生成AIの波とともに始まる2024年
2024年第1四半期の刺激的なAIイノベーションを振り返ります。OpenAIのSora AI、Neuralinkの脳チップ、そして最新のLLMなどの躍進を取り上げます。

AIコミュニティはほぼ毎日、ニュースを賑わせているようです。2024年の最初の数ヶ月はエキサイティングで、新しいAIイノベーションで満ち溢れていました。強力な新しい大規模言語モデルから人間の脳インプラントまで、2024年は素晴らしい年になりそうです。
AIは産業を変革し、情報をよりアクセスしやすくし、さらには人間の精神と機械を融合させるための第一歩を踏み出しています。2024年の第1四半期を振り返り、わずか数ヶ月で遂げられたAIの進歩を詳しく見てみましょう。
Link to this sectionLLMsのトレンド#
膨大なテキストデータに基づいて人間の言語を理解、生成、操作するように設計された大規模言語モデル(LLMs)は、2024年の第1四半期に中心的な役割を果たしました。多くの主要なテック企業が独自のLLMモデルをリリースし、それぞれが独自の機能を持っています。GPT-3のような以前のLLMsの信じられないほどの成功が、このトレンドを刺激しました。ここでは、2024年初頭の最も注目すべきLLMリリースをいくつか紹介します。
Link to this sectionAnthropicのClaude 3#
Anthropicは2024年3月14日にClaude 3をリリースしました。Claude 3モデルには、Opus、Sonnet、Haikuの3つのバージョンがあり、それぞれが異なる市場と目的に対応しています。最も高速なモデルであるHaikuは、迅速で基本的な回答のために最適化されています。Sonnetは速度と知性のバランスを取り、エンタープライズアプリケーションをターゲットにしています。最も高度なバージョンであるOpusは、比類のない知性と推論を提供し、複雑なタスクやトップレベルのベンチマーク達成に最適です。
Claude 3は多くの高度な機能と改善を誇っています:
- 強化された多言語会話:日本語、スペイン語、フランス語を含む言語での能力が向上しました。
- 高度なビジョン機能:さまざまな視覚フォーマットを処理可能です。
- 拒否の最小化:不要な拒否が減り、より深い理解を示しており、コンテキスト把握能力が向上したことを示しています。
- 拡張されたコンテキストウィンドウ:200Kのコンテキストウィンドウを提供しますが、顧客のニーズに応じて100万トークンを超える入力を処理する能力があります。
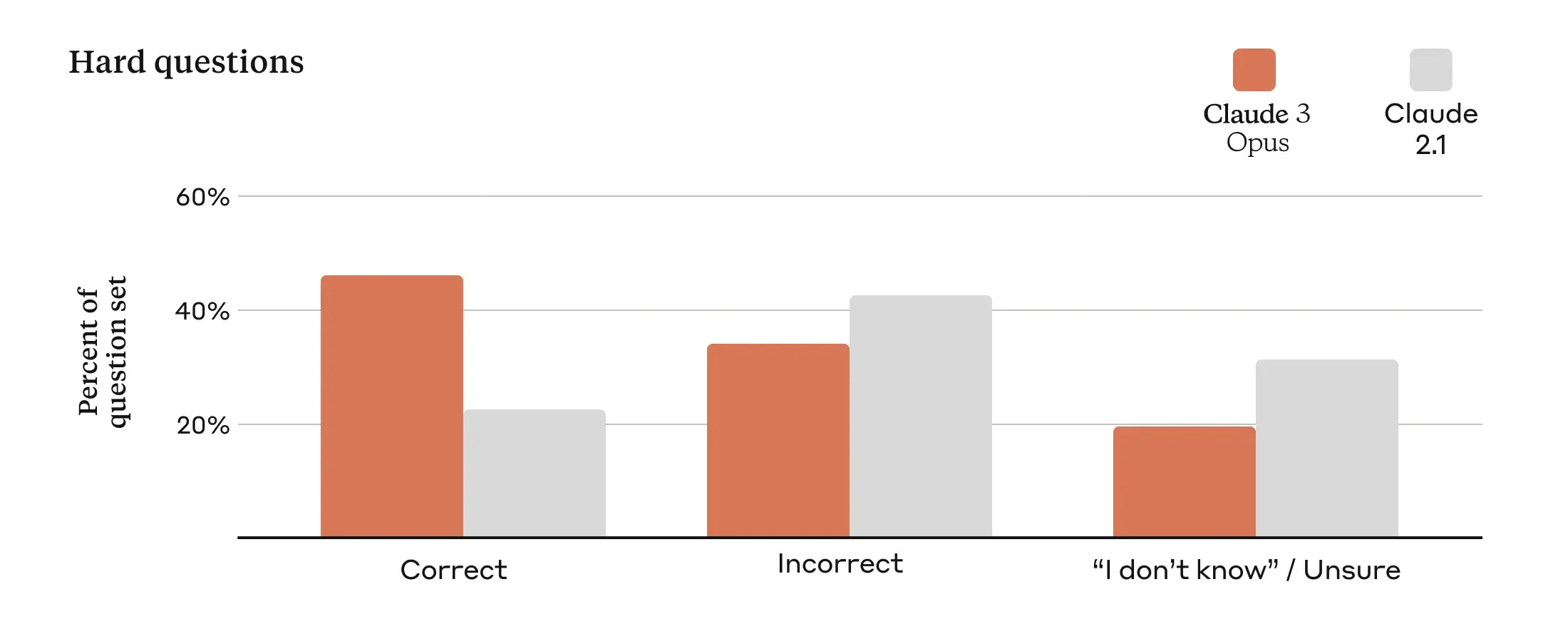
Fig 1. Claude 3は以前のバージョンよりもコンテキストを認識しています。
Link to this sectionDatabricksのDBRX#
Databricks DBRXは、2024年3月27日にDatabricksによってリリースされたオープンで汎用的なLLMです。DBRXは、言語理解、プログラミング、数学など、さまざまなベンチマークで非常に優れた成績を収めています。類似モデルより約40%小型でありながら、他の確立されたモデルを凌駕しています。
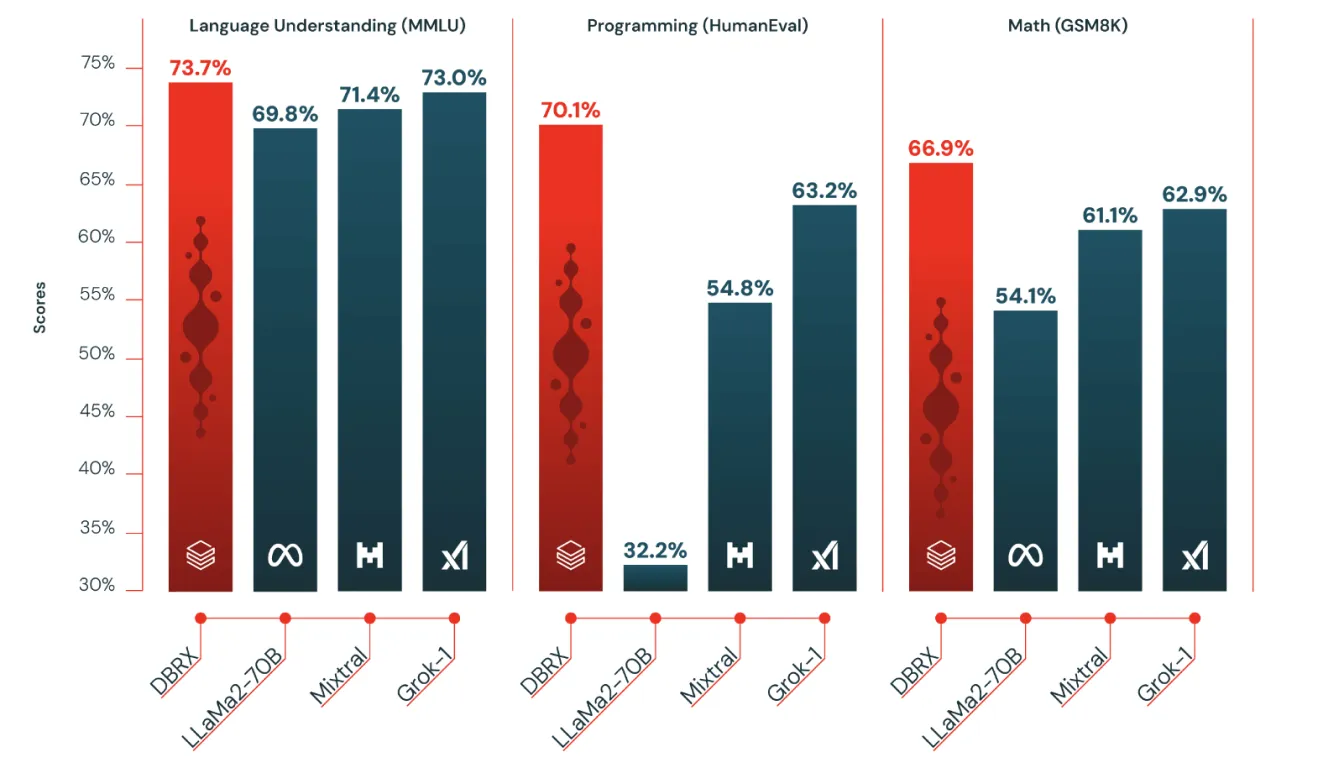
Fig 2. DBRXと他のモデルの比較。
DBRXは、きめ細かなMixture-of-Experts (MoE)アーキテクチャを用いた次トークン予測を使用してトレーニングされました。そのため、トレーニングと推論のパフォーマンスが大幅に向上しています。このアーキテクチャにより、モデルは専門化されたサブモデル(「エキスパート」)の多様なセットに相談することで、シーケンス内の次の単語をより正確に予測できます。これらのサブモデルは、さまざまな種類の情報やタスクを処理するのに適しています。
Link to this sectionGoogleのGemini 1.5#
Googleは2024年2月15日、広範なテキスト、ビデオ、音声データを分析できる、計算効率の高いマルチモーダルAIモデル「Gemini 1.5」を発表しました。この最新モデルは、パフォーマンス、効率、機能の面でより高度です。Gemini 1.5の重要な機能は、長いコンテキスト理解におけるブレイクスルーです。このモデルは、最大100万トークンを一貫して処理可能です。Gemini 1.5の機能も、新しいMoEベースのアーキテクチャのおかげです。
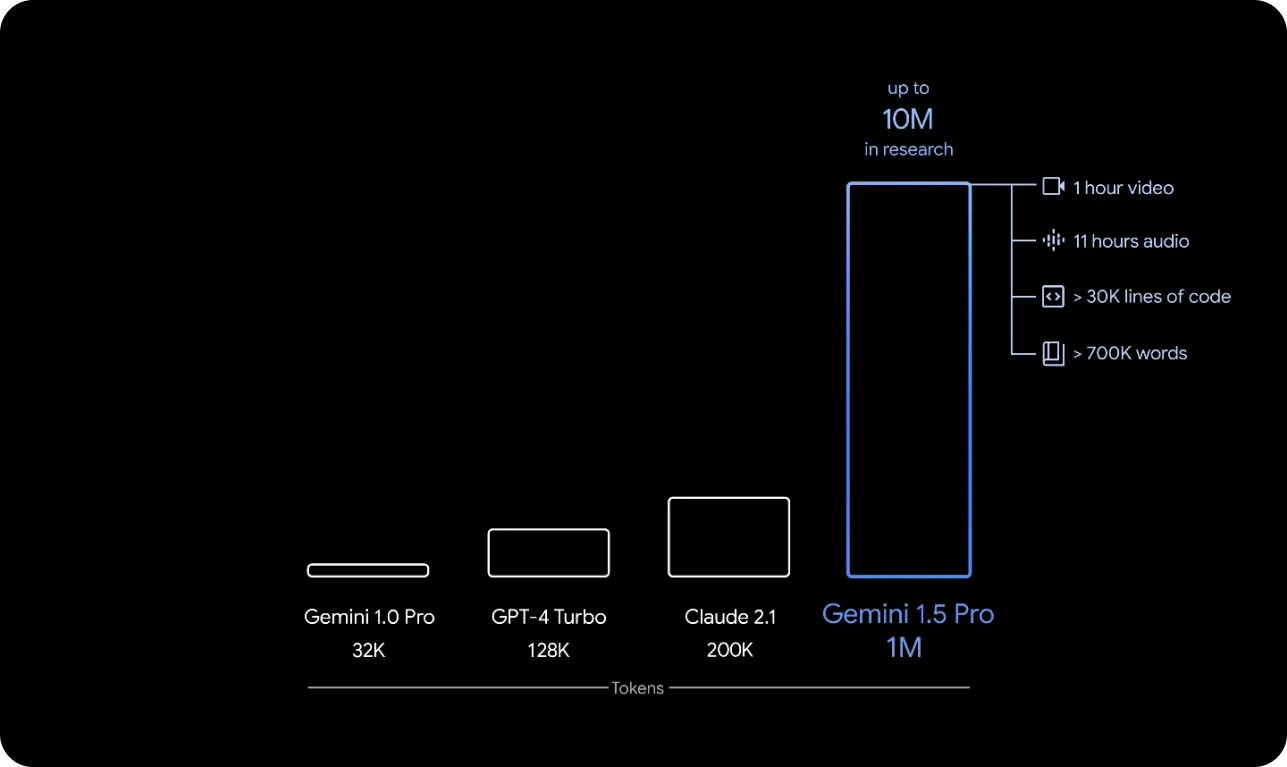
Fig 3. 一般的なLLMsのコンテキスト長の比較
以下はGemini 1.5の最も興味深い機能のいくつかです:
- 改善されたデータ処理:大規模なPDF、コードリポジトリ、または長いビデオをプロンプトとして直接アップロードできます。モデルはモダリティ全体で推論し、テキストを出力できます。
- 複数のファイルアップロードとクエリ:開発者は複数のファイルをアップロードして質問できるようになりました。
- さまざまなタスクに使用可能:多様なタスクにスケールするように最適化されており、数学、科学、推論、多言語対応、ビデオ理解、コードなどの分野で改善が見られます。
Link to this sectionAIによる素晴らしいビジュアル#
2024年の第1四半期には、ソーシャルメディアの未来とAIの進歩に関する議論を巻き起こすほどリアルなビジュアルを作成できる生成AIモデルが登場しました。会話を盛り上げているモデルを詳しく見ていきましょう。
Link to this sectionOpenAIのSora#
ChatGPTの作成者であるOpenAIは、2024年2月15日にSoraと呼ばれる最先端のテキスト・ツー・ビデオ・ディープラーニングモデルを発表しました。Soraは、ユーザーのテキストプロンプトに基づいて、高い視覚品質を持つ1分間のビデオを生成できるテキスト・ツー・ビデオジェネレーターです。
例として、以下のプロンプトを見てみましょう。
“A gorgeously rendered papercraft world of a coral reef, rife with colorful fish and sea creatures.”
そして、こちらが出力されたビデオのフレームです。

Fig 4. Soraによって生成されたビデオのフレーム。
Soraのアーキテクチャは、テクスチャ生成のための拡散モデルと、構造的一貫性のためのTransformerモデルをブレンドすることでこれを可能にしています。現在まで、Soraへのアクセスは、リスクを理解しフィードバックを得るために、レッドチーム担当者と、厳選されたビジュアルアーティスト、デザイナー、映画制作者のグループに提供されています。
Link to this sectionStability AIのStable Diffusion 3#
Stability AIは2024年2月22日に、テキストから画像を生成するモデルであるStable Diffusion 3を発表しました。このモデルは、ディフュージョンTransformerアーキテクチャとフロー・マッチングを組み合わせています。技術論文はまだ公開されていませんが、注目すべき重要な機能がいくつかあります。

Fig 5. プロンプトに基づく出力画像: “Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy” (Source)
Stable Diffusionの最新モデルは、パフォーマンス、画質、および複数の被写体を含む画像作成における正確さが向上しています。Stable Diffusion 3は、8億から80億のパラメータまで、さまざまなモデルを提供します。ユーザーは、スケーラビリティと詳細さに対する特定のニーズに基づいて選択できます。
Link to this sectionGoogleのLumiere#
2024年1月23日、Googleはテキスト・ツー・ビデオ拡散モデルであるLumiereを立ち上げました。Lumiereは、Space-Time-U-Net(略してSTUNet)と呼ばれるアーキテクチャを使用しています。これは、Lumiereがビデオ内の物の位置と動きを理解するのに役立ちます。そうすることで、滑らかで生き生きとしたビデオを生成できます。

Fig 6. プロンプト「Panda play ukulele at home.」に基づいて生成されたビデオのフレーム。
ビデオごとに80フレームを生成する能力を備えたLumiereは、境界を押し広げ、AI分野におけるビデオ品質の新しい基準を設定しています。Lumiereのいくつかの機能は以下の通りです:
- Image-to-Video:画像とプロンプトから開始して、Lumiereは画像をアニメーション化してビデオにすることができます。
- Stylized Generation:Lumiereは、単一のリファレンス画像を使用して特定のスタイルでビデオを作成できます。
- Cinemagraphs:Lumiereは画像内の特定の領域をアニメーション化して、シーンの残りの部分は静止したまま特定のオブジェクトが動くようなダイナミックなシーンを作成できます。
- Video Inpainting:ビデオ内の人物の服装を変更したり、背景の詳細を変更したりするなど、ビデオの一部を変更できます。
Link to this section未来はすぐそこにあるようです#
2024年の始まりは、SF映画から飛び出してきたような多くのAIイノベーションももたらしました。以前は不可能だと言われていたことが、現在取り組まれています。以下の発見により、未来はそれほど遠くないと感じられます。
Link to this sectionイーロン・マスクのNeuralink#
イーロン・マスクのNeuralinkは、2024年1月29日に人間の脳へのワイヤレスチップの埋め込みに成功しました。これは、人間の脳をコンピュータに接続するための大きな一歩です。イーロン・マスクは、Neuralinkの最初の製品である「Telepathy」が開発中であることを共有しました。

Fig 7. Neuralinkインプラント
目標は、ユーザー、特に四肢の機能を失ったユーザーが、思考を通じて簡単にデバイスを制御できるようにすることです。潜在的なアプリケーションは、利便性を超えています。イーロン・マスクは、麻痺のある個人が簡単にコミュニケーションできる未来を想像しています。
Link to this sectionディズニーのHoloTile Floor#
2024年1月18日、ウォルト・ディズニー・イマジニアリングはHoloTile Floorを発表しました。これは世界初の複数人対応の全方向トレッドミル床と呼ばれています。

Fig 8 ディズニーのイマジニア、ラニー・スムートが最新のイノベーション、HoloTile床の上でポーズをとっています。
没入型の仮想現実および拡張現実体験のために、テレキネシスのように人や物の下を動くことができます。あらゆる方向に歩くことができ、その上にいる間は衝突を避けることができます。ディズニーのHoloTile床は、劇場などのステージに設置して、創造的な方法でダンスや移動を行うこともできます。
Link to this sectionAppleのVision Pro#
2024年2月2日、Appleの待望のVision Proヘッドセットが市場に投入されました。仮想現実および拡張現実体験を再定義するために設計された一連の機能とアプリケーションを備えています。Vision Proヘッドセットは、エンターテインメント、生産性、空間コンピューティングを融合させることで、多様なユーザーに対応しています。Appleは、生産性ツールからゲーム、エンターテインメントサービスまで、600以上のアプリがVision Pro向けに最適化されたことを誇らしげに発表しました。
Link to this sectionCognitionのDevin#
2024年3月12日、CognitionはDevinと呼ばれるソフトウェアエンジニアリングアシスタントをリリースしました。Devinは、世界初の自律型AIソフトウェアエンジニアへの試みです。提案を提供したり特定のタスクを完了したりする従来のコーディングアシスタントとは異なり、Devinは初期コンセプトから完了までのソフトウェア開発プロジェクト全体を処理するように設計されています。
新しい技術を学習し、フルアプリを構築してデプロイし、バグを見つけて修正し、独自のモデルをトレーニングし、オープンソースや本番環境のコードベースに貢献し、Upworkのようなサイトからの実際の開発ジョブを引き受けることさえできます。
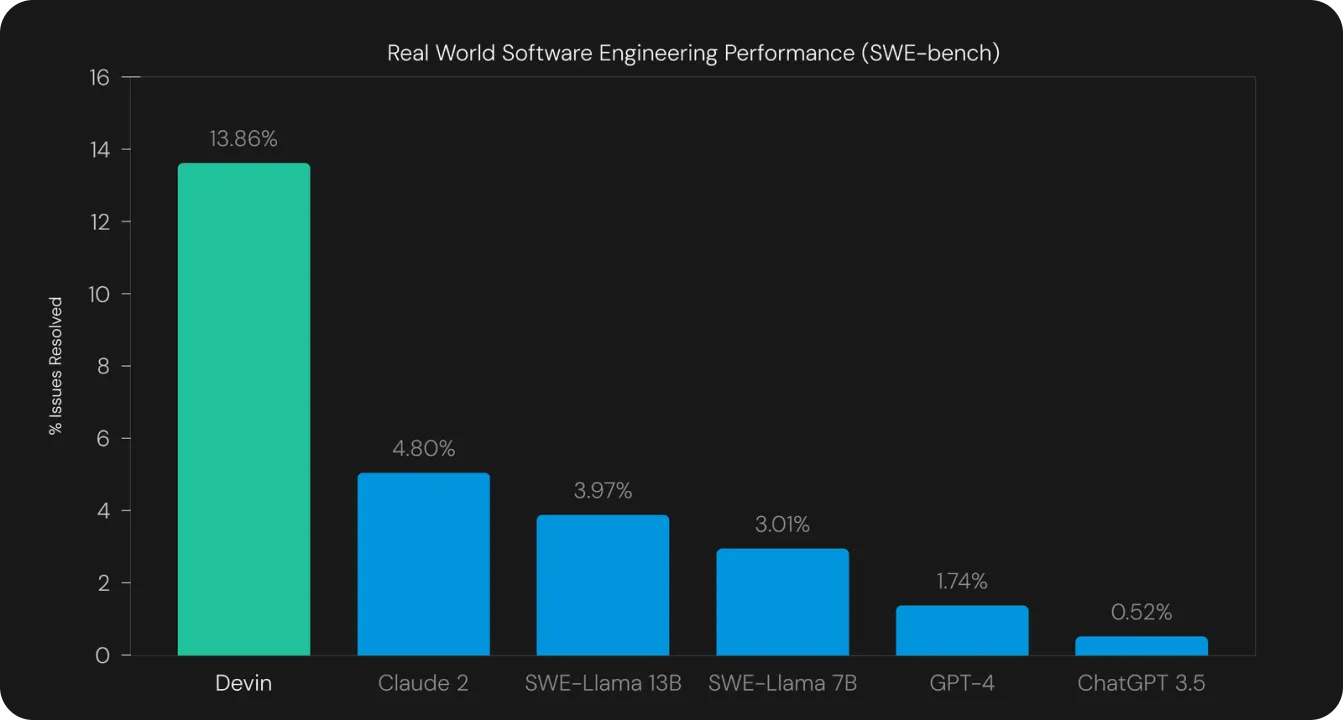
Fig 9. Devinと他のモデルの比較。
Devinは、Djangoやscikit-learnのようなオープンソースプロジェクトで見つかる現実世界のGitHubの問題をエージェントに解決させる、困難なベンチマークであるSWE-benchで評価されました。以前の最先端技術が1.96%であったのに対し、Devinは問題の13.86%をエンドツーエンドで正しく解決しました。
Link to this section佳作#
非常に多くのことが起こっているため、この記事ですべてを網羅することは不可能です。しかし、さらにいくつかの佳作を紹介します。
- 2024年3月21日に発表されたNVIDIAのLATTE3Dは、テキストプロンプトから3D表現を即座に作成するテキスト・ツー・3D AIモデルです。
- Midjourneyの新しいテキスト・ツー・ビデオジェネレーターは、CEOのDavid Holzによって予告されており、1月にトレーニングを開始し、間もなく発売される予定です。
- AI PC革命を前進させ、Lenovoは2024年1月8日にE Ink Prism技術を搭載したThinkBook 13xと、高性能なAIラップトップをリリースしました。
Link to this section私たちと一緒にAIトレンドの最新情報を入手しましょう!#
2024年の始まりには、AIの画期的な進歩と多くの主要な技術的マイルストーンがありました。しかし、これはAIができることのほんの始まりに過ぎません。最新のAI開発について詳しく知りたい場合は、Ultralyticsにお任せください。
私たちのGitHub repositoryをチェックして、コンピュータビジョンとAIへの最新の貢献をご覧ください。また、私たちのソリューションページをご覧になり、AIがmanufacturingやhealthcareのような産業でどのように使用されているかをご確認ください。






