Popular open-source OCR models and how they work
Join us as we explore popular OCR models, how they convert images to text, and their role in AI and computer vision applications.

For a visual walkthrough of the concepts covered in this article, watch the video below.
Many businesses and digital systems rely on information from documents, like scanned invoices, identification cards, or handwritten forms. But when that information is stored as an image, it’s hard for computers to search, extract, or use it for various tasks.
However, with tools like computer vision, a field of AI that enables machines to interpret and understand visual information, turning images into text is becoming much easier. Optical Character Recognition (OCR), in particular, is a computer vision technology that can be used to detect and extract text.
OCR models are trained to recognize text in a variety of formats and convert it into editable, searchable data. They are widely used in document automation, identity verification, and real-time scanning systems.
In this article, we’ll explore how OCR models work, popular open-source models, where they are used, common applications, and key considerations for real-world use.
Link to this sectionWhat is OCR?#
OCR models are designed to help machines read text from visual sources, similar to how we read printed or handwritten text. These models take inputs like scanned documents, images, or photos of handwritten notes and turn them into digital text that can be searched, edited, or used in software systems.
While earlier OCR systems followed a strict template, modern OCR models use deep learning to recognize text. They can easily recognize different kinds of text fonts, languages, and even messy handwriting while handling low-quality images. These advances have made models for OCR a key part of automation in text-heavy industries like finance, healthcare, logistics, and government services.
While OCR models are great for images where the text is clear and structured, they can face challenges when text appears alongside complex visuals or within dynamic scenes. In these cases, OCR models can be used alongside computer vision models like Ultralytics YOLO11.
YOLO11 can detect specific objects in an image, such as signs, documents, or labels, helping to locate the text regions before OCR is used to extract the actual content.
For example, in autonomous vehicles, YOLO11 can detect a stop sign, and then OCR can read the text, allowing the system to accurately interpret both the object and its meaning.
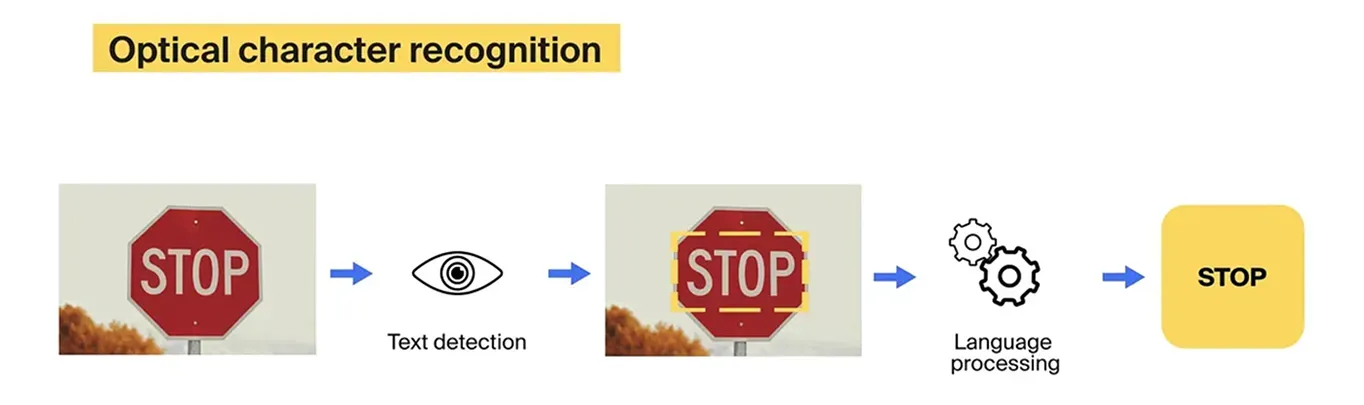
Fig 1. An example of using OCR (source).
Link to this sectionAn overview of how OCR models work#
Now that we’ve covered what OCR is, let’s take a closer look at how OCR models actually work.
Before an OCR model is used to read and extract text from an image, the image is usually put through two important steps: preprocessing and object detection.
First, the image is cleaned and enhanced through preprocessing. Basic image processing techniques, like sharpening, noise reduction, and adjusting brightness or contrast, are applied to improve the overall quality of the image and make the text easier to detect.
Next, computer vision tasks like object detection are used. In this step, specific objects of interest with text are located - such as license plates, street signs, forms, or ID cards. By identifying these objects, the system isolates the areas where meaningful text is located, preparing them for recognition.
Only after these steps does the OCR model begin its work. First, it takes the detected regions and breaks them down into smaller parts - identifying individual characters, words, or lines of text.
Using deep learning techniques, the model analyzes the shapes, patterns, and spacing of the letters, compares them against what it has learned during training, and predicts the most likely characters. It then reconstructs the recognized characters into coherent text for further processing.
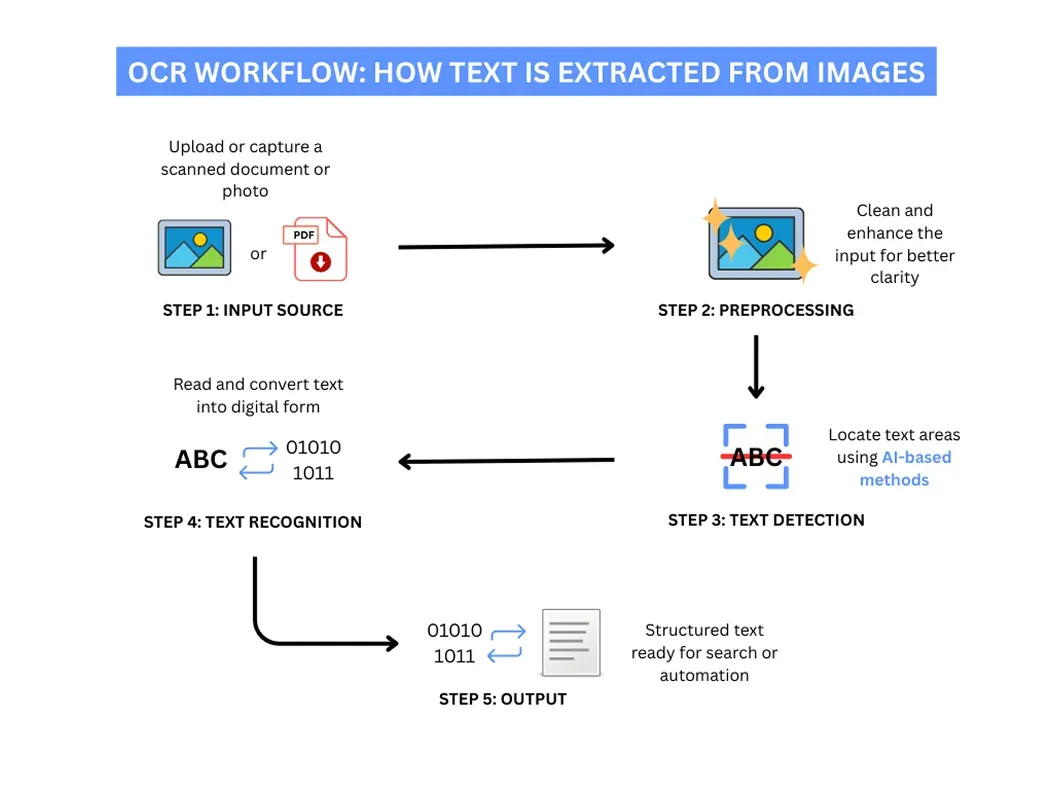
Fig 2. Understanding how OCR works. Image by author.
Link to this sectionPopular open-source OCR models#
When you’re building a computer vision application that involves text extraction, choosing the right OCR model comes down to factors like accuracy, language support, and how easily it fits into real-world systems.
Nowadays, many open-source models provide the flexibility, strong community support, and reliable performance that developers need. Let’s walk through some of the most popular options and what makes them stand out.
Link to this sectionTesseract OCR#
Tesseract is one of the most widely used open-source OCR models available today. It was initially developed at Hewlett-Packard Laboratories in Bristol, England, and Greeley, Colorado, between 1985 and 1994. In 2005, HP released Tesseract as open-source software, and since 2006, it has been maintained by Google, with ongoing contributions from the open-source community.
One of Tesseract’s key features is its ability to handle over 100 languages, making it a reliable choice for multilingual projects. Continuous improvements have enhanced its dependability in reading printed text, especially in structured documents like forms and reports.

Fig 3. Text recognition using Tesseract OCR (source).
Tesseract is commonly used in projects that involve scanning invoices, archiving paperwork, or extracting text from documents with standard layouts. It performs best when document quality is good, and the layout doesn’t vary significantly.
Link to this sectionEasyOCR#
Similarly, EasyOCR is a Python-based, open-source OCR library developed by Jaided AI. It supports over 80 languages, including Latin, Chinese, Arabic, and Cyrillic scripts, making it a versatile tool for multilingual text recognition.
Designed to handle both printed and handwritten text, EasyOCR works well with documents that vary in layout, font, or structure. This flexibility makes it a great option for extracting text from diverse sources such as receipts, street signs, and forms with mixed-language inputs.
Built on PyTorch, EasyOCR leverages deep learning techniques for accurate text detection and recognition. It runs efficiently on both CPUs and GPUs, allowing it to scale depending on the task - whether processing a few images locally or handling large batches of files on more powerful systems.
As an open-source tool, EasyOCR benefits from regular updates and community-driven improvements, helping it stay current and adaptable to a wide range of real-world OCR needs.
Link to this sectionPaddleOCR#
PaddleOCR is a high-performance OCR toolkit developed by Baidu that combines text detection and recognition in one streamlined pipeline. With support for 80 languages, it can handle complex documents such as receipts, tables, and forms.
What makes PaddleOCR different is that it’s built on the PaddlePaddle deep learning framework. The PaddlePaddle framework was designed for easy, reliable, and scalable AI model development and deployment. Also, PaddleOCR delivers high accuracy even on low-quality or cluttered images, making it a good choice for real-world OCR tasks where precision and reliability are key.
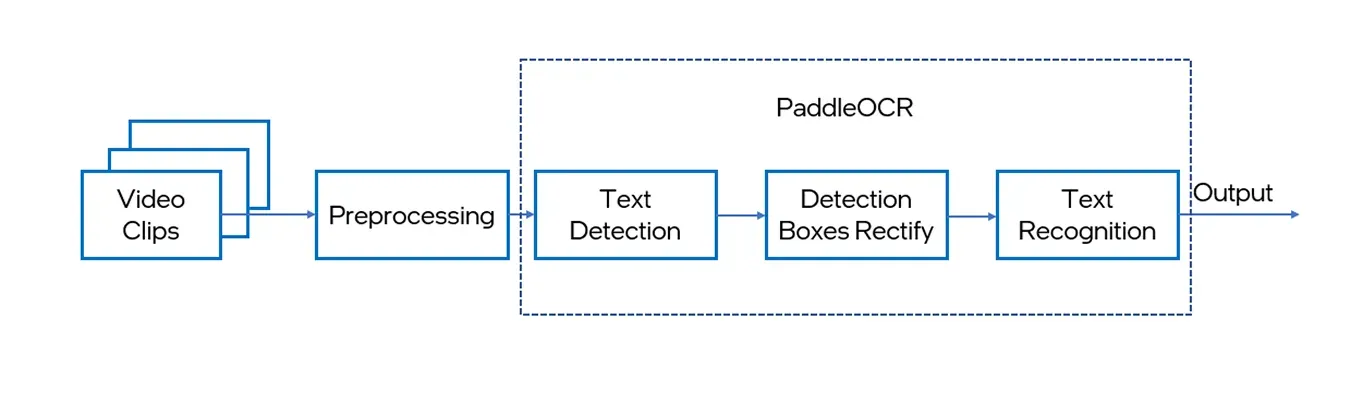
Fig 4. PaddleOCR’s workflow (source).
On top of this, PaddleOCR is highly modular, letting developers customize their pipelines by picking specific detection, recognition, and classification components. With well-documented Python APIs and strong community support, it’s a flexible, production-ready solution for a wide range of OCR applications.
Link to this sectionOther popular open-source OCR models#
Here are some other open-source OCR models that are commonly used:
- MMOCR: Designed for more complex projects, MMOCR can detect text and also understand how it’s arranged on a page. It's ideal for working with tables, multi-column layouts, and other visually complex documents.
- TrOCR: Built on transformers, a type of deep learning model especially good at understanding sequences of text, TrOCR excels at handling longer passages and messy, unstructured layouts. It’s a reliable choice when content reads like continuous language rather than isolated labels.
Link to this sectionCommon applications of OCR models#
As OCR technology becomes more advanced, its role has expanded far beyond basic digitization. In fact, OCR models are now being adopted across various industries that depend on textual information. Here is a glimpse at some ways in which OCR is being applied in real-world systems today:
- Legal industry and e-discovery: Law firms apply OCR to scan thousands of pages of legal documents, making contracts, court filings, and evidence searchable for quicker discovery and analysis.
- Healthcare: Hospitals are using OCR models to digitize patient records, interpret handwritten prescriptions, and manage lab reports efficiently. This streamlines administrative tasks and improves accuracy across medical workflows.
- Historical preservation: Museums, libraries, and archives apply OCR to digitize old books, manuscripts, and newspapers, preserving valuable cultural heritage and making it searchable for researchers.
- ID and passport verification: Many digital onboarding and travel systems rely on OCR to extract key data from government-issued documents. Faster identity checks and fewer manual entry errors lead to smoother user experiences and higher security.

Fig 5. OCR-based scanner for passport identity verification. (source).
Link to this sectionPros and cons of OCR models#
OCR models have come a long way since they were first conceived in the 1950s. They are now more accessible, accurate, and adaptable to different content and platforms. Here are key strengths that today’s OCR models bring to the table:
- Accessibility improvements: OCR helps make content more accessible by converting printed material into formats readable by screen readers for visually impaired users.
- Enhances machine learning pipelines: It acts as a bridge that turns unstructured visual data into structured text, making it usable for machine learning models downstream.
- Template-free extraction: Advanced OCR no longer requires rigid templates — it can intelligently extract information even when layouts vary between documents.
Despite its advantages, OCR models still have a few challenges, especially when the input isn’t perfect. Here are some common limitations to keep in mind:
- Sensitive to image quality: OCR works best with clear images; blurry or dark photos can affect results.
- Struggles with certain handwriting or fonts: Fancy or messy writing may still confuse even the best models.
- Post-processing still needed: Even with high accuracy, OCR outputs often need some human review or clean-up, especially for critical documents.
Link to this sectionKey takeaways#
OCR enables computers to read text from images, making it possible to use that information in digital systems. It plays a key role in processing documents, signs, and handwritten notes and is impactful in areas where speed and accuracy are critical.
OCR models also often work alongside models like Ultralytics YOLO11, which can detect objects within images. Together, they enable systems to understand what is written and where it appears. As these technologies continue to improve, OCR is becoming a core part of how machines interpret and interact with the world.
Curious about vision AI? Visit our GitHub repository and connect with our community to keep exploring. Learn about innovations like AI in self-driving cars and vision AI in agriculture on our solutions pages. Check out our licensing options and get started on a computer vision project!






