Обучай модели YOLO быстрее с помощью Ultralytics Platform
Узнай, как быстрее обучать модели YOLO с помощью Ultralytics Platform — комплексной среды, созданной для ускорения пути от данных до развертывания.
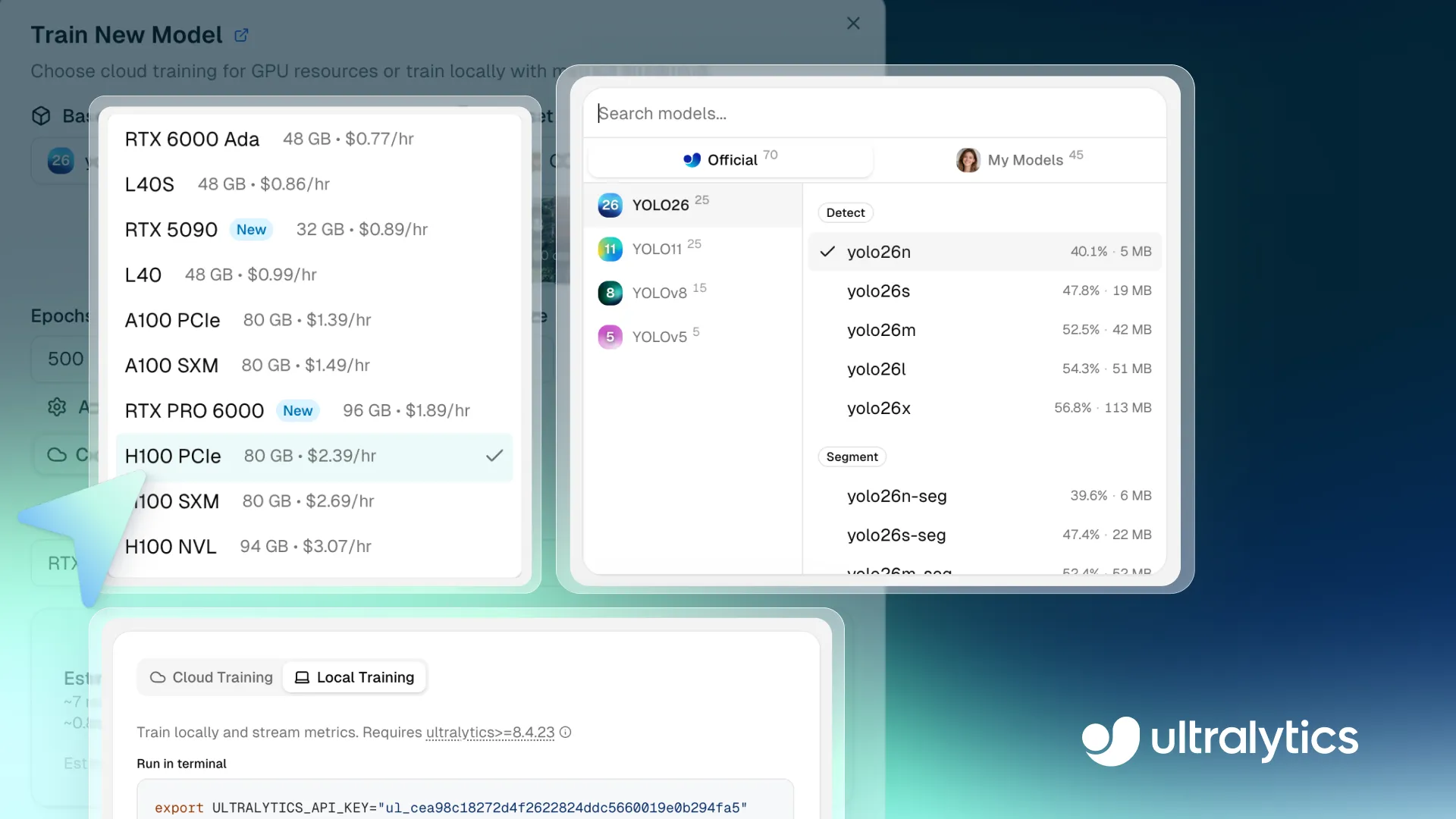
На прошлой неделе Ultralytics представила Ultralytics Platform — единое рабочее пространство, созданное для упрощения создания, обучения и развертывания моделей компьютерного зрения для команд. Вместо того чтобы переключаться между множеством инструментов, платформа собирает всё необходимое в одном месте. Путь от идеи до развертывания моделей машинного зрения становится простым и удобным.
Это критически важно, так как компьютерное зрение стремительно становится неотъемлемой частью различных отраслей. Оно лежит в основе таких решений, как инспекция на производстве, аналитика в ритейле и автономная навигация.
Превращение таких решений в надежные системы зависит от того, насколько качественно обучены модели. Обучение моделей включает в себя процесс обучения на размеченных данных, чтобы модель могла распознавать паттерны и делать точные предсказания. Как правило, хорошо обученные модели обеспечивают более высокую производительность и более надежные результаты в реальных задачах.
Однако обучение модели компьютерного зрения не всегда проходит гладко. Оно состоит из множества этапов, таких как настройка окружения, выбор подходящих вычислительных ресурсов, подбор гиперпараметров и отслеживание множества экспериментов по обучению. Когда эти шаги распределены между разными инструментами и системами, рабочий процесс обучения быстро становится сложным и трудноуправляемым.
Ultralytics Platform решает эту проблему, объединяя весь процесс обучения в единую панель управления. Ты можешь настраивать, запускать и контролировать задачи обучения в одном месте, работаешь ли ты в облаке, локально или в Google Colab.
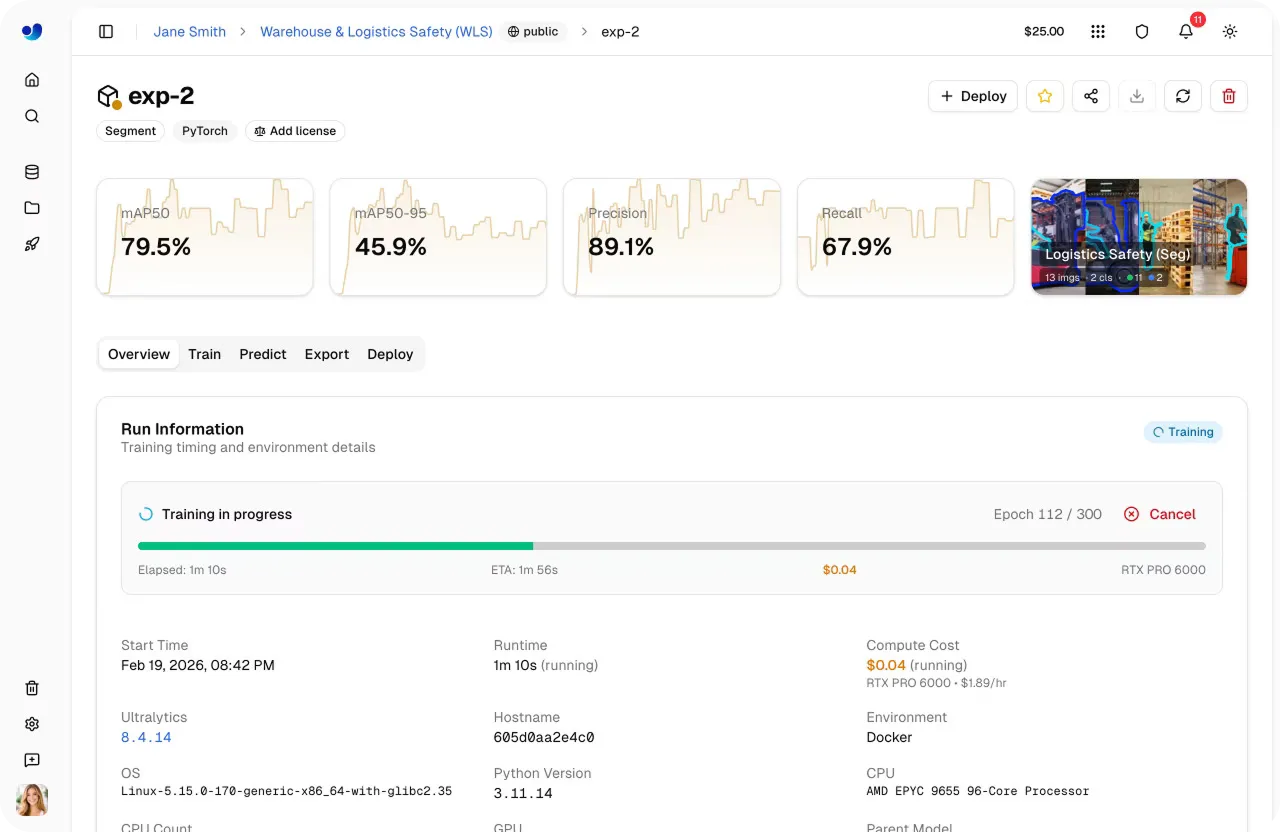
Рис. 1. Взгляд на обучение модели внутри Ultralytics Platform (Источник)
В этой статье мы разберем, как Ultralytics Platform оптимизирует обучение моделей и почему это даст тебе преимущество в проектах по машинному зрению. Давай начнем!
Link to this sectionМодели компьютерного зрения учатся на данных в процессе обучения#
Прежде чем погружаться в то, как устроено обучение моделей на Ultralytics Platform, давай сделаем шаг назад и разберем, что такое обучение моделей и из чего оно состоит.
Обучение моделей — это процесс, в ходе которого модель компьютерного зрения учится интерпретировать визуальные данные. Она анализирует изображения или видео и постепенно корректирует свои внутренние параметры, чтобы точно выполнять задачи зрения, такие как обнаружение объектов, классификация изображений и сегментация экземпляров. Со временем модель совершенствуется, изучая паттерны непосредственно из увиденных ею данных.
Качество обучения во многом зависит от наборов данных (датасетов). Ты можешь представить датасет как набор карточек, которые учитель использует для обучения ученика, где каждый пример помогает модели понять, что именно нужно искать.
Типичный датасет для компьютерного зрения включает изображения, обычно в форматах JPG или PNG, и аннотации, которые описывают, что находится на каждом изображении. Эти аннотации, часто сохраняемые в виде файлов JSON или TXT, предоставляют метки и контекст, необходимые модели для эффективного обучения.
Но обучение — это не просто подача данных в модель. Оно включает в себя несколько ключевых этапов: от подготовки датасета до выбора подходящей модели и настройки процесса обучения. Далее давай подробнее рассмотрим некоторые из этих шагов.
Link to this sectionВзгляд на то, как подготавливаются датасеты#
Может показаться, что как только у тебя есть датасет, ты можешь сразу приступать к обучению модели, но сначала нужно выполнить несколько шагов, например, разделение датасета.
Как правило, датасет делят на три части: обучающая выборка, валидационная выборка и тестовая выборка. Обучающие изображения используются для обучения модели паттернам в данных, а валидационная выборка помогает контролировать и настраивать производительность во время обучения.
Тестовая выборка используется в самом конце для оценки того, насколько хорошо модель работает на совершенно новых, не виденных ранее данных. Такая настройка помогает убедиться, что модель не просто запоминает данные, а может обобщать их для реальных сценариев.
Link to this sectionВыбор подходящей модели для обучения#
Еще один важный шаг перед обучением — выбор модели, которую ты хочешь использовать. Во многих случаях это означает выбор предобученной модели. Такие модели, как Ultralytics YOLO, уже обучены на огромных датасетах и изучили общие визуальные паттерны, что делает их отличной отправной точкой.
Использование этих моделей — пример трансферного обучения (transfer learning), когда ты опираешься на уже существующие знания и адаптируешь модель под свою специфическую задачу. Такой подход помогает ускорить обучение и улучшить результаты, особенно при работе с ограниченным объемом данных.
Эти модели также бывают разных размеров, каждая из которых предлагает компромисс между скоростью и точностью. Модели меньшего размера быстрее и эффективнее, в то время как более крупные модели обычно обеспечивают более высокую точность, но требуют больше вычислительных ресурсов.
Link to this sectionНастройка параметров обучения для моделей зрения#
После того как у тебя подготовлен датасет и выбрана модель, следующим шагом будет настройка процесса обучения.
Модель компьютерного зрения обучается с использованием набора параметров, которые определяют, как она обрабатывает данные, обновляет свои веса и улучшается со временем. Эти настройки напрямую влияют как на скорость обучения, так и на финальную точность, поэтому они необходимы для достижения качественных результатов.
Вот некоторые из наиболее часто используемых параметров обучения:
- Epochs (Эпохи): Количество полных проходов модели по всему датасету во время обучения. Увеличение количества эпох дает модели больше возможностей изучить паттерны в данных.
- Batch size (Размер пакета): Количество изображений, обрабатываемых одновременно за один шаг обучения. Больший размер пакета может ускорить обучение, но требует больше оперативной памяти.
- Image size (Размер изображения): Разрешение входных изображений, используемых во время обучения. Более высокое разрешение может улучшить точность обнаружения, но увеличивает вычислительные затраты.
- Learning rate (Скорость обучения): Темп, с которым модель обновляет свои внутренние параметры во время обучения. Слишком высокие или слишком низкие значения могут сделать обучение нестабильным.
- Optimizer (Оптимизатор): Алгоритм, отвечающий за обновление параметров модели на основе ошибки, вычисленной на каждой итерации обучения.
В рабочих процессах на базе Ultralytics YOLO эти конфигурации обычно определяются в YAML-файле. Этот файл содержит пути к датасету, имена классов и способ разделения данных. Он выступает в роли центральной конфигурации, которая указывает модели, как интерпретировать датасет.
Link to this sectionОт фрагментированных рабочих процессов к единому опыту с Ultralytics Platform#
Мы только что обсудили некоторые ключевые этапы обучения модели компьютерного зрения: от подготовки датасетов до выбора модели и настройки параметров обучения. На практике этот процесс часто выходит за рамки этих шагов, включая отслеживание экспериментов, сравнение множества запусков обучения и постоянное совершенствование моделей.
Эти этапы редко выполняются в одном месте. Датасеты могут подготавливаться в одном инструменте, запуски обучения — в другой среде, а отслеживание экспериментов — управляться отдельно. По мере роста проектов эта фрагментация усложняет работу, замедляет итерации и затрудняет поддержание порядка.
Ultralytics Platform устраняет эту сложность, объединяя весь рабочий процесс обучения в единую среду. Вместо переключения между инструментами ты можешь управлять датасетами, настраивать обучение, проводить эксперименты и контролировать результаты в одном месте.
Далее давай углубимся в то, как Ultralytics Platform делает обучение моделей умнее.
Link to this sectionВарианты обучения, поддерживаемые Ultralytics Platform#
В реальных приложениях обучение модели компьютерного зрения часто требует гибких сред. В зависимости от размера твоего датасета, сложности модели и доступного оборудования ты можешь выбрать обучение в облаке, на локальной машине или через внешние среды блокнотов.
Ultralytics Platform поддерживает следующие варианты обучения для удовлетворения этих потребностей:
- Cloud training (Облачное обучение): Обучение запускается на графических процессорах (GPU) в облаке под управлением Ultralytics. Этот вариант идеален для больших датасетов или более сложных моделей, требующих значительных вычислительных мощностей.
- Local training (Локальное обучение): Этот вариант использует оборудование, доступное на твоей машине, и отлично подходит для быстрых экспериментов, тестирования конфигураций или работы с небольшими датасетами. Для более масштабируемых рабочих нагрузок обучение также можно запустить в твоем собственном облачном окружении, например AWS или GCP.
- Google Colab: С Ultralytics Platform ты можешь запустить обучение в хостинговой среде блокнотов Google Colab, обеспечивая гибкий рабочий процесс прямо в браузере без необходимости настройки локальной машины.
Link to this sectionИзучение облачного обучения на Ultralytics Platform#
Когда дело доходит до проектов компьютерного зрения, обучение моделей локально или через среды блокнотов не всегда просто.
Например, при локальном обучении производительность полностью зависит от твоего оборудования, что может ограничить вычислительную мощность и замедлить эксперименты. GPU необходимы для эффективного обучения, но не каждая установка имеет к ним стабильный доступ.
Хотя среды блокнотов, такие как Google Colab, предлагают альтернативу, предоставляя облачные GPU, сессии часто бывают временными и могут прерывать длительные процессы обучения. По мере роста датасетов и усложнения рабочих процессов эти ограничения быстро превращаются в «бутылочное горлышко», делая обучение медленнее и менее надежным.
Ultralytics Platform решает эту проблему с помощью опции облачного обучения. Она предоставляет готовую среду, где Python-зависимости и фреймворки, такие как PyTorch, уже предварительно настроены, что позволяет тебе начать обучение без дополнительной настройки.
Из одной панели управления ты можешь запускать задачи обучения и следить за прогрессом в реальном времени. Это позволяет сосредоточиться на улучшении моделей, а не на управлении инфраструктурой.
Теперь давай посмотрим, как начать облачное обучение на Ultralytics Platform.
Link to this sectionШаг 1: Выбери базовую модель#
Первый шаг — выбор базовой модели для запуска обучения. Ты можешь выбрать предобученную модель Ultralytics YOLO, клонировать модель сообщества или загрузить собственные предобученные веса для соответствия специфическим требованиям.
Платформа поддерживает все модели Ultralytics YOLO, включая Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8 и Ultralytics YOLOv5, каждая из которых доступна в различных размерах, таких как nano (n), small (s), medium (m), large (l) и extra-large (x). Поскольку разные варианты моделей предлагают баланс между скоростью и точностью, ты можешь выбрать ту, которая соответствует твоим требованиям к производительности и вычислениям.
Эти модели поддерживают ряд задач компьютерного зрения, с которыми пользователи Ultralytics YOLO уже знакомы, включая обнаружение объектов, сегментацию экземпляров, классификацию изображений, обнаружение ориентированных ограничивающих рамок (OBB) и оценку позы.
Если у тебя есть специфические требования, ты можешь загрузить свои веса предобученной модели. Это означает, что ты можешь продолжить обучение или дообучить (fine-tune) существующую модель, например детектор объектов, прямо внутри платформы, вместо того чтобы начинать с нуля. Это особенно полезно, если ты уже обучил модель в другом месте или хочешь адаптировать модель под конкретный сценарий использования.
Link to this sectionШаг 2: Выбери датасет#
Следующий шаг — выбор датасета для обучения. На Ultralytics Platform ты можешь использовать существующие датасеты, такие как COCO, клонировать датасеты сообщества или загрузить свой собственный датасет, адаптированный под твою задачу.
Платформа поддерживает распространенные форматы аннотаций, такие как Ultralytics YOLO и COCO, а также может обрабатывать загрузку «сырых» изображений, если ты планируешь аннотировать пользовательские данные прямо на платформе.
После загрузки датасеты автоматически обрабатываются, включая валидацию, нормализацию, парсинг меток и генерацию статистики. Это дает тебе мгновенный обзор данных, включая распределение классов и структуру датасета, и помогает убедиться, что всё готово к обучению.
Датасеты также автоматически привязываются к запускам обучения, позволяя отслеживать, какие данные использовались для каждой модели, и поддерживать согласованность между экспериментами.
Link to this sectionШаг 3: Настрой параметры обучения#
После выбора датасета ты можешь настроить параметры обучения, которые управляют процессом обучения модели. К ним относятся эпохи, размер пакета, размер изображения и имя запуска для лога обучения. Многие из этих параметров влияют как на длительность обучения, так и на итоговую производительность модели.
Для более контролируемого обучения платформа также позволяет корректировать расширенные параметры, такие как скорость обучения, тип оптимизатора, настройки аугментации цвета и другие параметры. Эти настройки позволяют точно настроить процесс обучения для улучшения точности и стабильности модели.
Link to this sectionШаг 4: Выбери GPU#
Далее ты можешь выбрать конфигурацию GPU для своего запуска обучения. Выбор подходящего GPU зависит от таких факторов, как размер датасета, размер пакета, разрешение изображения и сложность модели. Нахождение правильного баланса помогает сделать обучение эффективным без использования лишних вычислительных мощностей.
Ultralytics Platform предлагает 22 варианта GPU с различными уровнями VRAM (памяти на GPU) и вычислительной мощностью, поддерживая всё — от небольших задач до масштабных рабочих нагрузок.
Благодаря этому ты можешь подобрать оборудование под свои нужды, будь то обучение легких моделей или работа с большими сложными датасетами. Чтобы узнать больше, ознакомься со списком доступных GPU на странице документации по обучению на платформе Ultralytics.
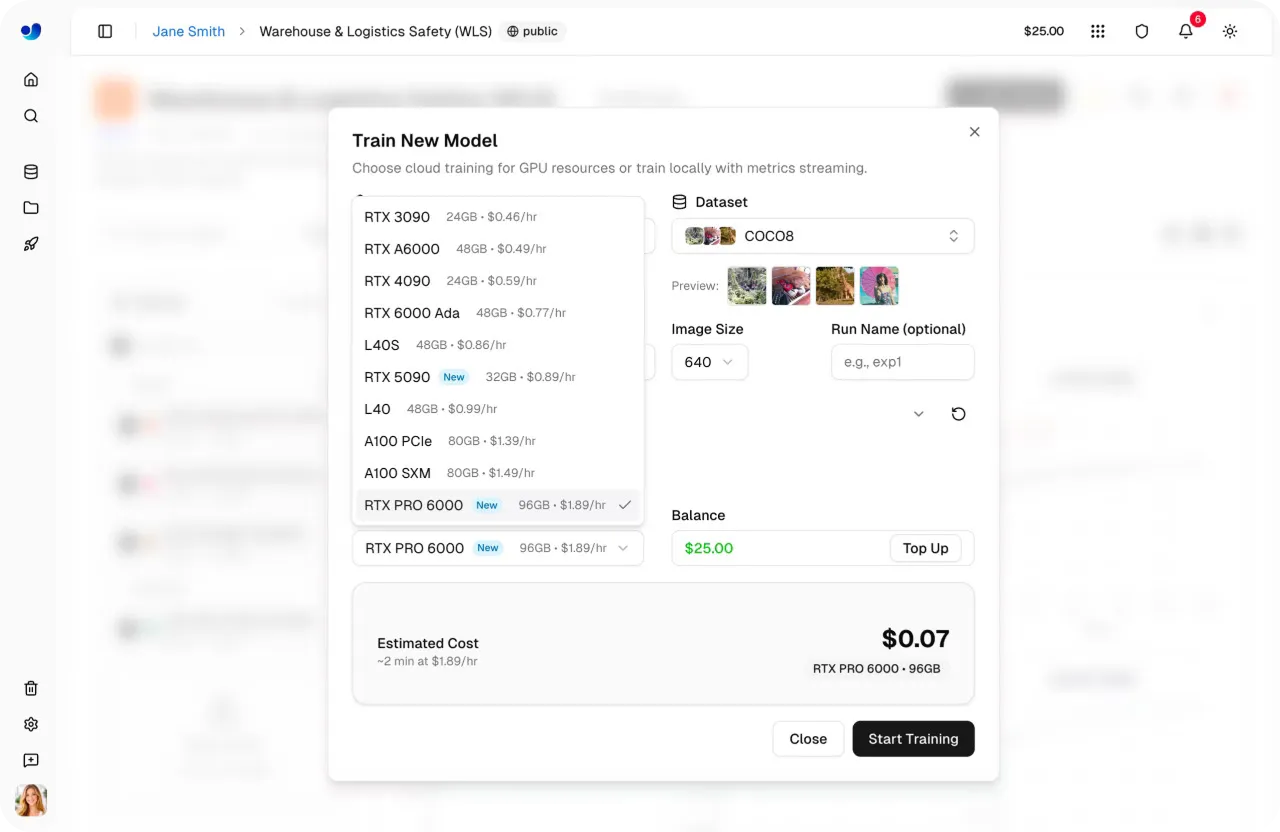
Рис. 2. Некоторые из опций GPU, доступных через Ultralytics Platform (Источник)
Link to this sectionШаг 5: Запусти облачное обучение#
Как только ты выбрал модель, датасет, параметры обучения и опцию вычислений, запуск процесса обучения выполняется быстро. Из панели управления ты можешь запустить обучение одним кликом, а платформа сделает всё остальное: инициализирует среду и запустит задачу на выбранном GPU.
Как только обучение начнется, ты сможешь отслеживать прогресс прямо в платформе. Вкладка «Train» предоставляет видимость ключевых метрик в реальном времени, включая показатели производительности, кривые потерь (loss curves), использование системы и живые логи обучения.
Чтобы узнать больше об обучении локально или с использованием Google Colab через Ultralytics Platform, ты можешь изучить дополнительные руководства в официальной документации по платформе Ultralytics.
Link to this sectionОценка и сравнение моделей на Ultralytics Platform#
После завершения обучения следующим шагом будет оценка того, насколько хорошо работает твоя модель. На Ultralytics Platform ты можешь сравнивать несколько запусков обучения в рамках одного проекта, получая четкое представление о результатах разных экспериментов.
При разработке моделей обучение часто повторяется несколько раз с разными настройками, такими как изменение скорости обучения, размера пакета или размера модели, для улучшения результатов. Каждый такой запуск дает немного отличающуюся модель, поэтому их сравнение жизненно важно.
Проекты выступают в роли центрального узла, где модели и эксперименты организованы вместе. Ты можешь отслеживать прогресс, просматривать результаты и оставаться сфокусированным, не переключаясь между разными инструментами или экранами.
Из этого единого представления ты также можешь анализировать ключевые метрики производительности, такие как precision, recall и mAP (mean average precision), чтобы понять, как твоя модель работает с разными классами. Ты также можешь сравнивать запуски обучения бок о бок, чтобы определить, какие конфигурации приносят наилучшие результаты.
В дополнение к этим метрикам, ты можешь использовать вкладку «Predict» для быстрой проверки обученных моделей на тестовых изображениях или данных, что поможет визуально проверить производительность и выявить потенциальные проблемы.
Имея эти данные, ты можешь выбрать лучшую модель (обычно сохраняемую как чекпоинт «best.pt») и перейти к следующему этапу — будь то дальнейшая оценка, использование модели для инференса или развертывание модели через платформу.
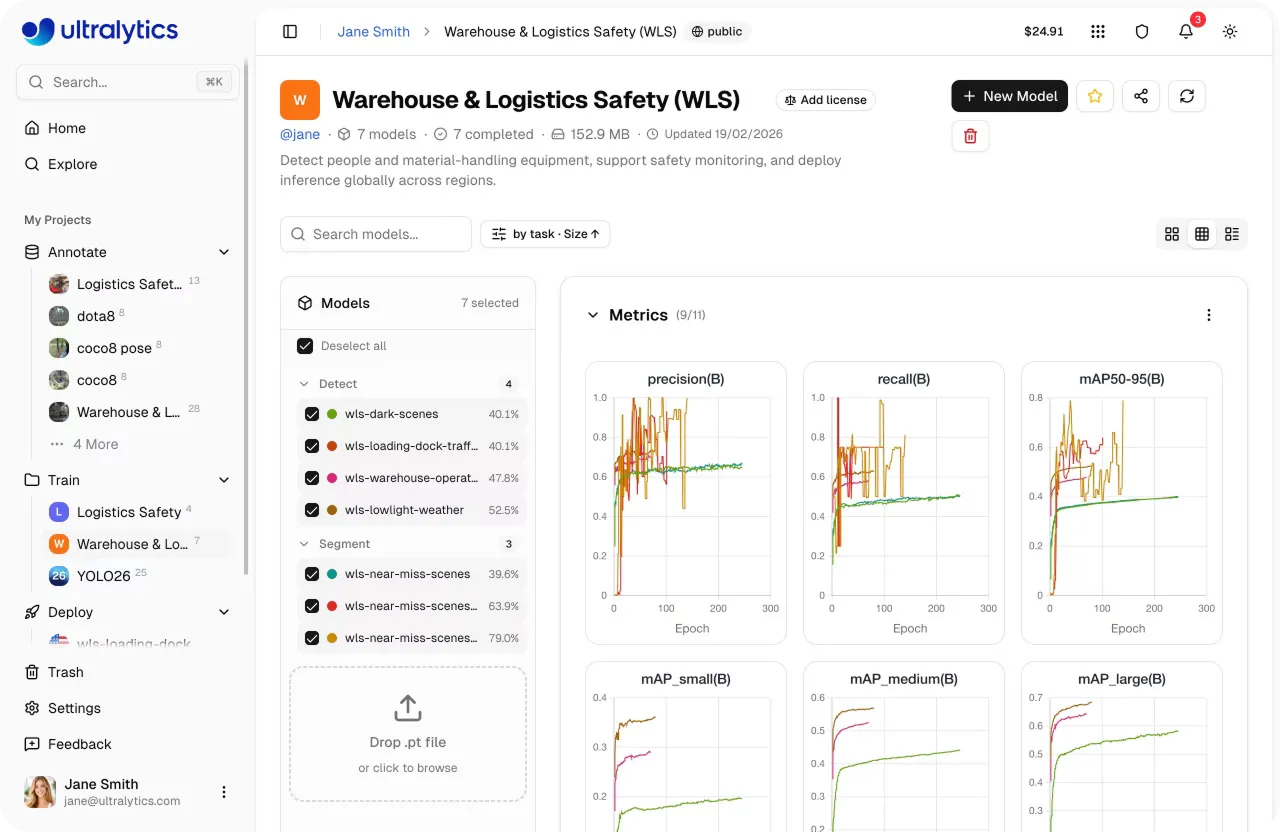
Рис. 3. Пример просмотра метрик на Ultralytics Platform (Источник)
Link to this sectionОценка стоимости обучения внутри Ultralytics Platform#
Обучение моделей обнаружения объектов в облаке влечет за собой затраты на вычисления, особенно при доступе к высокопроизводительным GPU. Чтобы сделать это удобнее, Ultralytics Platform предоставляет оценку стоимости перед началом обучения.
Это дает тебе ясное понимание ожидаемого потребления ресурсов, помогая планировать задачи, управлять бюджетом и избегать непредвиденных расходов до запуска задачи обучения. Вот как ты можешь проверить оценочную стоимость перед началом обучения.
Link to this sectionКак оценивается время обучения#
Для точной оценки стоимости платформа сначала вычисляет, сколько времени займет одна эпоха обучения. Это зависит от таких факторов, как размер датасета, размер модели, разрешение изображения, размер пакета и скорость выбранного GPU.
Используя эти вводные данные, она определяет оценочное время на эпоху и масштабирует его на весь процесс обучения. Общая длительность рассчитывается путем суммирования времени всех эпох с учетом небольших накладных расходов на запуск.
Накладные расходы учитывают такие задачи, как инициализация среды, загрузка датасетов и подготовка GPU, гарантируя, что оценка отражает полный процесс обучения, а не только цикл обучения.
Link to this sectionКак рассчитывается стоимость обучения#
После того как общее время обучения оценено, платформа конвертирует его в стоимость, используя почасовой тариф выбранного GPU.
Объединяя длительность обучения и тарифы на GPU, мы получаем ясную оценку того, сколько будет стоить запуск, еще до того, как он начнется.
Наличие такой информации заранее позволяет легко скорректировать твою настройку, например изменив параметры обучения или выбрав другой GPU, чтобы ты мог эффективнее балансировать между производительностью и стоимостью.
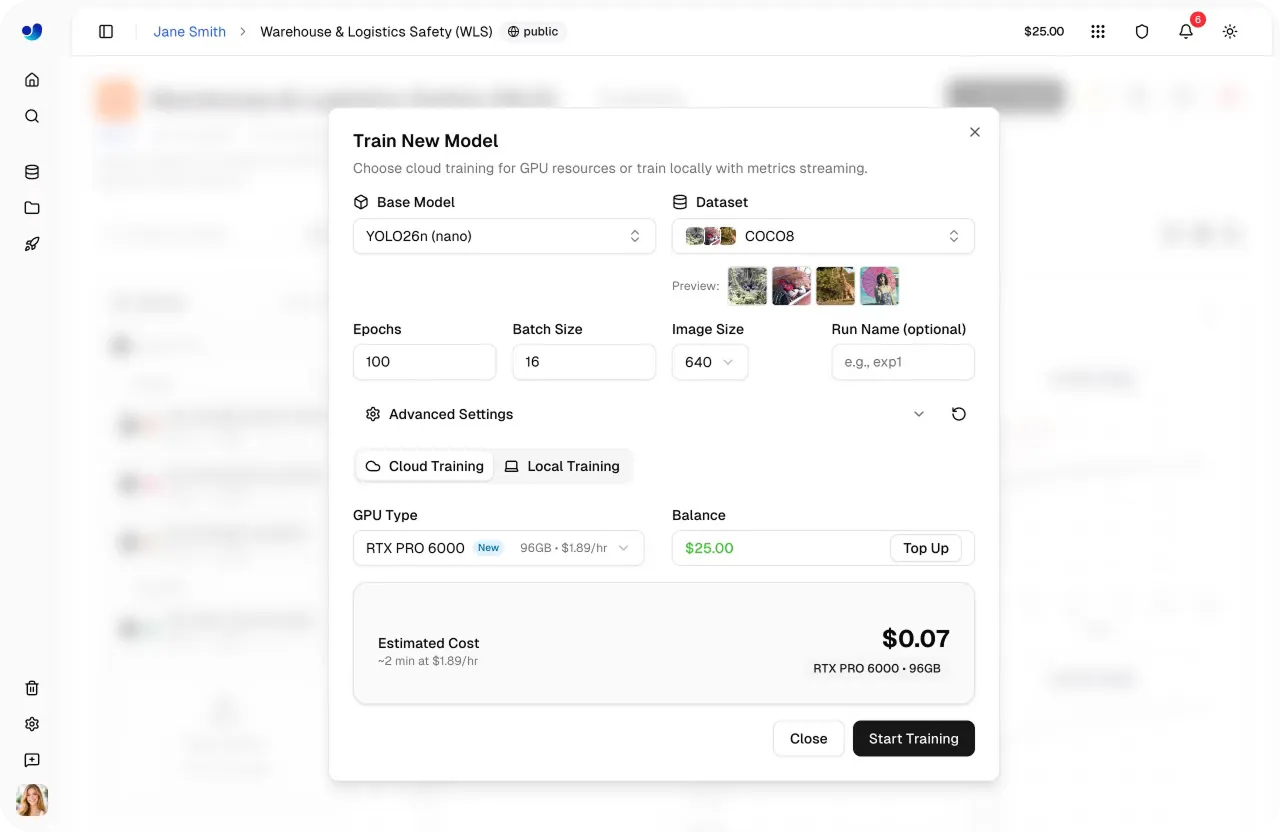
Рис. 4. Настройка обучения модели и оценка стоимости внутри Ultralytics Platform (Источник)
Link to this sectionКлючевые преимущества использования Ultralytics Platform для обучения моделей#
До сих пор мы прошли через основные этапы обучения моделей компьютерного зрения и узнали, как они объединяются на Ultralytics Platform.
Помимо этих основных функций, есть дополнительные возможности, которые улучшают рабочий процесс обучения. Вот обзор некоторых ключевых преимуществ использования Ultralytics Platform для обучения моделей:
- Встроенная воспроизводимость экспериментов: Каждый запуск обучения автоматически записывается с его полной конфигурацией, включая модель, датасет, параметры и настройки вычислений. Это позволяет легко возвращаться к экспериментам и надежно воспроизводить результаты.
- Аналитика обучения в динамике: Вместо того чтобы просматривать только итоговые результаты, ты можешь отслеживать изменения производительности по эпохам, что поможет тебе лучше понять поведение модели в процессе обучения.
- Снижение операционных затрат: Автоматизируя настройку окружения, управление зависимостями и инфраструктуру, платформа позволяет тебе больше сосредоточиться на разработке моделей, а не на настройке системы.
- Централизованная организация экспериментов: Проекты служат единым пространством для управления моделями, наборами данных и запусками обучения, что помогает поддерживать порядок в экспериментах по мере усложнения рабочих процессов.
Link to this sectionОсновные выводы#
Обучение — один из важнейших этапов жизненного цикла модели машинного обучения. От него зависит, насколько точно модель сможет распознавать и интерпретировать визуальные данные.
Объединяя конфигурацию данных для обучения, мониторинг, сравнение экспериментов и оценку затрат в одной среде, Ultralytics Platform упрощает процесс создания высокопроизводительных моделей компьютерного зрения и их подготовку к развертыванию.
Загляни в наше растущее сообщество и репозиторий на GitHub, чтобы узнать больше о компьютерном зрении. Если ты хочешь создавать решения в области машинного зрения, ознакомься с нашими вариантами лицензирования. Исследуй страницы наших решений, чтобы узнать больше о преимуществах компьютерного зрения в производстве и AI в сельском хозяйстве.






