How Ultralytics Platform simplifies computer vision model deployment
See how Ultralytics Platform brings together everything needed for computer vision model deployment, from testing to production-ready APIs.
Ultralytics has been working with the computer vision community for years, creating models and tools that make vision AI more accessible to everyone. With Ultralytics Platform, we’re taking it a step further by bringing the entire computer vision development workflow into one unified environment, covering everything from dataset management and annotation to model training, validation, and deployment.
In particular, we’re excited to make computer vision model deployment easier. As computer vision continues to make its way into real-world applications, analyzing images and video outside of controlled environments is still complex.
Unlike testing setups where conditions are predictable, real-world scenarios involve varying lighting, changing inputs, and unpredictable workloads, making deployment one of the most challenging parts of the vision workflow.
Deployment involves more than just making a model available for use. It requires setting up processes that can handle real-world data and ensuring everything runs smoothly as usage grows and projects scale.
Teams also need to track performance and maintain reliability over time. This often means switching between different AI tools for testing, integration, deployment, and monitoring, which can slow down model development and add unnecessary complexity.
Workflows end up becoming fragmented. Ultralytics Platform unifies and simplifies this process.
It provides built-in support for model serving, testing, and monitoring within a single environment. Teams can validate models using browser-based inference, integrate them into applications through shared inference services, and deploy to dedicated endpoints with performance monitoring capabilities.
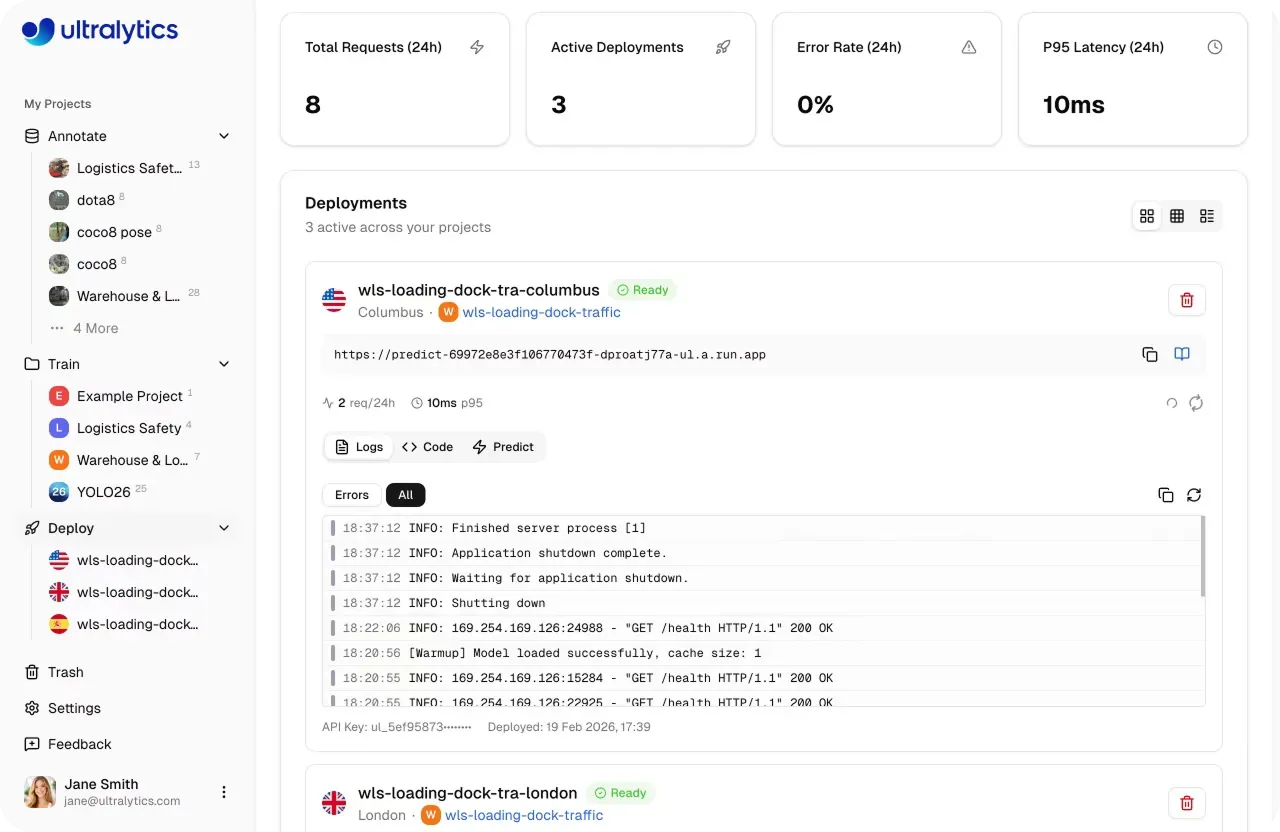
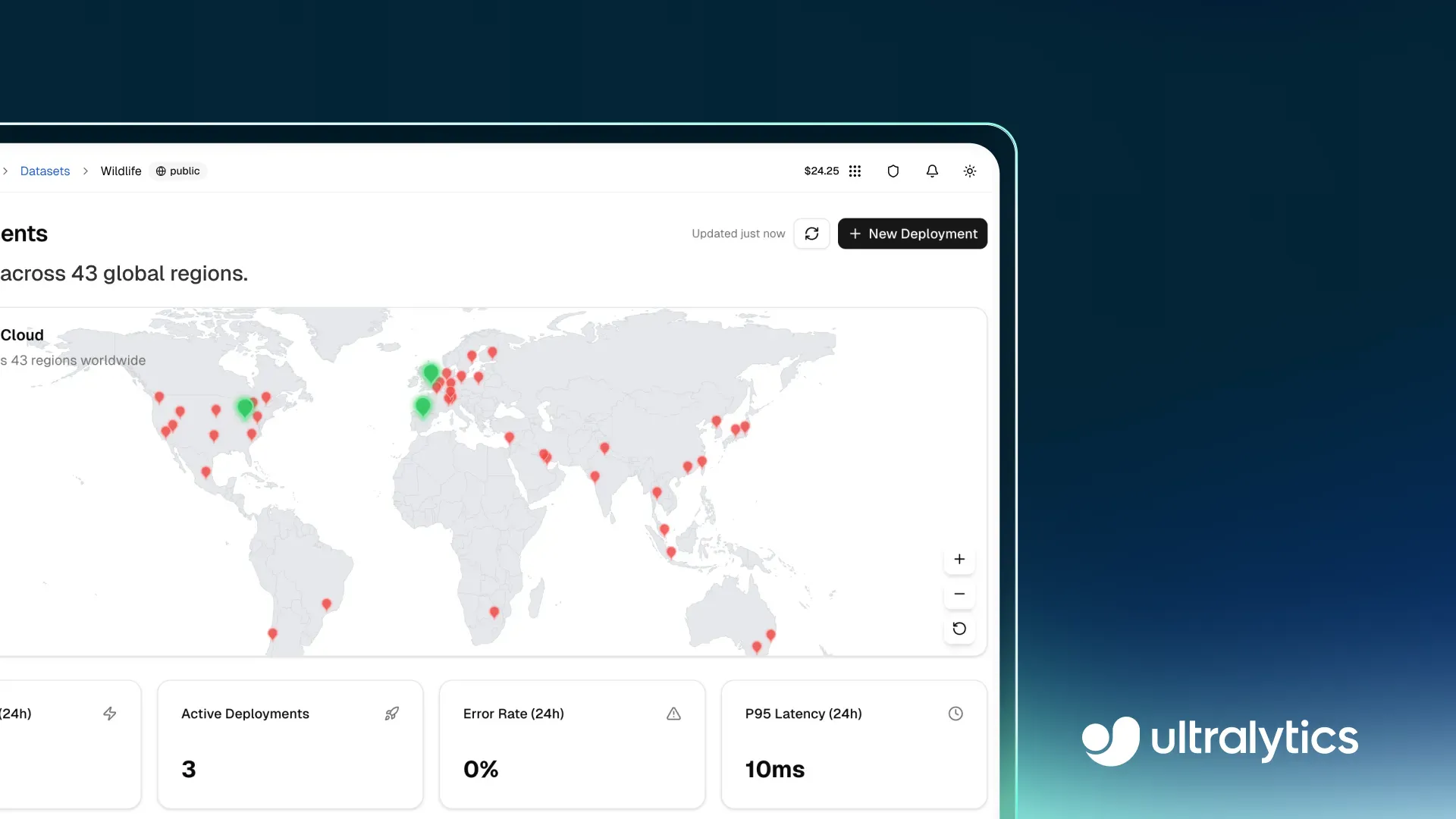
Fig 1. A look at the deployment page within Ultralytics Platform (Source)
In this article, we’ll explore how Ultralytics Platform redefines computer vision model deployment, from testing and integration to production deployment and monitoring. Let’s get started!
Link to this sectionAn overview of computer vision model deployment#
In a machine learning lifecycle, model deployment is the stage where a model moves from experimentation into real-world use. For computer vision models built using deep learning and convolutional neural networks, this generally means making them available to process images and videos in real time.
Once deployed, these models take in new data, which usually goes through preprocessing steps like resizing, normalization, or formatting. The processed data is then passed to the model, which applies patterns learned during training to generate high-precision predictions.
Depending on the use case, this can include different computer vision tasks. For example, Ultralytics YOLO models, such as Ultralytics YOLO26, support a wide range of vision tasks, including object detection, image classification, instance segmentation, pose estimation, and oriented bounding box (OBB) detection.
To make this practical in real-world applications, models often need to be integrated into systems that can handle both preprocessing and inference efficiently. This is where deployment infrastructure becomes essential.
In production environments, models are typically accessed through REST APIs or model-serving systems. These interfaces allow applications to send data and receive predictions programmatically, making it easier to integrate with external applications, IoT devices, or robotics systems that rely on real-time visual understanding.
Link to this sectionLimitations of traditional computer vision deployment tools#
Computer vision model deployment may sound straightforward, but until now, it has looked quite different in practice. Consider a common setup: data is first captured from cameras or sensors, sent to a model for inference, and then returned to an application as predictions.
In reality, each of these steps is often handled by separate tools and services. One system may handle data capture, another manages model serving, while additional tools are used for scaling, monitoring, and logging. Keeping these components connected and running reliably can quickly become complex.
As usage grows, this complexity increases. Managing infrastructure, handling dependencies, and maintaining consistent performance across the end-to-end pipeline can slow down development and make it more difficult to deploy computer vision models in real-world applications.
Ultralytics Platform brings these components together in a single, unified environment. This provides a more cohesive way to manage the entire deployment workflow while supporting performance and reliability at scale.
Link to this sectionModel deployment options enabled by Ultralytics Platform#
In addition to unifying the model deployment process, Ultralytics Platform also brings flexibility to how models are deployed and used.
To support different stages of computer vision model deployment, the platform offers four options: browser-based testing with instant inference, shared inference through APIs for development, dedicated endpoints for scalable production deployments across global regions, and model export for running models on external infrastructure or edge devices.
So let’s take a closer look at how each of these options works.
Link to this sectionValidate models quickly using the Predict tab#
Before moving a model into production, it is important to understand how it performs on new, unseen data. Ultralytics Platform includes a built-in Predict tab that lets you run inference directly in the browser without any setup, infrastructure, or dependencies.
The Predict tab makes model validation fast and interactive. You can upload images, use preloaded examples, or capture inputs with a webcam, and inference runs automatically as soon as data is provided.
Results appear instantly with visual overlays, confidence scores, and detailed outputs, giving you a clear view of how the model behaves.
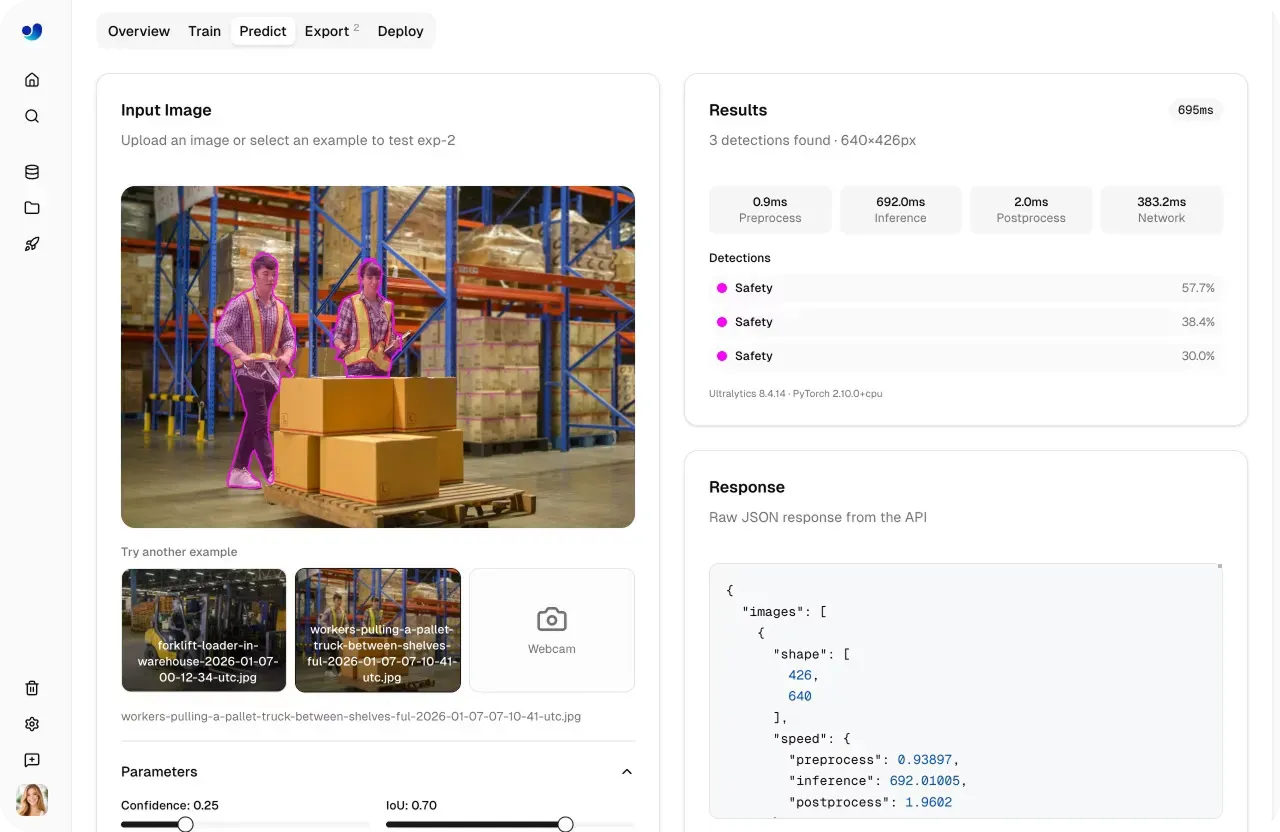
Fig 2. An example of validating a model using the Predict tab (Source)
This means with a few clicks, you can test out different inputs, adjust parameters, and evaluate performance within a single interface before moving to deployment.
Link to this sectionRunning shared inferences for testing or light usage#
Let’s say you’ve trained a model and validated it using the Predict tab. The next step is often to start integrating that model into an application or workflow.
Instead of setting up infrastructure or managing servers, Ultralytics Platform provides shared inference services that let you send data to your model and receive predictions through simple REST APIs.
Behind the scenes, shared inference runs on a multi-tenant system across a few core regions, where requests are automatically routed to the nearest available service. This helps maintain responsive performance while making it possible for users in different locations to access models consistently.
You can send inputs using standard HTTP requests and receive structured outputs in return, making it straightforward to connect models to applications, scripts, or automation workflows. This setup is a great option for development, testing, integrations, or lighter usage before moving to more scalable production deployments.
Link to this sectionDeploy models globally through dedicated endpoints#
Once a model is ready for production, it needs to handle real-world traffic reliably and at scale. Ultralytics Platform supports this with dedicated endpoints, where models run as single-tenant services across 43 global regions. Deploying closer to end users helps reduce latency and maintain consistent performance across different locations.
Each endpoint runs with its own allocated compute resources and a unique URL for inference requests. This level of control makes it easy to tune deployments based on performance needs, from lightweight use cases to more demanding, high-throughput applications that need more computational resources.
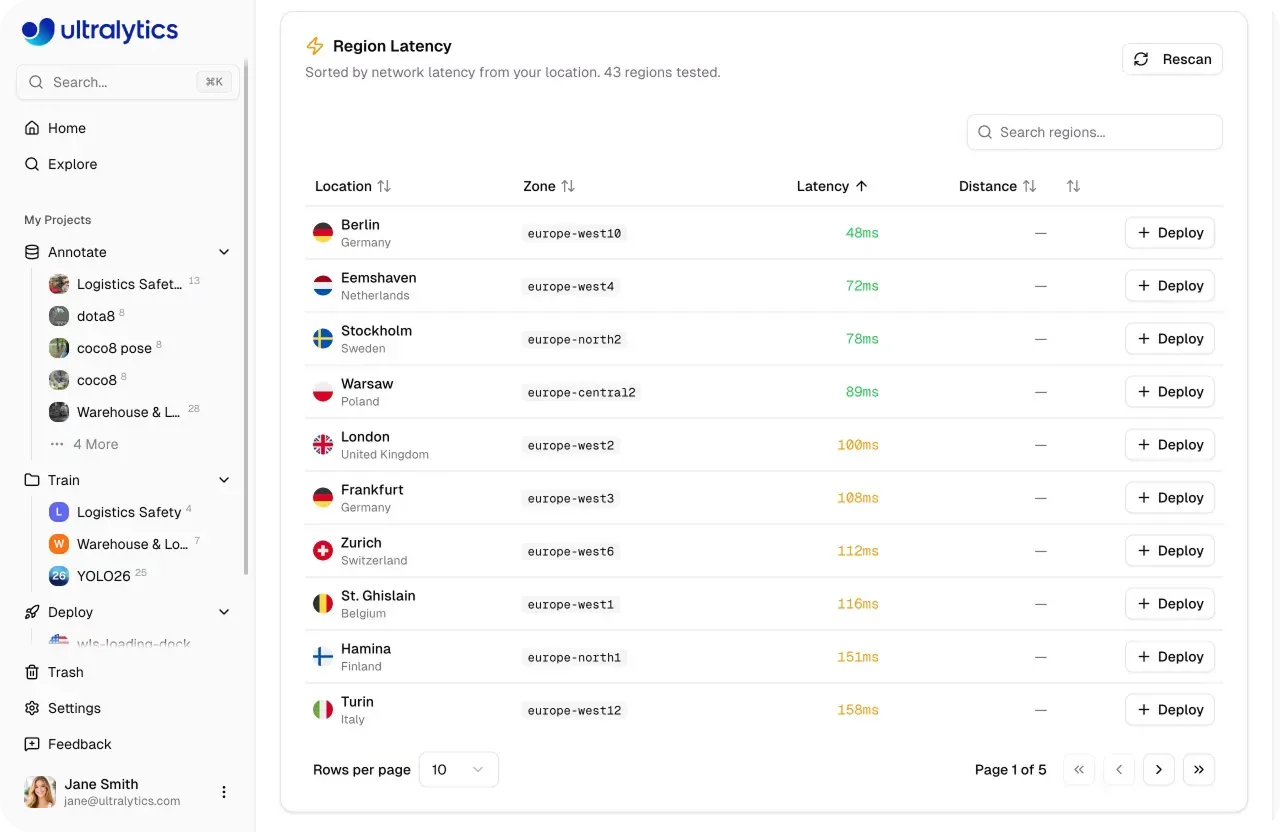
Fig 3. You can deploy models across 43 global regions using Ultralytics Platform (Source)
However, dedicated endpoints are designed to handle changing workloads themselves, with auto scaling that adjusts resources based on incoming traffic. They scale up during periods of high demand and scale down when usage drops. With scale-to-zero enabled by default, idle endpoints shut down automatically and restart when new requests arrive, helping optimize resource usage without manual intervention.
Link to this sectionExport your model easily with Ultralytics Platform#
Nowadays, edge AI is becoming increasingly essential as more applications rely on running models directly on devices like smartphones, cameras, and embedded systems. Running models locally can also help address data privacy requirements, since sensitive data such as images or video streams can be processed directly on-device without being sent to external servers.
In these scenarios, models need to run outside of Ultralytics Platform, making model export a crucial part of the deployment process. Ultralytics YOLO models are often trained using Python and PyTorch, and can then be exported to 17+ different formats, including ONNX, TensorRT, CoreML, and OpenVINO.
This wide range of formats ensures compatibility across diverse hardware, from high-performance graphics processing units (GPUs) to mobile and embedded devices. In addition to this, exporting enables performance tuning for specific environments.
Depending on the format, models can achieve faster inference speeds, such as improved GPU performance with TensorRT or optimized CPU execution with ONNX and OpenVINO. Options like FP16 and INT8 quantization can further reduce model size and improve throughput, which is especially useful for edge deployments.
On Ultralytics Platform, exporting is built directly into the workflow, making it quick to generate optimized models in just a few clicks. Teams can move from training to running models on external systems without adding extra overload.
Fig 4. A selection of export formats on Ultralytics Platform.
Link to this sectionChoosing the right model deployment option#
Each deployment option in Ultralytics Platform supports a different stage of the workflow, from early testing to production use. Here’s an overview of when you might use each one:
- Predict tab: This is typically used right after training or fine-tuning, when you want to validate how a model performs on new data using browser-based inference.
- Shared inference: At this stage, models can be integrated into applications through APIs, making it possible to test real-world interactions during development.
- Dedicated endpoints: These are used for production deployments, where models need consistent performance, dedicated resources, and the ability to scale across global regions.
- Model export: When models need to run outside the platform, the option to export them enables deployment on edge devices, mobile apps, or custom infrastructure.
Teams often move through these options step by step, going from validation to integration and finally to production deployment, all within the platform.
Link to this sectionMonitoring deployed models through Ultralytics Platform#
As critical as deployment is, the vision pipeline doesn’t end there. Once a model is running in production, continuous monitoring is key to make sure it performs reliably over time.
Ultralytics Platform provides built-in monitoring tools that give teams clear visibility into how their vision AI models behave over time, supporting a more structured machine learning operations (MLOps) workflow.
The Deploy page includes a dashboard that tracks key metrics such as total requests, active deployments, response latency, and error rates. These insights help teams understand usage patterns, evaluate system responsiveness, and ensure low-latency performance across different workloads.
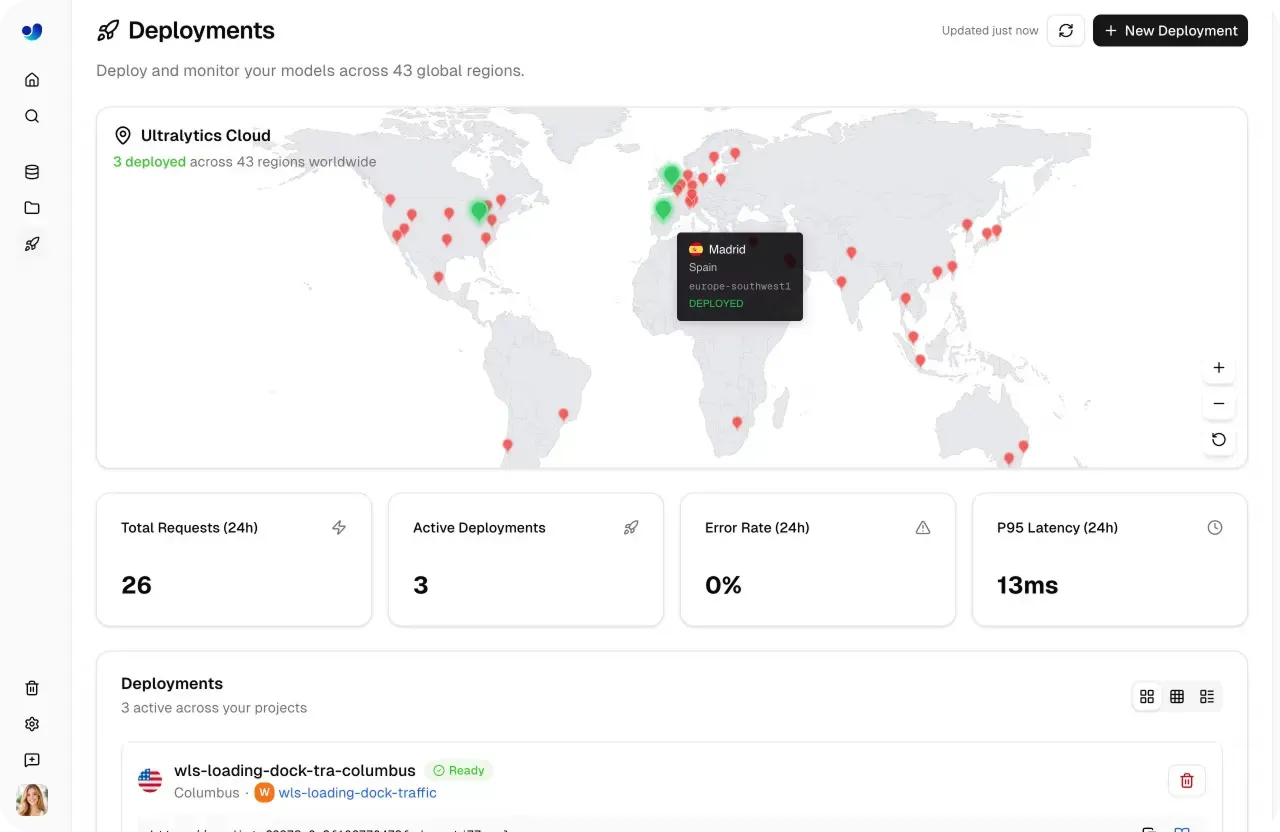
Fig 5. Ultralytics Platform makes monitoring deployed models easy. (Source)
Each dedicated endpoint also provides detailed observability through individual deployment views. This includes access to logs, model health status, and real-time performance data. Logs can be used to debug issues, trace failed requests, and identify potential problems related to dependencies or infrastructure.
As production environments evolve, factors such as changing input data, scaling demands, or shifting usage patterns can impact model accuracy and robustness. By continuously monitoring performance metrics, teams can detect anomalies, identify bottlenecks, and take corrective actions such as model optimization or resource adjustments to maintain consistent and reliable model serving.
Link to this sectionBuilding scalability into computer vision model deployments#
Scaling computer vision systems has traditionally meant stitching together workflows and frameworks that were never designed to work as one. Data pipelines, training loops, deployment infrastructure, and monitoring systems often live in separate places, creating friction at every stage.
The real challenge isn’t just building models, but keeping them moving. Moving from data to production, adapting to new inputs, handling growing demand, and continuously improving without slowing down.
What stands out about Ultralytics Platform is that this movement is built in. Instead of treating each stage as a separate step, it connects them into a continuous loop where models can be developed, deployed, observed, and updated within the same environment.
That shift changes how teams scale. It is no longer about orchestration of tools or infrastructure, but about maintaining momentum as systems grow.
Link to this sectionKey takeaways#
Bringing machine learning models like computer vision models into real-world applications requires them to be reliable, scalable, and easy to manage. Ultralytics Platform simplifies this process by combining various functions, such as model serving, deployment, and monitoring, into one unified environment. With flexible deployment options and built-in tools, teams can move from experimentation to production more quickly and with less complexity.
Check out our community and explore our GitHub repository to learn more. Explore our solutions pages to see various applications like AI in healthcare and computer vision in logistics. Discover our licensing options and start building today!






