸”等特征学会了猫、狮子和马等动物,它就能利用这些知识识别新动物,比如老虎。即使它以前从未见过老虎,也可以通过“一种带有深色条纹的狮子状动物”这样的描述来正确识别它。这使得机器在无需大量示例的情况下,学习和适应变得更加容易。
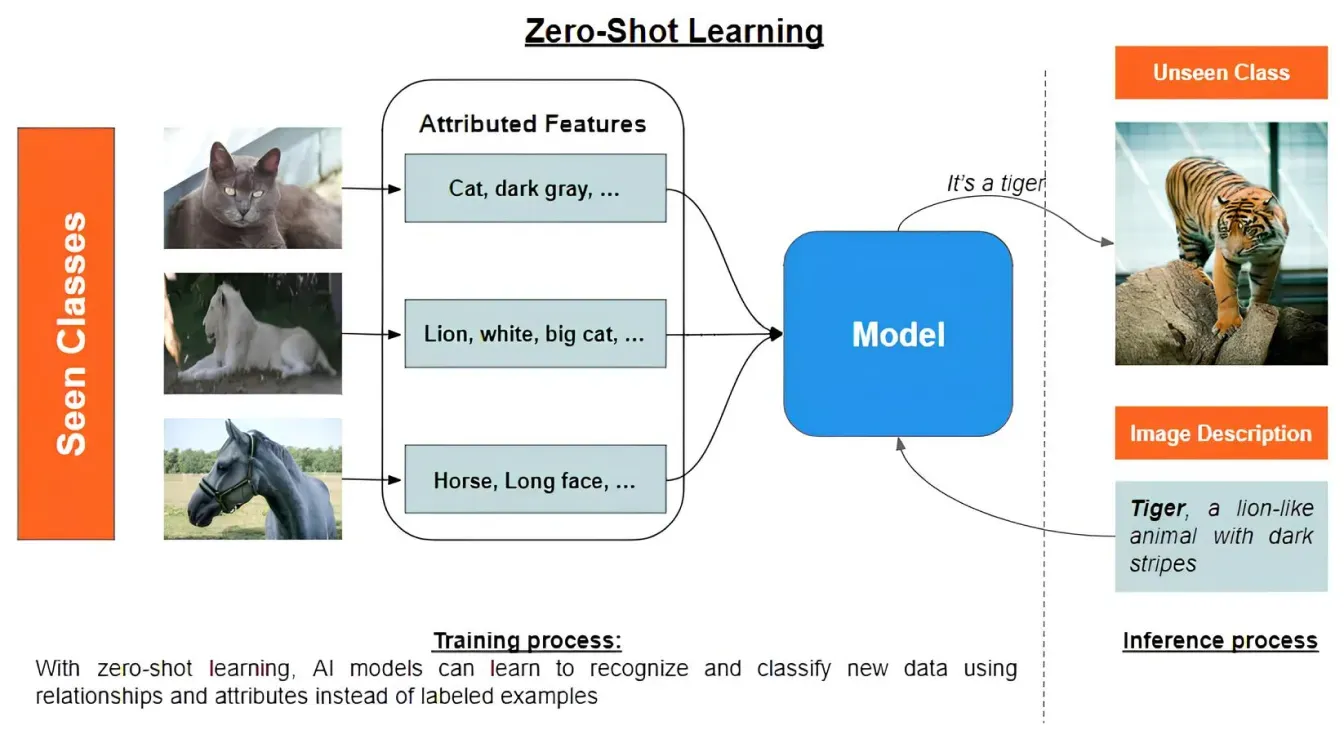
图 2. 零样本学习利用描述识别新对象。
Link to this section迁移学习#
迁移学习是一种学习范式,模型利用从一个任务中学到的知识来帮助解决类似的新任务。这种技术在处理目标检测、图像分类和模式识别等计算机视觉任务时特别有用。
例如,在计算机视觉中,预训练模型可以识别通用对象(如动物),然后通过迁移学习进行微调,以识别特定对象(如不同的犬种)。通过重用早期任务的知识,迁移学习使在较小的数据集上训练计算机视觉模型变得更加容易,从而节省了时间和精力。
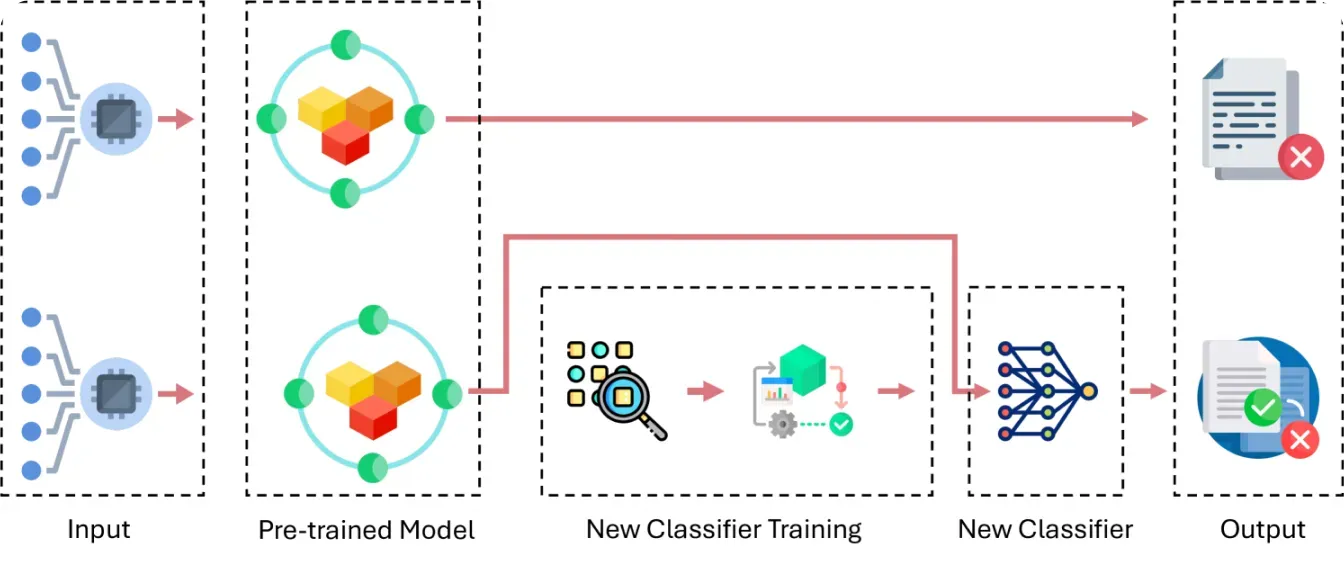
图 3。迁移学习工作原理概述。
你可能想知道哪些模型支持迁移学习。Ultralytics YOLO11就是一个支持此功能的出色计算机视觉模型案例。它是一款最先进的目标检测模型,首先在大规模通用数据集上进行预训练。之后,它可以在较小的专业数据集上进行微调和自定义训练,以完成特定任务。
Link to this section比较学习范式#
既然我们已经谈到了少样本学习、零样本学习和迁移学习,让我们比较一下它们,看看它们有何不同。
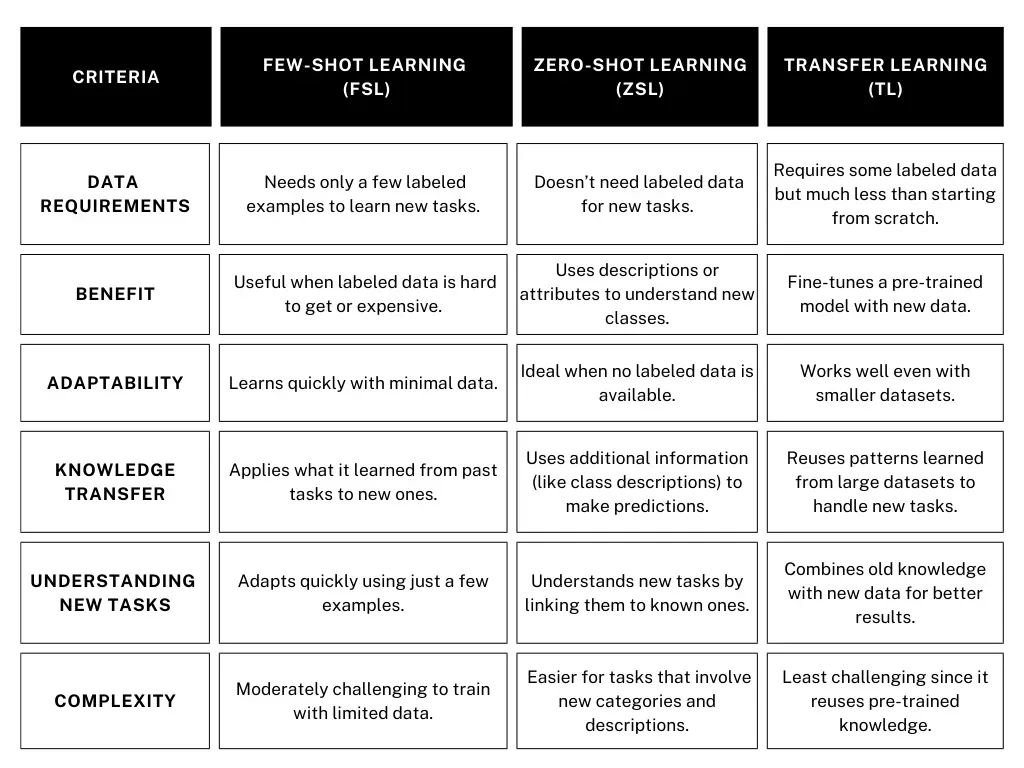
图 4. 少样本、零样本和迁移学习之间的关键区别。图片由作者提供。
当你只有少量标注数据时,少样本学习非常有用。它使AI模型只需几个示例即可进行学习。相比之下,零样本学习不需要任何标注数据。相反,它利用描述或上下文来帮助系统处理新任务。与此同时,迁移学习采取了不同的方法,利用预训练模型的知识,使它们能够以极少的额外数据快速适应新任务。每种方法都有其各自的优势,具体取决于你所处理的数据类型和任务。
Link to this section各种学习范式的现实应用#
这些学习范式已经在许多领域发挥作用,通过创新的解决方案解决复杂问题。让我们更深入地了解它们如何在现实世界中应用。
Link to this section利用少样本学习诊断罕见疾病#
少样本学习是医疗领域的一次变革,特别是在医学影像方面。它可以帮助医生仅使用几个示例甚至描述来诊断罕见疾病,而无需大量数据。这在数据受限时尤其有用,因为收集罕见疾病的大型数据集往往极具挑战性。
例如,SHEPHERD利用少样本学习和生物医学知识图谱来诊断罕见遗传疾病。它将患者信息(如症状和检查结果)映射到已知基因和疾病的网络上。这有助于在数据有限的情况下,精准定位可能的遗传病因并寻找类似病例。
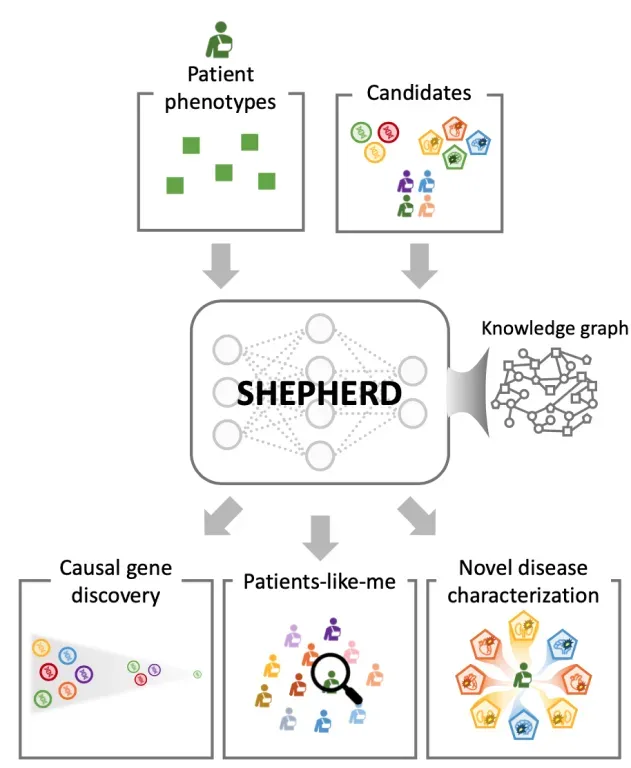
图 5. Shepherd模型利用极少量数据诊断罕见疾病。
Link to this section利用零样本学习改善植物病害检测#
在农业中,快速识别植物病害至关重要,因为检测延迟会导致大面积作物受损、产量下降和严重的经济损失。传统方法通常依赖大数据集和专家知识,而这些在偏远或资源受限地区往往难以获取。这就是零样本学习等AI进步发挥作用的地方。
假设一位农民正在种植番茄和土豆,并注意到叶片发黄或出现褐斑等症状。零样本学习可以在不需要大数据集的情况下帮助识别晚疫病等病害。通过使用症状描述,模型可以分类其以前未见过的疾病。这种方法快速、可扩展,并允许农民检测多种植物问题。它有助于更有效地监测作物健康、采取及时措施并减少损失。

图 6。使用零样本学习识别植物病害。
Link to this section自动驾驶汽车与迁移学习#
自动驾驶汽车通常需要适应不同的环境以安全行驶。迁移学习帮助它们利用先验知识快速调整以适应新条件,而无需从零开始训练。结合有助于车辆解释视觉信息的计算机视觉技术,这些技术使得在不同地形和天气条件下行驶更加顺畅,从而提高了自动驾驶的效率和可靠性。
这方面的一个好例子是使用Ultralytics YOLO11监控停车位的停车管理系统。YOLO11是一款预训练的目标检测模型,可以通过迁移学习进行微调,以实时识别空闲和已占用的停车位。通过在较小的停车场图像数据集上训练模型,它可以准确地检测空位、已停车位,甚至预留区域。

图 7。使用Ultralytics YOLO11进行停车管理。
与其他技术集成后,该系统可以引导驾驶员前往最近的可用车位,有助于减少搜索时间和交通拥堵。迁移学习通过利用YOLO11现有的目标检测能力,使这成为可能,从而允许其在无需从零开始的情况下适应停车管理的特定需求。这种方法既节省了时间和资源,又创建了一个高效且可扩展的解决方案,改善了停车运营并提升了整体用户体验。
Link to this section学习范式的新兴趋势#
计算机视觉中学习范式的未来趋向于开发更智能、更可持续的视觉AI系统。特别是一个不断增长的趋势是使用结合了少样本学习、零样本学习和迁移学习的混合方法。通过融合这些方法的优势,模型可以用极少量数据学习新任务,并将其知识应用到不同领域。
一个有趣的例子是使用自适应深度嵌入来微调模型,利用先前任务的知识和少量新数据,从而更轻松地处理有限的数据集。
同样,X-shot学习旨在处理数据量不同的任务。它利用弱监督(模型从有限或带有噪声的标签中学习)和明确的指令来帮助它们快速适应,即使在几乎没有或完全没有先验示例的情况下也是如此。这些混合方法展示了整合不同的学习方法如何帮助AI系统更有效地解决挑战。
Link to this section关键要点#
少样本学习、零样本学习和迁移学习各自解决了计算机视觉中的特定挑战,使它们适合不同的任务。正确的方法取决于具体应用以及可用数据量的多少。例如,少样本学习在有限数据下表现良好,而零样本学习则非常适合处理未见或不熟悉的类别。
展望未来,将这些方法结合起来创建整合视觉、语言和音频的混合模型,可能会成为一个核心重点。这些进展旨在使AI系统更加灵活、高效,并能够解决复杂问题,为该领域的创新开辟了新可能性。
通过加入我们的社区并查看我们的GitHub仓库,探索更多关于AI的内容。了解自动驾驶汽车中的AI以及农业中的计算机视觉如何重塑未来。查看YOLO许可证的可用选项即可开始!






