Trainiere YOLO-Modelle schneller mit der Ultralytics Platform
Finde heraus, wie du YOLO-Modelle schneller mit der Ultralytics Platform trainierst, einer End-to-End-Umgebung, die entwickelt wurde, um den Weg von der Datenerfassung bis zur Bereitstellung zu beschleunigen.
Letzte Woche hat Ultralytics die Ultralytics Platform eingeführt, einen einheitlichen Arbeitsbereich, der entwickelt wurde, um die Art und Weise, wie Teams Computer-Vision-Modelle erstellen, trainieren und bereitstellen, zu vereinfachen. Anstatt mit mehreren Tools zu jonglieren, bringt die Plattform alles an einem Ort zusammen. Der Weg von der Idee bis zur Bereitstellung von Vision AI-Modellen wird damit völlig unkompliziert.
Dies ist entscheidend, da Computer Vision schnell zu einem zentralen Bestandteil verschiedener Branchen wird. Es unterstützt Anwendungen wie Inspektionssysteme in der Fertigung, Einzelhandelsanalysen und autonome Navigation.
Die Umwandlung dieser vision-gestützten Anwendungen in zuverlässige Systeme hängt davon ab, wie gut die Modelle trainiert sind. Das Modelltraining beinhaltet das Lernen aus gelabelten Daten, damit das Modell Muster erkennen und genaue Vorhersagen treffen kann. Im Allgemeinen führen gut trainierte Modelle zu einer besseren Modellperformance und zuverlässigeren Ergebnissen in realen Anwendungen.
Das Training eines Computer-Vision-Modells ist jedoch nicht immer einfach. Es besteht aus verschiedenen Aspekten wie der Einrichtung von Umgebungen, der Auswahl geeigneter Rechenressourcen, der Optimierung von Hyperparametern und der Nachverfolgung mehrerer Trainingsexperimente. Wenn diese Schritte auf verschiedene Tools und Systeme verteilt sind, wird der Trainings-Workflow schnell komplex und schwer zu verwalten.
Die Ultralytics Platform löst dies, indem sie den gesamten Trainingsprozess in einem einzigen, einheitlichen Dashboard zusammenführt. Du kannst Trainings-Jobs an einem Ort konfigurieren, ausführen und überwachen, egal ob du in der Cloud, lokal oder auf Google Colab arbeitest.
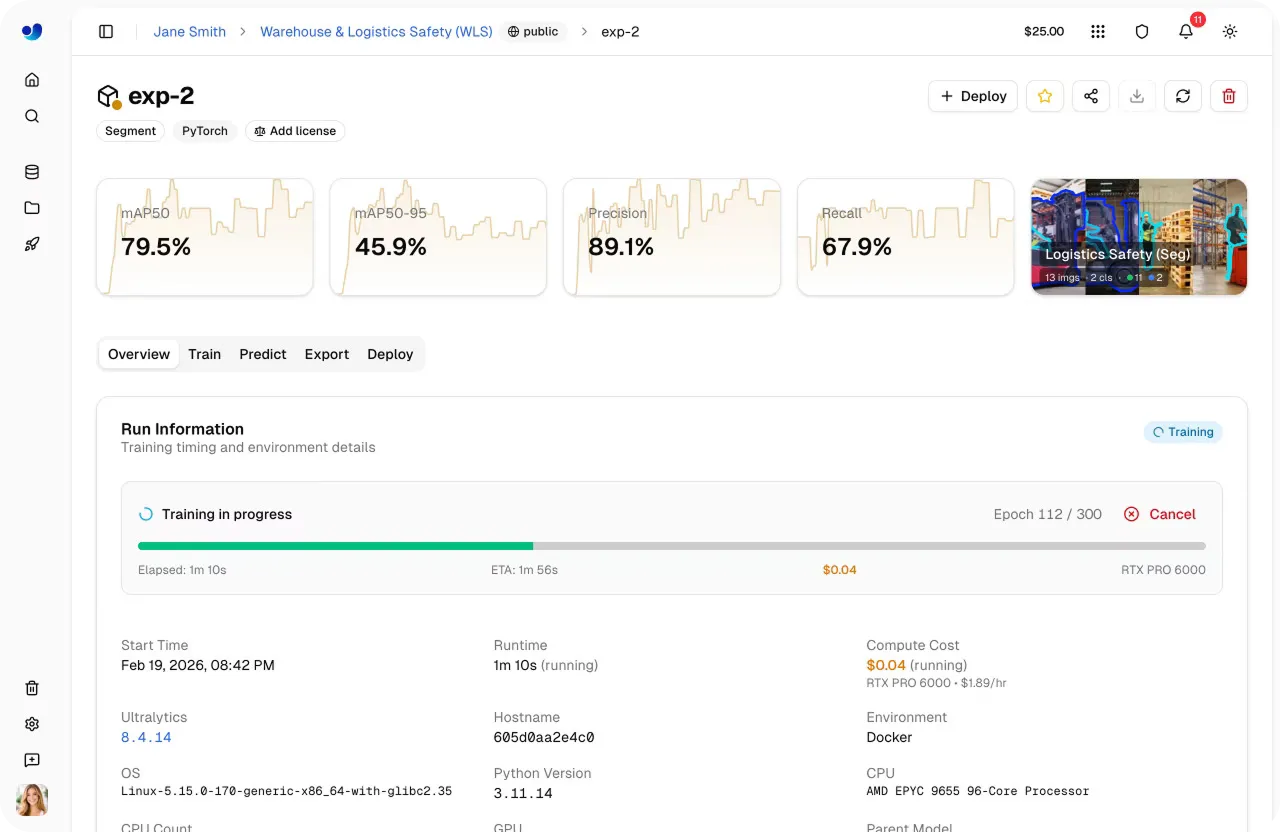
Abb. 1. Ein Einblick in das Modelltraining innerhalb der Ultralytics Platform (Quelle)
In diesem Artikel untersuchen wir, wie die Ultralytics Platform das Modelltraining optimiert und warum sie dir bei deinen Vision AI-Projekten einen Vorsprung verschaffen kann. Fangen wir an!
Link to this sectionComputer-Vision-Modelle lernen durch Modelltraining aus Daten#
Bevor wir uns damit befassen, wie das Modelltraining auf der Ultralytics Platform funktioniert, lass uns einen Schritt zurücktreten und durchgehen, was Modelltraining ist und was dazugehört.
Modelltraining ist der Prozess, bei dem ein Computer-Vision-Modell lernt, visuelle Daten zu interpretieren. Es analysiert Bilder oder Videos und passt seine internen Parameter schrittweise an, um Vision-Aufgaben wie Objektverfolgung, Bildklassifizierung und Instanzsegmentierung genau auszuführen. Mit der Zeit verbessert sich das Modell, indem es Muster direkt aus den Daten lernt, die es sieht.
Die Qualität des Trainings hängt stark von den Datensätzen ab. Du kannst dir einen Datensatz wie einen Stapel Lernkarten vorstellen, die ein Lehrer verwenden würde, um einen Schüler auszubilden, wobei jedes Beispiel dem Modell hilft zu lernen, worauf es achten muss.
Ein typischer Computer-Vision-Datensatz enthält Bilder, normalerweise in Formaten wie JPG oder PNG, sowie Annotationen, die beschreiben, was in jedem Bild enthalten ist. Diese Annotationen, die oft als JSON- oder TXT-Dateien gespeichert sind, liefern die Labels und den Kontext, die das Modell benötigt, um effektiv zu lernen.
Aber beim Training geht es nicht nur darum, Daten in ein Modell einzuspeisen. Es umfasst mehrere wichtige Schritte, von der Vorbereitung des Datensatzes bis zur Auswahl des richtigen Modells und der Konfiguration des Trainingsprozesses. Lass uns als nächstes einen genaueren Blick auf einige dieser Schritte werfen.
Link to this sectionEin Blick darauf, wie Datensätze vorbereitet werden#
Es mag so aussehen, als könntest du sofort mit dem Training eines Modells beginnen, sobald du einen Datensatz hast, aber es gibt ein paar Schritte, die du zuerst unternehmen musst, wie zum Beispiel die Aufteilung des Datensatzes.
Im Allgemeinen wird ein Datensatz in drei Teile unterteilt: Trainingsset, Validierungsset und Testset. Die Trainingsbilder werden verwendet, um dem Modell Muster in den Daten beizubringen, während das Validierungsset hilft, die Performance während des Trainings zu überwachen und fein abzustimmen.
Das Testset wird am Ende verwendet, um zu bewerten, wie gut das Modell bei völlig neuen, unbekannten Daten abschneidet. Dieses Setup hilft sicherzustellen, dass das Modell die Daten nicht nur auswendig lernt, sondern auf reale Szenarien verallgemeinern kann.
Link to this sectionAuswahl des richtigen Modells für das Training#
Ein weiterer wichtiger Schritt vor dem Training ist die Auswahl des Modells, das du verwenden möchtest. In vielen Fällen bedeutet dies die Auswahl eines vortrainierten Modells. Modelle wie Ultralytics YOLO-Modelle sind bereits auf großen Datensätzen trainiert und haben allgemeine visuelle Muster gelernt, was sie zu einem starken Ausgangspunkt macht.
Die Verwendung dieser Modelle ist ein Beispiel für Transfer Learning, bei dem du auf vorhandenem Wissen aufbaust und das Modell an deine spezifische Aufgabe anpasst. Dieser Ansatz trägt dazu bei, das Training zu beschleunigen und die Ergebnisse zu verbessern, insbesondere wenn nur begrenzte Daten zur Verfügung stehen.
Diese Modelle gibt es auch in verschiedenen Größen, wobei jedes einen Kompromiss zwischen Geschwindigkeit und Genauigkeit bietet. Kleinere Modelle sind schneller und effizienter, während größere Modelle tendenziell eine höhere Genauigkeit liefern, aber mehr Rechenleistung erfordern.
Link to this sectionKonfiguration der Trainingsparameter für Vision-Modelle#
Nachdem du einen vorbereiteten Datensatz hast und ein Modell ausgewählt hast, besteht der nächste Schritt darin, zu konfigurieren, wie das Modell lernt.
Ein Computer-Vision-Modell wird unter Verwendung einer Reihe von Parametern trainiert, die bestimmen, wie es Daten verarbeitet, seine Gewichte aktualisiert und sich mit der Zeit verbessert. Diese Einstellungen wirken sich direkt sowohl auf die Trainingsgeschwindigkeit als auch auf die endgültige Genauigkeit aus, was sie für das Erreichen starker Ergebnisse unerlässlich macht.
Hier sind einige der am häufigsten verwendeten Trainingsparameter:
- Epochs (Epochen): Dies stellt dar, wie oft das Modell während des Trainings den gesamten Datensatz durchläuft. Die Erhöhung der Anzahl der Epochen gibt dem Modell mehr Möglichkeiten, Muster aus den Daten zu lernen.
- Batch size (Batch-Größe): Dies ist die Anzahl der Bilder, die in einem einzigen Trainingsschritt zusammen verarbeitet werden. Größere Batch-Größen können das Training beschleunigen, erfordern aber mehr Speicher.
- Image size (Bildgröße): Dies gibt die Auflösung der während des Trainings verwendeten Eingabebilder an. Höhere Auflösungen können die Erkennungsgenauigkeit verbessern, erhöhen aber die Rechenkosten.
- Learning rate (Lernrate): Dies ist die Rate, mit der das Modell während des Trainings seine internen Parameter aktualisiert. Werte, die zu hoch oder zu niedrig sind, können das Training instabil machen.
- Optimizer (Optimierer): Dies ist der Algorithmus, der für die Aktualisierung der Modellparameter basierend auf dem bei jeder Trainingsiteration berechneten Fehler verantwortlich ist.
In Ultralytics YOLO-basierten Workflows werden diese Konfigurationen normalerweise in einer YAML-Datei definiert. Diese Datei legt Datensatzpfade, Klassennamen und die Aufteilung der Daten fest. Sie fungiert als zentrale Konfiguration, die dem Modell mitteilt, wie es den Datensatz interpretieren soll.
Link to this sectionVon fragmentierten Workflows zu einer einheitlichen Erfahrung mit der Ultralytics Platform#
Wir haben gerade einige der wichtigsten Schritte beim Training eines Computer-Vision-Modells besprochen, von der Vorbereitung der Datensätze bis zur Auswahl eines Modells und der Konfiguration der Trainingsparameter. In der Praxis geht der Prozess oft weiter und beinhaltet das Nachverfolgen von Experimenten, das Vergleichen mehrerer Trainingsläufe und die kontinuierliche Verbesserung der Modelle im Laufe der Zeit.
Diese Schritte werden selten an einem einzigen Ort abgewickelt. Datensätze werden möglicherweise in einem Tool vorbereitet, Trainingsläufe in einer anderen Umgebung ausgeführt und das Experiment-Tracking separat verwaltet. Mit dem Wachstum der Projekte erhöht diese Fragmentierung die Komplexität, verlangsamt die Iteration und macht es schwieriger, alles organisiert zu halten.
Die Ultralytics Platform beseitigt diese Komplexität, indem sie den gesamten Trainings-Workflow in eine Umgebung bringt. Anstatt zwischen Tools zu wechseln, kannst du Datensätze verwalten, das Training konfigurieren, Experimente ausführen und Ergebnisse überwachen – alles an einem Ort.
Lass uns als nächstes eintauchen, wie die Ultralytics Platform das Modelltraining intelligenter macht.
Link to this sectionVon der Ultralytics Platform unterstützte Trainingsoptionen#
In realen Anwendungen erfordert das Training eines Computer-Vision-Modells oft flexible Umgebungen. Abhängig von der Größe deines Datensatzes, der Komplexität des Modells und der verfügbaren Hardware kannst du wählen, ob du das Training in der Cloud, auf einem lokalen Rechner oder über externe Notebook-Umgebungen durchführen möchtest.
Die Ultralytics Platform unterstützt die folgenden Trainingsoptionen, um diesen Anforderungen gerecht zu werden:
- Cloud training: Trainingsläufe auf von Ultralytics verwalteten Cloud-Grafikprozessoren (GPUs). Diese Option ist ideal für größere Datensätze oder komplexere Modelle, die erhebliche Rechenressourcen erfordern.
- Local training: Diese Option nutzt die auf deinem Rechner verfügbare Hardware und eignet sich hervorragend für schnelle Experimente, das Testen von Konfigurationen oder die Arbeit mit kleineren Datensätzen. Für skalierbarere Workloads kann das Training auch in deiner eigenen Cloud-Umgebung ausgeführt werden, wie z. B. AWS oder GCP.
- Google Colab: Mit der Ultralytics Platform kannst du das Training in der gehosteten Notebook-Umgebung von Google Colab ausführen, was einen flexiblen, browserbasierten Workflow ermöglicht, ohne einen lokalen Rechner konfigurieren zu müssen.
Link to this sectionErkundung des Cloud-Trainings auf der Ultralytics Platform#
Wenn es um Computer-Vision-Projekte geht, ist das Training von Modellen lokal oder über Notebook-Umgebungen nicht immer einfach.
Zum Beispiel hängt die Performance beim lokalen Training vollständig von deiner Hardware ab, was die Rechenleistung einschränken und das Experimentieren verlangsamen kann. GPUs sind für ein effizientes Training unerlässlich, aber nicht jedes Setup hat zuverlässigen Zugriff darauf.
Während Notebook-Umgebungen wie Google Colab eine Alternative bieten, indem sie cloudbasierte GPUs bereitstellen, sind Sitzungen oft temporär und können längere Trainingsläufe unterbrechen. Wenn Datensätze wachsen und Workflows komplexer werden, können diese Einschränkungen schnell zu Engpässen werden, die das Training langsamer und weniger zuverlässig machen.
Die Ultralytics Platform begegnet dem mit ihrer Cloud-Trainingsoption. Sie bietet eine einsatzbereite Umgebung, in der Python-Abhängigkeiten und Frameworks wie PyTorch vorkonfiguriert sind, sodass du ohne zusätzliche Einrichtung mit dem Training beginnen kannst.
Über ein einziges Dashboard kannst du Trainings-Jobs starten und den Fortschritt in Echtzeit überwachen. Das macht es einfacher, sich auf die Verbesserung deiner Modelle zu konzentrieren, anstatt die Infrastruktur zu verwalten.
Lass uns nun sehen, wie du mit dem Cloud-Training auf der Ultralytics Platform loslegst.
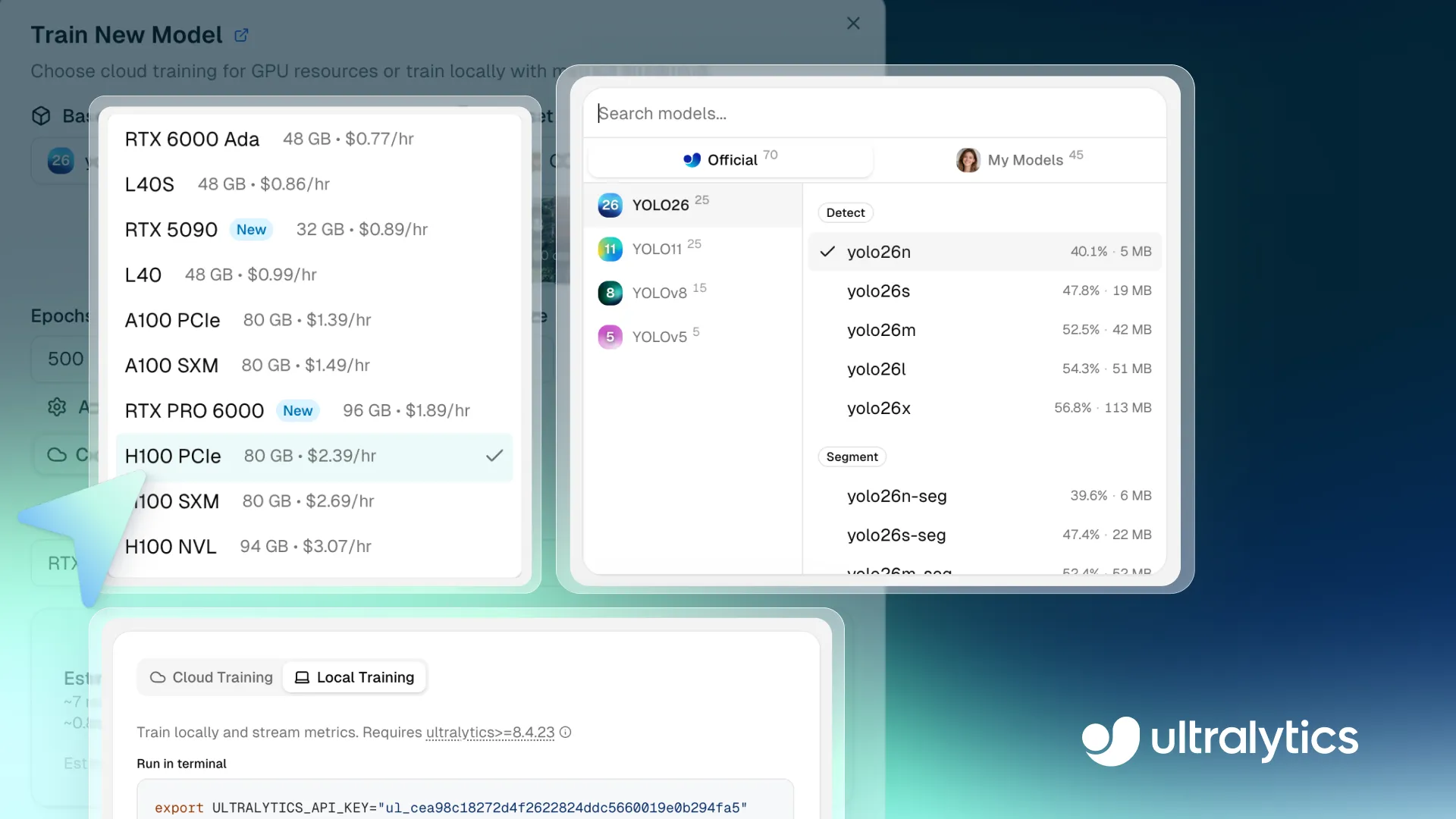
Link to this sectionSchritt 1: Wähle ein Basismodell#
Der erste Schritt ist die Auswahl eines Basismodells für deinen Trainingslauf. Du kannst ein vortrainiertes Ultralytics YOLO model auswählen, ein Community-Modell klonen oder deine eigenen vortrainierten Gewichte hochladen, um benutzerdefinierte Anforderungen zu erfüllen.
Die Plattform unterstützt alle Ultralytics YOLO-Modelle, einschließlich Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8 und Ultralytics YOLOv5, die jeweils in verschiedenen Größenvarianten wie nano (n), small (s), medium (m), large (l) und extra-large (x) erhältlich sind. Da verschiedene Modellvarianten einen Kompromiss zwischen Geschwindigkeit und Genauigkeit bieten, kannst du ein Modell auswählen, das deinen Performance- und Rechenanforderungen entspricht.
Diese Modelle unterstützen eine Reihe von Computer-Vision-Aufgaben, die Ultralytics YOLO-Benutzern bereits vertraut sind, einschließlich Objektverfolgung, Instanzsegmentierung, Bildklassifizierung, orientierte Bounding Box (OBB)-Erkennung und Pose-Schätzung.
Wenn du spezielle Anforderungen hast, kannst du auch deine eigenen vortrainierten Modellgewichte hochladen. Das bedeutet, dass du das Training fortsetzen oder ein bestehendes Modell wie einen Objektdetektor innerhalb der Plattform feinabstimmen kannst, anstatt bei Null anzufangen. Dies ist besonders nützlich, wenn du bereits ein Modell anderswo trainiert hast oder ein Modell an einen spezielleren Anwendungsfall anpassen möchtest.
Link to this sectionSchritt 2: Wähle einen Datensatz#
Der nächste Schritt ist die Auswahl eines Datensatzes für das Training. Auf der Ultralytics Platform kannst du bereits existierende Datensätze wie den COCO-Datensatz verwenden, Datensätze aus der Community klonen oder deinen eigenen benutzerdefinierten Datensatz hochladen, der auf deine spezifische Anwendung zugeschnitten ist.
Die Plattform unterstützt gängige Annotationsformate wie Ultralytics YOLO und COCO und kann auch rohe Bild-Uploads verarbeiten, falls du benutzerdefinierte Daten direkt auf der Plattform annotieren möchtest.
Nach dem Hochladen werden die Datensätze automatisch verarbeitet, einschließlich Validierung, Normalisierung, Label-Parsing und Statistikerstellung. Dies gibt dir unmittelbare Transparenz über deine Daten, einschließlich Klassenverteilungen und Datensatzstruktur, und hilft sicherzustellen, dass alles für das Training bereit ist.
Datensätze werden auch automatisch mit Trainingsläufen verknüpft, sodass du nachverfolgen kannst, welche Daten für welches Modell verwendet wurden, und Konsistenz über Experimente hinweg beibehalten kannst.
Link to this sectionSchritt 3: Konfiguriere die Trainingsparameter#
Nach der Auswahl des Datensatzes kannst du die Trainingsparameter konfigurieren, die steuern, wie das Modell lernt. Dazu gehören Epochen, Batch-Größe, Bildgröße und der Laufname für das Trainingsprotokoll. Viele dieser Parameter beeinflussen sowohl die Trainingsdauer als auch die endgültige Performance des Modells.
Für ein kontrollierteres Training kannst du auf der Plattform auch erweiterte Parameter wie die Lernrate, den Optimierertyp, Farbeinstellungen für die Augmentierung und andere Trainingsoptionen anpassen. Diese Einstellungen können den Trainingsprozess feinabstimmen, um die Modellgenauigkeit und Stabilität zu verbessern.
Link to this sectionSchritt 4: Wähle eine GPU#
Als nächstes kannst du die GPU-Konfiguration für deinen Trainingslauf auswählen. Die Auswahl der richtigen GPU hängt von Faktoren wie Datensatzgröße, Batch-Größe, Bildauflösung und Modellkomplexität ab. Das Finden des richtigen Gleichgewichts hilft, das Training effizient zu halten, ohne mehr Rechenleistung als nötig zu verbrauchen.
Die Ultralytics Platform bietet 22 GPU-Optionen mit unterschiedlichen Stufen von VRAM (Speicher auf einer GPU) und Rechenleistung, die alles von kleinen Aufgaben bis hin zu großen Workloads unterstützen.
Damit kannst du die Hardware an deine spezifischen Bedürfnisse anpassen, egal ob du leichtgewichtige Modelle trainierst oder mit großen, komplexen Datensätzen arbeitest. Um mehr zu erfahren, sieh dir die Liste der verfügbaren GPUs auf der Platform training docs-Seite von Ultralytics an.
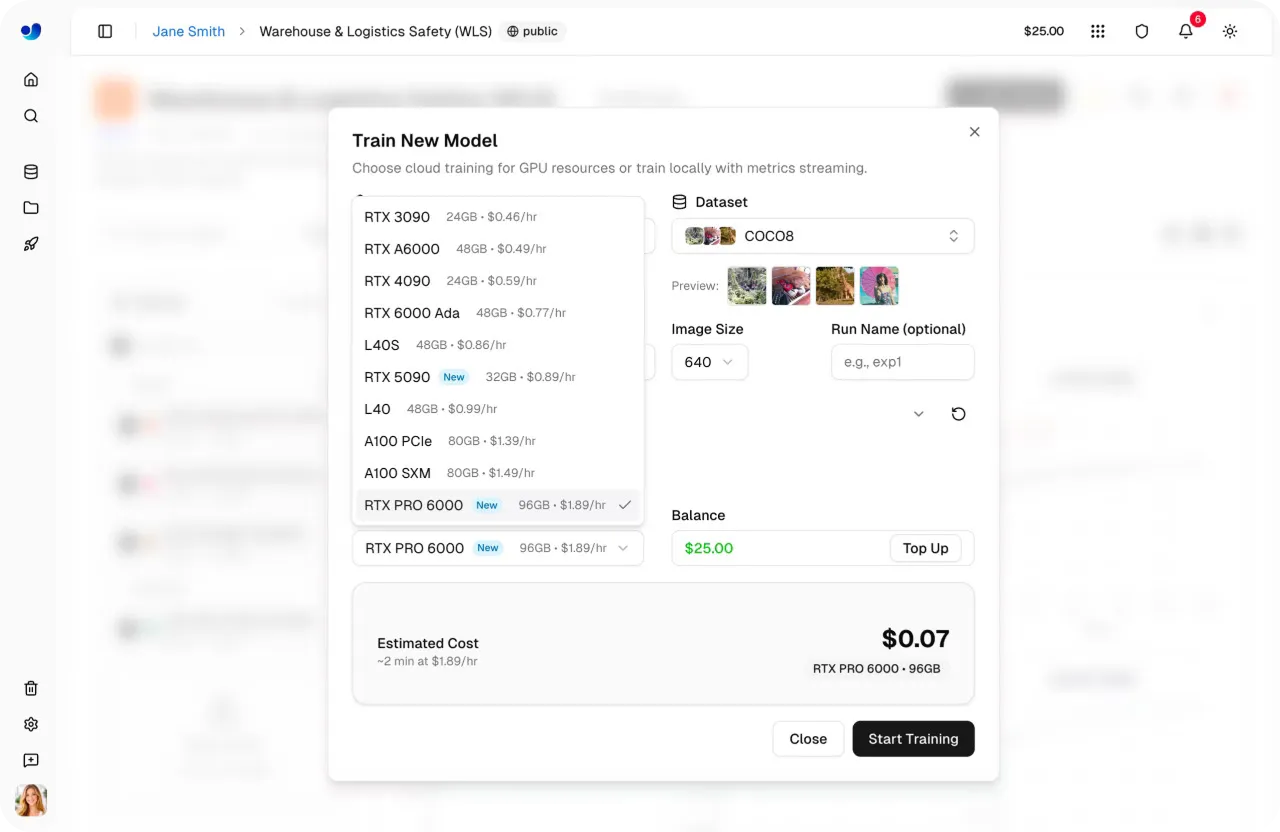
Abb. 2. Einige der über die Ultralytics Platform aktivierten GPU-Optionen (Quelle)
Link to this sectionSchritt 5: Cloud-Training starten#
Sobald du das Modell, den Datensatz, die Trainingsparameter und die Rechenoption ausgewählt hast, ist das Starten eines Trainingslaufs schnell erledigt. Über das Dashboard kannst du das Training mit einem einzigen Klick starten, und die Plattform kümmert sich um den Rest, indem sie die Umgebung initialisiert und den Job auf der ausgewählten GPU ausführt.
Sobald das Training beginnt, kannst du den Fortschritt direkt auf der Plattform überwachen. Der Tab "Train" bietet Echtzeit-Transparenz zu wichtigen Metriken, einschließlich Performance-Metriken, Verlustkurven, Systemauslastung und Live-Trainingsprotokollen.
Um mehr über das lokale Training oder die Verwendung von Google Colab mit der Ultralytics Platform zu erfahren, kannst du weitere Tutorials in der offiziellen Platform documentation von Ultralytics erkunden.
Link to this sectionModelle auf der Ultralytics Platform bewerten und vergleichen#
Nach Abschluss des Trainings besteht der nächste Schritt darin, zu bewerten, wie gut dein Modell abschneidet. Auf der Ultralytics Platform kannst du mehrere Trainingsläufe innerhalb eines Projekts vergleichen, was dir eine klare Sicht darauf gibt, wie verschiedene Experimente abschneiden.
Bei der Entwicklung von Modellen wird das Training oft mehrmals mit unterschiedlichen Einstellungen wiederholt, wie z. B. durch Ändern der Lernrate, der Batch-Größe oder der Modellgröße, um die Ergebnisse zu verbessern. Jeder dieser Läufe produziert ein etwas anderes Modell, weshalb ein Vergleich unerlässlich ist.
Projekte fungieren als zentraler Knotenpunkt, an dem Modelle und Experimente gemeinsam organisiert sind. Du kannst den Fortschritt verfolgen, Ergebnisse überprüfen und fokussiert bleiben, ohne zwischen verschiedenen Tools oder Ansichten wechseln zu müssen.
Von dieser einheitlichen Ansicht aus kannst du auch wichtige Performance-Metriken wie Precision, Recall und mAP (mean average precision) analysieren, um zu verstehen, wie dein Modell über verschiedene Klassen hinweg abschneidet. Du kannst auch Trainingsläufe Seite an Seite vergleichen, um zu identifizieren, welche Konfigurationen die besten Ergebnisse liefern.
Um diese Metriken zu ergänzen, kannst du den Predict-Tab verwenden, um trainierte Modelle schnell an Beispielbildern oder -daten zu testen, was dir hilft, die Performance visuell zu validieren und potenzielle Probleme zu erkennen.
Mit diesen Erkenntnissen kannst du das leistungsstärkste Modell auswählen, das normalerweise als „best.pt“-Checkpunkt gespeichert wird, und zur nächsten Stufe übergehen, sei es eine weitere Evaluierung, die Verwendung des Modells zur Durchführung von Schlussfolgerungen (Inference) oder die Modellbereitstellung über die Plattform.
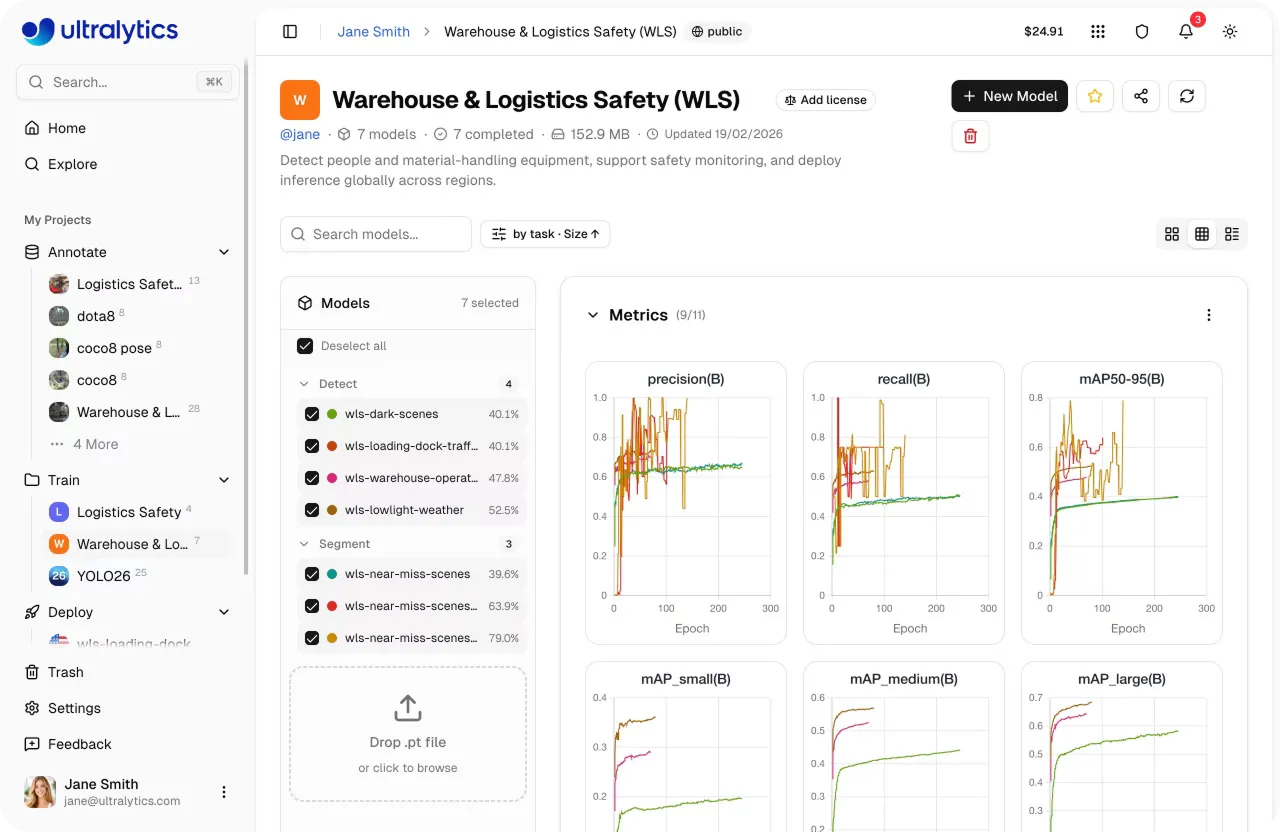
Abb. 3. Ein Beispiel für das Anzeigen von Metriken auf der Ultralytics Platform (Quelle)
Link to this sectionSchätzung der Trainingskosten innerhalb der Ultralytics Platform#
Das Training von Objekterkennungsmodellen in der Cloud verursacht Rechenkosten, insbesondere wenn du auf leistungsstarke GPUs zugreifst. Um dies komfortabler zu gestalten, bietet die Ultralytics Platform eine Kostenschätzung, bevor das Training beginnt.
Sie gibt dir klare Transparenz über die erwartete Nutzung, was dir hilft, Workloads zu planen, Budgets zu verwalten und unerwartete Kosten zu vermeiden, bevor du einen Trainings-Job startest. Hier erfährst du, wie du die geschätzten Kosten überprüfen kannst, bevor du mit dem Training beginnst.
Link to this sectionWie die Trainingszeit geschätzt wird#
Um die Kosten genau zu schätzen, berechnet die Plattform zuerst, wie lange eine einzelne Trainingsepoche dauern wird. Dies hängt von Faktoren wie Datensatzgröße, Modellgröße, Bildauflösung, Batch-Größe und der Geschwindigkeit der ausgewählten GPU ab.
Unter Verwendung dieser Eingaben bestimmt sie die geschätzte Zeit pro Epoche und skaliert sie auf den gesamten Trainingslauf. Die Gesamtdauer wird durch die Kombination der Zeit über alle Epochen mit einem kleinen Start-Mehraufwand berechnet.
Der Mehraufwand berücksichtigt Aufgaben wie das Initialisieren der Umgebung, das Laden von Datensätzen und das Vorbereiten der GPU, wodurch sichergestellt wird, dass die Schätzung den vollständigen Trainingsprozess widerspiegelt und nicht nur die Trainingsschleife.
Link to this sectionWie die Trainingskosten berechnet werden#
Sobald die gesamte Trainingszeit geschätzt ist, rechnet die Plattform sie unter Verwendung des Stundensatzes der ausgewählten GPU in Kosten um.
Durch die Kombination der Trainingsdauer mit der GPU-Preisgestaltung können wir eine klare Schätzung erhalten, wie viel der Lauf kosten wird, noch bevor er beginnt.
Die Transparenz im Voraus macht es einfach, dein Setup anzupassen, wie z. B. durch das Optimieren von Trainingsparametern oder die Auswahl einer anderen GPU, sodass du Performance und Kosten effektiver ausbalancieren kannst.
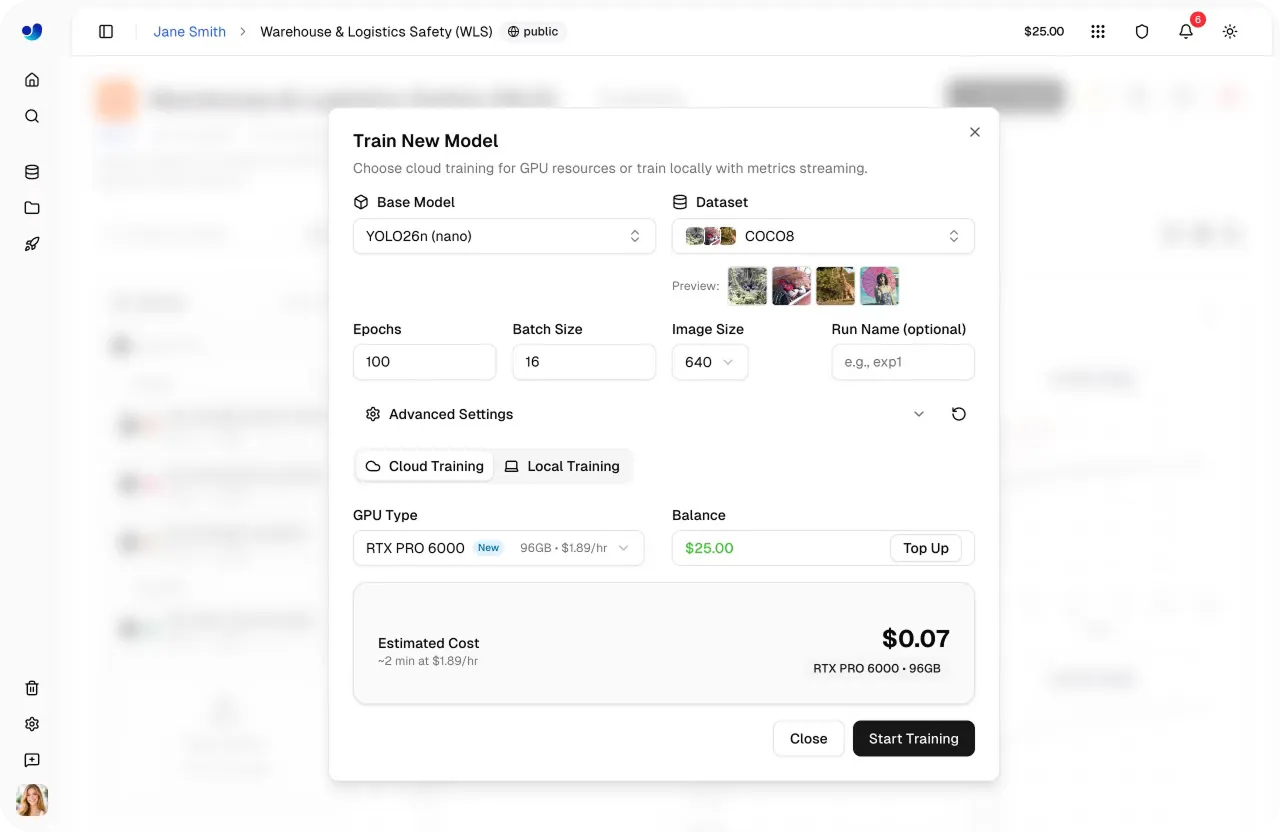
Abb. 4. Einrichten des Modelltrainings und Schätzen der Kosten innerhalb der Ultralytics Platform (Quelle)
Link to this sectionHauptvorteile der Verwendung der Ultralytics Platform für das Modelltraining#
Bisher sind wir die wichtigsten Schritte beim Training von Computer-Vision-Modellen durchgegangen und wie sie auf der Ultralytics Platform zusammenkommen.
Über diese Kernfunktionen hinaus gibt es zusätzliche Fähigkeiten, die den Trainings-Workflow verbessern. Hier ist ein Überblick über einige der wichtigsten Vorteile der Verwendung der Ultralytics Platform für das Modelltraining:
- Integrierte Experiment-Reproduzierbarkeit: Jeder Trainingslauf wird automatisch mit seiner vollständigen Konfiguration protokolliert, einschließlich Modell, Datensatz, Parametern und Rechen-Setup. Dies macht es einfach, Experimente erneut zu besuchen und Ergebnisse zuverlässig zu reproduzieren.
- Training-Erkenntnisse im Zeitverlauf: Anstatt nur die Endergebnisse zu sehen, kannst du nachverfolgen, wie sich die Leistung über die Epochen hinweg entwickelt, was dir hilft, das Modellverhalten während des Trainings besser zu verstehen.
- Reduzierter betrieblicher Aufwand: Indem die Plattform die Einrichtung der Umgebung, das Abhängigkeitsmanagement und die Infrastruktur im Hintergrund übernimmt, kannst du dich mehr auf die Modellentwicklung und weniger auf die Einrichtung konzentrieren.
- Zentralisierte Experimentverwaltung: Projekte dienen als zentraler Ort zur Verwaltung von Modellen, Datensätzen und Trainingsläufen, was dabei hilft, Experimente strukturiert zu halten, während Workflows komplexer werden.
Link to this sectionWichtige Erkenntnisse#
Das Training ist eine der wichtigsten Phasen im Lebenszyklus eines Machine-Learning-Modells. Es bestimmt, wie genau ein Modell visuelle Daten erkennen und interpretieren kann.
Durch die Bündelung von Trainingsdatenkonfiguration, Überwachung, Experimentvergleich und Kostenschätzung in einer einzigen Umgebung optimiert die Ultralytics Platform den Prozess der Erstellung leistungsstarker Computer-Vision-Modelle und deren Vorbereitung auf den Einsatz.
Sieh dir unsere wachsende Community und unser GitHub-Repository an, um mehr über Computer Vision zu erfahren. Wenn du Vision-Lösungen entwickeln möchtest, wirf einen Blick auf unsere Lizenzoptionen. Erkunde unsere Lösungsseiten, um mehr über die Vorteile von Computer Vision in der Fertigung und KI in der Landwirtschaft zu erfahren.






