Como a Ultralytics Platform simplifica a implantação de modelos de visão computacional
Vê como a Ultralytics Platform reúne tudo o que é necessário para a implantação de modelos de visão computacional, desde testes até APIs prontas para produção.
A Ultralytics tem trabalhado com a comunidade de visão computacional durante anos, criando modelos e ferramentas que tornam a IA de visão mais acessível a todos. Com a Ultralytics Platform, estamos dando um passo adiante ao trazer todo o fluxo de trabalho de desenvolvimento de visão computacional para um ambiente unificado, abrangendo desde o gerenciamento e anotação de conjuntos de dados até o treinamento, validação e implementação de modelos.
Em particular, estamos empolgados em tornar a implementação de modelos de visão computacional mais fácil. À medida que a visão computacional continua a chegar a aplicações do mundo real, analisar imagens e vídeos fora de ambientes controlados ainda é complexo.
Ao contrário de configurações de teste onde as condições são previsíveis, cenários do mundo real envolvem iluminação variável, entradas em mudança e cargas de trabalho imprevisíveis, tornando a implementação uma das partes mais desafiadoras do fluxo de trabalho de visão.
A implementação envolve mais do que apenas tornar um modelo disponível para uso. Ela exige a configuração de processos que possam lidar com dados do mundo real e garantir que tudo funcione perfeitamente à medida que o uso aumenta e os projetos crescem.
As equipes também precisam rastrear o desempenho e manter a confiabilidade ao longo do tempo. Isso geralmente significa alternar entre diferentes ferramentas de IA para teste, integração, implementação e monitoramento, o que pode atrasar o desenvolvimento do modelo e adicionar complexidade desnecessária.
Os fluxos de trabalho acabam se tornando fragmentados. A Ultralytics Platform unifica e simplifica esse processo.
Ela fornece suporte integrado para servir, testar e monitorar modelos dentro de um único ambiente. As equipes podem validar modelos usando inferência baseada no navegador, integrá-los em aplicações por meio de serviços de inferência compartilhados e implementar em endpoints dedicados com recursos de monitoramento de desempenho.
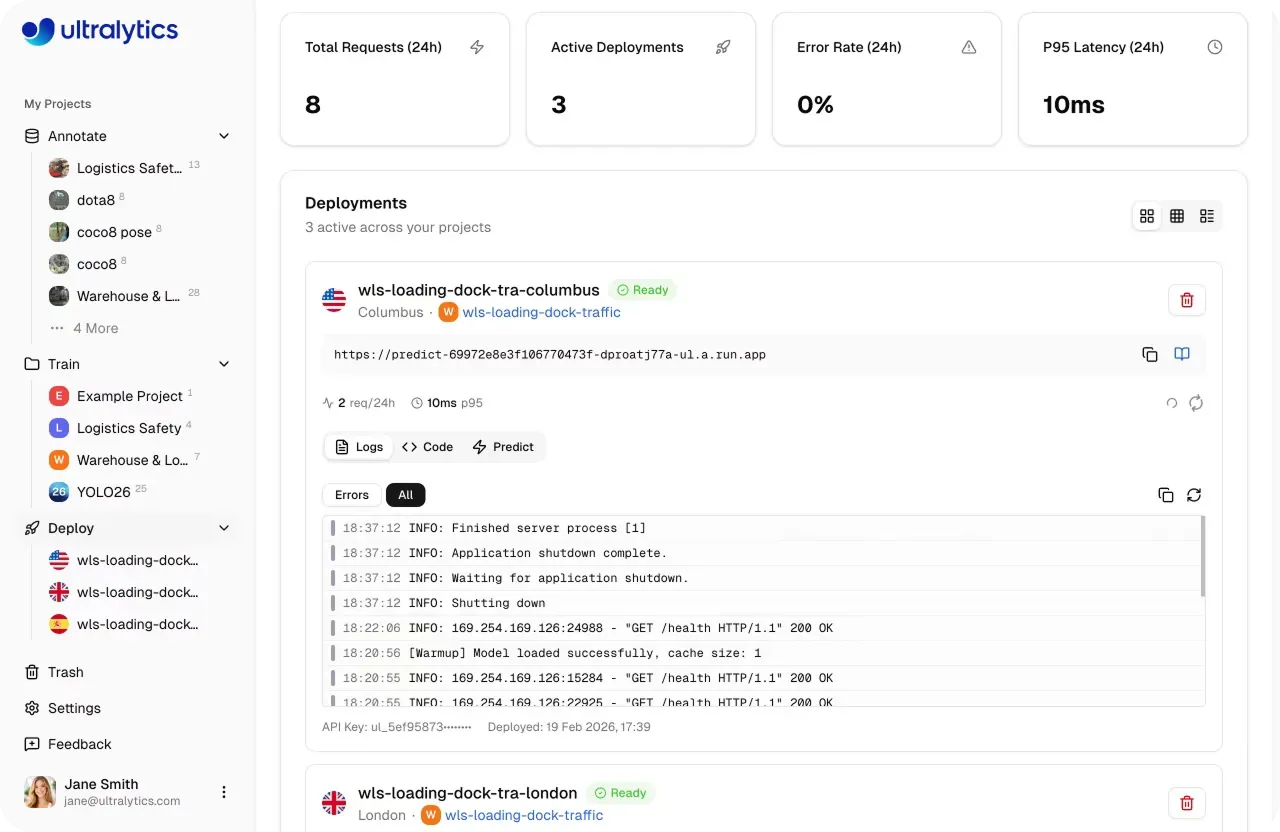
Fig 1. Uma olhada na página de implementação dentro da Ultralytics Platform (Fonte)
Neste artigo, exploraremos como a Ultralytics Platform redefine a implementação de modelos de visão computacional, desde testes e integração até a implementação em produção e monitoramento. Vamos começar!
Link to this sectionUma visão geral da implementação de modelos de visão computacional#
No ciclo de vida de aprendizado de máquina, a implementação de modelos é o estágio em que um modelo passa da experimentação para o uso no mundo real. Para modelos de visão computacional construídos usando aprendizado profundo e redes neurais convolucionais, isso geralmente significa torná-los disponíveis para processar imagens e vídeos em tempo real.
Uma vez implementados, esses modelos recebem novos dados, que geralmente passam por etapas de pré-processamento, como redimensionamento, normalização ou formatação. Os dados processados são então passados para o modelo, que aplica padrões aprendidos durante o treinamento para gerar previsões de alta precisão.
Dependendo do caso de uso, isso pode incluir diferentes tarefas de visão computacional. Por exemplo, modelos Ultralytics YOLO, como o Ultralytics YOLO26, suportam uma ampla gama de tarefas de visão, incluindo detecção de objetos, classificação de imagens, segmentação de instâncias, estimativa de pose e detecção de caixa delimitadora orientada (OBB).
Para tornar isso prático em aplicações do mundo real, os modelos geralmente precisam ser integrados a sistemas que possam lidar com pré-processamento e inferência de forma eficiente. É aqui que a infraestrutura de implementação se torna essencial.
Em ambientes de produção, os modelos são normalmente acessados por meio de REST APIs ou sistemas de servir modelos. Essas interfaces permitem que as aplicações enviem dados e recebam previsões programaticamente, facilitando a integração com aplicações externas, dispositivos IoT ou sistemas de robótica que dependem de compreensão visual em tempo real.
Link to this sectionLimitações das ferramentas tradicionais de implementação de visão computacional#
A implementação de modelos de visão computacional pode parecer simples, mas, até agora, tem sido bem diferente na prática. Considere uma configuração comum: os dados são primeiro capturados de câmeras ou sensores, enviados para um modelo para inferência e, em seguida, retornados a uma aplicação como previsões.
Na realidade, cada uma dessas etapas é geralmente tratada por ferramentas e serviços separados. Um sistema pode lidar com a captura de dados, outro gerencia o serviço de modelos, enquanto ferramentas adicionais são usadas para dimensionamento, monitoramento e registro. Manter esses componentes conectados e funcionando de forma confiável pode rapidamente se tornar complexo.
À medida que o uso aumenta, essa complexidade aumenta. Gerenciar infraestrutura, lidar com dependências e manter um desempenho consistente em todo o pipeline de ponta a ponta pode atrasar o desenvolvimento e tornar mais difícil implementar modelos de visão computacional em aplicações do mundo real.
A Ultralytics Platform reúne esses componentes em um único ambiente unificado. Isso fornece uma maneira mais coesa de gerenciar todo o fluxo de trabalho de implementação, ao mesmo tempo em que suporta desempenho e confiabilidade em escala.
Link to this sectionOpções de implementação de modelos habilitadas pela Ultralytics Platform#
Além de unificar o processo de implementação de modelos, a Ultralytics Platform também traz flexibilidade à forma como os modelos são implementados e usados.
Para suportar diferentes estágios da implementação de modelos de visão computacional, a plataforma oferece quatro opções: teste baseado no navegador com inferência instantânea, inferência compartilhada por meio de APIs para desenvolvimento, endpoints dedicados para implementações de produção escaláveis em regiões globais e exportação de modelos para execução em infraestrutura externa ou dispositivos de borda.
Então, vamos dar uma olhada mais de perto em como cada uma dessas opções funciona.
Link to this sectionValide modelos rapidamente usando a guia Predict#
Antes de mover um modelo para produção, é importante entender como ele se comporta com dados novos e não vistos. A Ultralytics Platform inclui uma guia Predict integrada que permite que você execute inferência diretamente no navegador sem qualquer configuração, infraestrutura ou dependências.
A guia Predict torna a validação de modelos rápida e interativa. Você pode fazer upload de imagens, usar exemplos pré-carregados ou capturar entradas com uma webcam, e a inferência é executada automaticamente assim que os dados são fornecidos.
Os resultados aparecem instantaneamente com sobreposições visuais, pontuações de confiança e saídas detalhadas, dando a você uma visão clara de como o modelo se comporta.
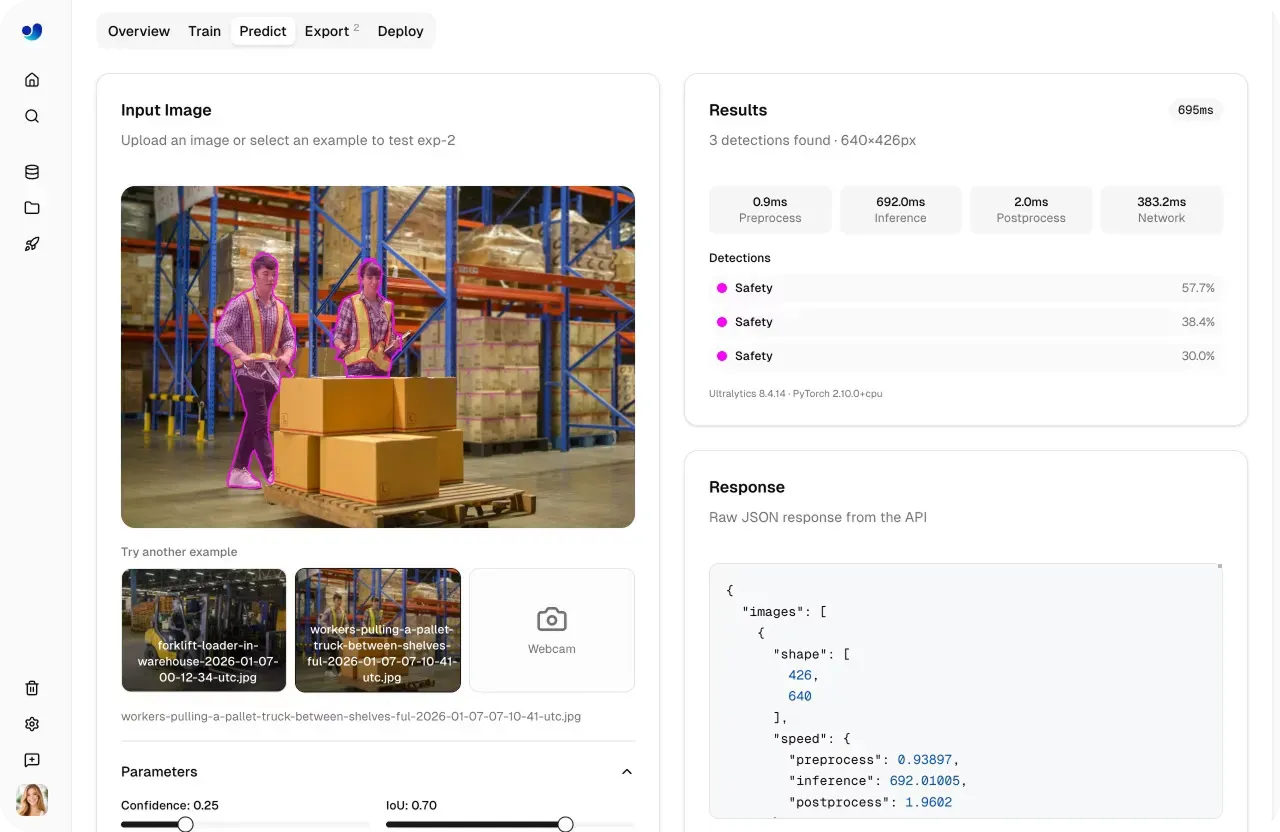
Fig 2. Um exemplo de validação de um modelo usando a guia Predict (Fonte)
Isso significa que, com alguns cliques, você pode testar diferentes entradas, ajustar parâmetros e avaliar o desempenho dentro de uma única interface antes de passar para a implementação.
Link to this sectionExecutando inferências compartilhadas para testes ou uso leve#
Digamos que você treinou um modelo e o validou usando a guia Predict. O próximo passo geralmente é começar a integrar esse modelo em uma aplicação ou fluxo de trabalho.
Em vez de configurar infraestrutura ou gerenciar servidores, a Ultralytics Platform fornece serviços de inferência compartilhados que permitem que você envie dados para seu modelo e receba previsões por meio de REST APIs simples.
Nos bastidores, a inferência compartilhada é executada em um sistema multilocatário em algumas regiões principais, onde as solicitações são roteadas automaticamente para o serviço disponível mais próximo. Isso ajuda a manter um desempenho responsivo, tornando possível que usuários em diferentes locais acessem modelos de forma consistente.
Você pode enviar entradas usando solicitações HTTP padrão e receber saídas estruturadas em retorno, tornando simples conectar modelos a aplicações, scripts ou fluxos de trabalho de automação. Esta configuração é uma ótima opção para desenvolvimento, testes, integrações ou uso mais leve antes de passar para implementações de produção mais escaláveis.
Link to this sectionImplemente modelos globalmente por meio de endpoints dedicados#
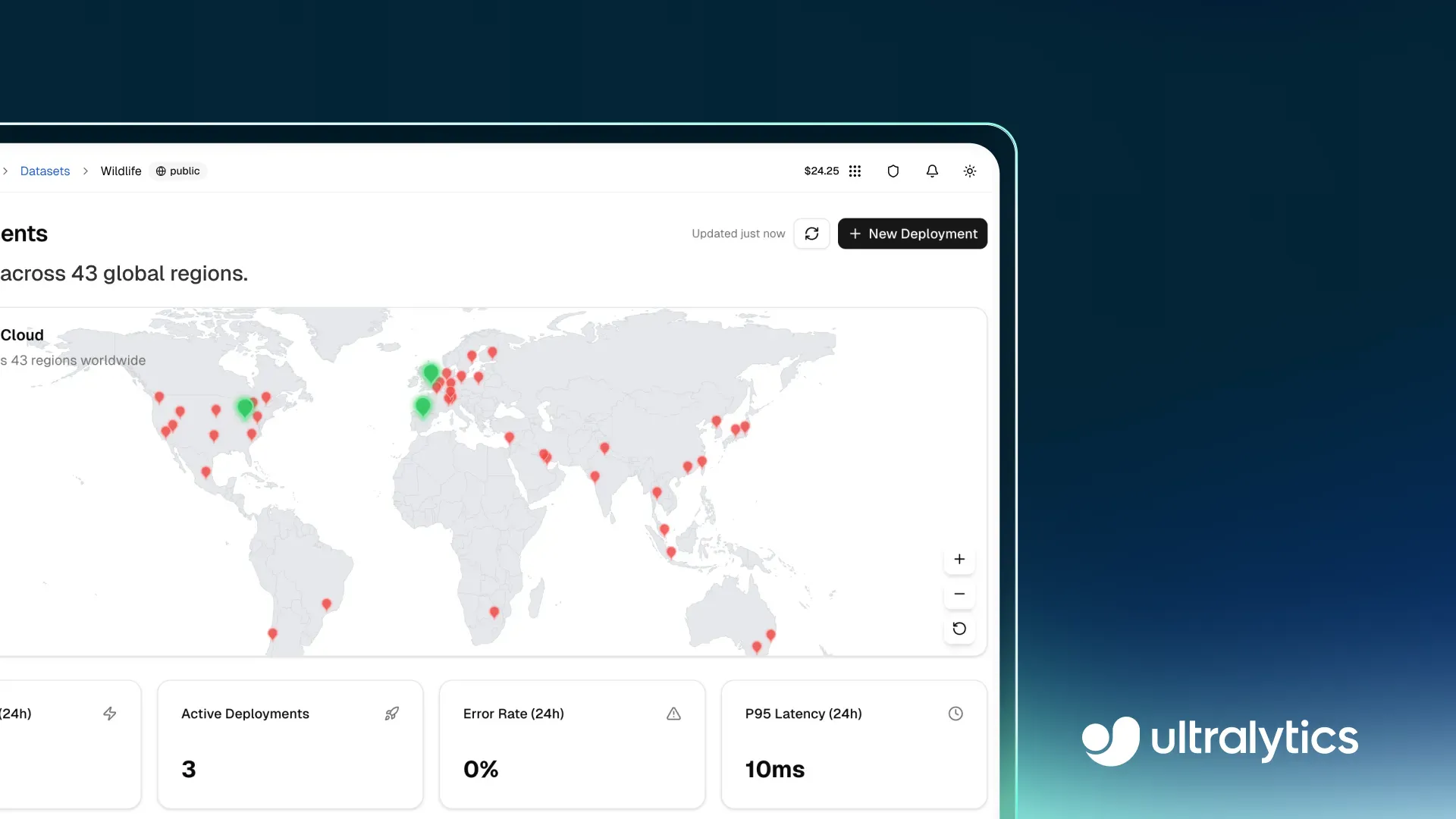
Uma vez que um modelo está pronto para produção, ele precisa lidar com o tráfego do mundo real de forma confiável e em escala. A Ultralytics Platform suporta isso com endpoints dedicados, onde os modelos são executados como serviços de locatário único em 43 regiões globais. Implementar mais perto dos usuários finais ajuda a reduzir a latência e manter um desempenho consistente em diferentes locais.
Cada endpoint é executado com seus próprios recursos de computação alocados e um URL exclusivo para solicitações de inferência. Esse nível de controle facilita ajustar as implementações com base nas necessidades de desempenho, desde casos de uso leves até aplicações mais exigentes e de alto rendimento que precisam de mais recursos computacionais.
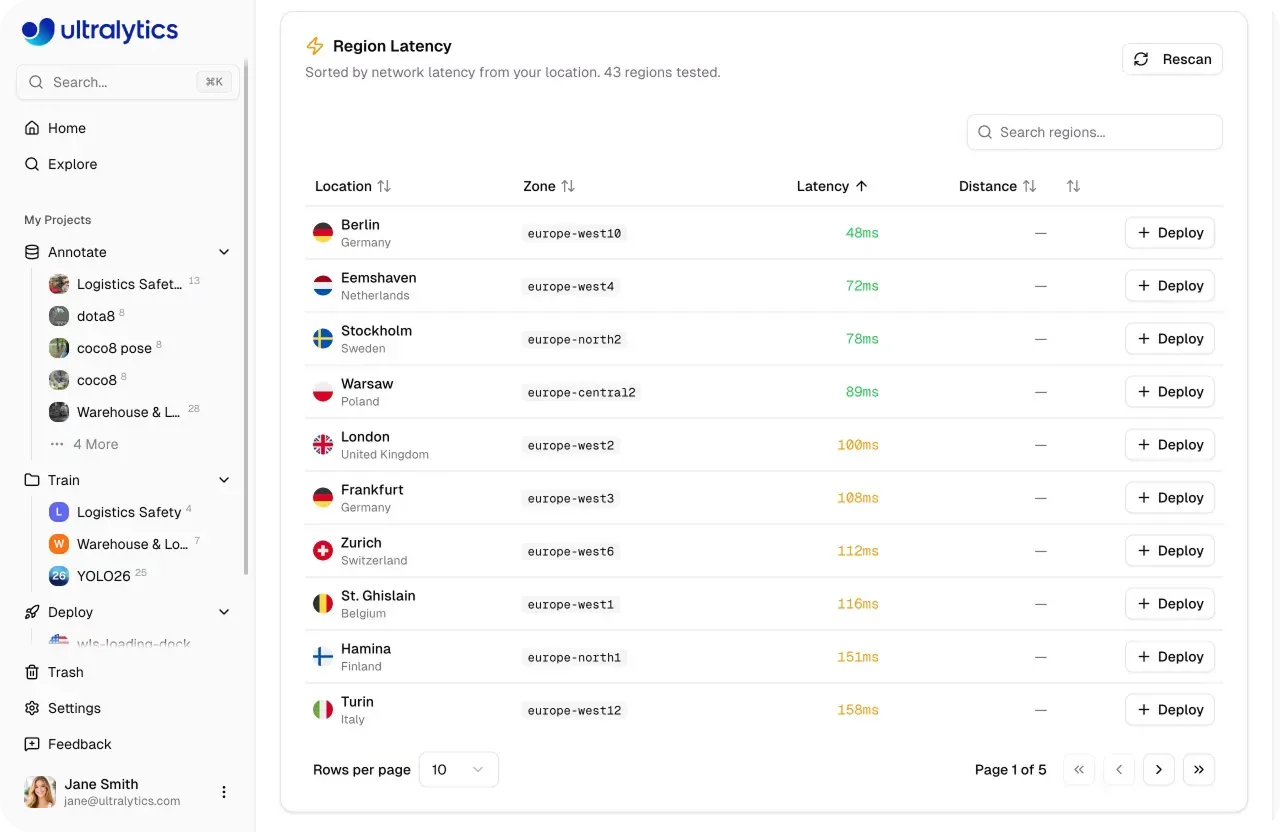
Fig 3. Você pode implementar modelos em 43 regiões globais usando a Ultralytics Platform (Fonte)
No entanto, endpoints dedicados são projetados para lidar com cargas de trabalho em mudança por conta própria, com escalonamento automático que ajusta os recursos com base no tráfego de entrada. Eles aumentam a escala durante períodos de alta demanda e diminuem quando o uso cai. Com o escalonamento para zero habilitado por padrão, endpoints ociosos são desligados automaticamente e reiniciam quando novas solicitações chegam, ajudando a otimizar o uso de recursos sem intervenção manual.
Link to this sectionExporte seu modelo facilmente com a Ultralytics Platform#
Hoje em dia, a IA de borda está se tornando cada vez mais essencial, à medida que mais aplicações dependem da execução de modelos diretamente em dispositivos como smartphones, câmeras e sistemas embarcados. Executar modelos localmente também pode ajudar a atender aos requisitos de privacidade de dados, já que dados confidenciais, como imagens ou fluxos de vídeo, podem ser processados diretamente no dispositivo sem serem enviados para servidores externos.
Nesses cenários, os modelos precisam ser executados fora da Ultralytics Platform, tornando a exportação de modelos uma parte crucial do processo de implementação. Modelos Ultralytics YOLO são frequentemente treinados usando Python e PyTorch, e podem então ser exportados para mais de 17 formatos diferentes, incluindo ONNX, TensorRT, CoreML e OpenVINO.
Esta ampla gama de formatos garante compatibilidade entre diversos hardwares, desde unidades de processamento gráfico (GPUs) de alto desempenho até dispositivos móveis e embarcados. Além disso, a exportação permite o ajuste de desempenho para ambientes específicos.
Dependendo do formato, os modelos podem atingir velocidades de inferência mais rápidas, como melhor desempenho de GPU com TensorRT ou execução otimizada de CPU com ONNX e OpenVINO. Opções como quantização FP16 e INT8 podem reduzir ainda mais o tamanho do modelo e melhorar o rendimento, o que é especialmente útil para implementações de borda.
Na Ultralytics Platform, a exportação é integrada diretamente ao fluxo de trabalho, tornando rápido gerar modelos otimizados com apenas alguns cliques. As equipes podem passar do treinamento para a execução de modelos em sistemas externos sem adicionar carga extra.
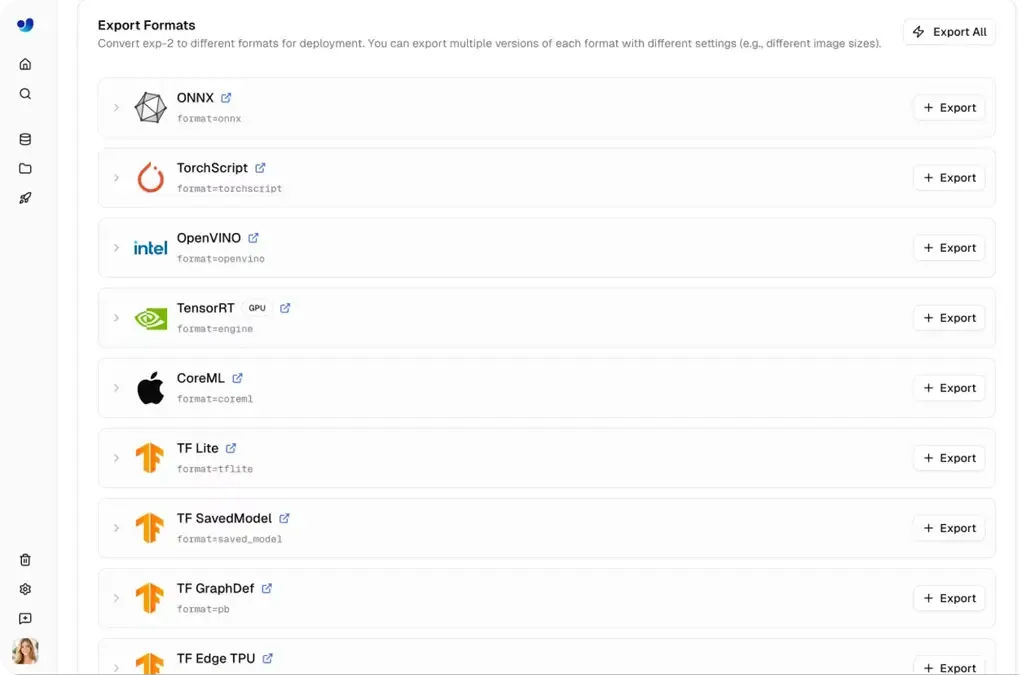
Fig 4. Uma seleção de formatos de exportação na Ultralytics Platform.
Link to this sectionEscolhendo a opção de implementação de modelo certa#
Cada opção de implementação na Ultralytics Platform suporta um estágio diferente do fluxo de trabalho, desde os primeiros testes até o uso em produção. Aqui está uma visão geral de quando você pode usar cada uma:
- Guia Predict: Isso é normalmente usado logo após o treinamento ou ajuste fino, quando você deseja validar como um modelo se comporta com novos dados usando inferência baseada no navegador.
- Inferência compartilhada: Neste estágio, os modelos podem ser integrados em aplicações por meio de APIs, tornando possível testar interações do mundo real durante o desenvolvimento.
- Endpoints dedicados: Estes são usados para implementações de produção, onde os modelos precisam de desempenho consistente, recursos dedicados e a capacidade de escalar em regiões globais.
- Exportação de modelo: Quando os modelos precisam ser executados fora da plataforma, a opção de exportá-los permite a implementação em dispositivos de borda, aplicações móveis ou infraestrutura personalizada.
As equipes frequentemente passam por essas opções passo a passo, indo da validação à integração e, finalmente, à implementação em produção, tudo dentro da plataforma.
Link to this sectionMonitorando modelos implementados por meio da Ultralytics Platform#
Por mais crítica que seja a implementação, o pipeline de visão não termina aí. Uma vez que um modelo está rodando em produção, o monitoramento contínuo é fundamental para garantir que ele tenha um desempenho confiável ao longo do tempo.
A Ultralytics Platform fornece ferramentas de monitoramento integrado que dão às equipes uma visibilidade clara de como seus modelos de IA de visão se comportam ao longo do tempo, apoiando um fluxo de trabalho de operações de aprendizado de máquina (MLOps) mais estruturado.
A página Deploy inclui um painel que rastreia as principais métricas, como total de solicitações, implementações ativas, latência de resposta e taxas de erro. Esses insights ajudam as equipes a entender os padrões de uso, avaliar a capacidade de resposta do sistema e garantir um desempenho de baixa latência em diferentes cargas de trabalho.
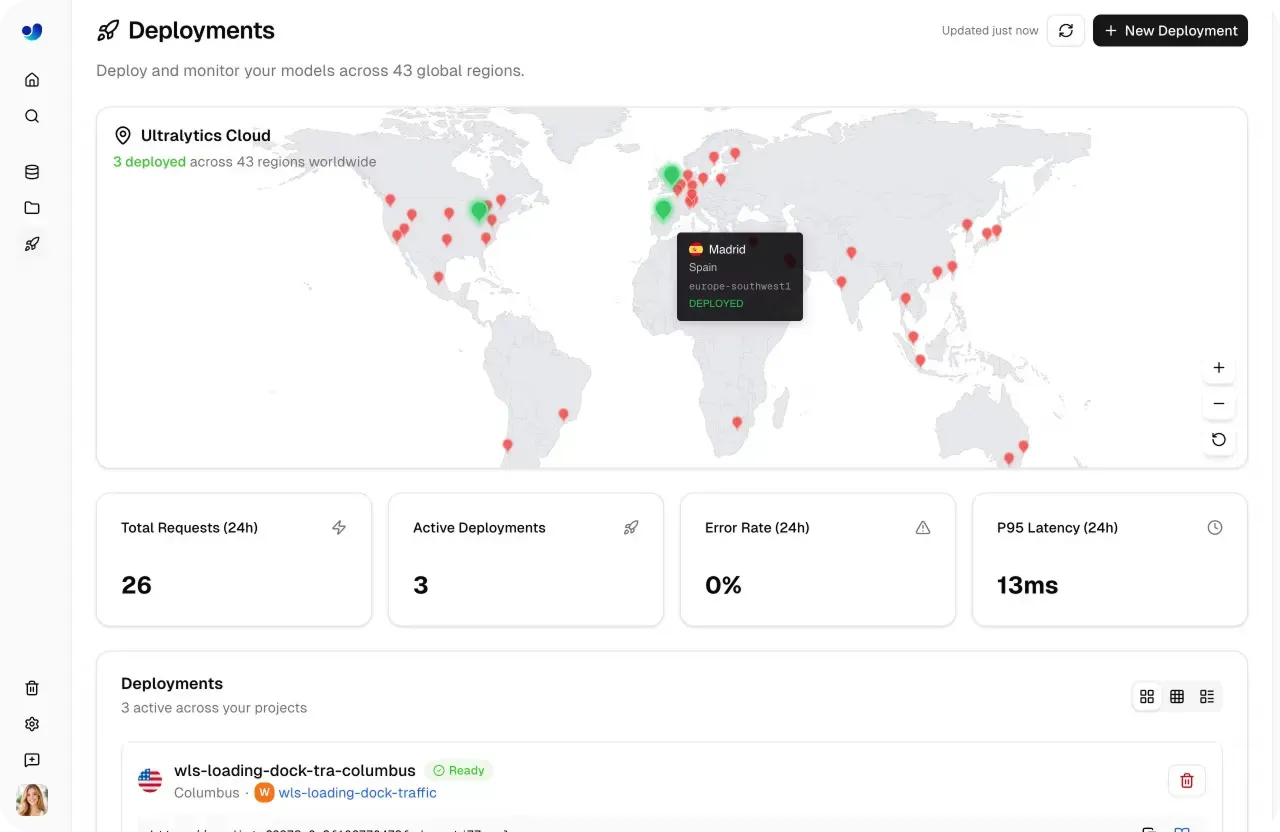
Fig 5. A Ultralytics Platform torna o monitoramento de modelos implementados fácil. (Fonte)
Cada endpoint dedicado também fornece observabilidade detalhada por meio de visualizações de implementação individuais. Isso inclui acesso a logs, status de integridade do modelo e dados de desempenho em tempo real. Os logs podem ser usados para depurar problemas, rastrear solicitações com falha e identificar possíveis problemas relacionados a dependências ou infraestrutura.
À medida que os ambientes de produção evoluem, fatores como dados de entrada em mudança, demandas de escala ou padrões de uso variáveis podem impactar a precisão e a robustez do modelo. Ao monitorar continuamente as métricas de desempenho, as equipes podem detectar anomalias, identificar gargalos e tomar ações corretivas, como otimização de modelo ou ajustes de recursos para manter um serviço de modelo consistente e confiável.
Link to this sectionConstruindo escalabilidade em implementações de modelos de visão computacional#
Escalar sistemas de visão computacional tem significado, tradicionalmente, unir fluxos de trabalho e estruturas que nunca foram projetados para funcionar como um só. Pipelines de dados, ciclos de treinamento, infraestrutura de implementação e sistemas de monitoramento geralmente vivem em lugares separados, criando atrito em cada estágio.
O verdadeiro desafio não é apenas construir modelos, mas mantê-los em movimento. Passar dos dados para a produção, adaptar-se a novas entradas, lidar com a demanda crescente e melhorar continuamente sem desacelerar.
O que se destaca na Ultralytics Platform é que esse movimento é nativo. Em vez de tratar cada estágio como uma etapa separada, ela os conecta em um loop contínuo onde os modelos podem ser desenvolvidos, implementados, observados e atualizados dentro do mesmo ambiente.
Essa mudança altera a forma como as equipes escalam. Já não se trata da orquestração de ferramentas ou infraestrutura, mas de manter o ritmo à medida que os sistemas crescem.
Link to this sectionPrincipais pontos#
Trazer modelos de aprendizado de máquina, como modelos de visão computacional, para aplicações do mundo real exige que eles sejam confiáveis, escaláveis e fáceis de gerenciar. A Ultralytics Platform simplifica esse processo combinando várias funções, como serviço de modelo, implementação e monitoramento, em um único ambiente unificado. Com opções de implementação flexíveis e ferramentas integradas, as equipes podem passar da experimentação para a produção mais rapidamente e com menos complexidade.
Confira nossa comunidade e explore nosso repositório GitHub para saber mais. Explore nossas páginas de soluções para ver várias aplicações, como IA na área da saúde e visão computacional na logística. Descubra nossas opções de licenciamento e comece a construir hoje mesmo!






