Model optimizasyonu nedir? Hızlı bir rehber
Hiperparametre ayarlama, model budama ve model kuantizasyonu gibi model optimizasyon tekniklerinin bilgisayarlı görü modellerinin daha verimli çalışmasına nasıl yardımcı olabileceğini öğren.

Model optimization is a process that aims to improve the efficiency and performance of machine learning models. By refining a model's structure and function, optimization makes it possible for models to deliver better results with minimal computational resources and reduced training and evaluation time.
This process is especially important in fields like computer vision, where models often require substantial resources to analyze complex images. In resource-constrained environments like mobile devices or edge systems, optimized models can work well with limited resources while still being accurate.
Model optimizasyonunu gerçekleştirmek için hiperparametre ayarı, model budama, model niceleme ve karma hassasiyet dahil olmak üzere yaygın olarak çeşitli teknikler kullanılır. Bu makalede, bu teknikleri ve bunların bilgisayarlı görü uygulamalarına sağladığı avantajları inceleyeceğiz. Hadi başlayalım!
Link to this sectionModel optimizasyonunu anlamak#
Computer vision models usually have deep layers and complex structures that are great for recognizing intricate patterns in images, but they can also be quite demanding in terms of processing power. When these models are deployed on devices with limited hardware, like mobile phones or edge devices, they can face certain challenges or limitations.
Bu cihazlardaki sınırlı işlem gücü, bellek ve enerji, modeller ayak uydurmakta zorlandıkça performance değerinde fark edilir düşüşlere yol açabilir. Model optimizasyon teknikleri, bu endişeleri gidermenin anahtarıdır. Modeli kolaylaştırmaya, computational needs azaltmaya ve sınırlı kaynaklarla bile etkili bir şekilde çalışabilmesini sağlamaya yardımcı olurlar. Model optimizasyonu, model architecture basitleştirilerek, hesaplamaların precision düşürülerek veya modeli daha hafif ve hızlı hale getirmek için gereksiz bileşenlerin kaldırılarak yapılabilir.
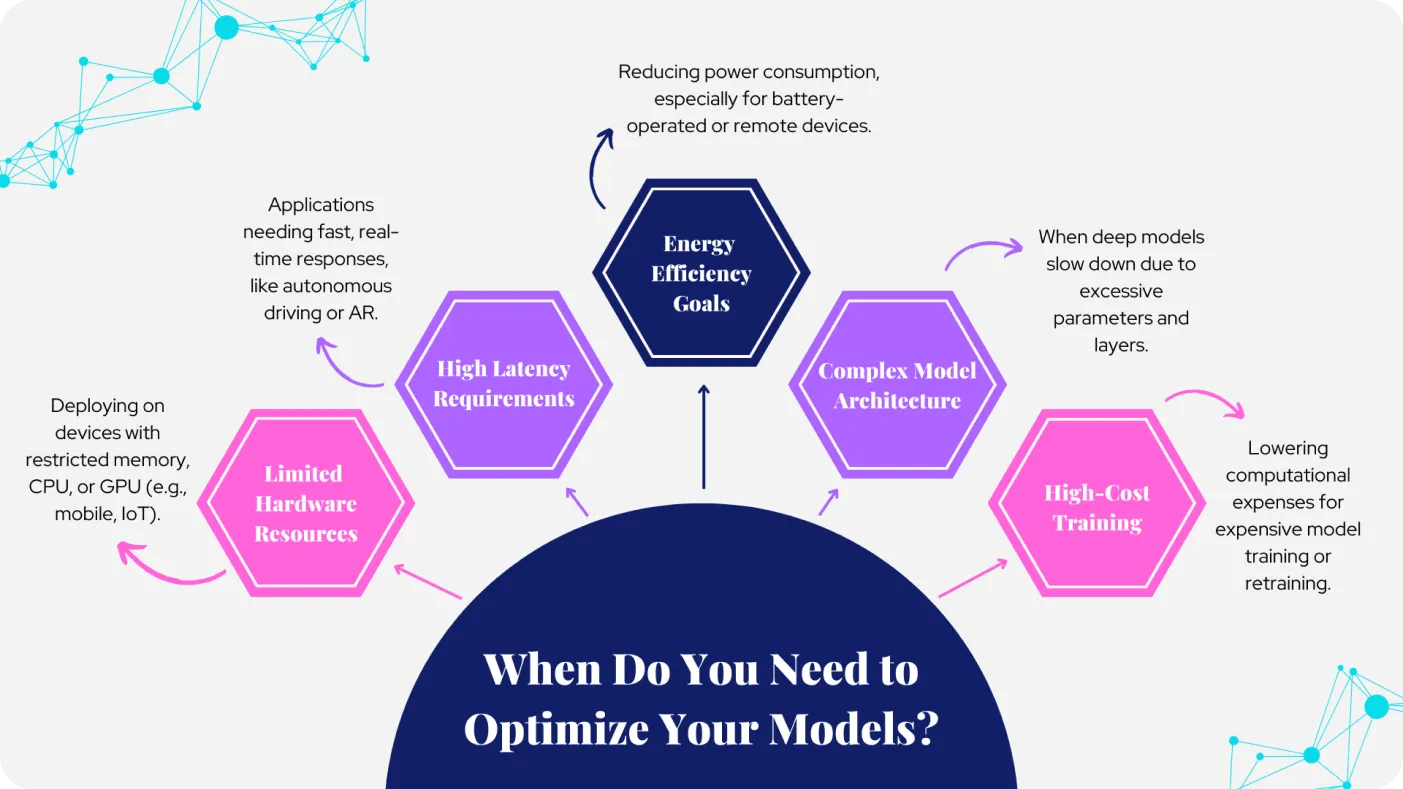
Şekil 1. Modellerinizi optimize etme nedenleri. Görsel, yazar tarafından hazırlanmıştır.
İşte aşağıdaki bölümlerde daha ayrıntılı inceleyeceğimiz en yaygın model optimizasyon tekniklerinden bazıları:
- Hiperparametre ayarı: Model performansını iyileştirmek için öğrenme hızı ve yığın boyutu gibi hiperparametrelerin sistematik olarak ayarlanmasını içerir.
- Model budama: Bu teknik, sinir ağından gereksiz ağırlıkları ve bağlantıları kaldırarak karmaşıklığını ve hesaplama maliyetini azaltır.
- Model niceleme: Niceleme, modelin ağırlıklarının ve aktivasyonlarının hassasiyetini tipik olarak 32-bit'ten 16-bit veya 8-bit'e düşürmeyi içerir, bu da bellek ayak izini ve hesaplama gereksinimlerini önemli ölçüde azaltır.
- Hassasiyet ayarlamaları: Karma hassasiyetli eğitim olarak da bilinir, modelin farklı bölümleri için farklı hassasiyet formatları kullanmayı ve doğruluktan ödün vermeden kaynak kullanımını optimize etmeyi içerir.
Link to this sectionAçıklandı: Makine öğrenimi modellerinde hiperparametreler#
Hiperparametrelerini -modelin veriden nasıl öğreneceğini şekillendiren ayarlar- ayarlayarak bir modelin daha iyi öğrenmesine ve performans göstermesine yardımcı olabilirsin. Hiperparametre ayarı, bu ayarları optimize ederek modelin verimliliğini ve doğruluğunu artıran bir tekniktir. Modelin eğitim sırasında öğrendiği parametrelerin aksine, hiperparametreler eğitim sürecini yönlendiren önceden ayarlanmış değerlerdir.
Ayarlanabilecek hiperparametre örneklerine göz atalım:
- Öğrenme hızı: Bu parametre, modelin iç ağırlıklarını ayarlamak için attığı adım boyutunu kontrol eder. Daha yüksek bir öğrenme hızı öğrenmeyi hızlandırabilir ancak en uygun çözümü kaçırma riski taşır, daha düşük bir hız ise daha doğru olabilir ancak daha yavaş çalışır.
- Yığın boyutu: Her eğitim adımında kaç veri örneğinin işleneceğini tanımlar. Daha büyük yığın boyutları daha kararlı bir öğrenme sunar ancak daha fazla bellek gerektirir. Daha küçük yığınlar daha hızlı eğitilir ancak daha az kararlı olabilir.
- Dönemler: Bu parametreyi kullanarak modelin tam veri kümesini kaç kez göreceğini belirleyebilirsin. Daha fazla dönem doğruluğu artırabilir ancak aşırı öğrenme riski taşır.
- Çekirdek boyutu: Evrişimli Sinir Ağlarındaki (CNN) filtre boyutunu tanımlar. Daha büyük çekirdekler daha geniş desenleri yakalar ancak daha fazla işlem gerektirir; daha küçük çekirdekler daha ince ayrıntılara odaklanır.
Link to this sectionHiperparametre ayarı nasıl çalışır#
Hiperparametre ayarı genellikle her hiperparametre için olası değerlerin bir aralığını tanımlamakla başlar. Bir arama algoritması daha sonra en iyi performansı üreten ayarları tanımlamak için bu aralıklardaki farklı kombinasyonları araştırır.
Yaygın ayarlama yöntemleri arasında ızgara arama, rastgele arama ve Bayesçi optimizasyon yer alır. Izgara arama, belirtilen aralıklardaki her olası değer kombinasyonunu test eder. Rastgele arama, kombinasyonları rastgele seçer ve genellikle etkili ayarları daha hızlı bulur. Bayesçi optimizasyon, önceki sonuçlara dayanarak umut verici hiperparametre değerlerini tahmin etmek için olasılıksal bir model kullanır. Bu yaklaşım genellikle gereken deneme sayısını azaltır.
Sonuç olarak, her hiperparametre kombinasyonu için modelin performansı değerlendirilir. Süreç, istenen sonuçlar elde edilene kadar tekrarlanır.
Link to this sectionHiperparametreler ve model parametreleri#
Hiperparametre ayarı üzerinde çalışırken, hiperparametreler ile model parametreleri arasındaki farkın ne olduğunu merak edebilirsin.
Hyperparameters are values set before training that control how the model learns, such as the learning rate or batch size. These settings are fixed during training and directly influence the learning process. Model parameters, on the other hand, are learned by the model itself during training. These include weights and biases, which adjust as the model trains and ultimately guide its predictions. In essence, hyperparameters shape the learning journey, while model parameters are the results of that learning process.
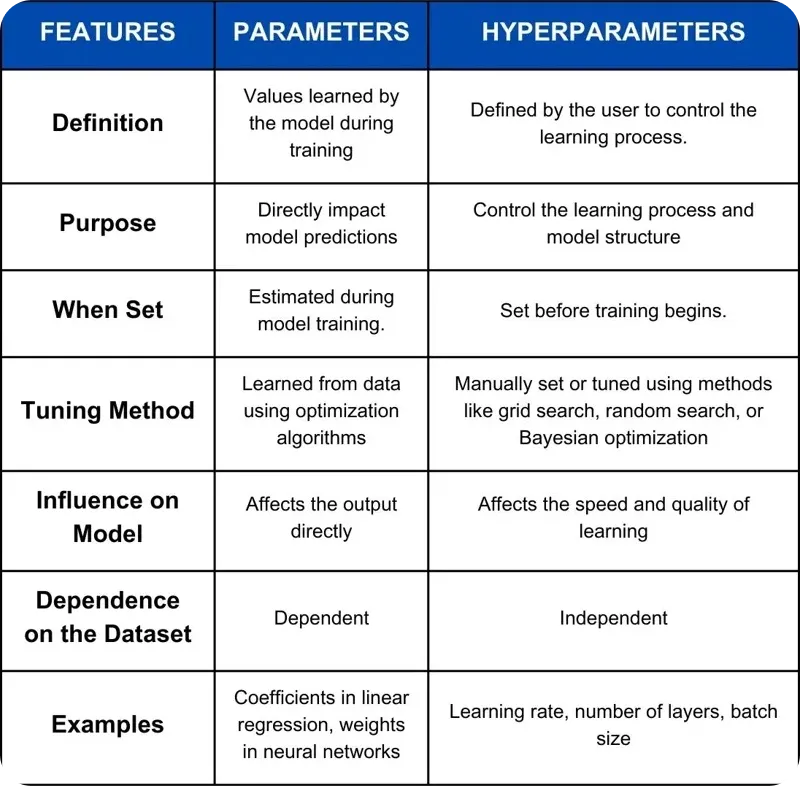
Şekil 2. Parametreler ve Hiperparametrelerin Karşılaştırılması.
Link to this sectionDerin öğrenmede model budama neden önemlidir#
Model pruning, bir modelden gereksiz ağırlıkları ve parametreleri kaldırarak onu daha verimli hale getiren bir boyut küçültme tekniğidir. computer vision alanında, özellikle derin neural networks ile çalışırken, ağırlıklar ve aktivasyonlar (nihai çıktıyı hesaplamaya yardımcı olan ara çıktılar) gibi çok sayıda parametre, hem karmaşıklığı hem de hesaplama taleplerini artırabilir. Budama, performansa minimum katkıda bulunan parametreleri tanımlayıp kaldırarak modeli kolaylaştırmaya yardımcı olur ve sonuçta daha hafif, verimli bir model ortaya çıkar.
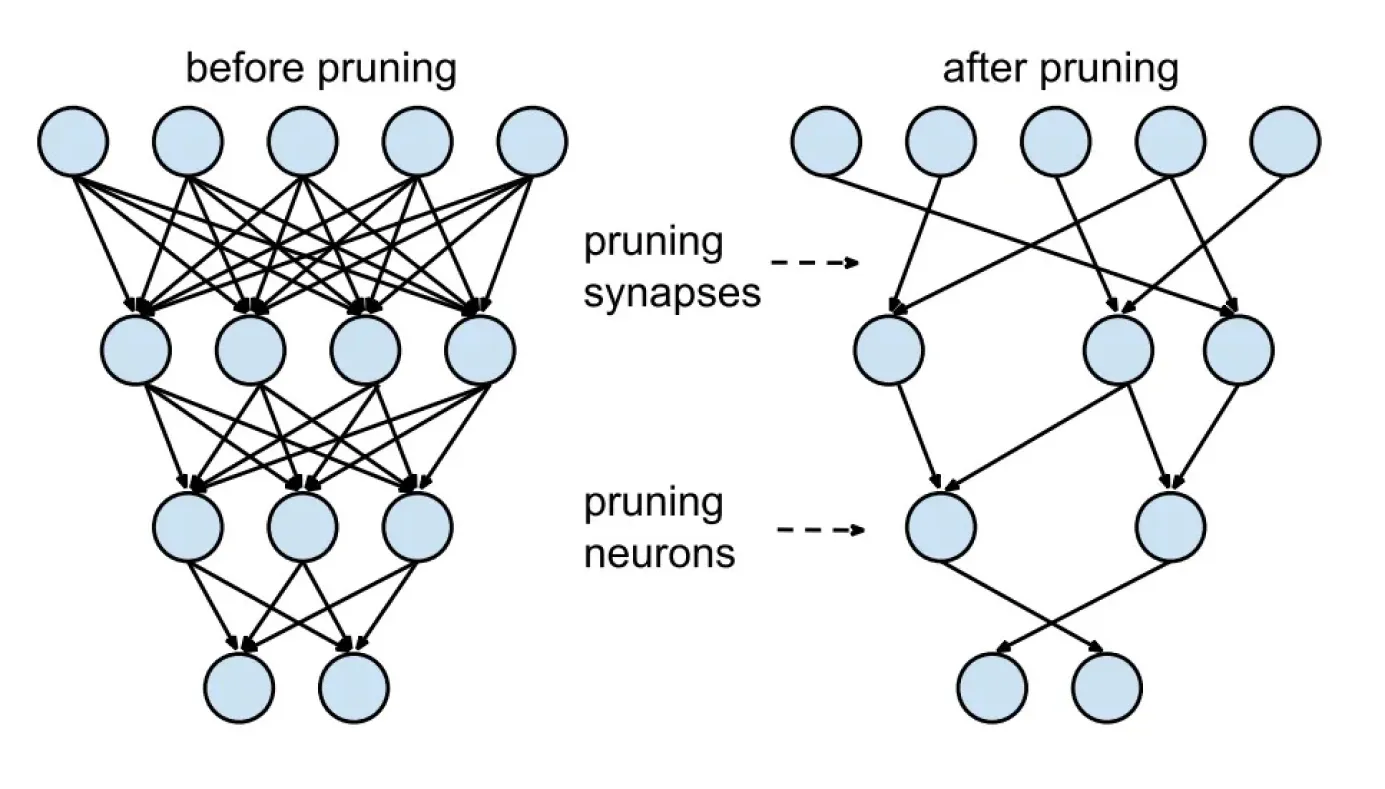
Şekil 3. Model budama öncesi ve sonrası.
Model eğitildikten sonra, büyüklük tabanlı budama veya duyarlılık analizi gibi teknikler her parametrenin önemini değerlendirebilir. Düşük öneme sahip parametreler daha sonra ağırlık budama, nöron budama veya yapısal budama olmak üzere üç ana teknikten biri kullanılarak budanır.
Ağırlık budama, çıktı üzerinde minimum etkisi olan bireysel bağlantıları kaldırır. Nöron budama, çıktıları modelin işlevine çok az katkıda bulunan tüm nöronları kaldırır. Yapısal budama, evrişimli filtreler veya tam bağlantılı katmanlardaki nöronlar gibi daha büyük bölümleri ortadan kaldırarak modelin verimliliğini optimize eder. Budama tamamlandıktan sonra model, kalan parametreleri ince ayar yapmak için yeniden eğitilir ve küçültülmüş biçimde yüksek doğruluğu koruduğundan emin olunur.
Link to this sectionNiceleme ile yapay zeka modellerinde gecikmeyi azaltma#
Model niceleme, bir modelin ağırlıklarını ve aktivasyonlarını temsil etmek için kullanılan bit sayısını azaltır. Tipik olarak yüksek hassasiyetli 32-bit kayan noktalı değerleri, 16-bit veya 8-bit tam sayılar gibi daha düşük hassasiyete dönüştürür. Bit hassasiyetini düşürerek, niceleme modelin boyutunu, bellek ayak izini ve hesaplama maliyetini önemli ölçüde azaltır.
Bilgisayarlı göruda, 32-bit kayan noktalar standarttır, ancak 16-bit veya 8-bit'e dönüştürme verimliliği artırabilir. İki ana niceleme türü vardır: ağırlık niceleme ve aktivasyon niceleme. Ağırlık niceleme, modelin ağırlıklarının hassasiyetini düşürerek boyut küçültme ile doğruluk arasında denge kurar. Aktivasyon niceleme, aktivasyonların hassasiyetini düşürerek bellek ve hesaplama taleplerini daha da azaltır.
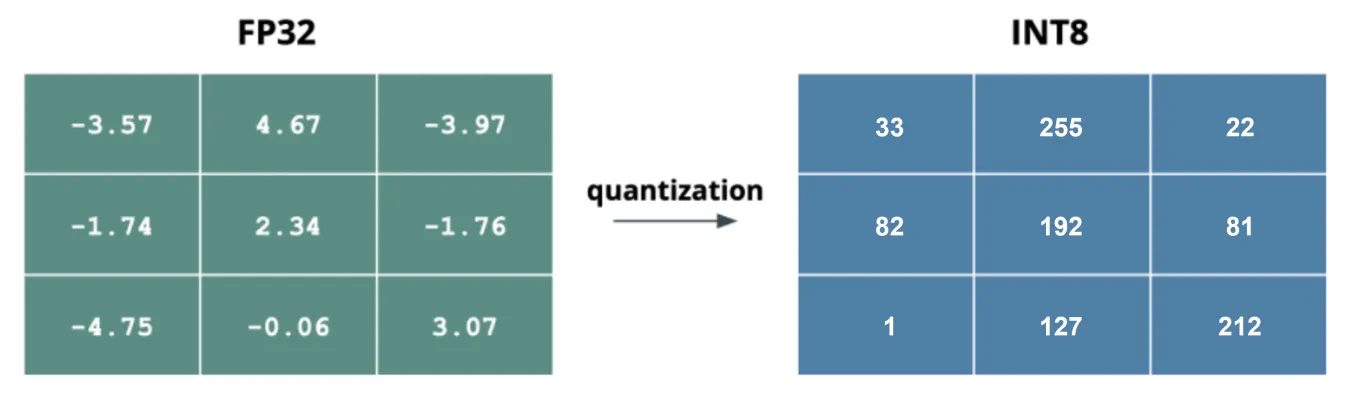
Şekil 4. 32-bit kayan noktadan 8-bit tam sayıya bir niceleme örneği.
Link to this sectionKarma hassasiyet yapay zeka çıkarımlarını nasıl hızlandırır#
Karma hassasiyet, bir sinir ağının çeşitli bölümleri için farklı sayısal hassasiyetler kullanan bir tekniktir. 32-bit kayan noktalar gibi daha yüksek hassasiyetli değerleri, 16-bit veya 8-bit kayan noktalar gibi düşük hassasiyetli değerlerle birleştirerek, karma hassasiyet, bilgisayarlı görü modellerinin doğruluğu feda etmeden eğitimi hızlandırmasını ve bellek kullanımını azaltmasını mümkün kılar.
Eğitim sırasında karma hassasiyet, ağın genelinde gerektiğinde yüksek hassasiyeti korurken belirli katmanlarda daha düşük hassasiyet kullanılarak elde edilir. Bu, döküm (casting) ve kayıp ölçeklendirme yoluyla yapılır. Döküm, model tarafından gerektiği gibi veri türlerini farklı hassasiyetler arasında dönüştürür. Kayıp ölçeklendirme, sayısal eksik akışı (underflow) önlemek için azaltılmış hassasiyeti ayarlar ve kararlı eğitimi sağlar. Karma hassasiyet, özellikle büyük modeller ve büyük yığın boyutları için kullanışlıdır.
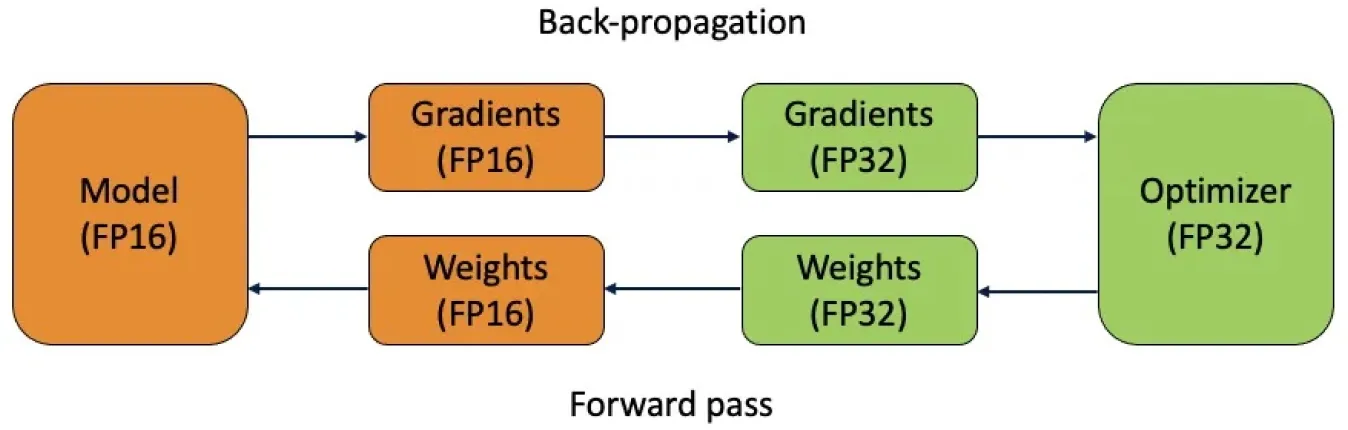
Şekil 5. Karma hassasiyetli eğitim hem 16-bit (FP16) hem de 32-bit (FP32) kayan noktalı tiplerini kullanır.
Link to this sectionModel doğruluğu ve verimliliğini dengeleme#
Artık çeşitli model optimizasyon tekniklerini ele aldığımıza göre, özel ihtiyaçlarınıza göre hangisinin kullanılacağına nasıl karar vereceğinizi tartışalım. Seçim, donanım, konuşlandırma ortamının hesaplama ve bellek kısıtlamaları ve gerekli doğruluk seviyesi gibi faktörlere bağlıdır.
Örneğin, daha küçük, daha hızlı modeller sınırlı kaynaklara sahip mobil cihazlar için daha uygundur, daha büyük ve daha doğru modeller ise yüksek performanslı sistemlerde kullanılabilir. İşte her tekniğin farklı hedeflerle nasıl uyumlu olduğu:
- Budama: Doğruluğu önemli ölçüde etkilemeden model boyutunu küçültmek için idealdir, bu da onu cep telefonları veya Nesnelerin İnterneti (IoT) cihazları gibi kaynak kısıtlı cihazlar için mükemmel kılar.
- Quantization: A great option for shrinking model size and speeding up inference, particularly on mobile devices and embedded systems with limited memory and processing power. It works well for applications where slight accuracy reductions are acceptable.
- Karma hassasiyet: Büyük ölçekli modeller için tasarlanan bu teknik, bellek kullanımını azaltır ve karma hassasiyetli işlemleri destekleyen GPU'lar ve TPU'lar gibi donanımlarda eğitimi hızlandırır. Genellikle verimliliğin önemli olduğu yüksek performanslı görevlerde kullanılır.
- Hiperparametre ayarı: Hesaplama açısından yoğun olsa da, tıbbi görüntüleme veya otonom sürüş gibi yüksek doğruluk gerektiren uygulamalar için gereklidir.
Link to this sectionÖne çıkanlar#
Model optimizasyonu, özellikle gerçek dünya uygulamalarında yapay zekayı konuşlandırmak için makine öğreniminin hayati bir parçasıdır. Hiperparametre ayarı, model budama, niceleme ve karma hassasiyet gibi teknikler, bilgisayarlı görü modellerinin performansını, verimliliğini ve kaynak kullanımını iyileştirmeye yardımcı olur. Bu optimizasyonlar, modelleri daha hızlı ve daha az kaynak yoğun hale getirir; bu da sınırlı bellek ve işlem gücüne sahip cihazlar için idealdir. Optimize edilmiş modellerin farklı platformlarda ölçeklendirilmesi ve konuşlandırılması da daha kolaydır, bu da hem etkili hem de çok çeşitli kullanımlara uyarlanabilir yapay zeka çözümlerini mümkün kılar.
Visit the Ultralytics GitHub repository and join our community to learn more about AI applications in manufacturing and agriculture.






