SAM 3 살펴보기: Meta AI의 새로운 Segment Anything Model
Meta AI의 새로운 SAM 3(Segment Anything Model)가 실제 이미지와 비디오 전반에서 객체를 얼마나 쉽게 탐지, 세그멘테이션 및 추적하는지 확인해 보세요.

2025년 11월 19일, Meta AI는 SAM 3로도 알려진 Segment Anything Model 3를 발표했습니다. Segment Anything Model의 이 최신 버전은 텍스트 프롬프트, 시각적 프롬프트, 이미지 예시를 사용하여 실제 이미지 및 비디오에서 객체를 감지, 세그멘테이션 및 추적하는 새로운 방법을 도입했습니다.
SAM 3 모델은 SAM 및 SAM 2를 기반으로 구축되었으며 컨셉 세그멘테이션, 오픈 어휘 감지(open vocabulary detection), 실시간 비디오 추적과 같은 새로운 발전과 기능을 제공합니다. 짧은 명사구를 이해하고, 프레임 간 객체를 추적하며, 이전 모델들이 일관되게 처리할 수 없었던 미세하거나 드문 개념을 식별할 수 있습니다.
SAM 3 출시의 일환으로, Meta는 SAM 3D도 도입했습니다. 이 차세대 모델 제품군은 단일 이미지에서 객체, 장면, 전신을 복원하며 Segment Anything 생태계를 3D 이해 영역으로 확장합니다. 이러한 추가 기능은 computer vision, 로봇 공학, 미디어 편집 및 창의적인 워크플로우 전반에 걸쳐 새로운 응용 분야를 열어줍니다.
본 글에서는 SAM 3가 무엇인지, SAM 2와 어떤 점이 다른지, 모델이 어떻게 작동하는지, 그리고 실제 응용 사례에 대해 살펴봅니다. 시작해 보겠습니다!
Link to this sectionSAM 3란 무엇인가? Meta의 Segment Anything Model 3 살펴보기#
SAM 3는 간단한 지침을 기반으로 이미지와 비디오에서 객체를 식별, 분리 및 추적할 수 있는 최첨단 computer vision model입니다. 고정된 레이블 목록에 의존하는 대신 SAM 3는 자연어와 시각적 단서를 이해하므로 모델에 무엇을 찾아야 할지 쉽게 지시할 수 있습니다.
예를 들어, SAM 3를 사용하면 "노란색 스쿨버스" 또는 "줄무늬 고양이"와 같은 짧은 문구를 입력하거나, 객체를 클릭하거나, 이미지에서 예시를 강조 표시할 수 있습니다. 그러면 모델이 일치하는 모든 객체를 감지하고 깔끔한 세그멘테이션 마스크(객체에 속하는 픽셀을 정확히 보여주는 시각적 윤곽선)를 생성합니다. SAM 3는 비디오 프레임 전체에서 해당 객체를 추적하여 움직임에 따라 일관성을 유지할 수도 있습니다.
Link to this sectionSAM 3D로 가능해진 단일 이미지 3D 복원#
Meta AI 발표의 또 다른 흥미로운 부분은 Segment Anything 프로젝트를 3D understanding으로 확장하는 SAM 3D입니다. SAM 3D는 단일 2D 이미지를 사용하여 3차원 공간에서 객체나 인체의 모양, 자세 또는 구조를 복원할 수 있습니다. 즉, 모델은 하나의 시점만 사용할 수 있는 경우에도 사물이 공간을 어떻게 차지하는지 추정할 수 있습니다.
SAM 3D는 두 가지 다른 모델로 출시되었습니다. 기하학적 구조와 텍스처를 갖춘 일상적인 물체를 복원하는 SAM 3D Objects와 단일 이미지에서 인체의 모양과 자세를 추정하는 SAM 3D Body입니다. 두 모델 모두 SAM 3의 세그멘테이션 출력을 사용한 다음 원본 사진 속 객체의 외형 및 위치와 일치하는 3D 표현을 생성합니다.

그림 1. SAM 3D 사용 예시. (출처: Meta AI의 segment anything playground를 사용하여 생성)
Link to this sectionSAM 3: 감지, 세그멘테이션, 추적을 통합하는 새로운 기능#
다음은 감지, 세그멘테이션, 추적을 하나의 통합 모델로 결합하기 위해 SAM 3가 도입한 주요 업데이트 사항입니다:
- 컨셉 세그멘테이션 작업: SAM 및 SAM 2에서 객체 세그멘테이션은 클릭이나 박스와 같은 시각적 프롬프트에 의존했습니다. SAM 3는 짧은 텍스트 문구나 이미지에서의 예시 크롭을 기반으로 객체를 세그멘테이션하는 기능을 추가했습니다. 이는 모델이 각 인스턴스에 대한 클릭 없이 일치하는 모든 인스턴스를 식별할 수 있음을 의미합니다.
- 오픈 어휘 텍스트 프롬프트: 이전 버전과 달리 SAM 3는 짧은 자연어 문구를 해석할 수 있습니다. 이로 인해 고정된 레이블 목록이 필요 없으며 모델이 더 구체적이거나 흔하지 않은 개념을 다룰 수 있게 되었습니다.
- 감지, 세그멘테이션, 추적을 위한 단일 모델: SAM 3는 감지, 세그멘테이션, 추적을 하나의 모델로 통합하여 객체를 찾고, 세그멘테이션 마스크를 생성하고, 비디오 프레임 전체에서 이를 따라가기 위해 별도의 시스템을 사용할 필요가 없습니다. 이는 이미지와 비디오 모두에 대해 더욱 일관되고 간소화된 워크플로우를 생성하며, SAM 2도 일부 추적 기능을 제공했지만 SAM 3는 훨씬 더 강력하고 신뢰할 수 있는 성능을 제공합니다.
- 복잡한 장면에서의 더욱 안정적인 결과: SAM 3는 텍스트, 예시 이미지 및 시각적 프롬프트를 결합할 수 있기 때문에 시각적 클릭에만 의존했던 이전 버전보다 복잡하거나 반복적인 장면을 더 안정적으로 처리할 수 있습니다.
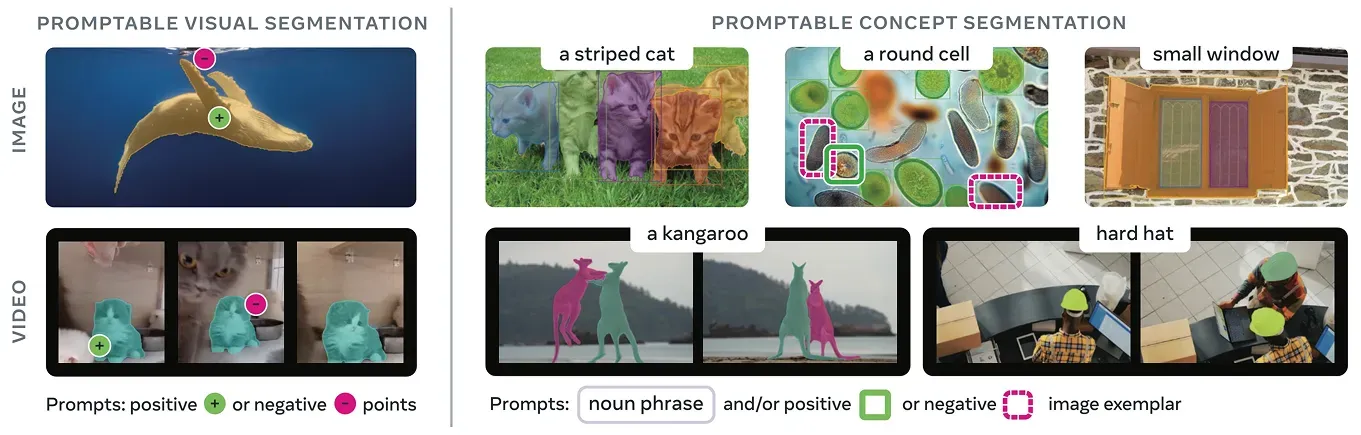
그림 2. SAM 3는 텍스트 또는 이미지 예시를 사용한 컨셉 세그멘테이션을 도입합니다. (출처)
Link to this sectionSAM 3 대 SAM 2 대 SAM 1 비교#
다양한 동물이 있는 사파리 비디오를 시청하고 있고, 코끼리만 감지하여 세그멘테이션하고 싶다고 가정해 보겠습니다. 이 작업은 SAM의 각 버전에서 어떻게 수행될까요?
SAM을 사용하면 세그멘테이션 마스크를 생성하기 위해 각 프레임에서 코끼리를 수동으로 클릭해야 합니다. 추적 기능이 없으므로 새로운 프레임마다 매번 새로운 클릭이 필요합니다.
SAM 2를 사용하면 코끼리를 한 번 클릭하여 마스크를 얻고 모델이 비디오 전체에서 해당 코끼리를 추적하게 할 수 있습니다. 하지만 SAM 2는 "코끼리"와 같은 범주를 스스로 이해하지 못하므로, 여러 코끼리(특정 객체)를 세그멘테이션하려면 여전히 별도의 클릭을 제공해야 합니다.
SAM 3를 사용하면 워크플로우가 훨씬 간단해집니다. "코끼리"를 입력하거나 단일 코끼리 주위에 bbox를 그려 예시를 제공하면 모델이 비디오의 모든 코끼리를 자동으로 찾아 세그멘테이션하고 프레임 전반에서 일관되게 추적합니다. 이전 버전에서 사용된 클릭 및 박스 프롬프트도 계속 지원하지만, 이제는 SAM 및 SAM 2가 수행할 수 없었던 텍스트 프롬프트와 예시 이미지에도 반응할 수 있습니다.
Link to this sectionSAM 3 모델의 작동 방식#
다음으로 SAM 3 모델의 작동 방식과 학습 방법에 대해 자세히 살펴보겠습니다.
Link to this sectionSAM 3 모델 아키텍처 개요#
SAM 3는 컨셉 프롬프트와 시각적 프롬프트를 단일 시스템에서 지원하기 위해 여러 구성 요소를 결합합니다. 핵심적으로 이 모델은 Meta의 통합 오픈 소스 이미지-텍스트 인코더인 Meta Perception Encoder를 사용합니다.
이 인코더는 이미지와 짧은 명사구를 모두 처리할 수 있습니다. 간단히 말해, 이를 통해 SAM 3는 Segment Anything Model의 이전 버전보다 언어와 시각적 특징을 더 효과적으로 연결할 수 있습니다.
이 인코더 위에 SAM 3는 transformer 모델의 DETR 제품군을 기반으로 하는 감지기를 포함합니다. 이 감지기는 이미지 내의 객체를 식별하고 시스템이 사용자의 프롬프트에 해당하는 객체를 결정하도록 돕습니다.
구체적으로 비디오 세그멘테이션을 위해 SAM 3는 SAM 2의 메모리 뱅크와 메모리 인코더를 기반으로 구축된 추적 구성 요소를 사용합니다. 이를 통해 모델은 프레임 간 객체에 대한 정보를 유지하여 시간이 지나도 객체를 재식별하고 추적할 수 있습니다.
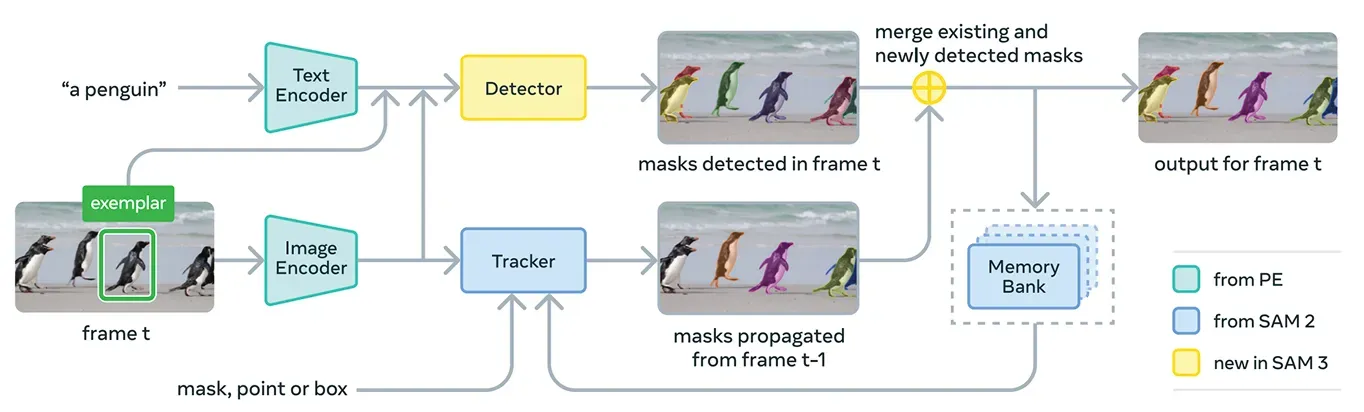
그림 3. 컨셉을 사용하여 모든 것을 세그멘테이션하는 방법 (출처: scontent)
Link to this sectionSegment Anything Model 3 이면의 확장 가능한 데이터 엔진#
SAM 3를 학습시키기 위해 Meta는 현재 인터넷에 존재하는 것보다 훨씬 더 많은 주석 데이터가 필요했습니다. 고품질 세그멘테이션 마스크와 텍스트 레이블은 대규모로 만들기 어렵고, 이미지와 비디오에서 개념의 모든 인스턴스를 완전히 윤곽을 잡는 작업은 느리고 비용이 많이 듭니다.
이를 해결하기 위해 Meta는 SAM 3 자체, 추가 AI 모델, 그리고 인간 주석자가 협력하는 새로운 데이터 엔진을 구축했습니다. 워크플로우는 SAM 3 및 Llama 기반 캡션 모델을 포함한 AI 시스템 파이프라인으로 시작됩니다.
이 시스템들은 대규모 이미지 및 비디오 컬렉션을 스캔하고, 캡션을 생성하며, 해당 캡션을 텍스트 레이블로 변환하고, 초기 세그멘테이션 마스크 후보를 생성합니다. 그런 다음 인간과 AI 주석자가 이러한 후보를 검토합니다.
마스크 품질 확인 및 컨셉 범위 검증과 같은 작업에서 인간의 정확도와 일치하거나 능가하도록 학습된 AI 주석자는 간단한 사례를 걸러냅니다. 인간은 모델이 여전히 어려움을 겪을 수 있는 더 까다로운 예시에만 개입합니다.
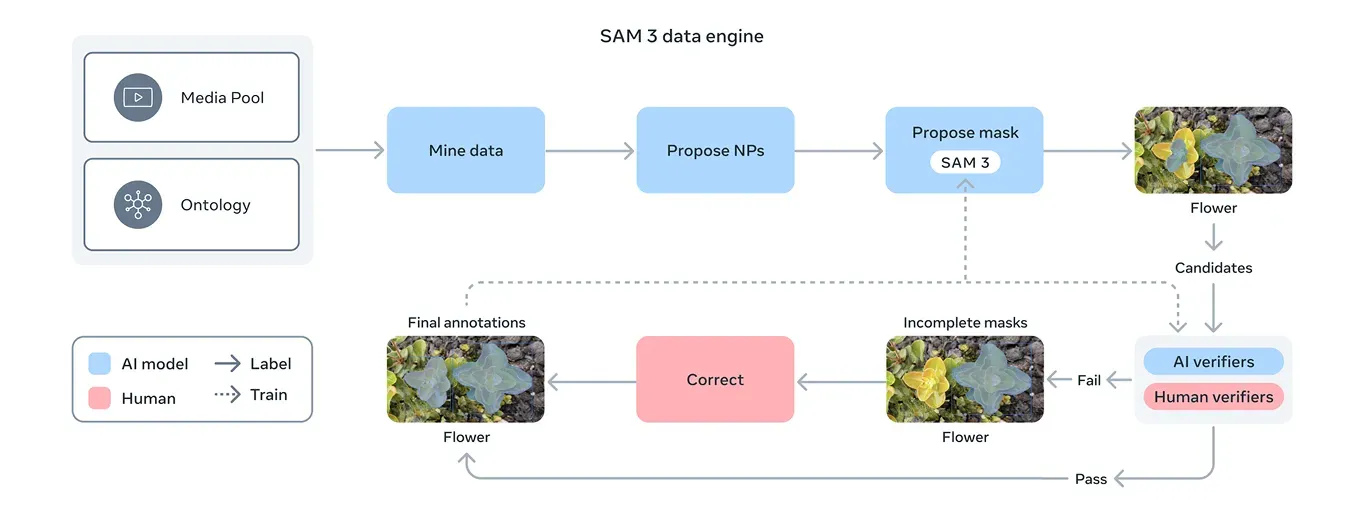
그림 4. SAM 3 데이터 엔진 (출처)
이 접근 방식은 Meta에 주석 속도의 획기적인 향상을 가져왔습니다. AI 주석자가 쉬운 사례를 처리하도록 함으로써 파이프라인은 부정적 프롬프트에서는 약 5배, 미세 조정 도메인의 긍정적 프롬프트에서는 36% 더 빨라졌습니다.
이러한 효율성 덕분에 데이터셋을 400만 개 이상의 고유한 컨셉으로 확장할 수 있었습니다. AI 제안, 인간의 수정, 업데이트된 모델 예측의 지속적인 루프는 시간이 지남에 따라 레이블 품질을 향상시키고 SAM 3가 훨씬 더 광범위한 시각적 및 텍스트 기반 컨셉을 학습하도록 돕습니다.
Link to this sectionSAM 3의 성능 개선#
성능 측면에서 SAM 3는 이전 모델에 비해 분명한 개선을 보여줍니다. 오픈 어휘 컨셉 감지 및 세그멘테이션을 평가하는 Meta의 새로운 SA-Co 벤치마크에서 SAM 3는 이미지와 비디오 모두에서 이전 시스템 성능의 약 두 배를 달성했습니다.
또한 point-to-mask 및 mask-to-masklet과 같은 대화형 시각적 작업에서 SAM 2와 일치하거나 능가합니다. Meta는 제로샷 LVIS(모델이 학습 예시 없이 희귀 범주를 인식해야 하는 경우) 및 객체 계수(객체의 모든 인스턴스가 감지되었는지 측정)와 같은 더 어려운 평가에서 추가적인 성과를 보고했으며, 이는 도메인 전반에 걸친 더 강력한 일반화 능력을 강조합니다.
이러한 정확도 향상 외에도 SAM 3는 효율적이며 H200 GPU에서 약 30밀리초 내에 100개 이상의 감지된 객체가 포함된 이미지를 처리하고, 비디오에서 여러 객체를 추적할 때 실시간에 가까운 속도를 유지합니다.
Link to this sectionSegment Anything Model 3의 응용#
이제 SAM 3를 더 잘 이해했으므로 고급 텍스트 기반 추론부터 과학 연구 및 Meta 자체 제품에 이르기까지 실제 응용 분야에서 어떻게 사용되고 있는지 살펴보겠습니다.
Link to this sectionSAM 3 Agent를 사용한 복잡한 텍스트 쿼리 처리#
SAM 3는 Meta가 SAM 3 Agent라고 부르는 대규모 멀티모달 언어 모델 내의 도구로도 사용할 수 있습니다. SAM 3에 "코끼리"와 같은 짧은 문구를 주는 대신 에이전트는 더 복잡한 질문을 SAM 3가 이해하는 더 작은 프롬프트로 나눌 수 있습니다.
예를 들어, 사용자가 "사진에서 말을 제어하고 안내하는 데 사용되는 객체는 무엇인가요?"라고 물으면 에이전트는 다양한 명사구를 시도하여 SAM 3에 보내고 어떤 마스크가 적절한지 확인합니다. 올바른 객체를 찾을 때까지 계속 정교화합니다.
특별한 추론 데이터셋에서 학습되지 않았음에도 SAM 3 Agent는 ReasonSeg 및 OmniLabel과 같이 복잡한 텍스트 쿼리를 위해 설계된 벤치마크에서 좋은 성능을 보입니다. 이는 SAM 3가 언어 이해와 미세한 시각적 세그멘테이션이 모두 필요한 시스템을 지원할 수 있음을 보여줍니다.
Link to this sectionSAM 3의 과학 및 보존 응용 사례#
흥미롭게도 SAM 3는 이미 상세한 시각적 레이블이 중요한 연구 환경에서 사용되고 있습니다. Meta는 Conservation X Labs 및 Osa Conservation과 협력하여 10,000개 이상의 카메라 트랩 비디오가 포함된 공공 야생 동물 모니터링 데이터셋인 SA-FARI를 구축했습니다.
모든 프레임의 모든 동물은 박스와 세그멘테이션 마스크로 레이블이 지정되며, 이는 수동으로 주석을 달 경우 매우 시간이 많이 걸리는 작업입니다. 마찬가지로 해양 연구에서 SAM 3는 FathomNet 및 MBARI와 함께 underwater imagery에 대한 인스턴스 세그멘테이션 마스크를 생성하고 새로운 평가 벤치마크를 지원하는 데 사용되고 있습니다.
이러한 데이터셋은 과학자들이 비디오 영상을 더 효율적으로 분석하고 대규모로 추적하기 어려운 동물과 서식지를 연구하는 데 도움을 줍니다. 연구자들은 이러한 자원을 사용하여 종 식별, 행동 분석 및 자동화된 생태 모니터링을 위한 자체 모델을 구축할 수도 있습니다.
Link to this sectionMeta가 자사 제품 전반에 SAM 3를 배포하는 방법#
연구 용도 외에도 SAM 3는 Meta의 소비자 제품 전반에서 새로운 기능과 사용 사례를 강화하고 있습니다. 이미 통합되고 있는 몇 가지 방법을 소개합니다:
- Instagram 편집: 제작자는 수동으로 프레임별 작업을 수행하지 않고도 비디오의 특정 인물이나 객체에 효과를 적용할 수 있습니다.
- Meta AI 앱 및 웹상의 meta.ai: SAM 3는 이미지와 비디오를 수정, 개선 및 리믹스하기 위한 새로운 도구를 지원합니다.
- Facebook Marketplace의 "View in Room": SAM 3는 SAM 3D와 함께 작동하여 사람들이 단일 사진을 사용하여 집에서 가구나 장식을 미리 볼 수 있도록 합니다.
- Aria Gen 2 research glasses: Segment Anything Model 3는 1인칭 시점에서 손과 객체를 세그멘테이션하고 추적하여 AR(증강 현실), 로봇 공학 및 상황 인식 AI 연구를 지원합니다.
Link to this section핵심 요약#
SAM 3는 세그멘테이션을 향한 흥미로운 도약입니다. 컨셉 세그멘테이션, 오픈 어휘 텍스트 프롬프트 및 향상된 추적 기능을 도입했습니다. 이미지와 비디오 모두에서 눈에 띄게 강력해진 성능과 SAM 3D의 추가로 인해 이 모델 제품군은 비전 AI, 창의적 도구, 과학 연구 및 실제 제품을 위한 새로운 가능성을 열어줍니다.
우리 커뮤니티에 가입하고 GitHub 저장소를 탐색하여 AI에 대해 더 알아보세요. 나만의 비전 AI 프로젝트를 구축하려면 라이선스 옵션을 확인하세요. 솔루션 페이지를 방문하여 의료 분야의 AI 및 소매업의 비전 AI와 같은 응용 분야에 대해 더 자세히 알아보세요.






