The impact of Ultralytics YOLO26’s faster, edge-first design
See how Ultralytics YOLO26 is faster on the edge and why that matters for next-generation computer vision applications that demand low latency and efficiency.
Earlier this week, Ultralytics officially launched Ultralytics YOLO26, a faster, lighter, and smaller YOLO model that aims to redefine how computer vision systems perform at the edge. YOLO26 supports the same core vision tasks as previous YOLO models, including object detection and instance segmentation.

Fig 1. An example of using YOLO26 to segment an object.
The defining difference between YOLO26 and previous models is the environment in which it was designed to operate. Rather than optimizing primarily for cloud graphics processing units (GPUs) or benchmark-driven performance, YOLO26 was designed from the ground up for real-world deployment on edge devices and embedded hardware.
As computer vision moves from research into production, the reality of performance constraints is becoming clearer. Edge environments are shaped by tight latency budgets, limited memory, power, and thermal constraints, and the need for predictable behavior across diverse platforms.
In these settings, overall system performance depends not just on raw inference speed, but also on how efficiently the entire pipeline operates. Post-processing overhead, memory pressure, and platform-specific execution paths are often bottlenecks.
YOLO26 addresses these challenges by taking a faster, edge-first approach that looks at the entire inference pipeline rather than individual model metrics. By focusing on edge optimization, simplifying the inference pipeline, and removing unnecessary post-processing steps, YOLO26 delivers speed improvements that result in lower latency and more reliable behavior in production.
In this article, we’ll explore how YOLO26’s architectural choices translate into real-world performance improvements, and why being faster at the edge fundamentally changes what is possible for next-generation computer vision applications.
Link to this sectionThe reality of edge deployment#
Running computer vision models at the edge is very different from running them in the cloud. In cloud environments, systems typically have access to powerful GPUs, large amounts of memory, and stable hardware. At the edge, the same assumptions don't apply.
Most edge deployments run on diverse hardware architectures, not GPUs. Devices typically use multiple specialized processors for different tasks, which are optimized for efficiency and low power rather than the raw compute capacity of cloud GPUs.
Latency is another major constraint. Edge systems often operate under tight real-time limits, where even small delays can affect responsiveness or safety. In these cases, end-to-end latency matters more than raw inference speed. A model can be fast on paper but still fall short once post-processing and data movement are added.
Memory also plays a big role. Many edge devices have limited memory and shared caches. Large intermediate tensors and inefficient memory usage can slow systems down, even when the model itself is efficient.
Power and thermal limits add further constraints. Edge devices often run without active cooling and within fixed power budgets. Performance needs to be efficient and sustainable, not just fast in short bursts.
On top of all of this, edge deployments require consistency. Models have to behave the same across devices and runtimes. Platform-specific code or complex post-processing steps can introduce subtle differences that make systems harder to deploy and maintain.
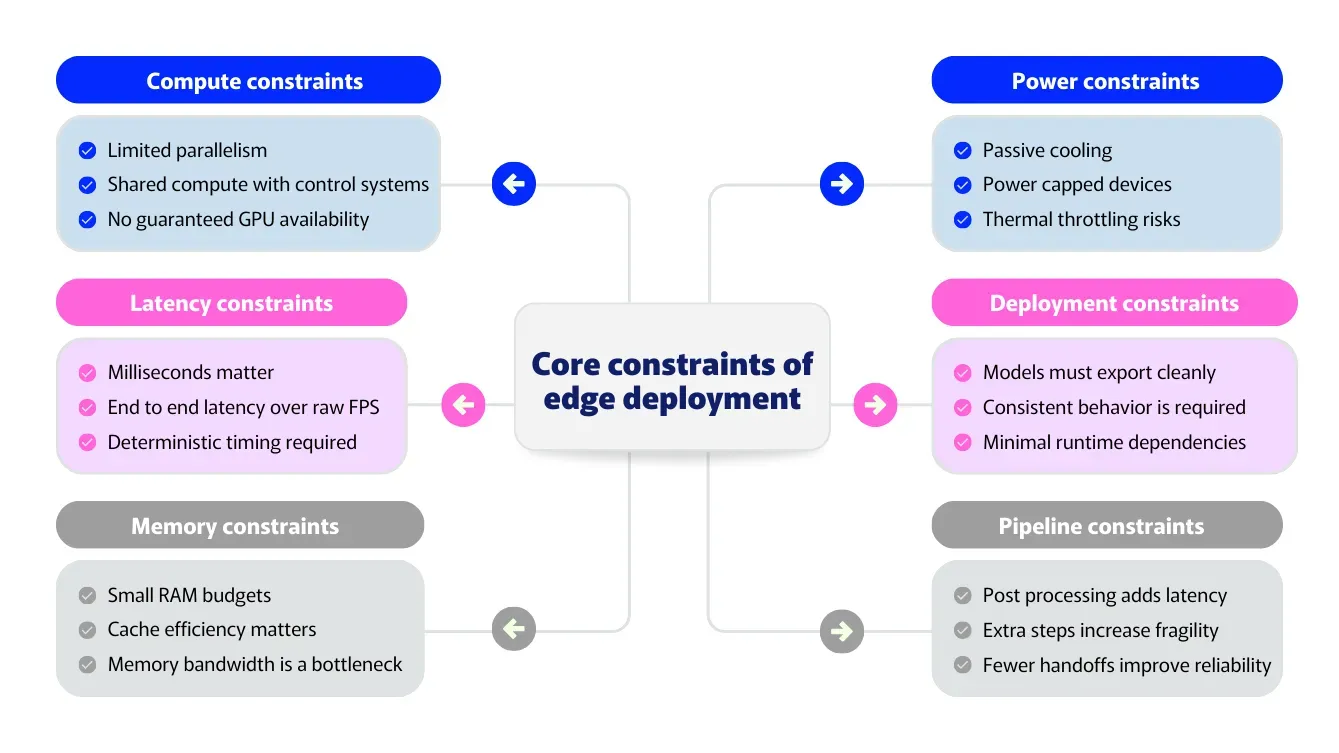
Fig 2. A look at the constraints of edge deployment. Image by author.
These constraints define what performance really means at the edge. In other words, performance is defined by the whole pipeline, not a single metric.
Link to this sectionWhy edge vision demands a different performance model#
So, how are the constraints of edge deployment related to the requirements of a computer vision model built for the edge? The connection becomes clear once models move from research settings into real-world systems.
In cloud environments, performance is often measured using benchmarks like inference speed and accuracy. At the edge, those metrics only tell part of the story. Vision systems typically run across heterogeneous hardware, where neural network inference is offloaded to specialized accelerators while other parts of the pipeline run on general-purpose processors.
In this context, model speed isn’t enough. How the entire system performs once the model is deployed is key. A model can appear fast by itself, but still fall short if post-processing, data movement, or platform-specific steps add overhead.
That’s why edge vision requires a performance model that focuses on system-level efficiency rather than isolated benchmarks. YOLO26 reflects this shift by focusing on edge-first optimization, streamlined inference, and end-to-end execution built for real-world deployment.
Link to this sectionThe foundation for speed: An edge-first design#
At the edge, performance is defined by how well a model maps to the device’s actual hardware architecture. Designing for the edge first ensures vision systems run reliably across real-world platforms, regardless of the specific mix of processing units available.
An edge-first approach prioritizes predictable and efficient execution across heterogeneous hardware, rather than adapting models that were optimized for cloud GPUs after the fact. Simply put, this means favoring operations that translate well to neural network accelerators, minimizing non-neural work outside the model, and reducing unnecessary complexity that can slow end-to-end execution.
YOLO26 was designed with these constraints in mind. Its architecture focuses on consistent performance instead of peak throughput under ideal conditions. By simplifying execution paths and eliminating unnecessary computation, YOLO26 reduces overhead across the inference pipeline and makes better use of the device’s available acceleration and memory hierarchy.
This approach also improves reliability. Edge-first optimization leads to more predictable timing and fewer performance spikes, which is critical for real-time systems. Instead of relying on specialized hardware or heavy post-processing to achieve speed, YOLO26 emphasizes efficiency throughout the inference pipeline.
Link to this sectionEnd-to-end inference and the cost of post-processing#
You might be wondering what it means to eliminate unnecessary post-processing steps. To understand this, let's take a step back and look at how traditional object detection systems work.
In many object detection pipelines, inference doesn't end when the model produces its predictions. Instead, the model outputs a large number of overlapping bounding boxes, which then need to be filtered and refined before they can be used. This cleanup happens through post-processing steps that run outside the model itself.
One of the most common post-processing steps is Non-Maximum Suppression, or NMS. NMS compares overlapping bounding boxes and keeps only the most confident detections, removing duplicates that refer to the same object. While this approach is effective, it introduces extra computation after inference is complete.
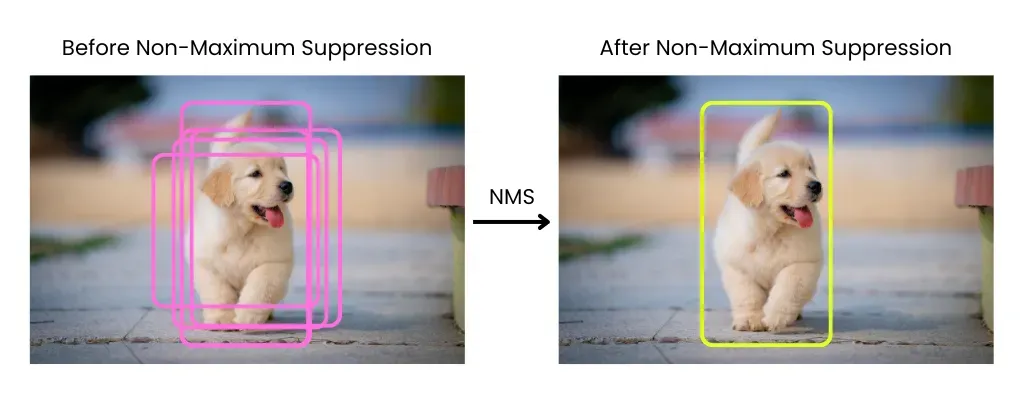
Fig 3. Understanding NMS. Image by author.
At the edge, this extra work comes at a cost. Post-processing steps like NMS are not well suited to the specialized accelerators used for neural network inference, which are optimized for dense neural computation rather than control-heavy or memory-intensive operations.
As a result, NMS introduces additional latency and memory overhead, and its cost grows as the number of detections increases. Even when the model itself is fast, NMS can still consume a significant portion of the total runtime.
Post-processing also increases system complexity. Because it lives outside the model, it has to be implemented separately for different runtimes and hardware targets. This often leads to platform-specific code paths, inconsistent behavior across devices, and more fragile deployment pipelines.
Most importantly, post-processing breaks the idea of true end-to-end performance. Measuring model inference speed doesn't reflect how the system behaves in production. What ultimately matters is the total time from input to final output, including every step in the pipeline.
In these situations, post-processing becomes a hidden bottleneck at the edge. It adds latency, consumes CPU resources, and complicates deployment, all while sitting outside the model itself.
Link to this sectionHow YOLO26 removes NMS and why that makes it faster#
YOLO26 removes NMS by tackling the root cause of duplicate detections rather than cleaning them up after inference. Instead of producing many overlapping predictions that need to be filtered, the model is trained to generate a smaller set of confident, final detections directly.
This is made possible by changing how detections are learned during training. YOLO26 encourages a clearer one-to-one relationship between objects and predictions, reducing redundancy at its source. As a result, duplicate detections are resolved inside the network itself rather than through external post-processing.
Removing NMS has an immediate impact on edge performance. Since NMS doesn’t map well to neural network accelerators, eliminating it reduces memory movement and avoids expensive non-neural processing steps. This lowers end-to-end latency and makes performance more predictable, especially on edge devices where post-processing can otherwise consume a noticeable portion of total runtime.
It also simplifies the inference pipeline. With fewer steps outside the model, there is less data movement and fewer handoffs between components. The model’s output is already the final result, which makes execution more predictable.
Link to this sectionRemoving DFL to enable true end-to-end performance#
Another innovation in YOLO26 is the removal of Distribution Focal Loss, or DFL, which was used in earlier YOLO models for bounding box regression. Instead of predicting a single coordinate directly, models using DFL learned a distribution of possible values and then derived a final bounding box from that distribution. This approach helped improve localization accuracy and was an important step forward in previous generations.
Over time, however, DFL also introduced trade-offs. Predicting distributions increases computation and adds complexity to the model architecture, which can slow inference on CPUs and make models harder to export across deployment formats. DFL also imposed fixed regression ranges, which could limit flexibility when detecting very large objects.
YOLO26 removes DFL as part of its move toward a simpler, end-to-end design. Bounding box regression is redesigned to be more direct, reducing unnecessary computation while maintaining accuracy. This change aligns with YOLO26’s NMS-free approach.
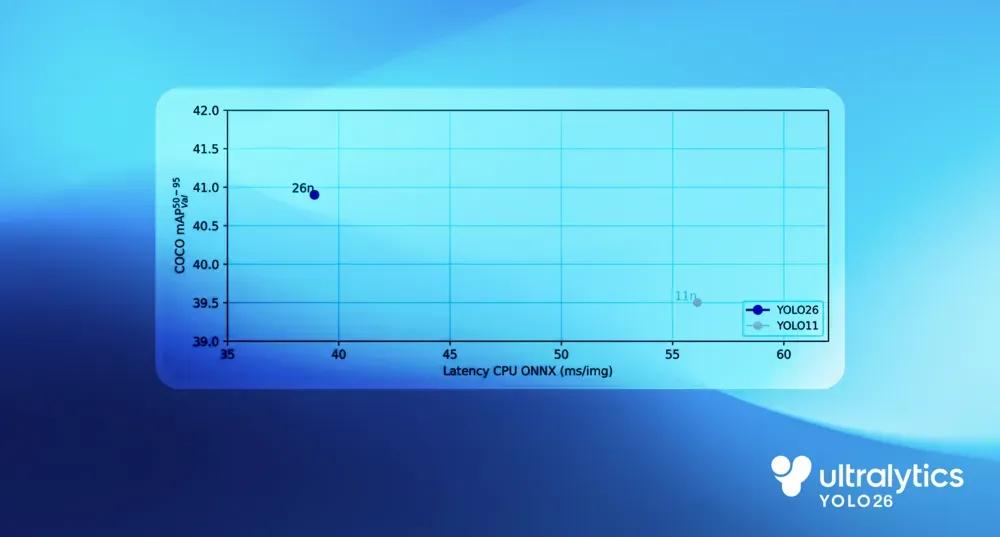
Link to this sectionWhere the 43% faster CPU inference comes from#
In CPU-based benchmarks, YOLO26 shows a clear performance improvement over earlier YOLO models. Compared to Ultralytics YOLO11, the YOLO26 nano model delivers up to 43% faster CPU inference, a difference that has a meaningful impact in real-world edge deployments.
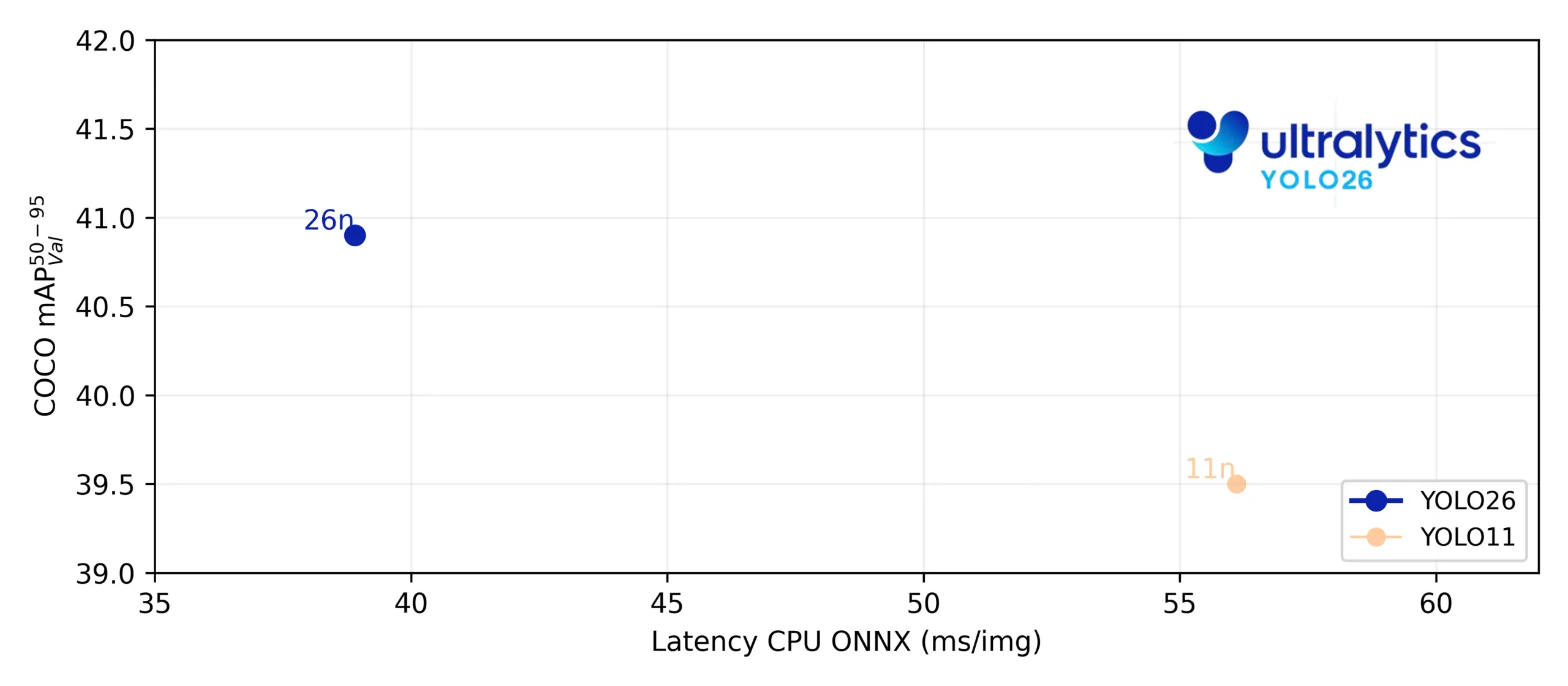
Fig 4. Benchmarking YOLO26 CPU Speed.
This gain comes from simplifying the full inference pipeline rather than optimizing a single component. End-to-end execution removes post-processing overhead, a more direct bounding box regression method reduces computation, and CPU-first design choices improve execution efficiency on general-purpose processors.
Together, these changes reduce latency, lower CPU workload, and lead to faster, more consistent performance on real-world edge hardware.
Link to this sectionThe impact of YOLO26 on edge deployment and exports#
YOLO26’s performance gains extend beyond faster inference. By simplifying the model and reducing memory overhead, it becomes easier to deploy and more reliable to run across edge environments.
YOLO26’s end-to-end design also simplifies export. With fewer auxiliary components and no external post-processing steps, exported models are fully self-contained. This reduces platform-specific dependencies and helps ensure consistent behavior across runtimes and hardware targets.
In action, this means YOLO26 can be deployed more easily to edge devices such as cameras, robots, and embedded systems, using various export formats. What you export is what you run, with fewer integration steps and less risk of deployment drift.
Link to this sectionFaster edge inference enables robotics and industrial vision AI#
So far, we’ve looked at how YOLO26’s edge-first design improves performance at a system level. The real impact, however, is in how it makes vision AI easier to integrate into real-world applications.
For instance, in robotics and industrial environments, vision systems often operate under strict real-time constraints. Decisions need to be made quickly and consistently, using limited compute and without relying on cloud connectivity. With Ultralytics YOLO26, meeting these requirements becomes practical.
Applications like robot navigation and object manipulation benefit from lower latency and more predictable inference, allowing robots to respond smoothly to changes in their environment. Similarly, in industrial settings, vision models can run directly on production lines to detect defects, track components, and monitor processes without introducing delays or added complexity.
By enabling fast, reliable inference on edge hardware, YOLO26 helps make vision AI a natural part of robotics and industrial systems, rather than a challenge to deploy and maintain.
Link to this sectionKey takeaways#
YOLO26 was built for the edge, where real-world constraints like latency, memory, and reliability define what’s possible. By designing the model around CPU-first execution, end-to-end inference, and simpler deployment, YOLO26 makes vision AI practical to integrate into real systems. This edge-first approach enables a wide range of applications, from robotics and industrial vision to embedded and on-device AI, where performance and predictability matter most.
Join our growing community and explore our GitHub repository for hands-on AI resources. To build with vision AI today, explore our licensing options. Learn how AI in agriculture is transforming farming and how vision AI in healthcare is shaping the future by visiting our solutions pages.






