Comprendere il few-shot, zero-shot e transfer learning
Esplora le differenze tra few-shot learning, zero-shot learning e transfer learning nella computer vision e come questi paradigmi plasmano l'addestramento dei modelli AI.

I sistemi di intelligenza artificiale (IA) possono gestire compiti complessi come il riconoscimento facciale, la classificazione di immagini e la guida di veicoli con un input umano minimo. Lo fanno studiando i dati, riconoscendo schemi e usando tali schemi per effettuare previsioni o decisioni. Con l'avanzare dell'IA, stiamo assistendo a modi sempre più sofisticati in cui i modelli di IA possono apprendere, adattarsi ed eseguire compiti con notevole efficienza.
Ad esempio, la computer vision è una branca dell'IA che si concentra sul consentire alle macchine di interpretare e comprendere le informazioni visive dal mondo. Lo sviluppo tradizionale dei modelli di computer vision si basa pesantemente su ampi dataset annotati per l'addestramento. La raccolta e l'etichettatura di tali dati può richiedere tempo ed essere costosa.
Per gestire queste sfide, i ricercatori hanno introdotto approcci innovativi come il few-shot learning (FSL), che apprende da esempi limitati; lo zero-shot learning (ZSL), che identifica oggetti mai visti prima; e il transfer learning (TL), che applica le conoscenze dei modelli pre-addestrati a nuovi compiti.
In questo articolo esploreremo come funzionano questi paradigmi di apprendimento, evidenzieremo le loro differenze chiave e daremo uno sguardo alle applicazioni nel mondo reale. Iniziamo!
Link to this sectionUna panoramica sui paradigmi di apprendimento#
Esploriamo cosa sono il few-shot learning, lo zero-shot learning e il transfer learning rispetto alla computer vision e come funzionano.
Link to this sectionFew-shot learning#
Il few-shot learning è un metodo in cui i sistemi imparano a riconoscere nuovi oggetti usando solo un piccolo numero di esempi. Ad esempio, se mostri a un modello alcune immagini di un pinguino, un pellicano e una pulcinella di mare (questo piccolo gruppo è chiamato "support set"), imparerà che aspetto hanno questi uccelli.
In seguito, se mostri al modello una nuova immagine, come quella di un pinguino, la confronterà con quelle nel suo support set e sceglierà la corrispondenza più vicina. Quando raccogliere una grande quantità di dati è difficile, questo metodo è vantaggioso perché il sistema può comunque imparare e adattarsi con solo pochi esempi.
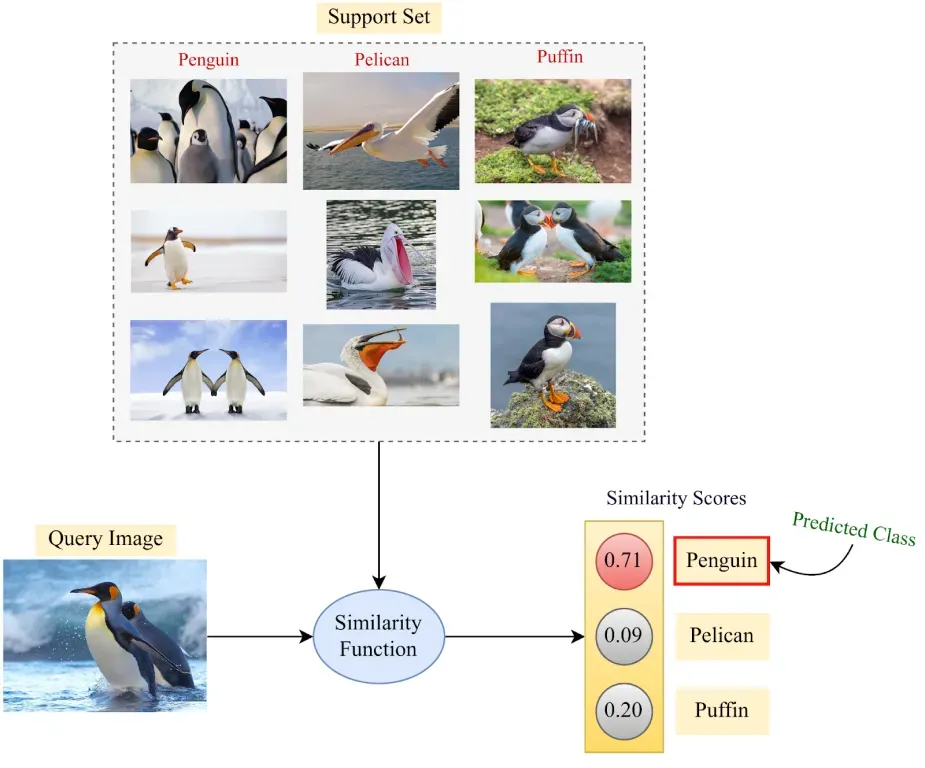
Fig 1. Una panoramica su come funziona il few-shot learning.
Link to this sectionZero-shot learning#
Lo zero-shot learning è un modo per le macchine di riconoscere cose che non hanno mai visto prima senza averne bisogno di esempi. Utilizza informazioni semantiche, come descrizioni, per aiutare a creare connessioni.
Ad esempio, se una macchina ha imparato a conoscere animali come gatti, leoni e cavalli comprendendo caratteristiche come "piccolo e soffice", "grande felino selvatico" o "muso lungo", può usare questa conoscenza per identificare un nuovo animale, come una tigre. Anche se non ha mai visto una tigre prima, può usare una descrizione come "un animale simile a un leone con strisce scure" per identificarla correttamente. Questo rende più facile per le macchine imparare e adattarsi senza aver bisogno di molti esempi.
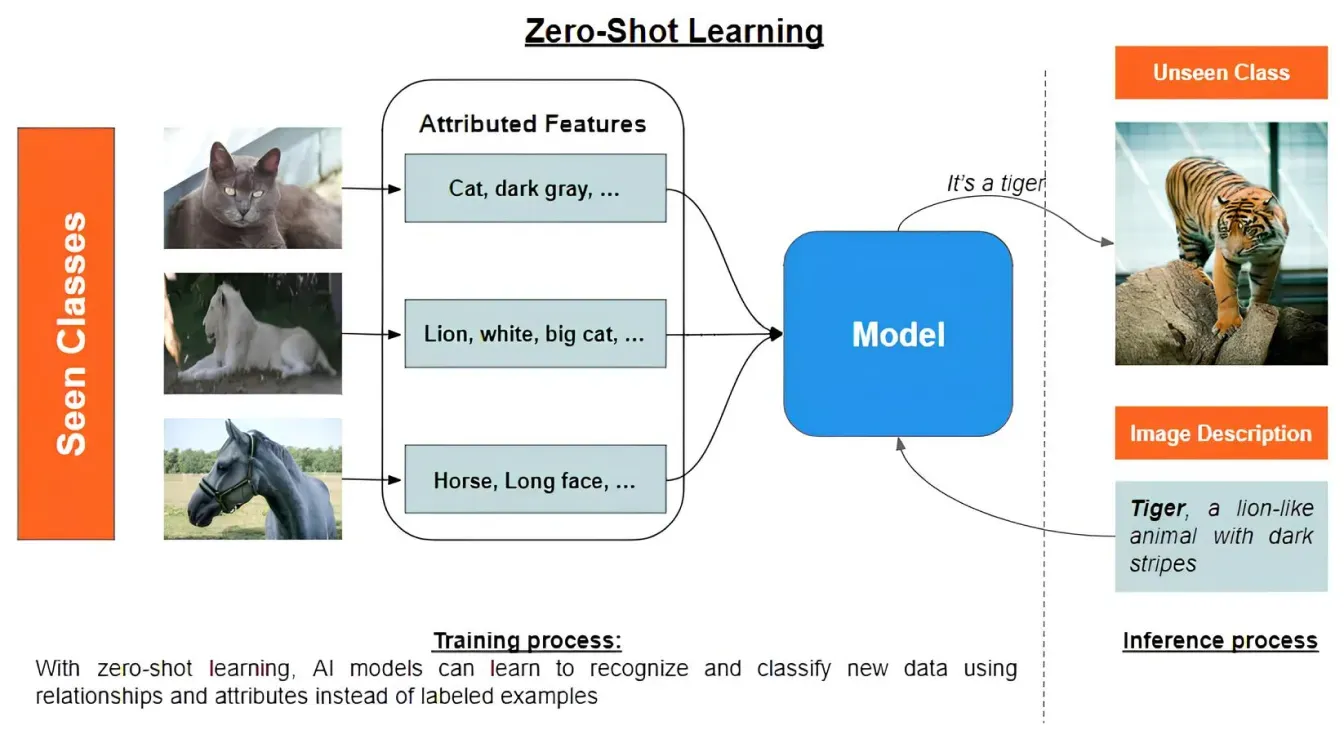
Fig 2. Lo zero-shot learning identifica nuovi oggetti usando le descrizioni.
Link to this sectionTransfer learning#
Il transfer learning è un paradigma di apprendimento in cui un modello usa ciò che ha imparato da un compito per aiutare a risolverne uno simile e nuovo. Questa tecnica è particolarmente utile quando si tratta di compiti di computer vision come il rilevamento di oggetti, la classificazione di immagini e il riconoscimento di pattern.
Ad esempio, nella computer vision, un modello pre-addestrato può riconoscere oggetti generici, come gli animali, e poi essere perfezionato tramite il transfer learning per identificarne di specifici, come diverse razze di cani. Riutilizzando la conoscenza dei compiti precedenti, il transfer learning rende più facile addestrare modelli di computer vision su dataset più piccoli, risparmiando tempo e fatica.
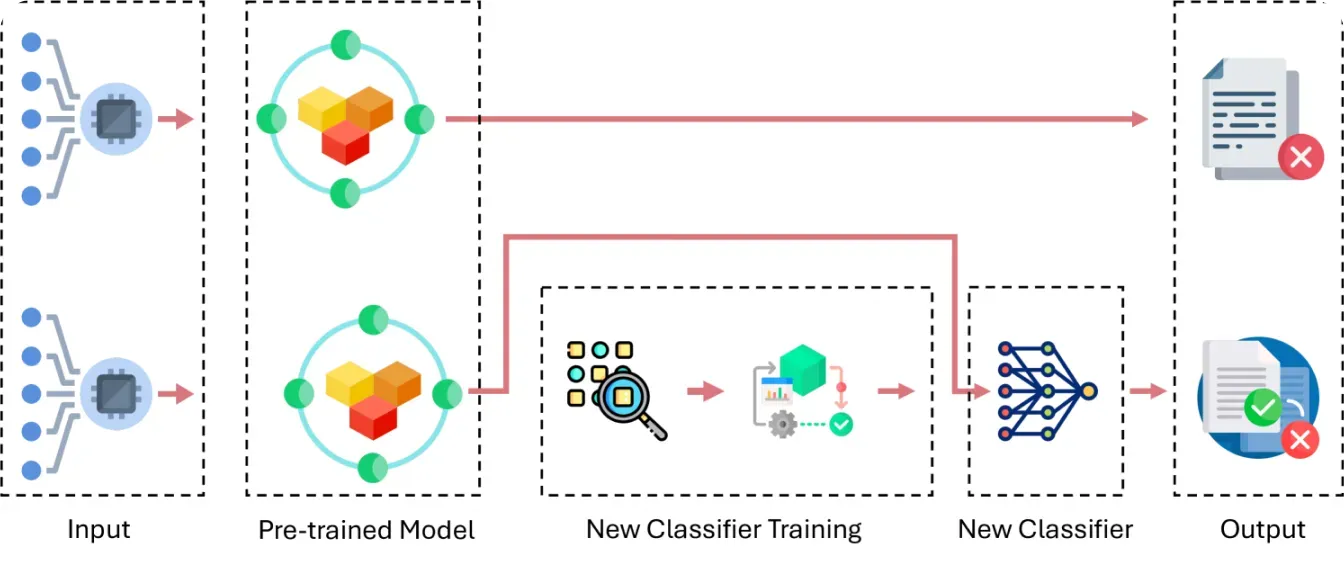
Fig 3. Una panoramica su come funziona il transfer learning.
Potresti chiederti quali modelli supportino il transfer learning. Ultralytics YOLO11 è un ottimo esempio di modello di computer vision in grado di farlo. È un modello di object detection all'avanguardia che viene prima pre-addestrato su un dataset ampio e generale. Dopodiché, può essere perfezionato e addestrato in modo personalizzato su un dataset più piccolo e specializzato per compiti specifici.
Link to this sectionConfronto tra i paradigmi di apprendimento#
Ora che abbiamo parlato di few-shot learning, zero-shot learning e transfer learning, confrontiamoli per vedere in cosa differiscono.
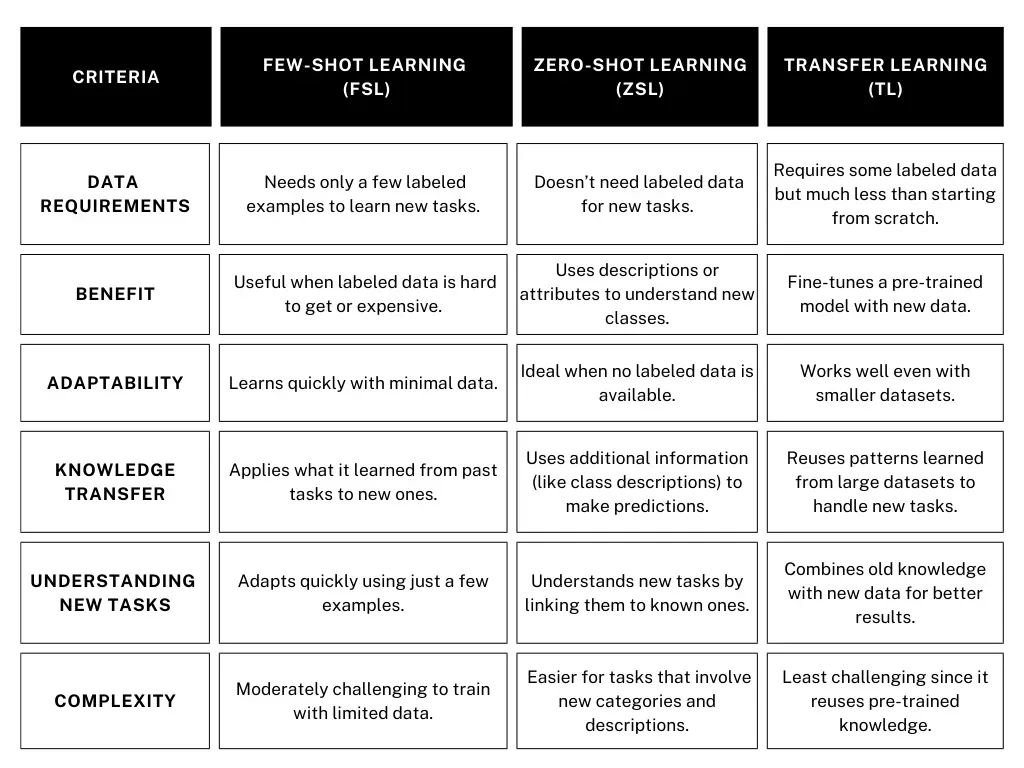
Fig 4. Differenze chiave tra few-shot, zero-shot e transfer learning. Immagine dell'autore.
Il few-shot learning è utile quando hai solo una piccola quantità di dati etichettati. Rende possibile a un modello di IA imparare da pochi esempi. Lo zero-shot learning, d'altra parte, non richiede alcun dato etichettato. Invece, utilizza descrizioni o contesto per aiutare il sistema a gestire nuovi compiti. Nel frattempo, il transfer learning adotta un approccio diverso utilizzando la conoscenza di modelli pre-addestrati, consentendo loro di adattarsi rapidamente a nuovi compiti con una quantità minima di dati extra. Ogni metodo ha i suoi punti di forza a seconda del tipo di dati e del compito su cui stai lavorando.
Link to this sectionApplicazioni nel mondo reale di vari paradigmi di apprendimento#
Questi paradigmi di apprendimento stanno già facendo la differenza in molti settori, risolvendo problemi complessi con soluzioni innovative. Diamo un'occhiata più da vicino a come possono essere applicati nel mondo reale.
Link to this sectionDiagnosticare malattie rare con il few-shot learning#
Il few-shot learning sta cambiando le regole del gioco nel settore sanitario, specialmente nell'imaging medico. Può aiutare i medici a diagnosticare malattie rare usando solo pochi esempi o addirittura descrizioni, senza bisogno di grandi quantità di dati. Questo è particolarmente utile quando i dati sono limitati, il che è spesso il caso perché raccogliere grandi dataset per condizioni rare può essere difficile.
Ad esempio, SHEPHERD usa il few-shot learning e grafi di conoscenza biomedica per diagnosticare rari disordini genetici. Mappa le informazioni del paziente, come sintomi e risultati dei test, su una rete di geni e malattie noti. Questo aiuta a individuare la probabile causa genetica e a trovare casi simili, anche quando i dati sono limitati.
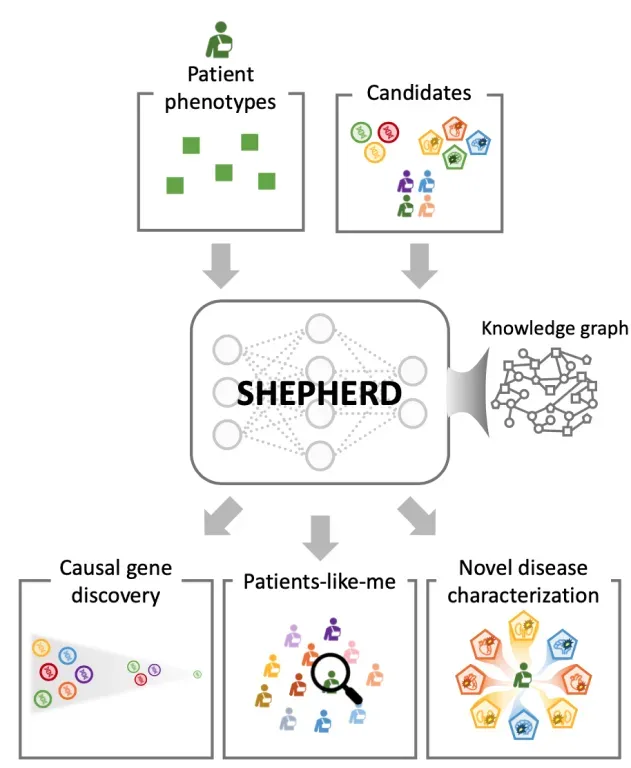
Fig 5. Il modello Shepherd diagnostica malattie rare usando dati minimi.
Link to this sectionMigliorare il rilevamento delle malattie delle piante con lo zero-shot learning#
In agricoltura, identificare rapidamente le malattie delle piante è essenziale perché i ritardi nel rilevamento possono portare a danni diffusi alle colture, rese ridotte e perdite finanziarie significative. I metodi tradizionali si basano spesso su ampi dataset e conoscenze di esperti, che potrebbero non essere sempre accessibili, specialmente in aree remote o con risorse limitate. È qui che entrano in gioco i progressi nell'IA, come lo zero-shot learning.
Diciamo che un agricoltore sta coltivando pomodori e patate e nota sintomi come ingiallimento delle foglie o macchie marroni. Lo zero-shot learning può aiutare a identificare malattie come la peronospora senza richiedere grandi dataset. Usando le descrizioni dei sintomi, il modello può classificare malattie che non ha mai visto prima. Questo approccio è veloce, scalabile e consente agli agricoltori di rilevare una varietà di problemi delle piante. Li aiuta a monitorare la salute delle colture in modo più efficiente, ad agire tempestivamente e a ridurre le perdite.

Fig 6. Uso dello zero-shot learning per identificare le malattie delle piante.
Link to this sectionVeicoli autonomi e transfer learning#
I veicoli autonomi devono spesso adattarsi a diversi ambienti per navigare in sicurezza. Il transfer learning li aiuta a usare le conoscenze pregresse per adattarsi rapidamente a nuove condizioni senza iniziare il loro addestramento da zero. Combinate con la computer vision, che aiuta i veicoli a interpretare le informazioni visive, queste tecnologie consentono una navigazione più fluida su terreni e condizioni meteorologiche diverse, rendendo la guida autonoma più efficiente e affidabile.
Un buon esempio di ciò in azione è un sistema di gestione dei parcheggi che usa Ultralytics YOLO11 per monitorare i posti auto. YOLO11, un modello di object detection pre-addestrato, può essere perfezionato tramite il transfer learning per identificare in tempo reale i posti auto vuoti e occupati. Addestrando il modello su un dataset più piccolo di immagini di parcheggi, impara a rilevare con precisione gli spazi liberi, i posti pieni e persino le aree riservate.

Fig 7. Gestione dei parcheggi usando Ultralytics YOLO11.
Integrato con altre tecnologie, questo sistema può guidare i conducenti verso il posto libero più vicino, contribuendo a ridurre i tempi di ricerca e la congestione del traffico. Il transfer learning rende tutto ciò possibile basandosi sulle capacità di object detection esistenti di YOLO11, consentendogli di adattarsi alle esigenze specifiche della gestione dei parcheggi senza dover ricominciare da zero. Questo approccio fa risparmiare tempo e risorse, creando una soluzione altamente efficiente e scalabile che migliora le operazioni di parcheggio e migliora l'esperienza utente complessiva.
Link to this sectionTendenze emergenti nei paradigmi di apprendimento#
Il futuro dei paradigmi di apprendimento nella computer vision punta allo sviluppo di sistemi di IA visiva più intelligenti e sostenibili. In particolare, una tendenza in crescita è l'uso di approcci ibridi che combinano few-shot learning, zero-shot learning e transfer learning. Unendo i punti di forza di questi metodi, i modelli possono apprendere nuovi compiti con dati minimi e applicare le proprie conoscenze in diverse aree.
Un esempio interessante è l'uso di deep embedding adattati per perfezionare i modelli usando la conoscenza di compiti precedenti e una piccola quantità di nuovi dati, rendendo più facile lavorare con dataset limitati.
Allo stesso modo, lo X-shot learning è progettato per gestire compiti con diverse quantità di dati. Utilizza una supervisione debole, in cui i modelli imparano da etichette limitate o rumorose, e istruzioni chiare per aiutarli ad adattarsi rapidamente, anche con pochi o nessun esempio precedente disponibile. Questi approcci ibridi mostrano come l'integrazione di diversi metodi di apprendimento possa aiutare i sistemi di IA ad affrontare le sfide in modo più efficace.
Link to this sectionPunti chiave#
Il few-shot learning, lo zero-shot learning e il transfer learning affrontano ciascuno sfide specifiche nella computer vision, rendendoli adatti a compiti diversi. L'approccio giusto dipende dall'applicazione specifica e dalla quantità di dati disponibili. Ad esempio, il few-shot learning funziona bene con dati limitati, mentre lo zero-shot learning è ottimo per gestire classi non viste o non familiari.
Guardando al futuro, è probabile che combinare questi metodi per creare modelli ibridi che integrino visione, linguaggio e audio sarà un focus chiave. Questi progressi mirano a rendere i sistemi di IA più flessibili, efficienti e capaci di affrontare problemi complessi, aprendo nuove possibilità per l'innovazione nel campo.
Esplora di più sull'IA unendoti alla nostra community e dando un'occhiata al nostro repository GitHub. Scopri come l'IA nelle auto a guida autonoma e la computer vision in agricoltura stanno rimodellando il futuro. Controlla le opzioni disponibili per la licenza YOLO per iniziare!






