Come addestrare, convalidare, prevedere, esportare e testare con i modelli Ultralytics YOLO
Impara come addestrare, convalidare, prevedere, esportare e testare con i modelli Ultralytics YOLO!

Immergiamoci nel mondo di Ultralytics ed esploriamo le diverse modalità disponibili per i vari modelli YOLO. Che tu stia addestrando modelli personalizzati di object detection o lavorando sulla segmentation, comprendere queste modalità è un passo fondamentale. Iniziamo subito!
Attraverso la documentazione di Ultralytics, troverai diverse modes che puoi utilizzare per i tuoi modelli, che si tratti di train, validate, predict, export, benchmark o track. Ciascuna di queste modalità ha uno scopo unico e ti aiuta a ottimizzare le prestazioni e il deployment del tuo modello.
Link to this sectionModalità Train#
Per prima cosa, esaminiamo la modalità train. È qui che costruisci e perfezioni il tuo modello. Puoi trovare istruzioni dettagliate e video guides nella documentazione, rendendo semplice iniziare ad addestrare i tuoi modelli personalizzati.
L'addestramento del modello prevede di fornire a un modello un nuovo dataset, consentendogli di apprendere vari pattern. Una volta addestrato, il modello può essere utilizzato in tempo reale per rilevare nuovi oggetti su cui è stato addestrato. Prima di iniziare il processo di addestramento, è essenziale annotare il tuo dataset in formato YOLO.
Link to this sectionModalità Validate#
Successivamente, approfondiamo la modalità validate. La validazione è essenziale per regolare gli iperparametri e garantire che il tuo modello funzioni bene. Ultralytics offre una varietà di opzioni di validazione, incluse impostazioni automatizzate, supporto multi-metrica e compatibilità con la Python API. Puoi anche eseguire la validazione direttamente tramite la command line interface (CLI) con il comando qui sotto.
Link to this sectionPerché validare?#
La validazione è fondamentale per:
- Precision: garantire che il tuo modello rilevi gli oggetti in modo accurato.
- Convenience: semplificare il processo di validazione.
- Flexibility: offrire molteplici metodi di validazione.
- Hyperparameter Tuning: ottimizzare il tuo modello per prestazioni migliori.
Ultralytics fornisce anche esempi utente che puoi copiare e incollare nei tuoi script Python. Questi esempi includono parametri come la dimensione dell'immagine, la batch size, il dispositivo (CPU o GPU) e l'intersection over union (IoU).
Link to this sectionModalità Predict#
Una volta che il tuo modello è stato addestrato e validato, è tempo di fare previsioni. La modalità Predict ti consente di eseguire l'inferenza su nuovi dati e vedere il tuo modello in azione. Questa modalità è perfetta per testare le prestazioni del tuo modello su dati reali. Con il frammento di codice Python qui sotto sarai in grado di eseguire previsioni sulle tue immagini!
Link to this sectionModalità Export#
Dopo aver validato e previsto, potresti voler distribuire il tuo modello. La modalità export ti consente di convertire il tuo modello in vari formati, come ONNX o TensorRT, rendendo più semplice la distribuzione su diverse piattaforme.
Link to this sectionModalità Benchmark#
Infine, abbiamo la modalità benchmark. Il benchmarking è essenziale per valutare le prestazioni del tuo modello in vari scenari. Questa modalità ti aiuta a prendere decisioni informate su allocazione delle risorse, ottimizzazione ed efficienza dei costi.
Link to this sectionCome effettuare il benchmarking#
Per eseguire un benchmark, puoi utilizzare gli esempi utente forniti nella documentazione. Questi esempi coprono metriche chiave e formati di esportazione, inclusi ONNX e TensorRT. Puoi anche specificare parametri come la quantizzazione di interi (INT8) o la quantizzazione a virgola mobile (FP16) per vedere come le diverse impostazioni influiscono sulle prestazioni.
Link to this sectionEsempio di benchmarking nel mondo reale#
Diamo un'occhiata a un esempio reale di benchmarking. Quando testiamo il nostro modello PyTorch, notiamo una velocità di inferenza di 68 millisecondi su una GPU RTX 3070. Dopo l'esportazione in TorchScript, la velocità di inferenza scende a 4 millisecondi, mostrando un miglioramento significativo.
Per i modelli ONNX, raggiungiamo una velocità di inferenza di 21 millisecondi. Testando questi modelli su una CPU (un Intel i9 di tredicesima generazione), vediamo risultati variabili. TorchScript funziona a 115 millisecondi, mentre ONNX ha prestazioni migliori a 84 millisecondi. Infine, OpenVINO ottimizzato per l'hardware Intel raggiunge ben 23 millisecondi.
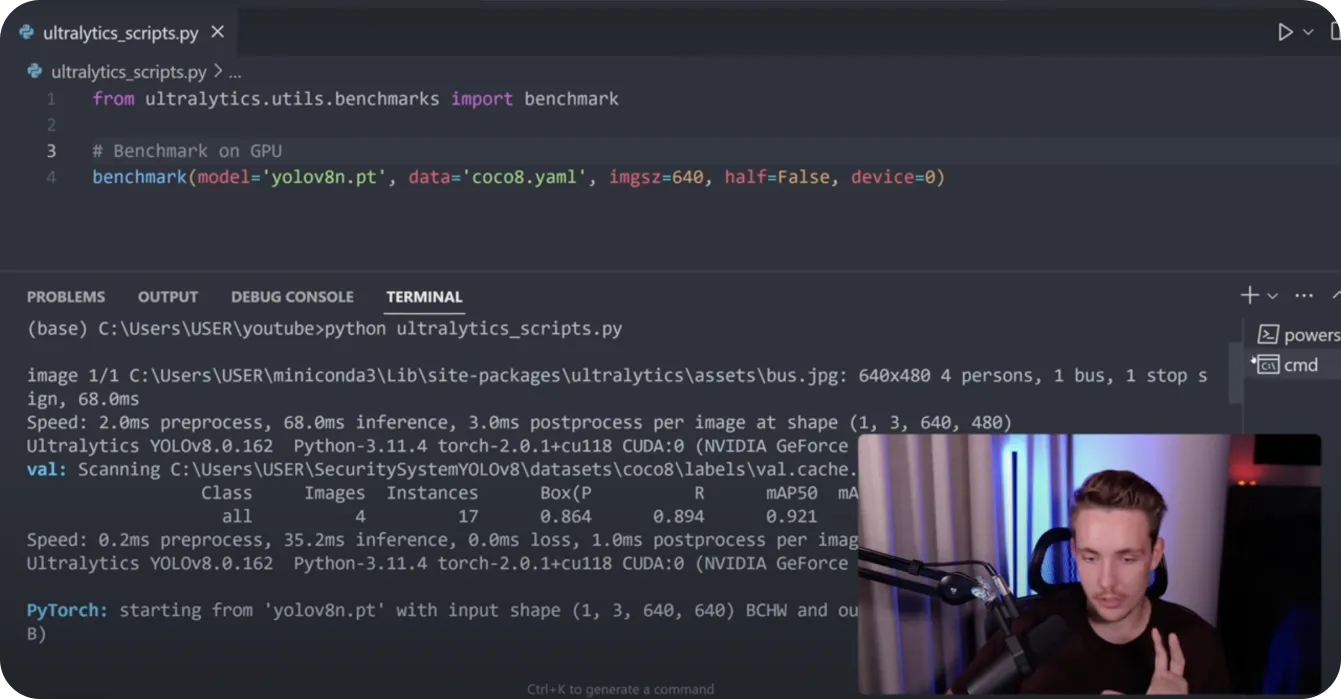
Fig 1. Nicolai Nielsen mostra come eseguire il benchmarking con i modelli Ultralytics YOLO.
Link to this sectionL'importanza del benchmarking#
Il benchmarking dimostra come diversi hardware e formati di esportazione possano influire sulle prestazioni del tuo modello. È fondamentale testare i tuoi modelli, specialmente se prevedi di distribuirli su hardware personalizzato o dispositivi edge. Questo processo garantisce che il tuo modello sia ottimizzato per l'ambiente di destinazione, fornendo le migliori prestazioni possibili.
Link to this sectionConclusione#
In sintesi, le modalità nella documentazione di Ultralytics sono strumenti potenti per addestrare, validare, prevedere, esportare e valutare i tuoi modelli YOLO. Ogni modalità svolge un ruolo vitale nell'ottimizzazione del tuo modello e nella sua preparazione per il deployment.
Non dimenticare di esplorare e unirti alla nostra community e di provare i frammenti di codice forniti nei tuoi progetti. Con questi strumenti, puoi creare modelli ad alte prestazioni e garantire che funzionino in modo efficiente in qualsiasi ambiente.






