Популярные OCR-модели с открытым кодом и принципы их работы
Присоединяйся к нам, чтобы изучить популярные модели OCR, принципы преобразования изображений в текст и их роль в приложениях ИИ и компьютерного зрения.

Чтобы наглядно ознакомиться с концепциями, описанными в этой статье, посмотри видео ниже.
Многие компании и цифровые системы полагаются на информацию из документов, таких как отсканированные счета, удостоверения личности или рукописные формы. Но когда эта информация хранится в виде изображения, компьютерам сложно искать, извлекать или использовать ее для различных задач.
Однако благодаря таким инструментам, как компьютерное зрение, область ИИ, которая позволяет машинам интерпретировать и понимать визуальную информацию, превращение изображений в текст становится намного проще. В частности, оптическое распознавание символов (OCR) — это технология компьютерного зрения, которую можно использовать для обнаружения и извлечения текста.
OCR-модели обучаются распознавать текст в различных форматах и преобразовывать его в редактируемые, доступные для поиска данные. Они широко используются в автоматизации документооборота, проверке личности и системах сканирования в реальном времени.
В этой статье мы рассмотрим, как работают OCR-модели, популярные модели с открытым исходным кодом, где они применяются, распространенные варианты использования и ключевые соображения для практического применения.
Link to this sectionЧто такое OCR?#
OCR-модели созданы для того, чтобы помочь машинам считывать текст из визуальных источников, подобно тому, как мы читаем печатный или рукописный текст. Эти модели принимают на вход такие данные, как отсканированные документы, изображения или фотографии рукописных заметок, и превращают их в цифровой текст, который можно искать, редактировать или использовать в программных системах.
Хотя ранние OCR-системы следовали строгому шаблону, современные OCR-модели используют глубокое обучение для распознавания текста. Они легко справляются с различными шрифтами, языками и даже неразборчивым почерком, работая при этом с изображениями низкого качества. Эти достижения сделали OCR-модели ключевой частью автоматизации в отраслях с большим объемом текстовой документации, таких как финансы, здравоохранение, логистика и государственные услуги.
Хотя OCR-модели отлично подходят для изображений, где текст четкий и структурированный, они могут столкнуться с трудностями, когда текст появляется на фоне сложных визуальных элементов или в динамичных сценах. В таких случаях OCR-модели можно использовать вместе с моделями компьютерного зрения, такими как Ultralytics YOLO11.
YOLO11 может обнаруживать конкретные объекты на изображении, такие как знаки, документы или этикетки, помогая локализовать области текста перед тем, как OCR будет использован для извлечения фактического содержимого.
Например, в автономных транспортных средствах YOLO11 может обнаружить знак «Стоп», а затем OCR может прочитать текст, позволяя системе точно интерпретировать как объект, так и его значение.
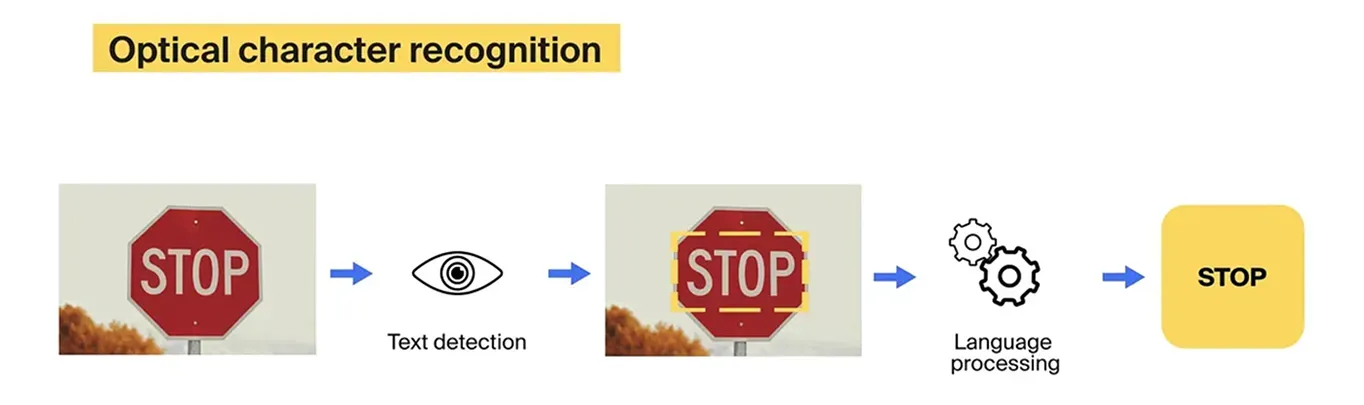
Рис. 1. Пример использования OCR (источник).
Link to this sectionОбзор того, как работают OCR-модели#
Теперь, когда мы разобрались, что такое OCR, давай более детально рассмотрим, как работают OCR-модели.
Перед тем как OCR-модель будет использована для чтения и извлечения текста из изображения, оно обычно проходит через два важных этапа: предварительная обработка и обнаружение объектов.
Сначала изображение очищается и улучшается посредством предварительной обработки. Применяются базовые методы обработки изображений, такие как повышение резкости, шумоподавление и настройка яркости или контрастности, чтобы улучшить общее качество изображения и облегчить обнаружение текста.
Затем используются задачи компьютерного зрения, такие как обнаружение объектов. На этом этапе определяются конкретные объекты с текстом, такие как номерные знаки, дорожные знаки, формы или ID-карты. Идентифицируя эти объекты, система изолирует области, где находится значимый текст, подготавливая их к распознаванию.
Только после этих шагов OCR-модель приступает к работе. Сначала она берет обнаруженные области и разбивает их на более мелкие части, идентифицируя отдельные символы, слова или строки текста.
Используя методы глубокого обучения, модель анализирует формы, паттерны и интервалы между буквами, сравнивает их с тем, что она выучила во время обучения, и предсказывает наиболее вероятные символы. Затем она восстанавливает распознанные символы в связный текст для дальнейшей обработки.
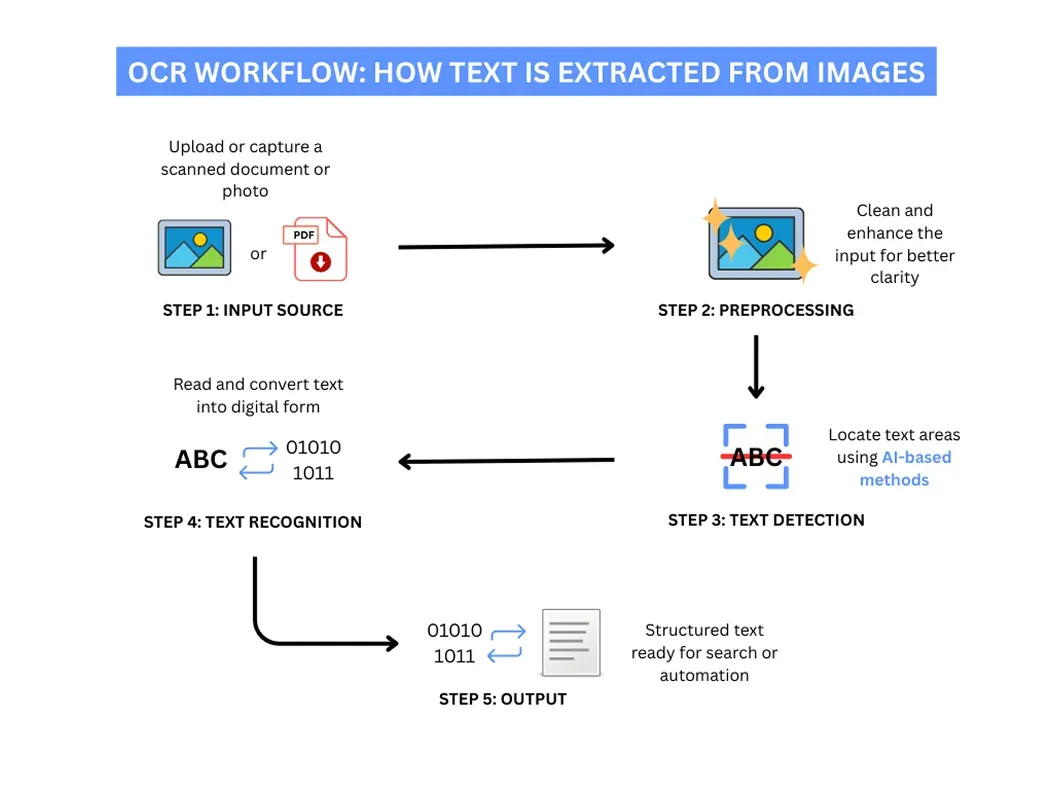
Рис. 2. Понимание работы OCR. Автор изображения неизвестен.
Link to this sectionПопулярные OCR-модели с открытым исходным кодом#
Когда ты создаешь приложение компьютерного зрения, которое включает извлечение текста, выбор подходящей OCR-модели зависит от таких факторов, как точность, поддержка языков и легкость интеграции в реальные системы.
В наши дни многие модели с открытым исходным кодом обеспечивают гибкость, сильную поддержку сообщества и надежную производительность, необходимые разработчикам. Давай рассмотрим некоторые из самых популярных вариантов и то, чем они выделяются.
Link to this sectionTesseract OCR#
Tesseract — одна из наиболее широко используемых сегодня OCR-моделей с открытым исходным кодом. Она была первоначально разработана в лабораториях Hewlett-Packard в Бристоле (Англия) и Грили (Колорадо) в период с 1985 по 1994 год. В 2005 году HP выпустила Tesseract как программное обеспечение с открытым исходным кодом, и с 2006 года его поддерживает Google при постоянном участии сообщества разработчиков.
Одной из ключевых особенностей Tesseract является способность поддерживать более 100 языков, что делает его надежным выбором для многоязычных проектов. Постоянные улучшения повысили его надежность при чтении печатного текста, особенно в структурированных документах, таких как формы и отчеты.

Рис. 3. Распознавание текста с помощью Tesseract OCR (источник).
Tesseract обычно используется в проектах, связанных со сканированием счетов, архивированием бумаг или извлечением текста из документов со стандартной версткой. Он лучше всего работает, когда качество документа хорошее, а макет не сильно меняется.
Link to this sectionEasyOCR#
Аналогично, EasyOCR — это библиотека OCR на Python с открытым исходным кодом, разработанная Jaided AI. Она поддерживает более 80 языков, включая латиницу, китайский, арабский и кириллицу, что делает ее универсальным инструментом для многоязычного распознавания текста.
Созданный для работы как с печатным, так и с рукописным текстом, EasyOCR хорошо справляется с документами, различающимися по верстке, шрифту или структуре. Эта гибкость делает его отличным вариантом для извлечения текста из различных источников, таких как чеки, уличные знаки и формы со смешанными языками ввода.
Построенный на базе PyTorch, EasyOCR использует методы глубокого обучения для точного обнаружения и распознавания текста. Он эффективно работает как на CPU, так и на GPU, позволяя масштабировать решение в зависимости от задачи — будь то обработка нескольких изображений локально или работа с большими пакетами файлов на более мощных системах.
Будучи инструментом с открытым исходным кодом, EasyOCR получает регулярные обновления и улучшения от сообщества, что помогает ему оставаться актуальным и адаптируемым к широкому спектру реальных задач OCR.
Link to this sectionPaddleOCR#
PaddleOCR — это высокопроизводительный OCR-инструментарий, разработанный Baidu, который объединяет обнаружение и распознавание текста в одном оптимизированном пайплайне. Благодаря поддержке 80 языков, он может работать со сложными документами, такими как чеки, таблицы и формы.
Что отличает PaddleOCR, так это то, что он построен на базе фреймворка глубокого обучения PaddlePaddle. Фреймворк PaddlePaddle был разработан для легкой, надежной и масштабируемой разработки и развертывания ИИ-моделей. Кроме того, PaddleOCR обеспечивает высокую точность даже на изображениях низкого качества или с большим количеством помех, что делает его хорошим выбором для реальных задач OCR, где точность и надежность являются ключевыми факторами.
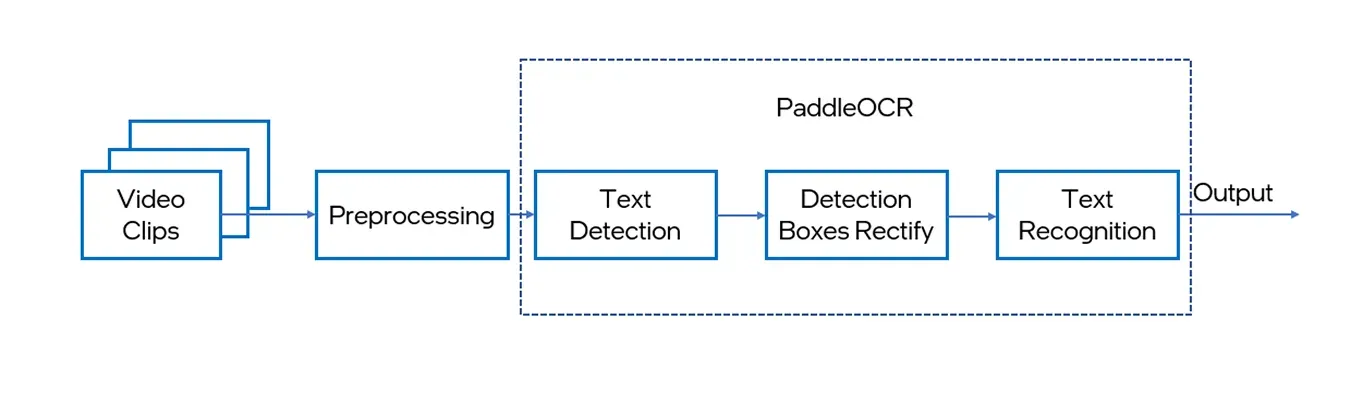
Рис. 4. Рабочий процесс PaddleOCR (источник).
Кроме того, PaddleOCR обладает высокой модульностью, позволяя разработчикам настраивать свои пайплайны, выбирая конкретные компоненты обнаружения, распознавания и классификации. Благодаря хорошо документированным API на Python и сильной поддержке сообщества, это гибкое, готовое к использованию решение для широкого спектра OCR-приложений.
Link to this sectionДругие популярные OCR-модели с открытым исходным кодом#
Вот еще несколько OCR-моделей с открытым исходным кодом, которые часто используются:
- MMOCR: Разработан для более сложных проектов, MMOCR умеет не только обнаруживать текст, но и понимать, как он расположен на странице. Он идеально подходит для работы с таблицами, многоколоночной версткой и другими визуально сложными документами.
- TrOCR: Построенный на основе трансформеров, типа моделей глубокого обучения, особенно эффективных в понимании последовательностей текста, TrOCR превосходно справляется с длинными отрывками и неаккуратными, неструктурированными макетами. Это надежный выбор, когда контент читается как непрерывная речь, а не как отдельные подписи.
Link to this sectionРаспространенные варианты применения OCR-моделей#
По мере того как технология OCR становится более совершенной, ее роль вышла далеко за рамки простой оцифровки. На самом деле, OCR-модели теперь внедряются в различные отрасли, зависящие от текстовой информации. Вот краткий обзор того, как OCR применяется в реальных системах сегодня:
- Юридическая отрасль и электронное обнаружение: Юридические фирмы используют OCR для сканирования тысяч страниц юридических документов, делая контракты, судебные документы и доказательства доступными для поиска для более быстрого обнаружения и анализа.
- Здравоохранение: Больницы используют OCR-модели для оцифровки медицинских записей, интерпретации рукописных рецептов и эффективного управления лабораторными отчетами. Это упрощает административные задачи и повышает точность в медицинских рабочих процессах.
- Сохранение исторического наследия: Музеи, библиотеки и архивы используют OCR для оцифровки старых книг, рукописей и газет, сохраняя ценное культурное наследие и делая его доступным для поиска исследователями.
- Проверка личности и паспортов: Многие системы цифрового онбординга и путешествий полагаются на OCR для извлечения ключевых данных из государственных документов. Более быстрая проверка личности и меньшее количество ошибок при ручном вводе приводят к более гладкому пользовательскому опыту и более высокой безопасности.

Рис. 5. Сканер на базе OCR для проверки личности по паспорту. (источник).
Link to this sectionПлюсы и минусы OCR-моделей#
OCR-модели прошли долгий путь с момента их появления в 1950-х годах. Сейчас они стали более доступными, точными и адаптируемыми к различному контенту и платформам. Вот основные преимущества, которые дают современные OCR-модели:
- Улучшение доступности: OCR помогает сделать контент более доступным, преобразуя печатный материал в форматы, читаемые программами экранного доступа для пользователей с нарушениями зрения.
- Улучшение пайплайнов машинного обучения: OCR выступает в качестве моста, который превращает неструктурированные визуальные данные в структурированный текст, делая его пригодным для использования downstream-моделями машинного обучения.
- Извлечение без шаблонов: Продвинутый OCR больше не требует жестких шаблонов — он может интеллектуально извлекать информацию, даже если верстка документов отличается.
Несмотря на свои преимущества, OCR-модели все еще сталкиваются с некоторыми проблемами, особенно когда входные данные неидеальны. Вот некоторые распространенные ограничения, которые стоит иметь в виду:
- Чувствительность к качеству изображения: OCR лучше всего работает с четкими изображениями; размытые или темные фотографии могут повлиять на результаты.
- Трудности с определенным почерком или шрифтами: Причудливый или неразборчивый почерк может сбить с толку даже лучшие модели.
- Все еще требуется постобработка: Даже при высокой точности результаты OCR часто нуждаются в проверке человеком или очистке, особенно для критически важных документов.
Link to this sectionОсновные выводы#
OCR позволяет компьютерам считывать текст с изображений, делая возможным использование этой информации в цифровых системах. Технология играет ключевую роль в обработке документов, знаков и рукописных заметок и имеет важное значение там, где критически важны скорость и точность.
OCR-модели также часто работают вместе с моделями, такими как Ultralytics YOLO11, которые могут обнаруживать объекты на изображениях. Вместе они позволяют системам понимать, что написано и где это находится. Поскольку эти технологии продолжают совершенствоваться, OCR становится основной частью того, как машины интерпретируют мир и взаимодействуют с ним.
Интересуешься ИИ-зрением? Посети наш репозиторий на GitHub и присоединяйся к нашему сообществу, чтобы продолжать исследования. Узнай о таких инновациях, как ИИ в беспилотных автомобилях и ИИ-зрение в сельском хозяйстве, на наших страницах с решениями. Ознакомься с нашими вариантами лицензирования и начни свой проект по компьютерному зрению!






