什么是模型优化?快速入门指南
了解超参数调优、模型剪枝和模型量化等模型优化技术如何帮助计算机视觉模型更高效地运行。

Model optimization is a process that aims to improve the efficiency and performance of machine learning models. By refining a model's structure and function, optimization makes it possible for models to deliver better results with minimal computational resources and reduced training and evaluation time.
这一过程在 计算机视觉 等领域尤为重要,因为这些领域的 模型 通常需要大量资源来分析 复杂图像。在 移动设备 或边缘系统等资源受限的环境中,优化后的模型可以在资源有限的情况下高效运行,同时保持准确性。
实现模型优化通常使用多种技术,包括超参数调整、模型剪枝、模型量化和混合精度。在本文中,我们将探讨这些技术及其为 计算机视觉应用 带来的益处。让我们开始吧!
Link to this section理解模型优化#
计算机视觉模型 通常具有 深度层 和复杂的结构,非常适合识别图像中的复杂模式,但它们在 处理能力 方面要求很高。当这些模型 部署 在硬件受限的设备(如 移动电话 或 边缘设备)上时,可能会面临某些挑战或限制。
这些设备有限的处理能力、内存和能量可能导致 性能 显著下降,因为模型难以跟上运行需求。模型优化技术是解决这些问题的关键。它们有助于简化模型,减少其 计算需求,并确保模型即使在资源有限的情况下也能有效工作。模型优化可以通过简化 模型架构、降低计算 精度 或移除不必要的组件来使模型变得更轻量、更快速。
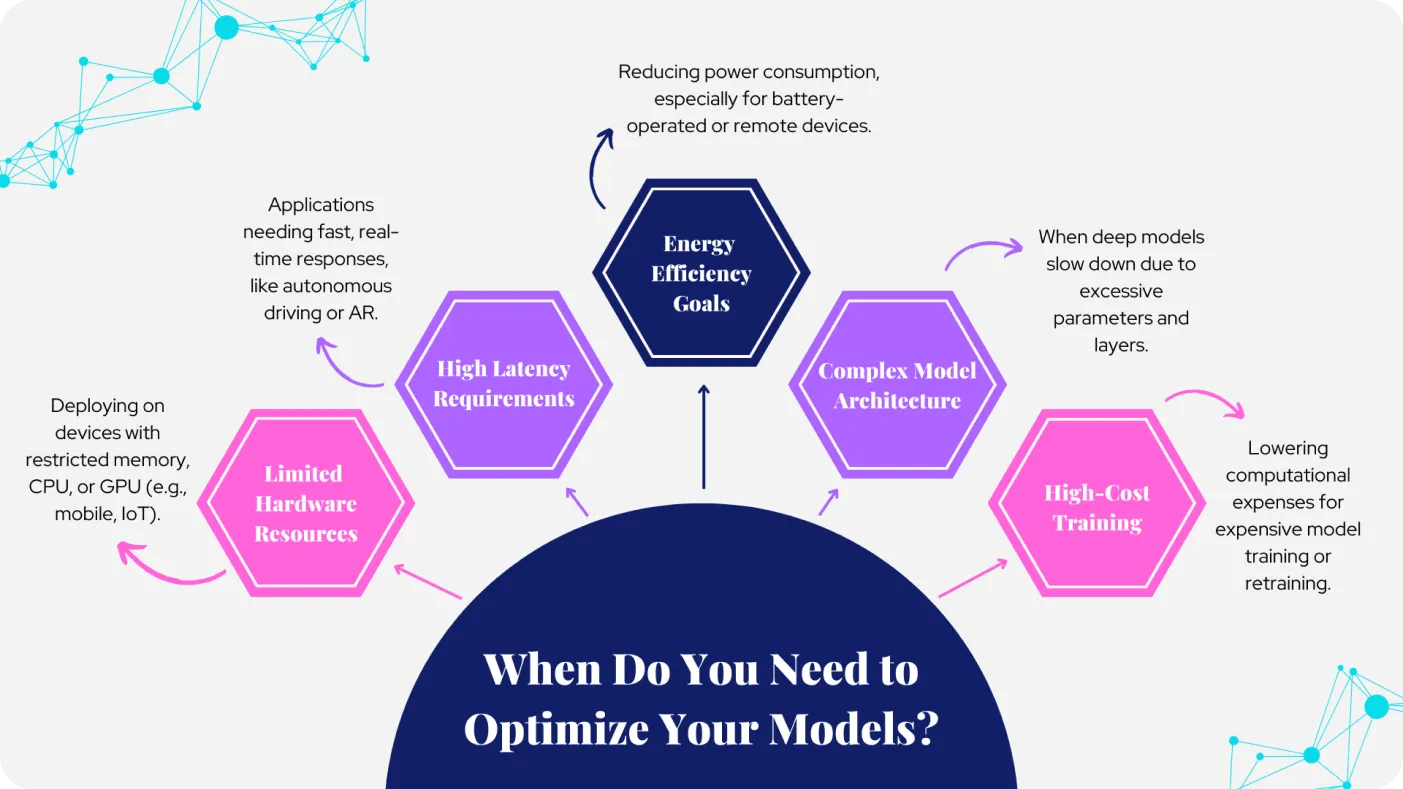
图 1. 优化模型的原因。图片由作者提供。
以下是一些最常用的模型 优化 技术,我们将在后续章节中更详细地探讨这些技术:
- 超参数调整:这涉及系统地调整超参数,例如学习率和批处理大小,以提高模型性能。
- 模型剪枝:该技术从神经网络中移除不必要的权重和连接,从而降低其复杂性和计算成本。
- 模型量化: 量化涉及降低模型权重和激活值的精度,通常从 32 位降低到 16 位或 8 位,从而显著减小内存占用并降低计算需求。
- 精度调整:也称为混合精度训练,它涉及对模型的不同部分使用不同的精度格式,并在不影响准确性的情况下优化资源使用。
Link to this section详解:机器学习模型中的超参数#
你可以通过调整超参数(决定模型如何从数据中学习的设置)来帮助模型更好地学习和执行任务。超参数调整 是一种优化这些设置的技术,可以提高模型的效率和 准确性。与模型在 训练 过程中学习的参数不同,超参数是指导训练过程的预设值。
让我们来看看一些可以调整的超参数示例:
- 学习率:该参数控制模型调整其内部权重的步长。较高的学习率可以加快学习速度,但有可能会错过最优解,而较低的速率可能更准确,但速度较慢。
- 批处理大小:它定义了每个训练步骤中处理的数据样本数量。较大的批处理大小提供更稳定的学习,但需要更多内存。较小的批次训练速度更快,但可能不太稳定。
- 迭代次数:你可以使用此参数确定模型查看完整 数据集 的次数。更多的迭代次数可以提高准确性,但存在 过拟合 的风险。
- 核大小:它定义了 卷积神经网络 (CNNs) 中的滤波器大小。较大的核可以捕获更广泛的模式,但需要更多的处理能力;较小的核专注于更精细的细节。
Link to this section超参数调整的工作原理#
超参数调优通常从定义每个超参数的取值范围开始。随后,搜索算法会在这些范围内探索不同的组合,以确定能产生 best performance 的设置。
常用的调整方法包括网格搜索、随机搜索和贝叶斯优化。网格搜索会测试指定范围内值的每一个可能组合。随机搜索会随机选择组合,通常能更快地找到有效的设置。贝叶斯优化使用概率模型,根据先前结果预测有潜力的超参数值。这种方法通常可以减少所需的试验次数。
最终,针对每种超参数组合,模型性能都会经过 evaluated。该过程会重复进行,直到达到预期的结果。
Link to this section超参数与模型参数#
在进行超参数调优时,你可能会好奇超参数与 model parameters 之间有什么区别。
超参数是在 training 前设置的值,用于控制 model 的学习方式,例如学习率或批次大小。这些设置在训练过程中是固定的,并直接影响学习过程。另一方面,模型参数则是在训练过程中由模型自身学习得到的。其中包括权重和 biases,它们会随着模型的训练而调整,并最终引导模型的 predictions。本质上,超参数塑造了学习的过程,而模型参数则是学习过程的结果。
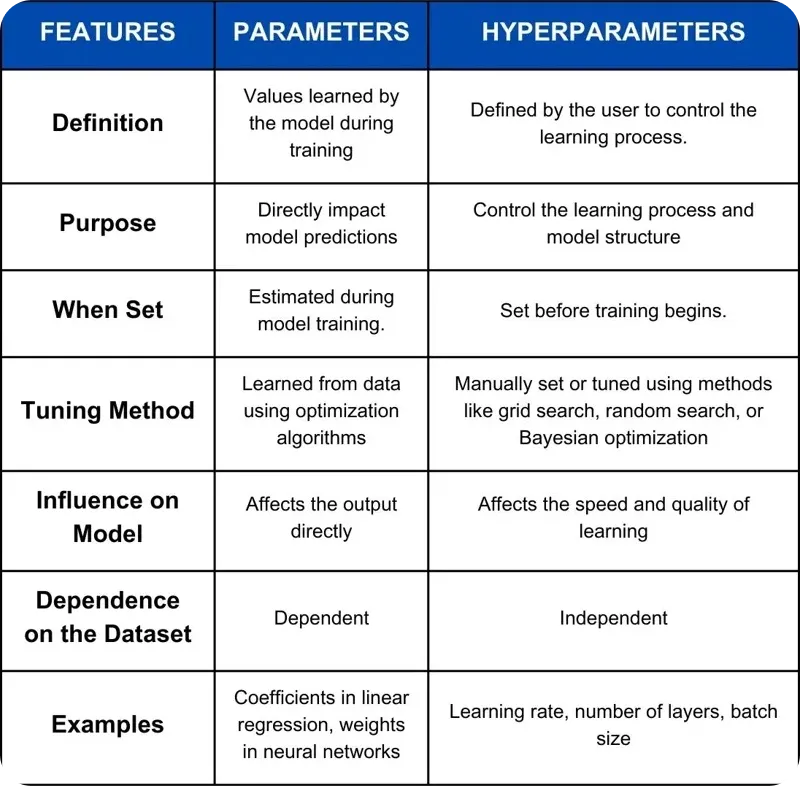
图 2. 比较参数与超参数。
Link to this section为什么模型剪枝在深度学习中很重要#
模型剪枝 是一种通过移除模型中不必要的权重和参数来使其更高效的尺寸缩减技术。在 计算机视觉 中,尤其是深度 神经网络 中,大量的参数(如权重和激活值,即有助于计算最终输出的中间输出)会增加复杂性和计算需求。剪枝有助于通过识别和删除对性能贡献微小的参数来精简模型,从而产生一个更轻量、更高效的模型。
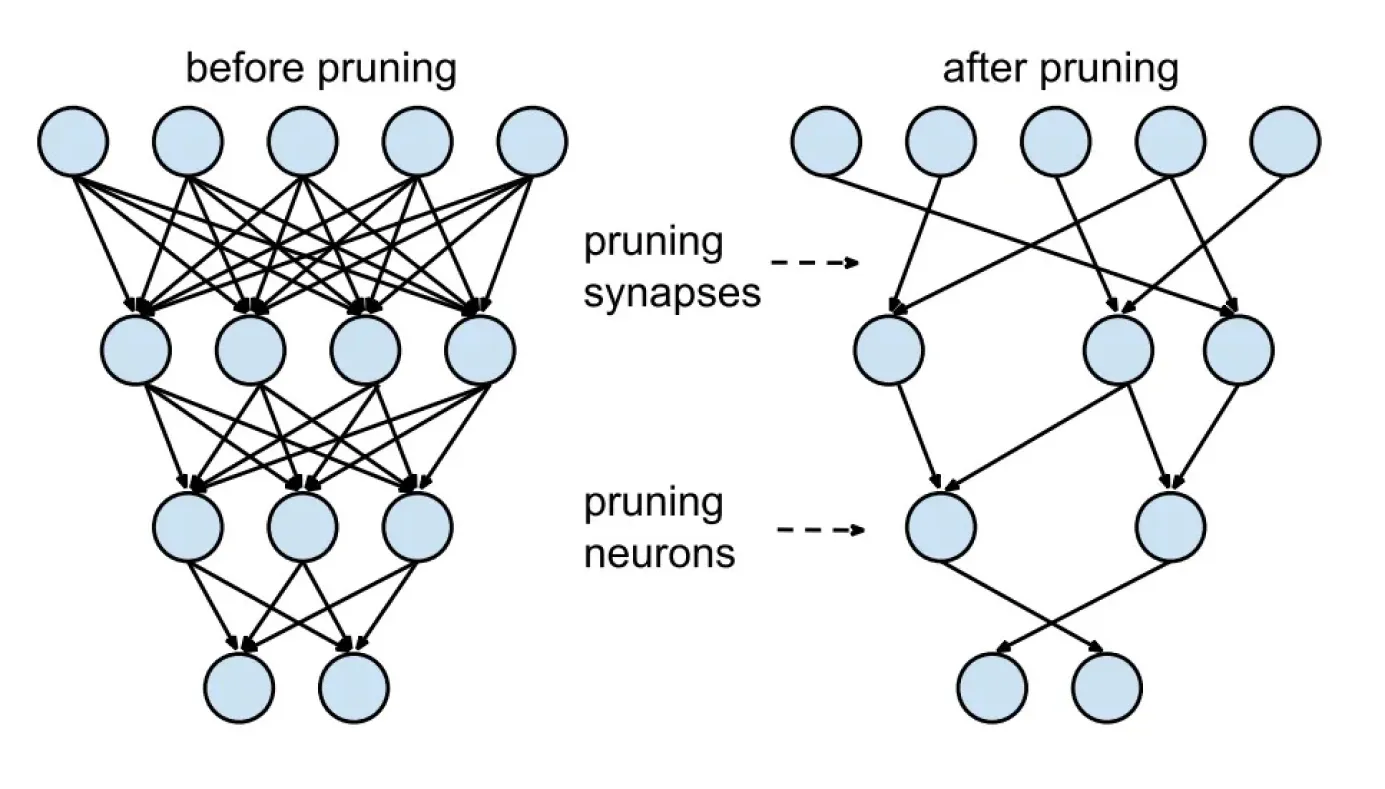
图 3. 模型剪枝前后对比。
模型训练完成后,可以使用基于幅度的剪枝或敏感性分析等技术来评估每个参数的重要性。然后,使用三种主要技术之一来剪枝低重要性参数:权重剪枝、神经元剪枝或结构化剪枝。
权重剪枝会移除对输出影响最小的单个连接。神经元剪枝会移除输出对模型功能贡献很小的整个神经元。结构化剪枝会消除更大的部分,例如卷积滤波器或全连接层中的神经元,从而优化模型的效率。剪枝完成后,模型会重新训练以 微调 其余参数,确保其在简化形式下仍保持高准确性。
Link to this section通过量化减少 AI 模型的延迟#
模型量化 减少了用于表示模型权重和激活值的位数。它通常将高精度的 32 位浮点值转换为较低的精度,例如 16 位或 8 位整数。通过降低位精度,量化显著减小了 模型的大小、内存占用和计算成本。
在 计算机视觉 中,32 位浮点数是标准,但转换为 16 位或 8 位可以提高效率。主要有两种类型的量化:权重量化和激活量化。权重量化降低了模型权重的精度,平衡了尺寸缩减和准确性。激活量化降低了激活值的精度,进一步降低了内存和计算需求。
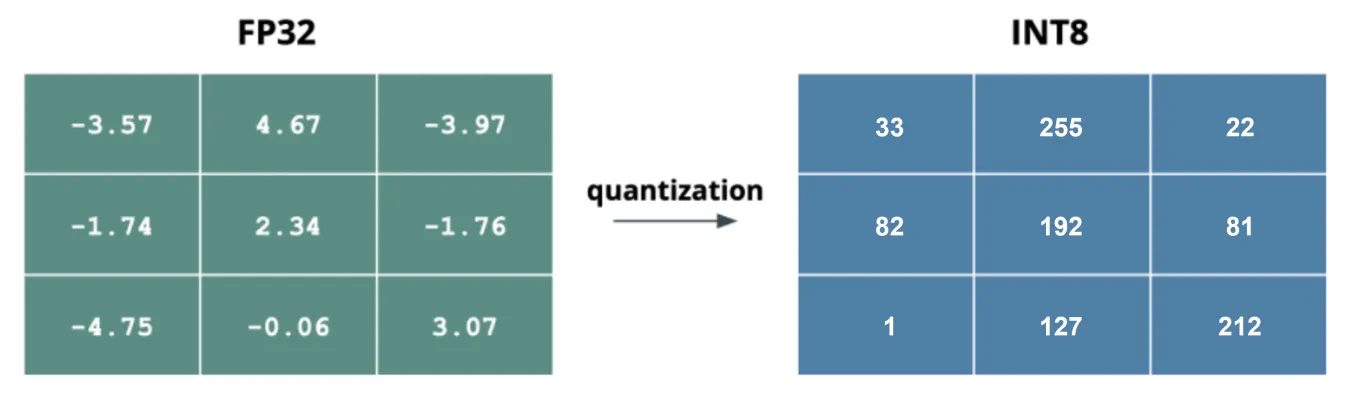
图 4. 从 32 位浮点数到 8 位整数的量化示例。
Link to this section混合精度如何加速 AI 推理#
混合精度 是一种对 神经网络 的不同部分使用不同数值精度的技术。通过将更高精度的值(例如 32 位浮点数)与更低精度的值(例如 16 位或 8 位浮点数)相结合,混合精度使 计算机视觉模型 能够在不牺牲准确性的前提下加快训练速度并减少内存使用。
在训练期间,混合精度是通过在特定层使用较低精度,而在整个网络的其他必要位置保持较高精度来实现的。这是通过类型转换和损失缩放完成的。类型转换根据模型要求在不同精度之间转换数据类型。损失缩放调整降低后的精度以防止数值下溢,确保稳定的训练。混合精度对于大型模型和大规模批处理特别有用。
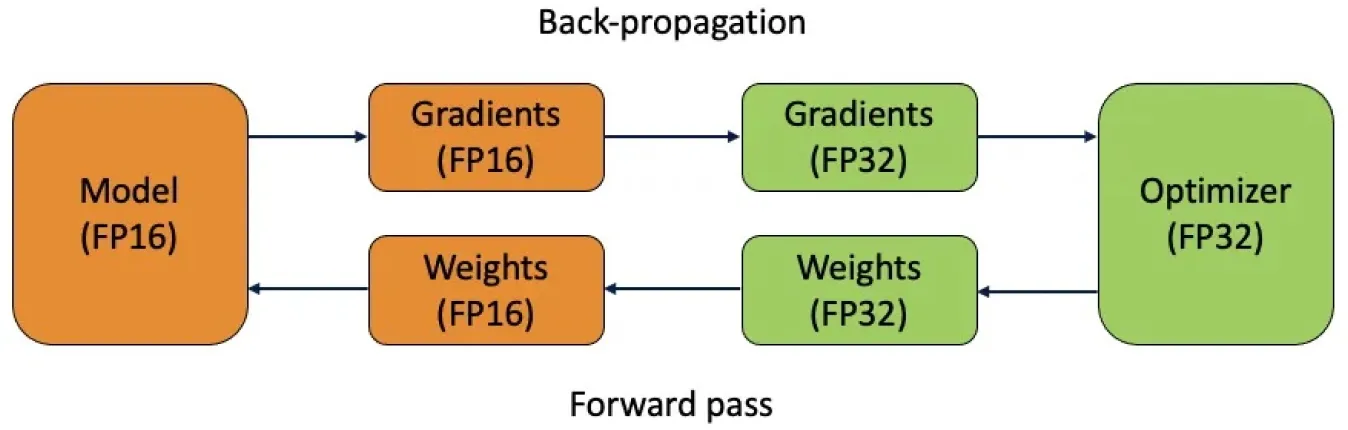
图 5. 混合精度训练同时使用 16 位 (FP16) 和 32 位 (FP32) 浮点类型。
Link to this section平衡模型准确性和效率#
既然我们已经介绍了几种模型优化技术,让我们讨论如何根据你的特定需求决定使用哪一种。选择取决于 硬件、部署环境 的计算和内存限制以及所需的准确性水平等因素。
例如,更小、更快的模型更适合资源有限的移动设备,而更大、更准确的模型则可用于高性能系统。以下是每种技术如何与 不同目标 相结合:
- 剪枝: 这是在不显著影响准确性的情况下减小模型尺寸的理想选择,非常适合移动电话或物联网 (IoT) 设备等资源受限的设备。
- 量化: 这是缩小模型尺寸并加速 推理 的绝佳选择,特别是在内存和处理能力有限的移动设备和 嵌入式系统 上。它适用于对准确性有轻微降低也可接受的应用。
- 混合精度: 该技术专为大规模模型设计,可减少内存使用并加速在支持混合精度操作的 GPU 和 TPU 等硬件上的训练。它通常用于效率至关重要的高性能任务中。
- 超参数调整: 虽然计算密集,但对于需要高准确性的应用(例如 医学影像 或 自动驾驶)来说,它是必不可少的。
Link to this section关键要点#
模型优化是机器学习的重要组成部分,特别是在将 AI 部署到实际应用中时。诸如超参数调整、模型剪枝、量化和混合精度等技术有助于提高计算机视觉模型的性能、效率和资源使用情况。这些优化使模型更快且资源占用更少,非常适合内存和处理能力受限的设备。优化后的模型也更容易在不同平台上进行扩展和部署,从而实现既有效又适应多种用途的 AI 解决方案。
访问 Ultralytics GitHub 存储库 并加入我们的 社区,了解更多关于 AI 在 制造业 和 农业 领域应用的信息。






