Wie die Ultralytics Platform die Bereitstellung von Computer-Vision-Modellen vereinfacht
Sieh dir an, wie die Ultralytics Platform alles vereint, was für die Bereitstellung von Computer-Vision-Modellen benötigt wird – vom Testen bis hin zu produktionsreifen APIs.
Ultralytics arbeitet seit Jahren mit der Computer-Vision-Community zusammen und entwickelt Modelle und Tools, die Vision-KI für jeden zugänglicher machen. Mit der Ultralytics Platform gehen wir noch einen Schritt weiter und führen den gesamten Workflow für die Entwicklung von Computer-Vision-Anwendungen in einer einzigen, einheitlichen Umgebung zusammen – von der Datenverwaltung und Annotation bis hin zum Modelltraining, der Validierung und der Bereitstellung.
Wir freuen uns besonders, die Bereitstellung von Computer-Vision-Modellen zu vereinfachen. Während Computer Vision immer mehr Einzug in reale Anwendungen hält, bleibt die Analyse von Bildern und Videos außerhalb kontrollierter Umgebungen komplex.
Im Gegensatz zu Testumgebungen mit vorhersehbaren Bedingungen sind reale Szenarien durch wechselnde Lichtverhältnisse, unterschiedliche Eingaben und unvorhersehbare Arbeitslasten geprägt, was die Bereitstellung zu einem der anspruchsvollsten Aspekte im Vision-Workflow macht.
Bereitstellung umfasst mehr als nur die bloße Verfügbarkeit eines Modells. Sie erfordert die Einrichtung von Prozessen, die mit realen Daten umgehen können, und stellt sicher, dass alles reibungslos läuft, während die Nutzung wächst und Projekte skaliert werden.
Teams müssen zudem die Leistung im Auge behalten und die Zuverlässigkeit langfristig sicherstellen. Dies bedeutet oft, zwischen verschiedenen KI-Tools für Tests, Integration, Bereitstellung und Überwachung zu wechseln, was die Modellentwicklung verlangsamen und unnötige Komplexität schaffen kann.
Workflows werden dadurch oft fragmentiert. Die Ultralytics Platform vereint und vereinfacht diesen Prozess.
Sie bietet integrierte Unterstützung für Modell-Serving, Tests und Überwachung in einer einzigen Umgebung. Teams können Modelle mittels browserbasierter Inferenz validieren, sie über gemeinsame Inferenzdienste in Anwendungen integrieren und sie auf dedizierten Endpunkten mit Funktionen zur Leistungsüberwachung bereitstellen.
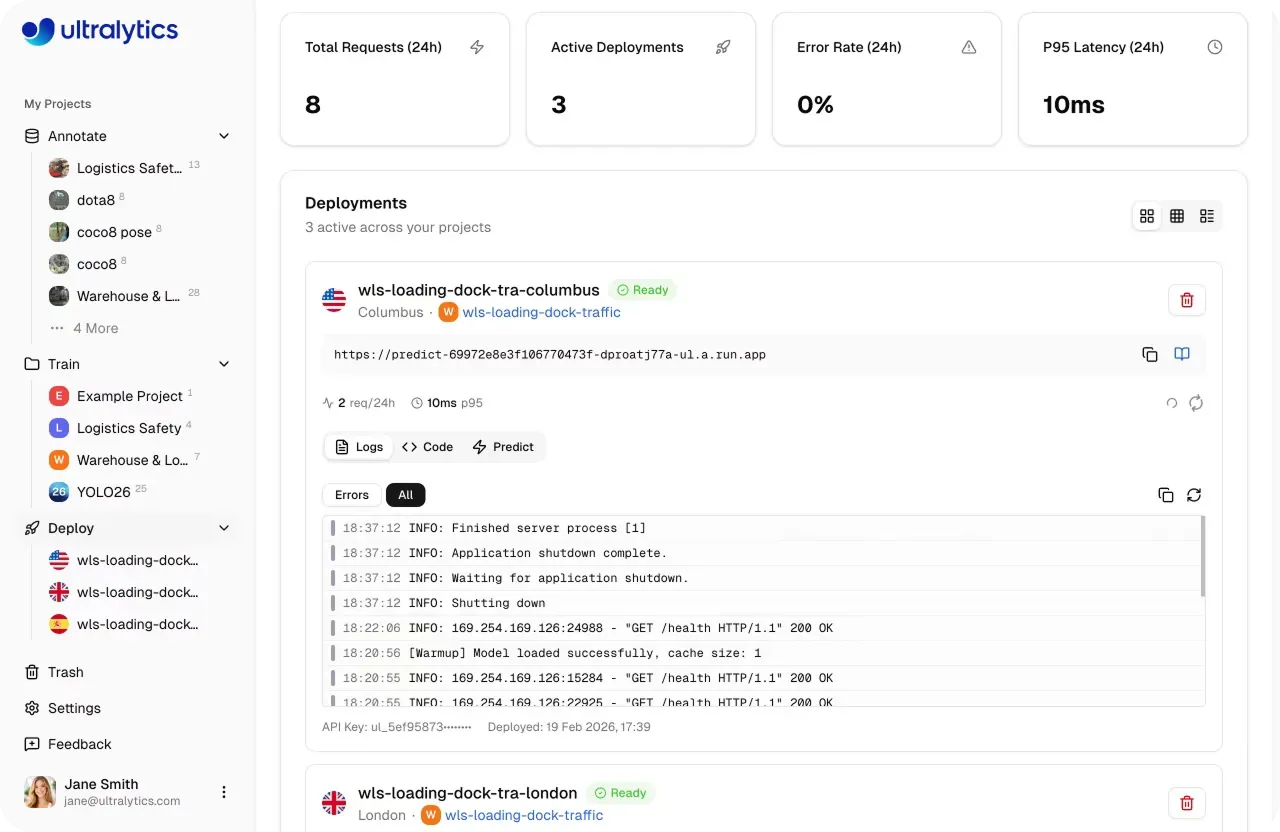
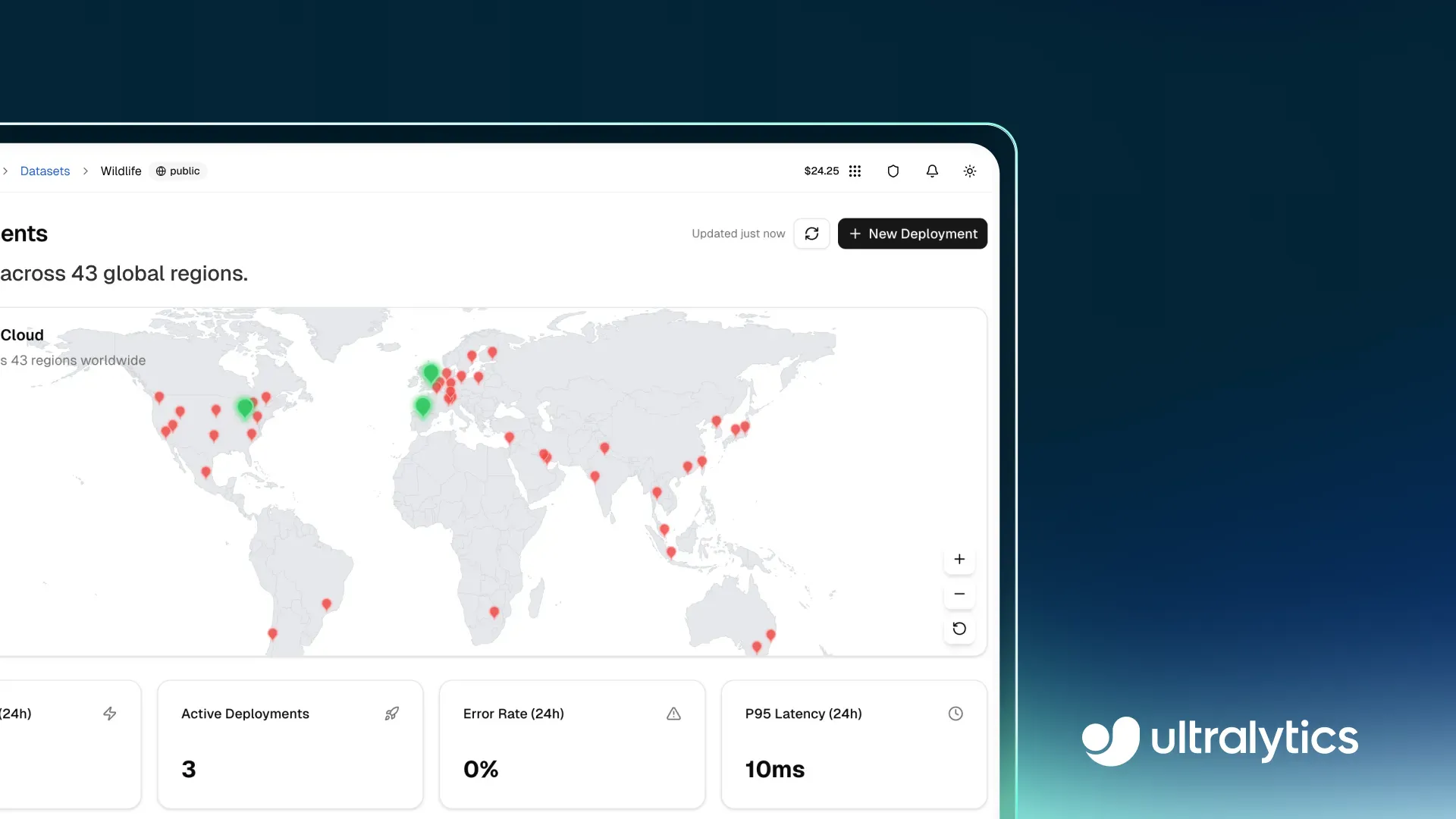
Abb. 1. Ein Blick auf die Deployment-Seite innerhalb der Ultralytics Platform (Quelle)
In diesem Artikel erfahren Sie, wie die Ultralytics Platform die Modellbereitstellung für Computer Vision neu definiert – von Tests und Integration bis hin zur Bereitstellung in der Produktion und Überwachung. Fangen wir an!
Link to this sectionEin Überblick über die Bereitstellung von Computer-Vision-Modellen#
Im Lebenszyklus von maschinellem Lernen ist die Modellbereitstellung die Phase, in der ein Modell aus der Experimentierphase in die reale Anwendung übergeht. Für Computer-Vision-Modelle, die auf Deep Learning und Convolutional Neural Networks basieren, bedeutet dies im Allgemeinen, sie für die Echtzeitverarbeitung von Bildern und Videos verfügbar zu machen.
Nach der Bereitstellung verarbeiten diese Modelle neue Daten, die normalerweise Vorverarbeitungsschritte wie Skalierung, Normalisierung oder Formatierung durchlaufen. Die verarbeiteten Daten werden dann an das Modell übergeben, das während des Trainings erlernte Muster anwendet, um präzise Vorhersagen zu generieren.
Je nach Anwendungsfall kann dies verschiedene Computer-Vision-Aufgaben umfassen. Beispielsweise unterstützen Ultralytics YOLO-Modelle, wie Ultralytics YOLO26, eine breite Palette an Aufgaben, darunter Objekterkennung, Bildklassifizierung, Instanzsegmentierung, Pose-Schätzung und die Erkennung mit orientierten Bounding Boxes (OBB).
Damit dies in realen Anwendungen praktisch umsetzbar ist, müssen Modelle oft in Systeme integriert werden, die sowohl Vorverarbeitung als auch Inferenz effizient bewältigen können. Genau hier wird die Bereitstellungsinfrastruktur unverzichtbar.
In Produktionsumgebungen wird meist über REST APIs oder Modell-Serving-Systeme auf Modelle zugegriffen. Diese Schnittstellen ermöglichen es Anwendungen, Daten programmatisch zu senden und Vorhersagen zu empfangen, was die Integration in externe Anwendungen, IoT-Geräte oder Robotiksysteme erleichtert, die auf Echtzeit-Bildanalyse angewiesen sind.
Link to this sectionEinschränkungen traditioneller Tools zur Bereitstellung von Computer-Vision-Modellen#
Die Bereitstellung von Computer-Vision-Modellen klingt einfach, sah aber bisher in der Praxis ganz anders aus. Betrachte ein typisches Setup: Daten werden zuerst von Kameras oder Sensoren erfasst, zur Inferenz an ein Modell gesendet und dann als Vorhersagen an eine Anwendung zurückgegeben.
In der Realität wird jeder dieser Schritte oft von getrennten Tools und Diensten gehandhabt. Ein System übernimmt die Datenerfassung, ein anderes das Modell-Serving, während zusätzliche Tools für Skalierung, Überwachung und Protokollierung eingesetzt werden. Diese Komponenten zuverlässig miteinander zu verbinden und am Laufen zu halten, wird schnell komplex.
Mit zunehmender Nutzung wächst diese Komplexität. Die Verwaltung der Infrastruktur, der Umgang mit Abhängigkeiten und die Aufrechterhaltung einer konsistenten Performance über die gesamte Pipeline hinweg können die Entwicklung verlangsamen und es erschweren, Computer-Vision-Modelle in realen Anwendungen bereitzustellen.
Die Ultralytics Platform führt diese Komponenten in einer einzigen, einheitlichen Umgebung zusammen. Dies bietet einen kohärenteren Weg zur Verwaltung des gesamten Bereitstellungs-Workflows bei gleichzeitiger Unterstützung von Performance und Zuverlässigkeit in großem Maßstab.
Link to this sectionOptionen zur Modellbereitstellung mit der Ultralytics Platform#
Neben der Vereinheitlichung des Modellbereitstellungsprozesses bietet die Ultralytics Platform auch Flexibilität bei der Art und Weise, wie Modelle bereitgestellt und genutzt werden.
Um verschiedene Phasen der Modellbereitstellung zu unterstützen, bietet die Plattform vier Optionen: browserbasiertes Testen mit sofortiger Inferenz, geteilte Inferenz über APIs für die Entwicklung, dedizierte Endpunkte für skalierbare Produktionseinsätze in globalen Regionen sowie den Modellexport für den Betrieb auf externer Infrastruktur oder Edge-Geräten.
Schauen wir uns also genauer an, wie jede dieser Optionen funktioniert.
Link to this sectionSchnelle Modellvalidierung über den Predict-Tab#
Bevor ein Modell in die Produktion geht, ist es wichtig zu verstehen, wie es mit neuen, unbekannten Daten abschneidet. Die Ultralytics Platform enthält einen integrierten Predict-Tab, mit dem du Inferenz ausführen kannst – direkt im Browser, ohne Setup, Infrastruktur oder Abhängigkeiten.
Der Predict-Tab macht die Modellvalidierung schnell und interaktiv. Du kannst Bilder hochladen, vorgefertigte Beispiele verwenden oder Eingaben per Webcam erfassen. Die Inferenz startet automatisch, sobald Daten bereitgestellt werden.
Die Ergebnisse erscheinen sofort mit visuellen Overlays, Konfidenzwerten und detaillierten Ausgaben, sodass du ein klares Bild davon bekommst, wie das Modell reagiert.
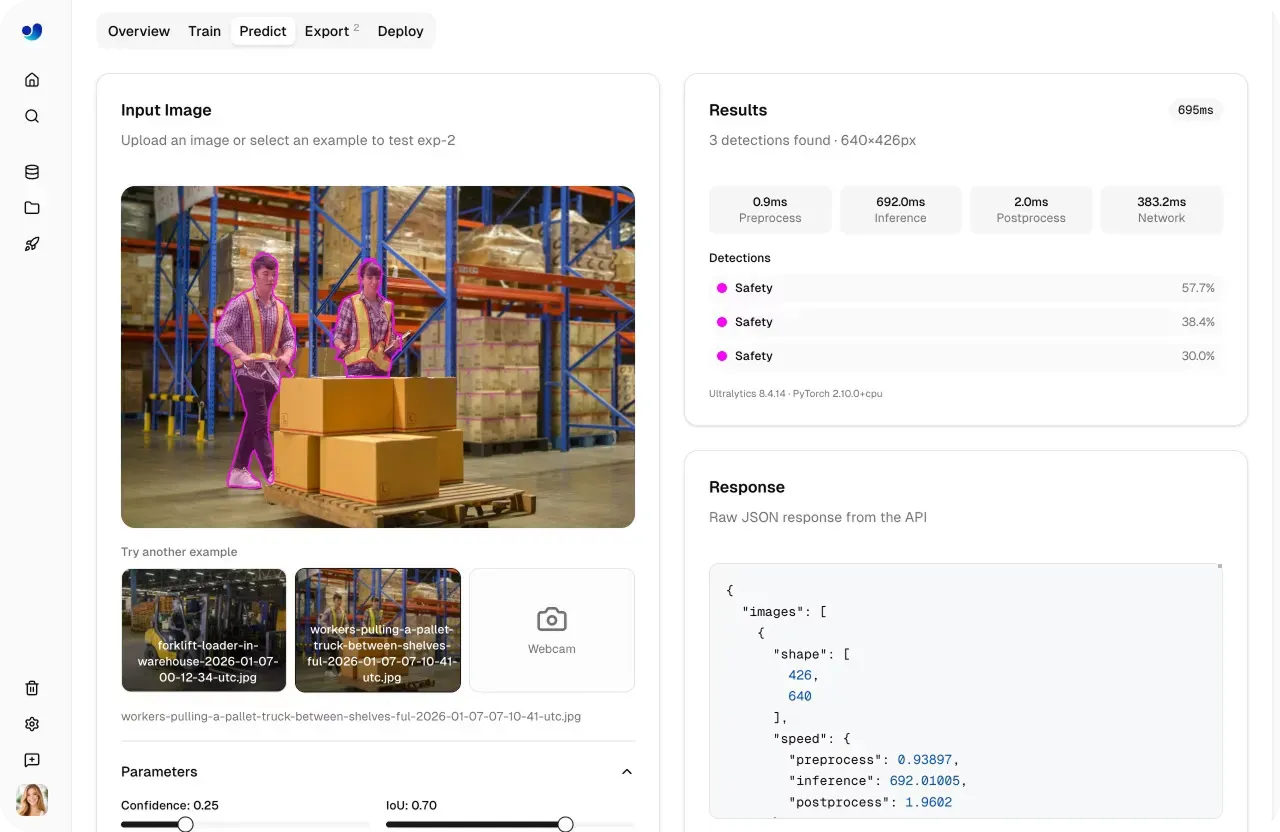
Abb. 2. Ein Beispiel für die Validierung eines Modells mit dem Predict-Tab (Quelle)
Das bedeutet, dass du mit wenigen Klicks verschiedene Eingaben testen, Parameter anpassen und die Performance innerhalb einer einzigen Oberfläche bewerten kannst, bevor du zur Bereitstellung übergehst.
Link to this sectionGemeinsame Inferenz für Tests oder leichte Nutzung#
Angenommen, du hast ein Modell trainiert und über den Predict-Tab validiert. Der nächste Schritt ist oft die Integration dieses Modells in eine Anwendung oder einen Workflow.
Anstatt Infrastruktur einzurichten oder Server zu verwalten, bietet die Ultralytics Platform gemeinsame Inferenzdienste, mit denen du Daten an dein Modell senden und Vorhersagen über einfache REST APIs empfangen kannst.
Im Hintergrund läuft die geteilte Inferenz auf einem Multi-Tenant-System in einigen Kernregionen, wobei Anfragen automatisch an den nächstgelegenen verfügbaren Dienst weitergeleitet werden. Dies hilft, eine reaktionsschnelle Performance beizubehalten und ermöglicht Benutzern an verschiedenen Standorten einen konsistenten Zugriff auf die Modelle.
Du kannst Eingaben über Standard-HTTP-Anfragen senden und strukturierte Ausgaben empfangen, was die Anbindung an Anwendungen, Skripte oder Automatisierungs-Workflows unkompliziert macht. Dieses Setup ist eine hervorragende Option für Entwicklung, Tests, Integrationen oder leichtere Nutzung, bevor du zu skalierbareren Produktionseinsätzen wechselst.
Link to this sectionGlobale Modellbereitstellung über dedizierte Endpunkte#
Sobald ein Modell produktionsreif ist, muss es reale Lasten zuverlässig und skalierbar verarbeiten können. Die Ultralytics Platform unterstützt dies mit dedizierten Endpunkten, auf denen Modelle als Single-Tenant-Dienste in 43 globalen Regionen ausgeführt werden. Die Bereitstellung in der Nähe der Endbenutzer hilft, Latenzen zu reduzieren und eine konsistente Performance an verschiedenen Standorten sicherzustellen.
Jeder Endpunkt läuft mit seinen eigenen zugewiesenen Rechenressourcen und einer eindeutigen URL für Inferenzanfragen. Dieses Maß an Kontrolle ermöglicht es, die Bereitstellung je nach Leistungsanforderungen anzupassen – von einfachen Anwendungsfällen bis hin zu anspruchsvollen Anwendungen mit hohem Durchsatz, die mehr Rechenressourcen erfordern.
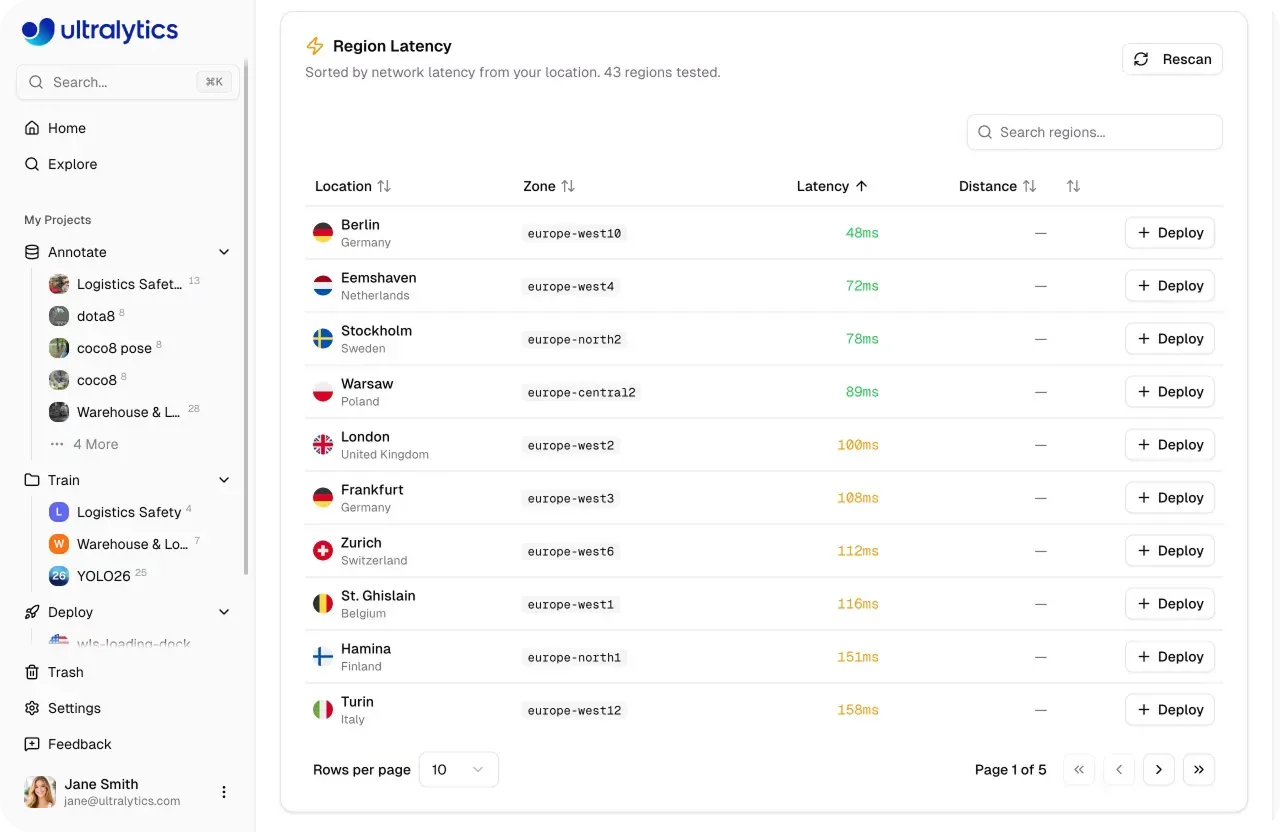
Abb. 3. Du kannst Modelle mit der Ultralytics Platform in 43 globalen Regionen bereitstellen (Quelle)
Dedizierte Endpunkte sind zudem so konzipiert, dass sie sich ändernden Arbeitslasten selbstständig anpassen, mit Auto-Scaling, das Ressourcen basierend auf eingehendem Traffic reguliert. Sie skalieren bei hoher Nachfrage nach oben und bei sinkender Nutzung nach unten. Da Scale-to-Zero standardmäßig aktiviert ist, werden inaktive Endpunkte automatisch heruntergefahren und starten neu, sobald neue Anfragen eintreffen, was die Ressourcennutzung ohne manuelles Eingreifen optimiert.
Link to this sectionModelle einfach exportieren mit der Ultralytics Platform#
Heutzutage wird Edge-KI immer wichtiger, da mehr Anwendungen darauf angewiesen sind, Modelle direkt auf Geräten wie Smartphones, Kameras und eingebetteten Systemen auszuführen. Der lokale Betrieb von Modellen kann auch dabei helfen, Datenschutzanforderungen zu erfüllen, da sensible Daten wie Bilder oder Videostreams direkt auf dem Gerät verarbeitet werden können, ohne an externe Server gesendet zu werden.
In diesen Szenarien müssen Modelle außerhalb der Ultralytics Platform laufen, weshalb der Modellexport ein entscheidender Teil des Bereitstellungsprozesses ist. Ultralytics YOLO-Modelle werden oft mit Python und PyTorch trainiert und können anschließend in 17+ verschiedene Formate exportiert werden, darunter ONNX, TensorRT, CoreML und OpenVINO.
Diese große Auswahl an Formaten stellt die Kompatibilität mit unterschiedlicher Hardware sicher, von leistungsstarken Grafikprozessoren (GPUs) bis hin zu Mobil- und eingebetteten Geräten. Zudem ermöglicht der Export eine Leistungsoptimierung für spezifische Umgebungen.
Je nach Format können Modelle schnellere Inferenzgeschwindigkeiten erzielen, wie etwa eine verbesserte GPU-Performance mit TensorRT oder optimierte CPU-Ausführung mit ONNX und OpenVINO. Optionen wie FP16- und INT8-Quantisierung können die Modellgröße weiter reduzieren und den Durchsatz verbessern, was besonders für Edge-Bereitstellungen nützlich ist.
Auf der Ultralytics Platform ist der Export direkt in den Workflow integriert, sodass optimierte Modelle mit wenigen Klicks erstellt werden können. Teams können vom Training zur Ausführung auf externen Systemen übergehen, ohne zusätzlichen Overhead zu erzeugen.
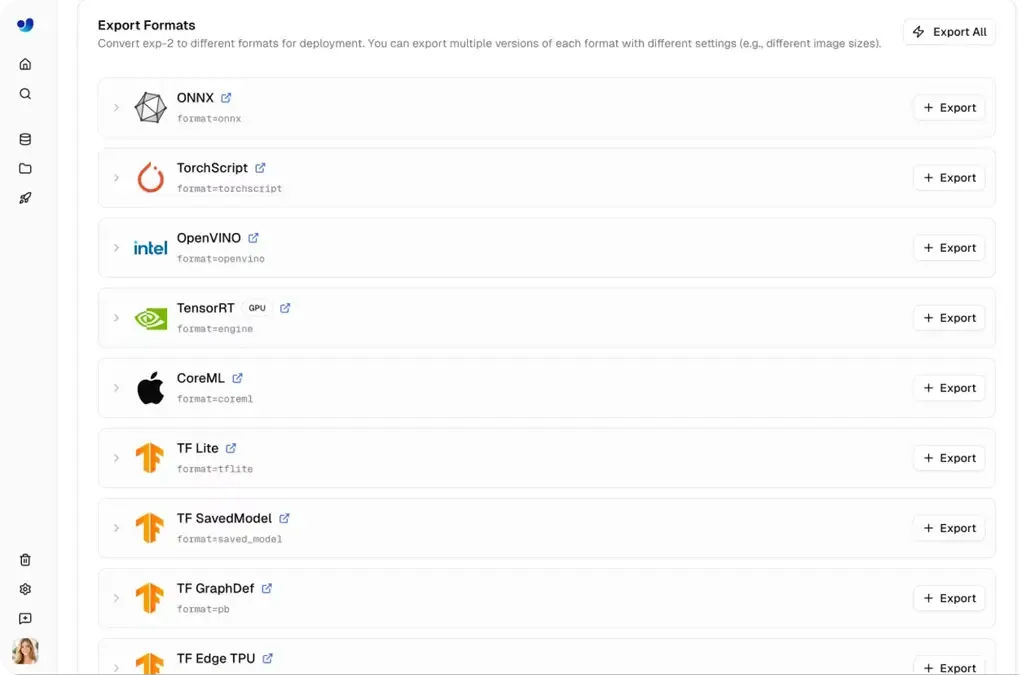
Abb. 4. Eine Auswahl an Exportformaten auf der Ultralytics Platform.
Link to this sectionDie richtige Bereitstellungsoption für Modelle wählen#
Jede Bereitstellungsoption in der Ultralytics Platform unterstützt eine andere Phase des Workflows, von ersten Tests bis hin zum Produktionseinsatz. Hier ist ein Überblick darüber, wann du welche Option nutzen solltest:
- Predict-Tab: Wird normalerweise direkt nach dem Training oder Fine-Tuning verwendet, wenn du die Performance eines Modells mit neuen Daten über browserbasierte Inferenz validieren möchtest.
- Geteilte Inferenz: In dieser Phase können Modelle über APIs in Anwendungen integriert werden, was es ermöglicht, reale Interaktionen während der Entwicklung zu testen.
- Dedizierte Endpunkte: Diese werden für die Produktion eingesetzt, wenn Modelle konsistente Performance, dedizierte Ressourcen und die Fähigkeit zur Skalierung über globale Regionen hinweg benötigen.
- Modellexport: Wenn Modelle außerhalb der Plattform laufen müssen, ermöglicht der Export die Bereitstellung auf Edge-Geräten, mobilen Apps oder benutzerdefinierter Infrastruktur.
Teams durchlaufen diese Optionen oft Schritt für Schritt, von der Validierung über die Integration bis hin zur Bereitstellung in der Produktion – alles innerhalb der Plattform.
Link to this sectionÜberwachung bereitgestellter Modelle mit der Ultralytics Platform#
So wichtig die Bereitstellung auch ist, die Vision-Pipeline endet dort nicht. Sobald ein Modell in der Produktion läuft, ist eine kontinuierliche Überwachung der Schlüssel, um eine dauerhaft zuverlässige Leistung sicherzustellen.
Die Ultralytics Platform bietet integrierte Überwachungstools, die Teams klare Einblicke in das Verhalten ihrer Vision-KI-Modelle geben und so einen strukturierteren MLOps-Workflow unterstützen.
Die Deploy-Seite enthält ein Dashboard, das wichtige Metriken wie Gesamtanfragen, aktive Bereitstellungen, Antwortlatenz und Fehlerraten verfolgt. Diese Erkenntnisse helfen Teams, Nutzungsmuster zu verstehen, die Reaktionsfähigkeit des Systems zu bewerten und eine latenzarme Performance über verschiedene Arbeitslasten hinweg zu gewährleisten.
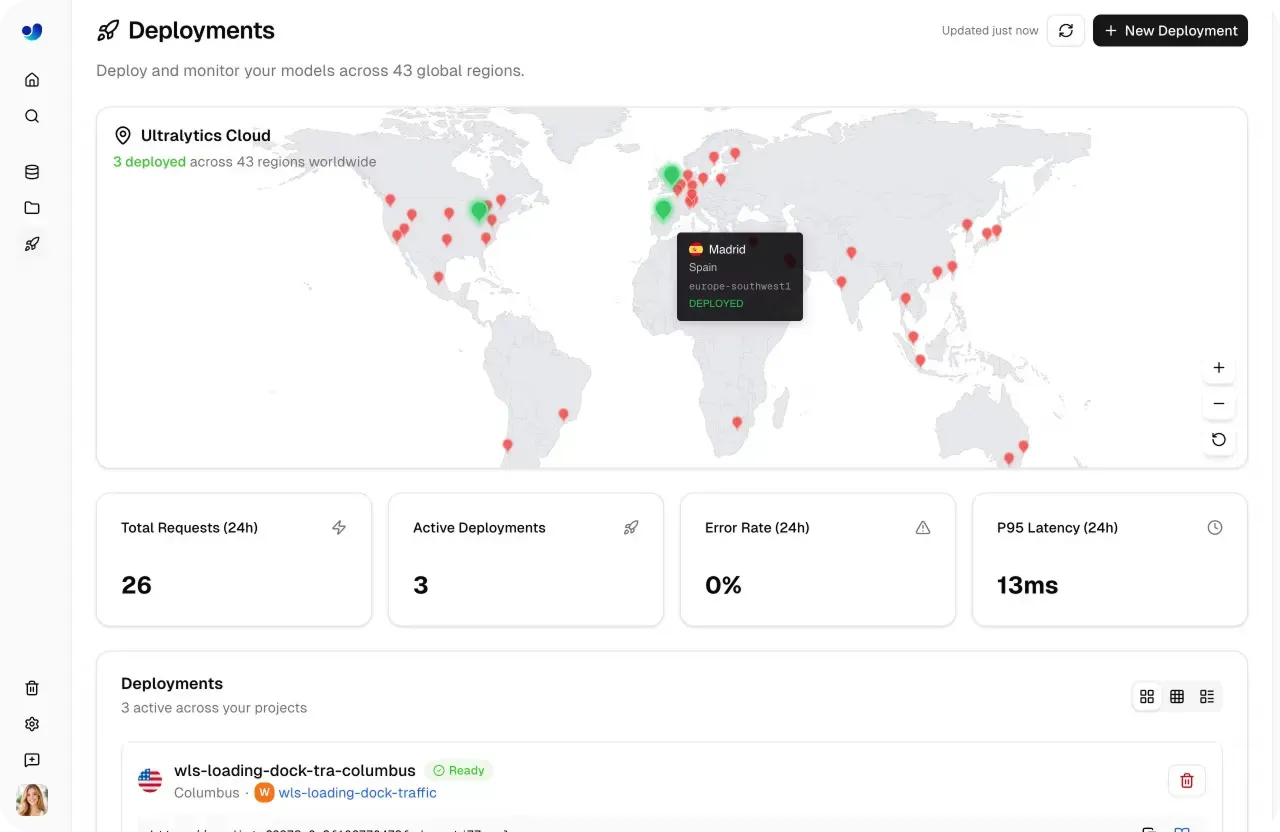
Abb. 5. Die Ultralytics Platform macht die Überwachung bereitgestellter Modelle einfach. (Quelle)
Jeder dedizierte Endpunkt bietet zudem detaillierte Beobachtbarkeit durch individuelle Deployment-Ansichten. Dazu gehören der Zugriff auf Protokolle, der Gesundheitsstatus des Modells und Echtzeit-Leistungsdaten. Protokolle können verwendet werden, um Probleme zu debuggen, fehlgeschlagene Anfragen zu verfolgen und potenzielle Probleme in Bezug auf Abhängigkeiten oder Infrastruktur zu identifizieren.
Da sich Produktionsumgebungen weiterentwickeln, können Faktoren wie sich ändernde Eingabedaten, Skalierungsanforderungen oder veränderte Nutzungsmuster die Genauigkeit und Robustheit des Modells beeinflussen. Durch kontinuierliche Überwachung der Leistungsmetriken können Teams Anomalien erkennen, Engpässe identifizieren und Korrekturmaßnahmen wie Modelloptimierungen oder Ressourcenanpassungen ergreifen, um ein konsistentes und zuverlässiges Modell-Serving aufrechtzuerhalten.
Link to this sectionSkalierbarkeit in die Bereitstellung von Computer-Vision-Modellen integrieren#
Die Skalierung von Computer-Vision-Systemen bedeutete traditionell, Workflows und Frameworks zusammenzuflicken, die nie für die Zusammenarbeit konzipiert waren. Daten-Pipelines, Trainingsschleifen, Bereitstellungsinfrastruktur und Überwachungssysteme befinden sich oft an verschiedenen Orten, was in jeder Phase für Reibungsverluste sorgt.
Die wahre Herausforderung besteht nicht nur darin, Modelle zu bauen, sondern sie in Bewegung zu halten. Der Weg von den Daten zur Produktion, die Anpassung an neue Eingaben, die Bewältigung wachsender Anforderungen und die kontinuierliche Verbesserung ohne Verlangsamung.
Was an der Ultralytics Platform besonders hervorsticht, ist, dass diese Dynamik bereits integriert ist. Anstatt jede Phase als Einzelschritt zu behandeln, verbindet sie diese zu einer kontinuierlichen Schleife, in der Modelle in derselben Umgebung entwickelt, bereitgestellt, beobachtet und aktualisiert werden können.
Dieser Wandel verändert die Art und Weise, wie Teams skalieren. Es geht nicht mehr um die Orchestrierung von Tools oder Infrastruktur, sondern darum, die Dynamik aufrechtzuerhalten, während Systeme wachsen.
Link to this sectionWichtige Erkenntnisse#
Um maschinelle Lernmodelle wie Computer-Vision-Modelle in reale Anwendungen zu bringen, müssen sie zuverlässig, skalierbar und einfach zu verwalten sein. Die Ultralytics Platform vereinfacht diesen Prozess, indem sie verschiedene Funktionen wie Modell-Serving, Bereitstellung und Überwachung in einer einheitlichen Umgebung kombiniert. Mit flexiblen Bereitstellungsoptionen und integrierten Tools können Teams schneller und mit weniger Komplexität von der Experimentierphase in die Produktion gelangen.
Besuche unsere Community und erkunde unser GitHub repository, um mehr zu erfahren. Entdecke unsere Lösungsseiten, um verschiedene Anwendungen wie KI im Gesundheitswesen und Computer Vision in der Logistik zu sehen. Entdecke unsere Lizenzierungsoptionen und fange noch heute an zu bauen!






