Exploring SAM 3: Meta AI’s new Segment Anything Model
Find out how SAM 3, Meta AI’s new Segment Anything Model, makes it easy to detect, segment, and track objects across real-world images and videos.

On November 19, 2025, Meta AI released Segment Anything Model 3, also known as SAM 3. This latest version of the Segment Anything Model introduces new ways to detect, segment, and track objects in real-world images and videos using text prompts, visual prompts, and image examples.
The SAM 3 model builds on SAM and SAM 2 and brings new advancements and features like concept segmentation, open vocabulary detection, and real-time video tracking. It can understand short noun phrases, follow objects across frames, and identify fine-grained or rare concepts that earlier models couldn't handle as consistently.
As part of the SAM 3 release, Meta also introduced SAM 3D. This suite of next-generation models reconstructs objects, scenes, and full human bodies from a single image and expands the Segment Anything ecosystem into 3D understanding. These additions open up new applications across computer vision, robotics, media editing, and creative workflows.
In this article, we will explore what SAM 3 is, what sets it apart from SAM 2, how the model works, and its real-world applications. Let’s get started!
Link to this sectionWhat is SAM 3? A look at Meta’s Segment Anything Model 3#
SAM 3 is a state-of-the-art computer vision model that can identify, separate, and track objects in images and videos based on simple instructions. Instead of relying on a fixed list of labels, SAM 3 understands natural language and visual cues, making it easy to tell the model what you want to find.
For example, with SAM 3, you can type a short phrase like “yellow school bus” or “a striped cat,” click on an object, or highlight an example in an image. The model will then detect every matching object and generate clean segmentation masks (a visual outline that shows exactly which pixels belong to an object). SAM 3 can also follow those objects across video frames, keeping them consistent as they move.
Link to this sectionSAM 3D enables single-image 3D reconstruction#
Another exciting part of Meta AI’s announcement is SAM 3D, which extends the Segment Anything project into 3D understanding. SAM 3D can take a single 2D image and reconstruct the shape, pose, or structure of an object or a human body in three dimensions. In other words, the model can estimate how something occupies space even when only one viewpoint is available.
SAM 3D has been released as two different models: SAM 3D Objects, which reconstructs everyday items with geometry and texture, and SAM 3D Body, which estimates human body shape and pose from a single image. Both models use the segmentation output from SAM 3 and then generate a 3D representation that aligns with the appearance and position of the object in the original photo.

Fig 1. An example of using SAM 3D. (Source: Created using Meta AI’s segment anything playground)
Link to this sectionSAM 3: New features to unify detection, segmentation, and tracking#
Here are some of the key updates SAM 3 introduces to bring detection, segmentation, and tracking together into one unified model:
- Concept segmentation tasks: In SAM and SAM 2, object segmentation depended on visual prompts like clicks or boxes. SAM 3 adds the ability to segment objects based on a short text phrase or an example crop from the image. This means the model can identify all matching instances without requiring a click for each one.
- Open vocabulary text prompts: Unlike previous versions, SAM 3 can interpret short natural language phrases. This removes the need for a fixed label list and makes it possible for the model to work with more specific or less common concepts.
- One model for detection, segmentation, and tracking: SAM 3 unifies detection, segmentation, and tracking into one model, eliminating the need for separate systems to find objects, generate segmentation masks, and follow them across video frames. This creates a more consistent and streamlined workflow for both images and video, and while SAM 2 also offered some tracking capabilities, SAM 3 delivers significantly stronger and more reliable performance.
- More stable results in complex scenes: Since SAM 3 can combine text, example images, and visual prompts, it can handle cluttered or repetitive scenes more reliably than earlier versions that relied only on visual clicks.
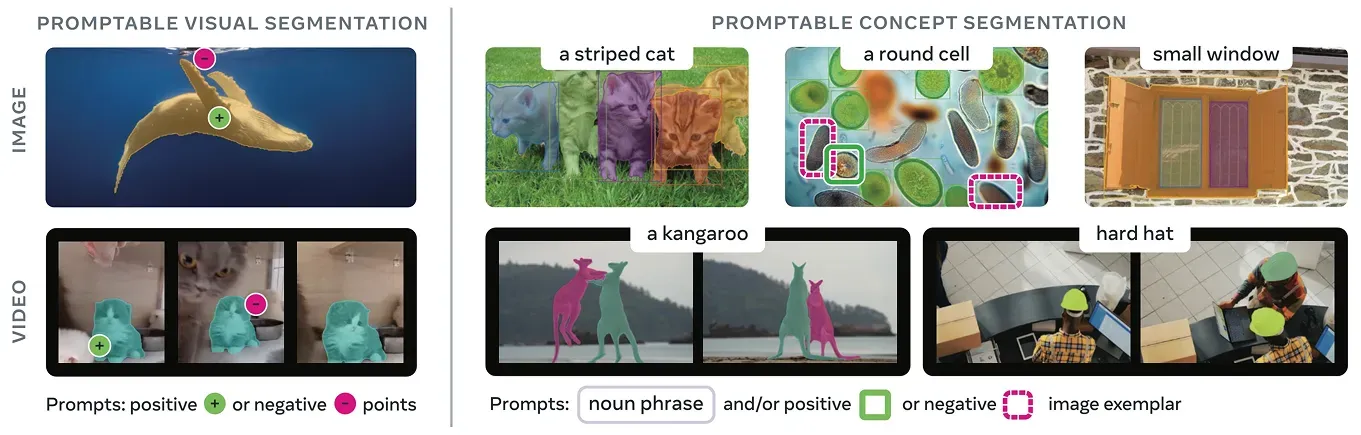
Fig 2. SAM 3 introduces concept segmentation with text or image examples. (Source)
Link to this sectionComparing SAM 3 vs SAM 2 vs SAM 1#
Let’s say you are watching a safari video with many different animals, and you want to detect and segment only the elephants. What would this task look like across the different versions of SAM?
With SAM, you would need to manually click on each elephant in each frame to generate a segmentation mask. There is no tracking, so every new frame requires new clicks.
With SAM 2, you could click once on an elephant, get its mask, and the model would track that same elephant through the video. However, you would still need to provide separate clicks if you wanted to segment multiple elephants (specific objects), since SAM 2 doesn’t understand categories like “elephant” on its own.
With SAM 3, the workflow becomes much simpler. You can type “elephant” or draw a bounding box around a single elephant to provide an example, and the model will automatically find every elephant in the video, segment them, and track them consistently across frames. It still supports the click and box prompts used in earlier versions, but now it can also respond to text prompts and exemplar images, which is something SAM and SAM 2 couldn't do.
Link to this sectionHow the SAM 3 model works#
Next, let’s take a closer look at how the SAM 3 model works and how it was trained.
Link to this sectionAn overview of SAM 3’s model architecture#
SAM 3 brings several components together to support concept prompts and visual prompts in a single system. At its core, the model uses the Meta Perception Encoder, which is Meta’s unified open-source image-text encoder.
This encoder can process both images and short noun phrases. Simply put, this allows SAM 3 to link language and visual features more effectively than previous versions of the Segment Anything Model.
On top of this encoder, SAM 3 includes a detector that is based on the DETR family of transformer models. This detector identifies objects in the image and helps the system determine which objects correspond to the user’s prompt.
Specifically, for video segmentation, SAM 3 uses a tracking component that builds on the memory bank and memory encoder from SAM 2. This lets the model hold information about objects across frames so it can re-identify and track them over time.
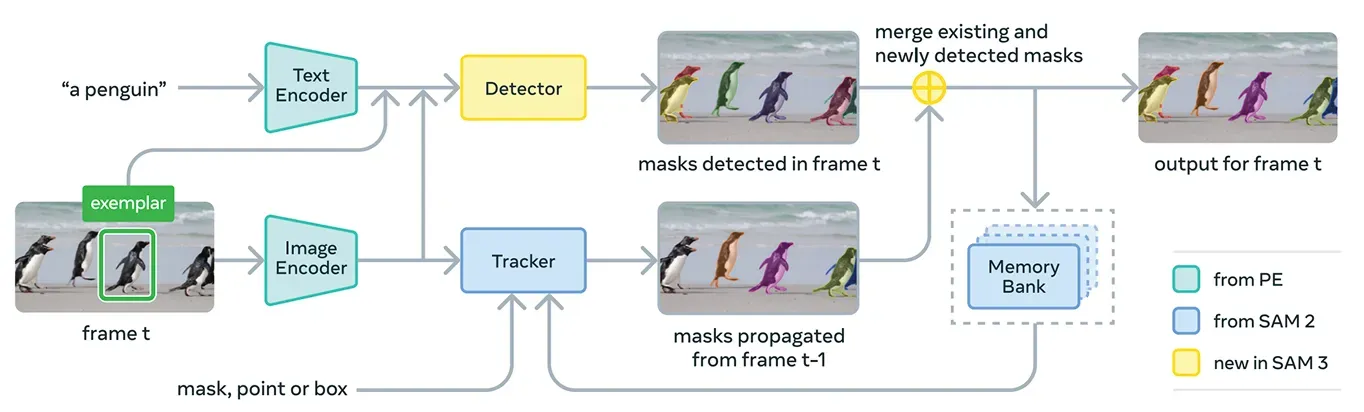
Fig 3. How segmenting anything with concepts works (Source: scontent)
Link to this sectionThe scalable data engine behind Segment Anything Model 3#
To train SAM 3, Meta needed far more annotated data than what currently exists on the internet. High-quality segmentation masks and text labels are difficult to create at a large scale, and fully outlining every instance of a concept in images and videos is slow and expensive.
To solve this, Meta built a new data engine that combines SAM 3 itself, additional AI models, and human annotators working together. The workflow begins with a pipeline of AI systems, including SAM 3 and a Llama-based captioning model.
These systems scan large collections of images and videos, generate captions, convert those captions into text labels, and produce early segmentation mask candidates. Human and AI annotators then review these candidates.
The AI annotators, trained to match or even surpass human accuracy on tasks like checking mask quality and verifying concept coverage, filter out straightforward cases. Humans step in only for more challenging examples where the model may still struggle.
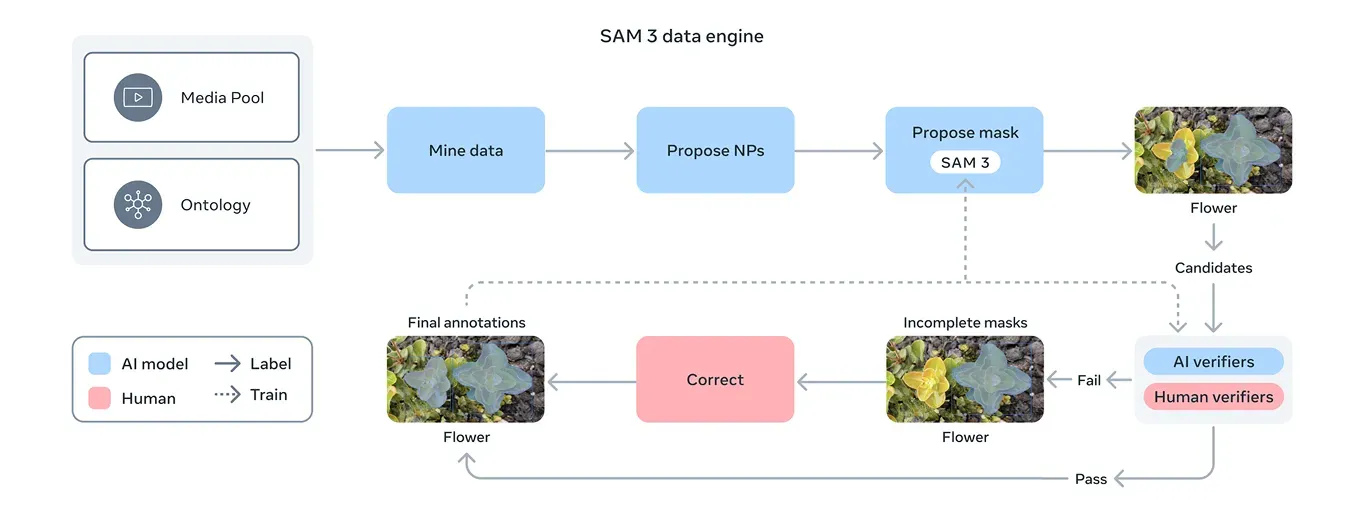
Fig 4. SAM 3 data engine (Source)
This approach gives Meta a major boost in annotation speed. By letting AI annotators handle easy cases, the pipeline becomes about five times faster on negative prompts and 36% faster on positive prompts in fine-grained domains.
This efficiency made it possible to scale the dataset to more than four million unique concepts. The constant loop of AI proposals, human corrections, and updated model predictions also improves label quality over time and helps SAM 3 learn a much broader set of visual and text-based concepts.
Link to this sectionSAM 3’s performance improvements#
With respect to performance, SAM 3 delivers a clear improvement over earlier models. On Meta’s new SA-Co benchmark, which evaluates open-vocabulary concept detection and segmentation, SAM 3 achieves roughly twice the performance of previous systems in both images and video.
It also matches or exceeds SAM 2 on interactive visual tasks such as point-to-mask and mask-to-masklet. Meta reports additional gains on harder evaluations like zero-shot LVIS (where models must recognize rare categories without training examples) and object counting (measuring whether all instances of an object are detected), highlighting stronger generalization across domains.
In addition to these accuracy improvements, SAM 3 is efficient, processing an image with more than 100 detected objects in about 30 milliseconds on an H200 GPU and maintaining near real-time speeds when tracking multiple objects in video.
Link to this sectionApplications of the Segment Anything Model 3#
Now that we have a better understanding of SAM 3, let's walk through how it is being used in real applications, from advanced text-guided reasoning to scientific research and Meta’s own products.
Link to this sectionHandling complex text queries using SAM 3 Agent#
SAM 3 can also be used as a tool inside a larger multimodal language model, which Meta calls the SAM 3 Agent. Instead of giving SAM 3 a short phrase like “elephant,” the agent can break a more complicated question into smaller prompts that SAM 3 understands.
For example, if the user asks, “What object in the picture is used for controlling and guiding a horse?” the agent tries different noun phrases, sends them to SAM 3, and checks which masks make sense. It keeps refining until it finds the right object.
Even without being trained on special reasoning datasets, the SAM 3 Agent performs well on benchmarks designed for complex text queries, such as ReasonSeg and OmniLabel. This shows that SAM 3 can support systems that need both language understanding and fine-grained visual segmentation.
Link to this sectionScientific and conservation applications of SAM 3#
Interestingly, SAM 3 is already being used in research settings where detailed visual labels are important. Meta worked with Conservation X Labs and Osa Conservation to build SA-FARI, a public wildlife monitoring dataset with more than 10,000 camera-trap videos.
Every animal in every frame is labeled with boxes and segmentation masks, something that would be extremely time-consuming to annotate by hand. Similarly, in ocean research, SAM 3 is being used alongside FathomNet and MBARI to create instance segmentation masks for underwater imagery and support new evaluation benchmarks.
Such datasets help scientists analyze video footage more efficiently and study animals and habitats that are usually difficult to track at scale. Researchers can also use these resources to build their own models for species identification, behavior analysis, and automated ecological monitoring.
Link to this sectionHow Meta is deploying SAM 3 across its products#
On top of its research uses, SAM 3 is also powering new features and use cases across Meta’s consumer products. Here’s a glimpse at some of the ways it is already being integrated:
- Instagram edits: Creators can apply effects to a specific person or object in a video without doing manual frame-by-frame work.
- Meta AI app and meta.ai on the web: SAM 3 supports new tools for modifying, enhancing, and remixing images and videos.
- Facebook Marketplace’s “View in Room”: SAM 3 works with SAM 3D to let people preview furniture or decor in their homes using a single photo.
- Aria Gen 2 research glasses: The Segment Anything Model 3 helps segment and track hands and objects from a first-person view, supporting AR (Augmented Reality), robotics, and contextual AI research.
Link to this sectionKey takeaways#
SAM 3 is an exciting step forward for segmentation. It introduces concept segmentation, open-vocabulary text prompts, and improved tracking. With noticeably stronger performance across both images and video, and the addition of SAM 3D, the model suite opens up new possibilities for vision AI, creative tools, scientific research, and real-world products.
Join our community and explore our GitHub repository to discover more about AI. If you're looking to build your own vision AI project, check out our licensing options. Explore more about applications like AI in healthcare and Vision AI in retail by visiting our solutions pages.






