Treine modelos YOLO mais rápido com a Ultralytics Platform
Descobre como treinar modelos YOLO mais rápido com a Ultralytics Platform, um ambiente ponta a ponta criado para acelerar o caminho dos dados até a implantação.
Na semana passada, a Ultralytics apresentou a Ultralytics Platform, um espaço de trabalho unificado projetado para simplificar a forma como as equipes criam, treinam e implantam modelos de visão computacional. Em vez de lidar com várias ferramentas, a plataforma traz tudo para um só lugar. Ir da ideia à implantação com modelos de visão AI torna-se simples.
Isso é crucial porque a visão computacional está se tornando rapidamente uma parte fundamental de vários setores. Ela impulsiona aplicações como inspeção de manufatura, análise de varejo e navegação autônoma.
Transformar essas aplicações habilitadas por visão em sistemas confiáveis depende de quão bem os modelos são treinados. O treinamento de modelos envolve aprender com dados rotulados para que o modelo possa reconhecer padrões e fazer previsões precisas. Em geral, modelos bem treinados levam a um melhor desempenho do modelo e resultados mais confiáveis em aplicações do mundo real.
No entanto, treinar um modelo de visão computacional nem sempre é simples. Consiste em vários aspectos, como configurar ambientes, selecionar recursos de computação apropriados, ajustar hiperparâmetros e rastrear múltiplos experimentos de treinamento. Quando essas etapas estão espalhadas por diferentes ferramentas e sistemas, o fluxo de trabalho de treinamento rapidamente se torna complexo e difícil de gerenciar.
A Ultralytics Platform resolve isso trazendo todo o processo de treinamento para um painel único e unificado. Podes configurar, executar e monitorar tarefas de treinamento em um só lugar, estejas trabalhando na nuvem, localmente ou no Google Colab.
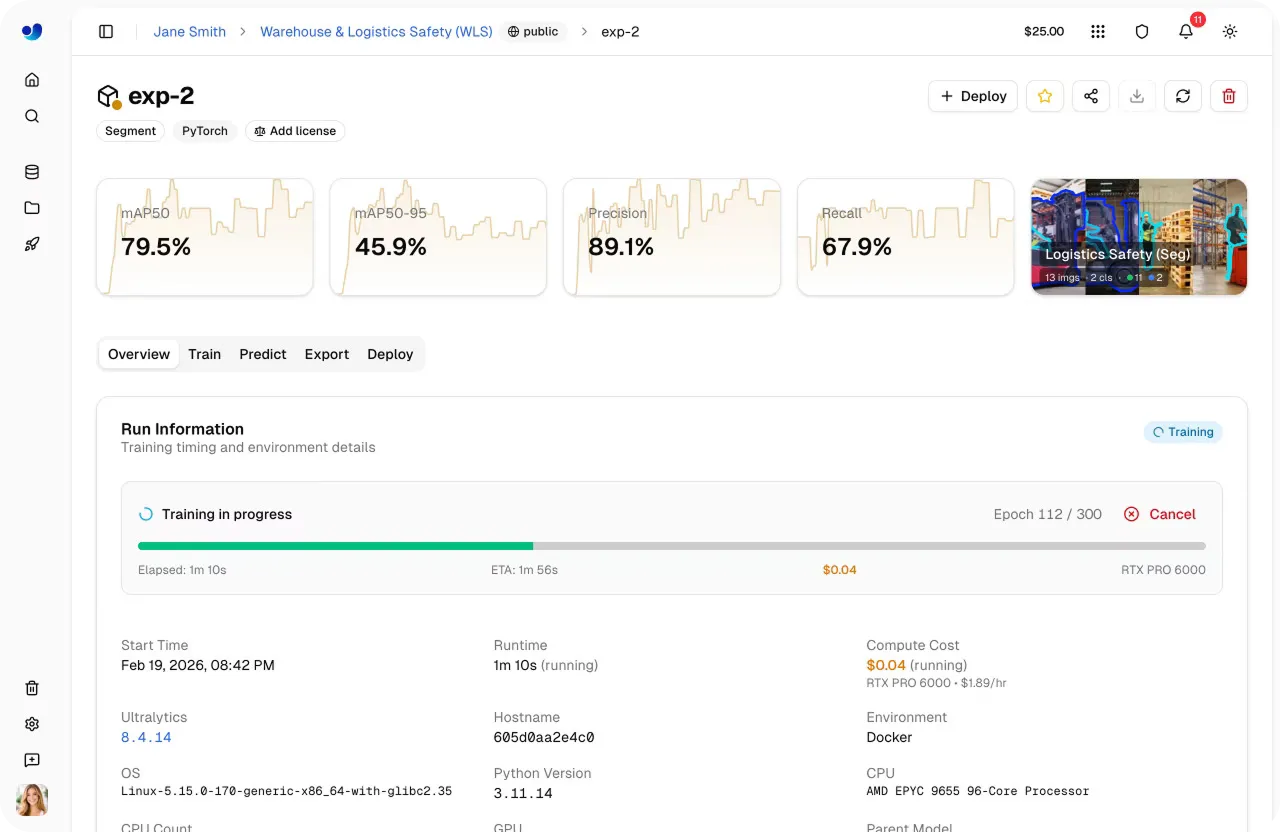
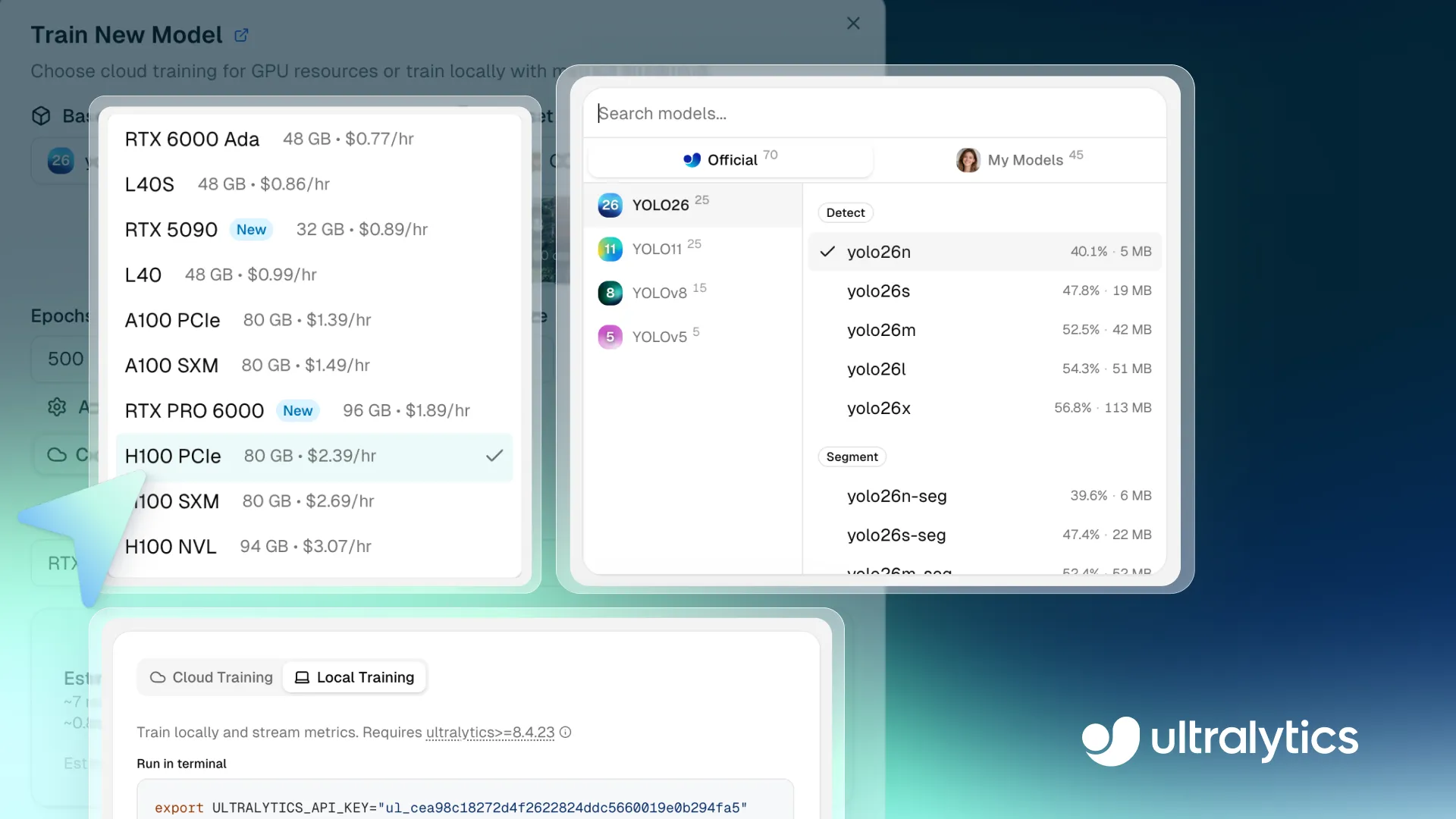
Fig 1. Um vislumbre do treinamento de modelos dentro da Ultralytics Platform (Fonte)
Neste artigo, vamos explorar como a Ultralytics Platform simplifica o model training e por que ela pode te dar uma vantagem em teus projetos de visão AI. Vamos começar!
Link to this sectionModelos de visão computacional aprendem com dados através do treinamento de modelos#
Antes de mergulhar em como o treinamento de modelos funciona na Ultralytics Platform, vamos dar um passo atrás e percorrer o que é o treinamento de modelos e o que está envolvido nisso.
O treinamento de modelos é o processo pelo qual um modelo de visão computacional aprende a interpretar dados visuais. Ele analisa imagens ou vídeos e ajusta gradualmente seus parâmetros internos para realizar vision tasks como detecção de objetos, classificação de imagens e segmentação de instâncias com precisão. Com o tempo, o modelo melhora aprendendo padrões diretamente dos dados que vê.
A qualidade do treinamento depende muito dos datasets. Podes pensar em um dataset como um conjunto de cartões de memória que um professor usaria para treinar um aluno, onde cada exemplo ajuda o modelo a aprender o que procurar.
Um dataset típico de visão computacional inclui imagens, geralmente em formatos como JPG ou PNG, e anotações que descrevem o que há em cada imagem. Essas anotações, frequentemente armazenadas como arquivos JSON ou TXT, fornecem os rótulos e o contexto que o modelo precisa para aprender de forma eficaz.
Mas o treinamento não se resume a alimentar um modelo com dados. Envolve várias etapas importantes, desde a preparação do dataset até a seleção do modelo certo e a configuração do processo de treinamento. A seguir, vamos dar uma olhada mais de perto em algumas dessas etapas.
Link to this sectionUm olhar sobre como os datasets são preparados#
Pode parecer que, uma vez que tenhas um dataset, podes começar imediatamente a treinar um modelo, mas existem algumas etapas que precisas seguir primeiro, como dividir o dataset.
Geralmente, um dataset é dividido em três partes: conjunto de treinamento, conjunto de validação e conjunto de teste. As imagens de treinamento são usadas para ensinar ao modelo padrões nos dados, enquanto o conjunto de validação ajuda a monitorar e ajustar o desempenho durante o treinamento.
O conjunto de teste é usado no final para avaliar o quão bem o modelo performa em dados completamente novos e não vistos. Essa configuração ajuda a garantir que o modelo não apenas memorize os dados, mas possa generalizar para cenários do mundo real.
Link to this sectionSelecionando o modelo certo para treinamento#
Outra etapa importante antes do treinamento é escolher o modelo que queres usar. Em muitos casos, isso significa selecionar um modelo pré-treinado. Modelos como os Ultralytics YOLO já estão treinados em grandes datasets e aprenderam padrões visuais gerais, tornando-os um forte ponto de partida.
Usar esses modelos é um exemplo de transfer learning, onde constróis sobre o conhecimento existente e adaptas o modelo à tua tarefa específica. Essa abordagem ajuda a acelerar o treinamento e melhorar os resultados, especialmente ao trabalhar com dados limitados.
Esses modelos também vêm em diferentes tamanhos, cada um oferecendo um equilíbrio entre velocidade e precisão. Modelos menores são mais rápidos e eficientes, enquanto modelos maiores tendem a entregar maior precisão, mas exigem mais computação.
Link to this sectionConfigurando parâmetros de treinamento para modelos de visão#
Depois de ter um dataset preparado e ter selecionado um modelo, a próxima etapa é configurar como o modelo aprende.
Um modelo de visão computacional é treinado usando um conjunto de parâmetros que determinam como ele processa dados, atualiza seus pesos e melhora com o tempo. Essas configurações impactam diretamente tanto a velocidade de treinamento quanto a precisão final, tornando-as essenciais para alcançar resultados fortes.
Aqui estão alguns dos parâmetros de treinamento mais comumente usados:
- Epochs: Representa quantas vezes o modelo percorre todo o dataset durante o treinamento. Aumentar o número de epochs dá ao modelo mais oportunidades para aprender padrões dos dados.
- Batch size: É o número de imagens processadas juntas em uma única etapa de treinamento. Batch sizes maiores podem acelerar o treinamento, mas exigem mais memória.
- Image size: Especifica a resolução das imagens de entrada usadas durante o treinamento. Resoluções mais altas podem melhorar a precisão da detecção, mas aumentam o custo computacional.
- Learning rate: É a taxa na qual o modelo atualiza seus parâmetros internos durante o treinamento. Valores muito altos ou muito baixos podem tornar o treinamento instável.
- Optimizer: É o algoritmo responsável por atualizar os parâmetros do modelo com base no erro calculado durante cada iteração de treinamento.
Nos fluxos de trabalho baseados em Ultralytics YOLO, essas configurações geralmente são definidas em um arquivo YAML. Este arquivo especifica caminhos de dataset, nomes de classes e como os dados são divididos. Ele atua como uma configuração central que diz ao modelo como interpretar o dataset.
Link to this sectionDe fluxos de trabalho fragmentados para uma experiência unificada com a Ultralytics Platform#
Acabamos de discutir algumas das etapas principais envolvidas no treinamento de um modelo de visão computacional, desde a preparação de datasets até a seleção de um modelo e a configuração de parâmetros de treinamento. Na prática, o processo muitas vezes vai além, incluindo o rastreamento de experimentos, a comparação de múltiplas execuções de treinamento e o refinamento contínuo dos modelos ao longo do tempo.
Essas etapas raramente são tratadas em um só lugar. Datasets podem ser preparados em uma ferramenta, execuções de treinamento feitas em outro ambiente e o rastreamento de experimentos gerenciado separadamente. À medida que os projetos crescem, essa fragmentação adiciona complexidade, retarda a iteração e torna mais difícil manter tudo organizado.
A Ultralytics Platform remove essa complexidade trazendo todo o fluxo de trabalho de treinamento para um único ambiente. Em vez de alternar entre ferramentas, podes gerenciar datasets, configurar o treinamento, executar experimentos e monitorar resultados, tudo em um só lugar.
A seguir, vamos mergulhar em como a Ultralytics Platform torna o treinamento de modelos mais inteligente.
Link to this sectionOpções de treinamento suportadas pela Ultralytics Platform#
Em aplicações do mundo real, treinar um modelo de visão computacional muitas vezes requer ambientes flexíveis. Dependendo do tamanho do teu dataset, da complexidade do modelo e do hardware disponível, podes escolher executar o treinamento na nuvem, em uma máquina local ou através de ambientes de notebook externos.
A Ultralytics Platform suporta as seguintes opções de treinamento para atender a essas necessidades:
- Cloud training: O treinamento é executado em unidades de processamento gráfico (GPUs) em nuvem gerenciadas pela Ultralytics. Esta opção é ideal para datasets maiores ou modelos mais complexos que exigem recursos computacionais significativos.
- Local training: Esta opção usa o hardware disponível na tua máquina e é ótima para experimentos rápidos, testes de configuração ou trabalho com datasets menores. Para cargas de trabalho mais escaláveis, o treinamento também pode ser executado no teu próprio ambiente de nuvem, como AWS ou GCP.
- Google Colab: Com a Ultralytics Platform, podes executar o treinamento no ambiente de notebook hospedado do Google Colab, permitindo um fluxo de trabalho flexível baseado em navegador, sem configurar uma máquina local.
Link to this sectionExplorando o treinamento em nuvem na Ultralytics Platform#
Quando se trata de projetos de visão computacional, treinar modelos localmente ou através de ambientes de notebook nem sempre é fácil.
Por exemplo, com o treinamento local, o desempenho depende inteiramente do teu hardware, o que pode limitar o poder de computação e retardar a experimentação. As GPUs são essenciais para um treinamento eficiente, mas nem toda configuração tem acesso confiável a elas.
Embora ambientes de notebook como o Google Colab ofereçam uma alternativa ao fornecer GPUs baseadas em nuvem, as sessões geralmente são temporárias e podem interromper execuções de treinamento mais longas. À medida que os datasets crescem e os fluxos de trabalho se tornam mais complexos, essas limitações podem rapidamente se transformar em gargalos, tornando o treinamento mais lento e menos confiável.
A Ultralytics Platform resolve isso com sua opção de treinamento em nuvem. Ela fornece um ambiente pronto para uso onde dependências de Python e frameworks como PyTorch estão pré-configurados, permitindo que comeces o treinamento sem configuração adicional.
A partir de um único painel, podes iniciar tarefas de treinamento e monitorar o progresso em tempo real. Isso torna mais fácil focar na melhoria dos teus modelos em vez de gerenciar a infraestrutura.
Agora, vamos ver como começar com o treinamento em nuvem na Ultralytics Platform.
Link to this sectionPasso 1: Selecionar um modelo base#
O primeiro passo é escolher um modelo base para tua execução de treinamento. Podes selecionar um Ultralytics YOLO model pré-treinado, clonar um modelo da comunidade ou enviar teus próprios pesos pré-treinados para atender aos teus requisitos personalizados.
A plataforma suporta todos os modelos Ultralytics YOLO, incluindo Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8 e Ultralytics YOLOv5, cada um disponível em diferentes variantes de tamanho, como nano (n), small (s), medium (m), large (l) e extra-large (x). Com diferentes variantes de modelo oferecendo um equilíbrio entre velocidade e precisão, podes escolher um modelo que se ajuste aos teus requisitos de desempenho e computação.
Esses modelos suportam uma gama de tarefas de visão computacional com as quais os usuários de Ultralytics YOLO já estão familiarizados, incluindo detecção de objetos, segmentação de instâncias, classificação de imagens, detecção de caixas delimitadoras orientadas (OBB) e estimativa de pose.
Se tiveres requisitos personalizados, também podes enviar teus próprios pesos de modelo pré-treinados. Isso significa que podes continuar treinando ou ajustar um modelo existente, como um detector de objetos, dentro da plataforma, em vez de começar do zero. É especialmente útil se já treinaste um modelo em outro lugar ou quiseres adaptar um modelo para um caso de uso mais específico.
Link to this sectionPasso 2: Selecionar um dataset#
O próximo passo é selecionar um dataset para treinamento. Na Ultralytics Platform, podes usar datasets pré-existentes como o dataset COCO, clonar datasets da comunidade ou enviar teu próprio dataset personalizado adaptado à tua aplicação específica.
A plataforma suporta formatos de anotação comuns, como Ultralytics YOLO e COCO, e também pode lidar com uploads de imagens brutas se planejares annotate custom data diretamente na plataforma.
Uma vez enviados, os datasets são processados automaticamente, incluindo validação, normalização, análise de rótulos e geração de estatísticas. Isso te dá visibilidade imediata dos teus dados, incluindo distribuições de classes e estrutura do dataset, e ajuda a garantir que tudo esteja pronto para o treinamento.
Os datasets também são vinculados automaticamente às execuções de treinamento, permitindo que rastrees quais dados foram usados para cada modelo e mantenhas a consistência entre os experimentos.
Link to this sectionPasso 3: Configurar parâmetros de treinamento#
Depois de escolher o dataset, podes configurar os parâmetros de treinamento que controlam como o modelo aprende. Estes incluem epochs, batch size, image size e nome da execução para o log de treinamento. Muitos desses parâmetros influenciam tanto a duração do treinamento quanto o desempenho final do modelo.
Para um treinamento mais controlado, a plataforma também te permite ajustar parâmetros avançados, como learning rate, tipo de otimizador, configurações de aumento de cor e outras opções de treinamento. Essas configurações podem ajustar o processo de treinamento para melhorar a precisão e a estabilidade do modelo.
Link to this sectionPasso 4: Selecionar uma GPU#
A seguir, podes selecionar a configuração de GPU para tua execução de treinamento. Escolher a GPU certa depende de fatores como tamanho do dataset, batch size, resolução da imagem e complexidade do modelo. Encontrar o equilíbrio certo ajuda a manter o treinamento eficiente sem usar mais computação do que o necessário.
A Ultralytics Platform oferece 22 opções de GPU com diferentes níveis de VRAM (memória em uma GPU) e poder de computação, suportando tudo, desde pequenas tarefas até cargas de trabalho de grande escala.
Usando isso, podes combinar o hardware às tuas necessidades específicas, esteja treinando modelos leves ou trabalhando com datasets grandes e complexos. Para saber mais, verifica a lista de GPUs disponíveis na página de Platform training docs da Ultralytics.
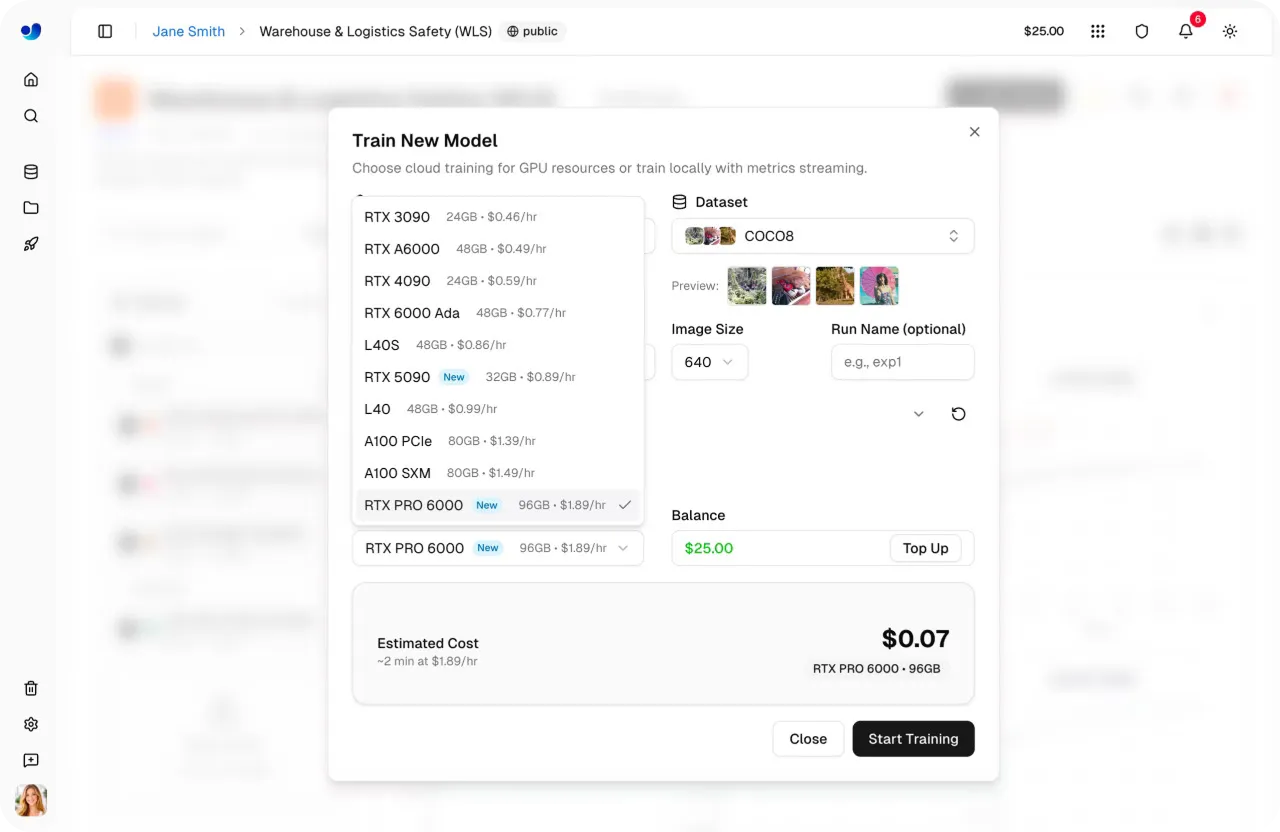
Fig 2. Algumas das opções de GPU habilitadas através da Ultralytics Platform (Fonte)
Link to this sectionPasso 5: Iniciar o treinamento em nuvem#
Uma vez que tenhas selecionado o modelo, dataset, parâmetros de treinamento e opção de computação, iniciar uma execução de treinamento é rápido. A partir do painel, podes iniciar o treinamento com um único clique, e a plataforma cuida do resto inicializando o ambiente e executando o trabalho na GPU selecionada.
À medida que o treinamento começa, podes monitorar o progresso diretamente dentro da plataforma. A aba Train fornece visibilidade em tempo real de métricas importantes, incluindo métricas de desempenho, curvas de perda, uso do sistema e logs de treinamento ao vivo.
Para aprender mais sobre como treinar localmente ou usar o Google Colab com a Ultralytics Platform, podes explorar mais tutoriais dentro da Platform documentation oficial da Ultralytics.
Link to this sectionAvaliando e comparando modelos na Ultralytics Platform#
Assim que o treinamento estiver concluído, o próximo passo é avaliar o quão bem teu modelo performa. Na Ultralytics Platform, podes comparar várias execuções de treinamento dentro de um projeto, dando-te uma visão clara de como diferentes experimentos performam.
Ao desenvolver modelos, o treinamento é frequentemente repetido várias vezes com configurações diferentes, como alterar a learning rate, batch size ou tamanho do modelo, para melhorar os resultados. Cada uma dessas execuções produz um modelo ligeiramente diferente, e é por isso que compará-las é vital.
Os projetos atuam como um hub central onde modelos e experimentos são organizados juntos. Podes rastrear o progresso, revisar resultados e manter o foco sem alternar entre diferentes ferramentas ou visões.
A partir desta visão unificada, também podes analisar métricas de desempenho importantes como precisão, recall e mAP (mean average precision) para entender como teu modelo performa entre diferentes classes. Também podes comparar execuções de treinamento lado a lado para identificar quais configurações entregam os melhores resultados.
Para complementar essas métricas, podes usar a aba Predict para testar rapidamente modelos treinados em imagens ou dados de amostra, ajudando-te a validar visualmente o desempenho e identificar problemas potenciais.
Com esses insights, podes selecionar o modelo com melhor desempenho, normalmente salvo como o checkpoint “best.pt”, e seguir para a próxima etapa, seja avaliação adicional, usar o modelo para executar inferência ou implantação de modelo através da plataforma.
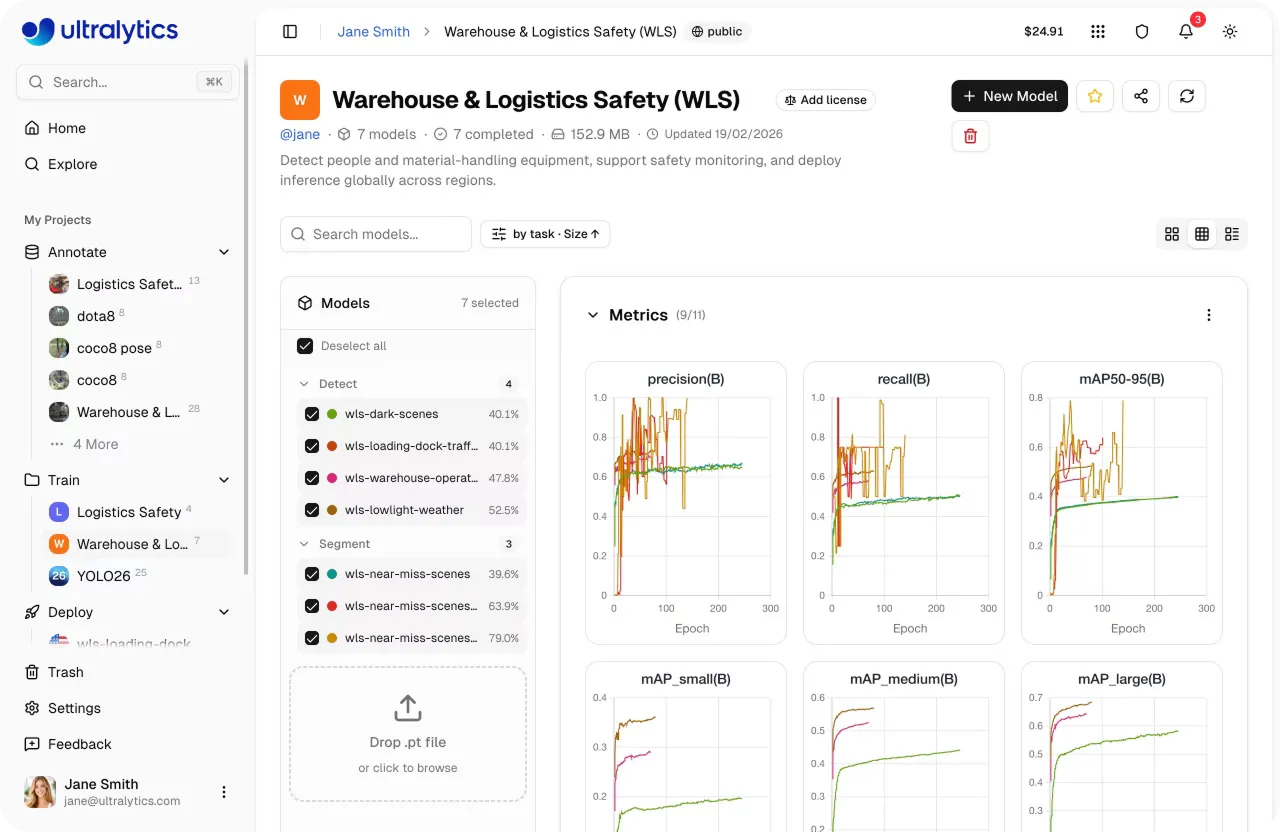
Fig 3. Um exemplo de visualização de métricas na Ultralytics Platform (Fonte)
Link to this sectionEstimando o custo de treinamento dentro da Ultralytics Platform#
Treinar modelos de detecção de objetos na nuvem gera custos de computação, especialmente quando acessas GPUs de alto desempenho. Para tornar isso mais conveniente, a Ultralytics Platform fornece uma estimativa de custo antes que o treinamento comece.
Ela te dá visibilidade clara sobre o uso esperado, ajudando-te a planejar cargas de trabalho, gerenciar orçamentos e evitar despesas inesperadas antes de iniciar uma tarefa de treinamento. Aqui está como podes verificar os custos estimados antes de começar o treinamento.
Link to this sectionComo o tempo de treinamento é estimado#
Para estimar o custo com precisão, a plataforma primeiro calcula quanto tempo levará uma única epoch de treinamento. Isso depende de fatores como tamanho do dataset, tamanho do modelo, resolução da imagem, batch size e a velocidade da GPU selecionada.
Usando essas entradas, ela determina o tempo estimado por epoch e escala para toda a execução de treinamento. A duração total é calculada combinando o tempo de todas as epochs com uma pequena sobrecarga de inicialização.
A sobrecarga contabiliza tarefas como inicializar o ambiente, carregar datasets e preparar a GPU, garantindo que a estimativa reflita o processo completo de treinamento, não apenas o loop de treinamento.
Link to this sectionComo o custo de treinamento é calculado#
Assim que o tempo total de treinamento é estimado, a plataforma converte-o em custo usando a taxa horária da GPU selecionada.
Ao combinar a duração do treinamento com o preço da GPU, podemos obter uma estimativa clara de quanto custará a execução antes mesmo de começar.
Ter visibilidade antecipada torna fácil ajustar tua configuração, como ajustar parâmetros de treinamento ou selecionar uma GPU diferente, para que possas equilibrar desempenho e custo de forma mais eficaz.
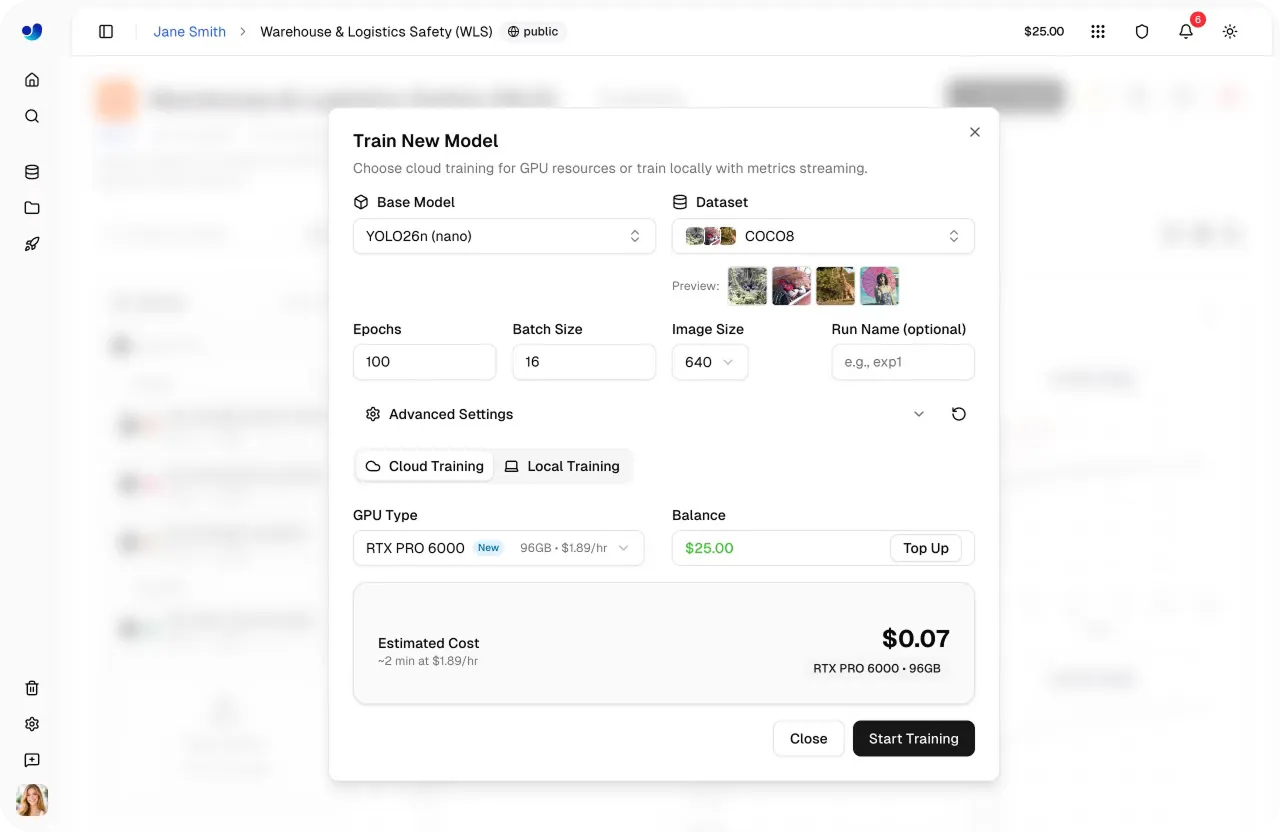
Fig 4. Configurando o treinamento de modelos e estimando o custo dentro da Ultralytics Platform (Fonte)
Link to this sectionPrincipais vantagens de usar a Ultralytics Platform para treinamento de modelos#
Até agora, percorremos as etapas principais envolvidas no treinamento de modelos de visão computacional e como elas se unem na Ultralytics Platform.
Além desses recursos principais, existem capacidades adicionais que aprimoram o fluxo de trabalho de treinamento. Aqui está uma visão geral de alguns dos principais benefícios de usar a Ultralytics Platform para treinamento de modelos:
- Reprodutibilidade de experimentos integrada: Cada execução de treinamento é logada automaticamente com sua configuração completa, incluindo modelo, dataset, parâmetros e configuração de computação. Isso torna simples revisitar experimentos e reproduzir resultados de forma confiável.
- Insights de treinamento ao longo do tempo: Em vez de apenas visualizar os resultados finais, você pode acompanhar como o desempenho evolui ao longo das épocas, ajudando a entender melhor o comportamento do modelo durante o treinamento.
- Carga operacional reduzida: Ao lidar com a configuração de ambiente, gerenciamento de dependências e infraestrutura em segundo plano, a plataforma permite que você se concentre mais no desenvolvimento do modelo e menos na configuração.
- Organização centralizada de experimentos: Projetos atuam como um único local para gerenciar modelos, conjuntos de dados e execuções de treinamento, ajudando a manter os experimentos estruturados à medida que os fluxos de trabalho se tornam mais complexos.
Link to this sectionPrincipais pontos#
O treinamento é um dos estágios mais importantes no ciclo de vida de um modelo de machine learning. Ele determina com que precisão um modelo consegue reconhecer e interpretar dados visuais.
Ao combinar a configuração de dados de treinamento, monitoramento, comparação de experimentos e estimativa de custos em um único ambiente, a Ultralytics Platform simplifica o processo de construção de modelos de visão computacional de alto desempenho e sua preparação para implantação.
Confira nossa crescente comunidade e repositório no GitHub para saber mais sobre visão computacional. Se você busca construir soluções de visão, dê uma olhada em nossas opções de licenciamento. Explore nossas páginas de soluções para saber mais sobre os benefícios da visão computacional na manufatura e IA na agricultura.






