Addestra modelli YOLO più velocemente con Ultralytics Platform
Scopri come addestrare i modelli YOLO più velocemente con Ultralytics Platform, un ambiente end-to-end creato per accelerare il percorso dai dati al deployment.
La scorsa settimana, Ultralytics ha presentato la Ultralytics Platform, uno spazio di lavoro unificato progettato per semplificare il modo in cui i team creano, addestrano e distribuiscono modelli di computer vision. Invece di destreggiarsi tra molteplici strumenti, la piattaforma riunisce tutto in un unico posto. Passare dall'idea alla distribuzione con modelli di visione AI diventa semplice.
Questo è fondamentale perché la computer vision sta rapidamente diventando una parte essenziale di diversi settori. Potenzia applicazioni come l'ispezione nella produzione, l'analisi nel retail e la navigazione autonoma.
Trasformare queste applicazioni basate sulla visione in sistemi affidabili dipende da quanto bene vengono addestrati i modelli. L'addestramento dei modelli implica l'apprendimento da dati etichettati, in modo che il modello possa riconoscere pattern ed effettuare previsioni accurate. In generale, modelli ben addestrati portano a migliori prestazioni del modello e a risultati più affidabili nelle applicazioni reali.
Tuttavia, addestrare un modello di computer vision non è sempre semplice. Consiste in vari aspetti, come la configurazione degli ambienti, la selezione delle risorse di calcolo appropriate, la regolazione degli iperparametri e il tracciamento di molteplici esperimenti di addestramento. Quando questi passaggi sono distribuiti su diversi strumenti e sistemi, il flusso di lavoro di addestramento diventa rapidamente complesso e difficile da gestire.
La Ultralytics Platform risolve questo problema portando l'intero processo di addestramento in un'unica dashboard unificata. Puoi configurare, eseguire e monitorare i lavori di addestramento in un unico posto, che tu stia lavorando nel cloud, localmente o su Google Colab.
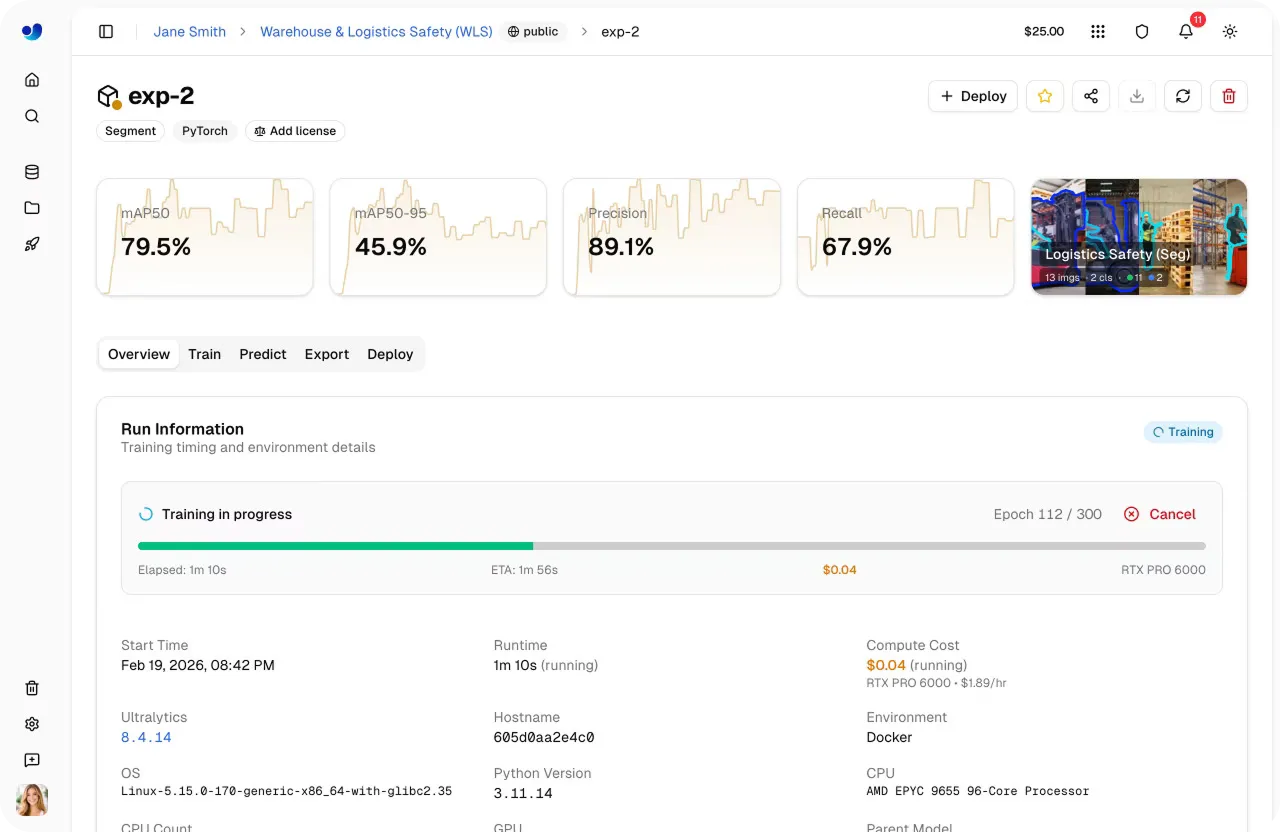
Fig 1. Uno sguardo all'addestramento del modello all'interno della Ultralytics Platform (Fonte)
In questo articolo, esploreremo come la Ultralytics Platform ottimizza l'addestramento del modello e perché può darti un vantaggio nei tuoi progetti di visione AI. Iniziamo!
Link to this sectionI modelli di computer vision imparano dai dati attraverso l'addestramento del modello#
Prima di immergerci in come funziona l'addestramento del modello sulla Ultralytics Platform, facciamo prima un passo indietro ed esaminiamo cosa sia l'addestramento del modello e cosa comporti.
L'addestramento del modello è il processo attraverso il quale un modello di computer vision impara a interpretare i dati visivi. Analizza immagini o video e regola gradualmente i suoi parametri interni per eseguire vision tasks come il rilevamento di oggetti, la classificazione delle immagini e la segmentazione delle istanze in modo accurato. Nel tempo, il modello migliora imparando i pattern direttamente dai dati che vede.
La qualità dell'addestramento dipende pesantemente dai dataset. Puoi pensare a un dataset come a un set di flashcard che un insegnante userebbe per addestrare uno studente, dove ogni esempio aiuta il modello a imparare cosa cercare.
Un tipico dataset di computer vision include immagini, solitamente in formati come JPG o PNG, e annotazioni che descrivono cosa c'è in ogni immagine. Queste annotazioni, spesso salvate come file JSON o TXT, forniscono le etichette e il contesto di cui il modello ha bisogno per imparare efficacemente.
Ma l'addestramento non riguarda solo l'alimentazione dei dati in un modello. Coinvolge diversi passaggi chiave, dalla preparazione del dataset alla selezione del modello giusto e alla configurazione del processo di addestramento. Successivamente, diamo un'occhiata più da vicino ad alcuni di questi passaggi.
Link to this sectionUno sguardo a come vengono preparati i dataset#
Potrebbe sembrare che una volta ottenuto un dataset, tu possa iniziare immediatamente ad addestrare un modello, ma ci sono alcuni passaggi che devi fare prima, come la suddivisione del dataset.
Generalmente, un dataset viene suddiviso in tre parti: set di addestramento (training set), set di validazione (validation set) e set di test (testing set). Le immagini di addestramento vengono utilizzate per insegnare al modello i pattern nei dati, mentre il set di validazione aiuta a monitorare e perfezionare le prestazioni durante l'addestramento.
Il set di test viene utilizzato alla fine per valutare quanto bene il modello funzioni su dati completamente nuovi e mai visti. Questa configurazione aiuta a garantire che il modello non si limiti a memorizzare i dati, ma possa generalizzare a scenari del mondo reale.
Link to this sectionSelezionare il modello giusto per l'addestramento#
Un altro passaggio importante prima dell'addestramento è scegliere il modello che vuoi usare. In molti casi, ciò significa selezionare un modello pre-addestrato. Modelli come quelli di Ultralytics YOLO sono già addestrati su grandi dataset e hanno imparato pattern visivi generali, rendendoli un ottimo punto di partenza.
L'utilizzo di questi modelli è un esempio di transfer learning, dove costruisci sulla conoscenza esistente e adatti il modello al tuo compito specifico. Questo approccio aiuta ad accelerare l'addestramento e a migliorare i risultati, specialmente quando lavori con dati limitati.
Questi modelli arrivano anche in diverse dimensioni, ognuna delle quali offre un compromesso tra velocità e precisione. I modelli più piccoli sono più veloci ed efficienti, mentre i modelli più grandi tendono a offrire una maggiore precisione ma richiedono più capacità di calcolo.
Link to this sectionConfigurare i parametri di addestramento per i modelli di visione#
Dopo aver preparato un dataset e selezionato un modello, il passaggio successivo è configurare come il modello impara.
Un modello di computer vision viene addestrato utilizzando un set di parametri che determinano come elabora i dati, aggiorna i suoi pesi e migliora nel tempo. Queste impostazioni influiscono direttamente sia sulla velocità di addestramento che sulla precisione finale, rendendole essenziali per ottenere risultati solidi.
Ecco alcuni dei parametri di addestramento più comunemente usati:
- Epochs: Rappresenta quante volte il modello attraversa l'intero dataset durante l'addestramento. Aumentare il numero di epoche dà al modello più opportunità di imparare pattern dai dati.
- Batch size: È il numero di immagini elaborate insieme in un singolo passaggio di addestramento. Batch size più grandi possono velocizzare l'addestramento ma richiedono più memoria.
- Image size: Specifica la risoluzione delle immagini di input utilizzate durante l'addestramento. Risoluzioni più alte possono migliorare la precisione del rilevamento ma aumentano il costo computazionale.
- Learning rate: È la velocità con cui il modello aggiorna i suoi parametri interni durante l'addestramento. Valori troppo alti o troppo bassi possono rendere l'addestramento instabile.
- Optimizer: È l'algoritmo responsabile dell'aggiornamento dei parametri del modello in base all'errore calcolato durante ogni iterazione di addestramento.
Nei flussi di lavoro basati su Ultralytics YOLO, queste configurazioni sono solitamente definite in un file YAML. Questo file specifica i percorsi del dataset, i nomi delle classi e come vengono suddivisi i dati. Agisce come una configurazione centrale che dice al modello come interpretare il dataset.
Link to this sectionDa flussi di lavoro frammentati a un'esperienza unificata con la Ultralytics Platform#
Abbiamo appena discusso alcuni dei passaggi chiave coinvolti nell'addestramento di un modello di computer vision, dalla preparazione dei dataset alla selezione di un modello e alla configurazione dei parametri di addestramento. In pratica, il processo spesso va oltre, includendo il tracciamento degli esperimenti, il confronto di molteplici cicli di addestramento e il perfezionamento continuo dei modelli nel tempo.
Questi passaggi sono raramente gestiti in un unico posto. I dataset possono essere preparati in uno strumento, i cicli di addestramento eseguiti in un altro ambiente e il tracciamento degli esperimenti gestito separatamente. Man mano che i progetti crescono, questa frammentazione aggiunge complessità, rallenta l'iterazione e rende più difficile mantenere tutto organizzato.
La Ultralytics Platform elimina questa complessità portando l'intero flusso di lavoro di addestramento in un unico ambiente. Invece di passare da uno strumento all'altro, puoi gestire dataset, configurare l'addestramento, eseguire esperimenti e monitorare i risultati, tutto in un unico posto.
Successivamente, immergiamoci in come la Ultralytics Platform rende più intelligente l'addestramento dei modelli.
Link to this sectionOpzioni di addestramento supportate dalla Ultralytics Platform#
Nelle applicazioni reali, addestrare un modello di computer vision richiede spesso ambienti flessibili. A seconda della dimensione del tuo dataset, della complessità del modello e dell'hardware disponibile, potresti scegliere di eseguire l'addestramento nel cloud, su una macchina locale o tramite ambienti notebook esterni.
La Ultralytics Platform supporta le seguenti opzioni di addestramento per soddisfare queste esigenze:
- Cloud training: L'addestramento viene eseguito su GPU nel cloud gestite da Ultralytics. Questa opzione è ideale per dataset più grandi o modelli più complessi che richiedono risorse computazionali significative.
- Local training: Questa opzione utilizza l'hardware disponibile sulla tua macchina ed è ottima per esperimenti rapidi, test di configurazione o per lavorare con dataset più piccoli. Per carichi di lavoro più scalabili, l'addestramento può essere eseguito anche nel tuo ambiente cloud, come AWS o GCP.
- Google Colab: Con la Ultralytics Platform, puoi eseguire l'addestramento nell'ambiente notebook ospitato di Google Colab, consentendo un flusso di lavoro flessibile basato su browser senza configurare una macchina locale.
Link to this sectionEsplorare l'addestramento nel cloud sulla Ultralytics Platform#
Quando si tratta di progetti di computer vision, addestrare modelli localmente o tramite ambienti notebook non è sempre facile.
Ad esempio, con l'addestramento locale, le prestazioni dipendono interamente dal tuo hardware, il che può limitare la potenza di calcolo e rallentare la sperimentazione. Le GPU sono essenziali per un addestramento efficiente, ma non ogni configurazione ha un accesso affidabile ad esse.
Sebbene gli ambienti notebook come Google Colab offrano un'alternativa fornendo GPU basate su cloud, le sessioni sono spesso temporanee e possono interrompere cicli di addestramento più lunghi. Man mano che i dataset crescono e i flussi di lavoro diventano più complessi, queste limitazioni possono trasformarsi rapidamente in colli di bottiglia, rendendo l'addestramento più lento e meno affidabile.
La Ultralytics Platform risolve questo problema con la sua opzione di cloud training. Fornisce un ambiente pronto all'uso in cui le dipendenze Python e framework come PyTorch sono pre-configurati, permettendoti di iniziare l'addestramento senza configurazioni aggiuntive.
Da una singola dashboard, puoi avviare lavori di addestramento e monitorare i progressi in tempo reale. Questo rende più facile concentrarsi sul miglioramento dei modelli invece che sulla gestione dell'infrastruttura.
Ora, vediamo come iniziare con l'addestramento nel cloud sulla Ultralytics Platform.
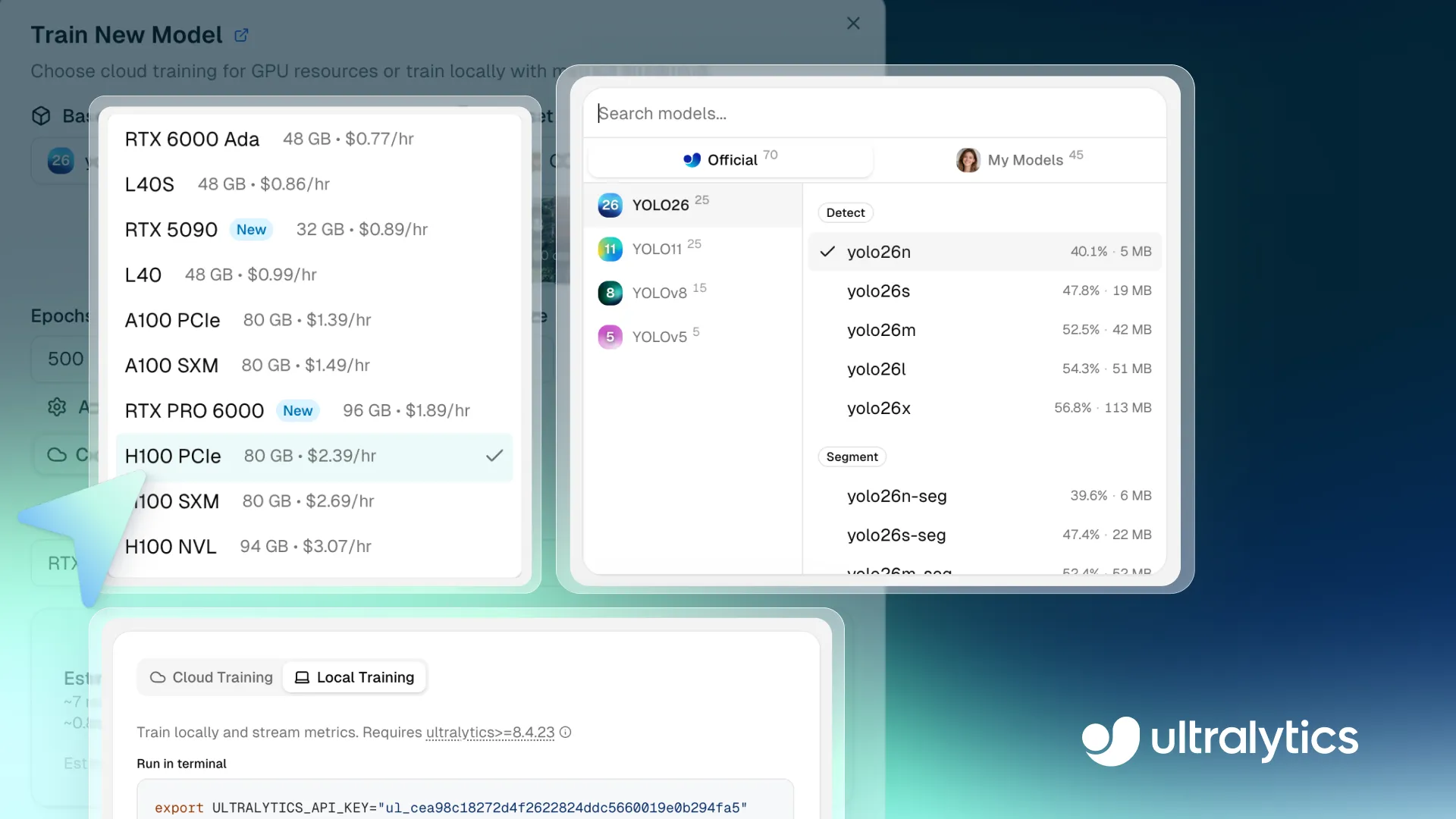
Link to this sectionPassaggio 1: Seleziona un modello di base#
Il primo passo è scegliere un modello di base per il tuo ciclo di addestramento. Puoi selezionare un Ultralytics YOLO model pre-addestrato, clonare un modello della community o caricare i tuoi pesi pre-addestrati per soddisfare requisiti personalizzati.
La piattaforma supporta tutti i modelli Ultralytics YOLO, inclusi Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8 e Ultralytics YOLOv5, ognuno disponibile in diverse varianti di dimensioni come nano (n), small (s), medium (m), large (l) ed extra-large (x). Con diverse varianti di modelli che offrono un compromesso tra velocità e precisione, puoi scegliere un modello che si adatta alle tue esigenze di prestazioni e di calcolo.
Questi modelli supportano una serie di compiti di computer vision con cui gli utenti di Ultralytics YOLO hanno già familiarità, tra cui rilevamento di oggetti, segmentazione delle istanze, classificazione delle immagini, rilevamento di oriented bounding box (OBB) e stima della posa.
Se hai requisiti personalizzati, puoi anche caricare i pesi del tuo modello pre-addestrato. Ciò significa che puoi continuare l'addestramento o perfezionare un modello esistente come un rilevatore di oggetti all'interno della piattaforma, invece di ricominciare da zero. È particolarmente utile se hai già addestrato un modello altrove o vuoi adattare un modello a un caso d'uso più specifico.
Link to this sectionPassaggio 2: Seleziona un dataset#
Il passaggio successivo è selezionare un dataset per l'addestramento. Sulla Ultralytics Platform, puoi utilizzare dataset preesistenti come il dataset COCO, clonare dataset dalla community o caricare il tuo dataset personalizzato su misura per la tua applicazione specifica.
La piattaforma supporta formati di annotazione comuni come Ultralytics YOLO e COCO, e può anche gestire caricamenti di immagini grezze se prevedi di annotare dati personalizzati direttamente sulla piattaforma.
Una volta caricati, i dataset vengono elaborati automaticamente, inclusa la validazione, la normalizzazione, l'analisi delle etichette e la generazione di statistiche. Questo ti dà una visibilità immediata sui tuoi dati, incluse le distribuzioni delle classi e la struttura del dataset, e aiuta a garantire che tutto sia pronto per l'addestramento.
I dataset sono anche automaticamente collegati ai cicli di addestramento, permettendoti di tracciare quali dati sono stati utilizzati per ogni modello e mantenere la coerenza tra gli esperimenti.
Link to this sectionPassaggio 3: Configura i parametri di addestramento#
Dopo aver scelto il dataset, puoi configurare i parametri di addestramento che controllano come il modello impara. Questi includono epoche, batch size, dimensione dell'immagine e nome del ciclo per il registro di addestramento. Molti di questi parametri influenzano sia la durata dell'addestramento che le prestazioni finali del modello.
Per un addestramento più controllato, la piattaforma ti consente anche di regolare parametri avanzati come il learning rate, il tipo di ottimizzatore, le impostazioni di aumentazione del colore e altre opzioni di addestramento. Queste impostazioni possono perfezionare il processo di addestramento per migliorare la precisione e la stabilità del modello.
Link to this sectionPassaggio 4: Seleziona una GPU#
Successivamente, puoi selezionare la configurazione della GPU per il tuo ciclo di addestramento. Scegliere la GPU giusta dipende da fattori come la dimensione del dataset, la batch size, la risoluzione dell'immagine e la complessità del modello. Trovare il giusto equilibrio aiuta a mantenere l'addestramento efficiente senza utilizzare più potenza di calcolo del necessario.
La Ultralytics Platform offre 22 opzioni di GPU con diversi livelli di VRAM (memoria su una GPU) e potenza di calcolo, supportando tutto, dai piccoli compiti ai carichi di lavoro su larga scala.
Utilizzando questo, puoi adattare l'hardware alle tue esigenze specifiche, che tu stia addestrando modelli leggeri o lavorando con dataset grandi e complessi. Per saperne di più, controlla l'elenco delle GPU disponibili nella pagina Platform training docs di Ultralytics.
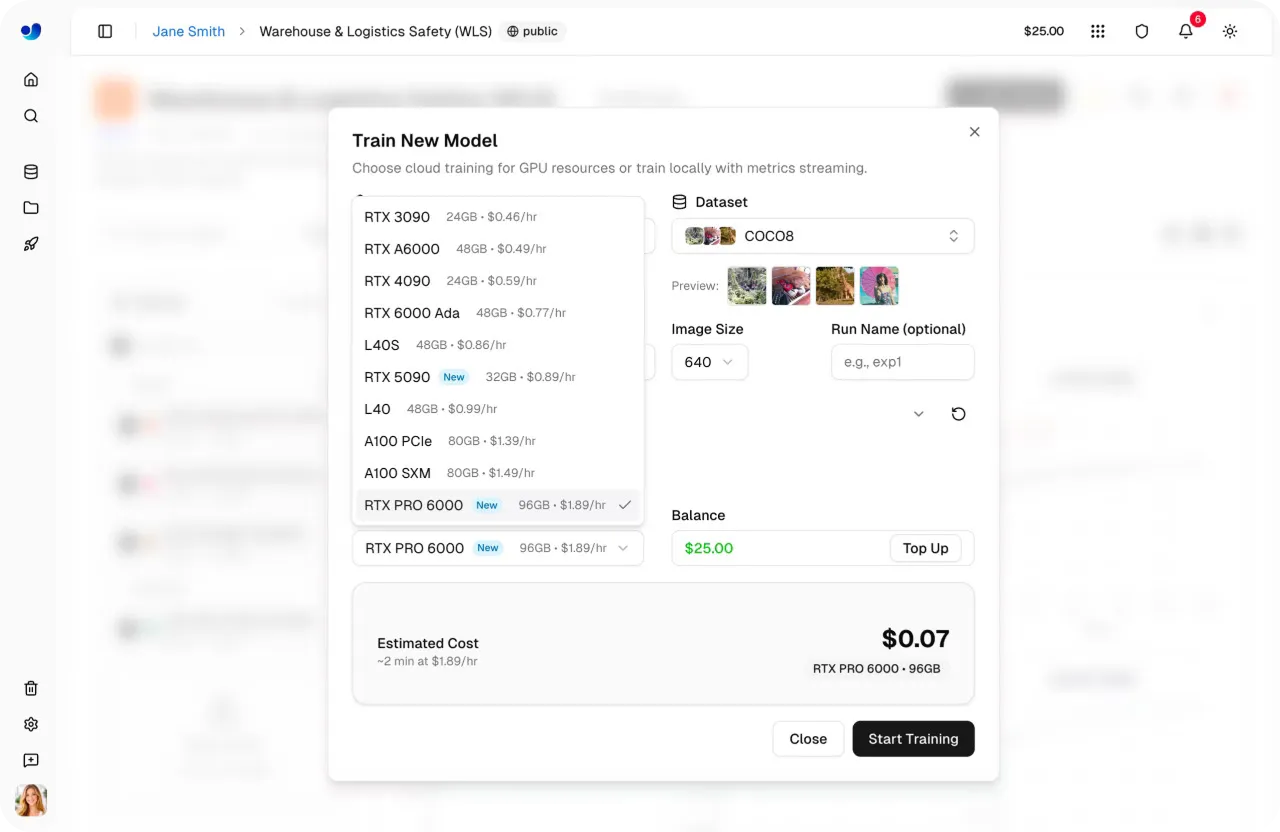
Fig 2. Alcune delle opzioni GPU abilitate tramite la Ultralytics Platform (Fonte)
Link to this sectionPassaggio 5: Avvia l'addestramento nel cloud#
Una volta selezionati il modello, il dataset, i parametri di addestramento e l'opzione di calcolo, avviare un ciclo di addestramento è veloce. Dalla dashboard, puoi avviare l'addestramento con un solo clic e la piattaforma gestisce il resto inizializzando l'ambiente ed eseguendo il lavoro sulla GPU selezionata.
All'inizio dell'addestramento, puoi monitorare i progressi direttamente all'interno della piattaforma. La scheda Train fornisce visibilità in tempo reale sulle metriche chiave, incluse metriche di prestazione, curve di perdita, utilizzo del sistema e registri di addestramento dal vivo.
Per saperne di più sull'addestramento locale o sull'uso di Google Colab con la Ultralytics Platform, puoi esplorare altri tutorial all'interno della documentazione ufficiale di Ultralytics.
Link to this sectionValutare e confrontare i modelli sulla Ultralytics Platform#
Una volta completato l'addestramento, il passaggio successivo è valutare quanto bene funzioni il tuo modello. Sulla Ultralytics Platform, puoi confrontare molteplici cicli di addestramento all'interno di un progetto, dandoti una visione chiara di come funzionano i diversi esperimenti.
Durante lo sviluppo dei modelli, l'addestramento viene spesso ripetuto più volte con impostazioni diverse, come la modifica del learning rate, della batch size o della dimensione del modello, per migliorare i risultati. Ognuno di questi cicli produce un modello leggermente diverso, motivo per cui confrontarli è fondamentale.
I progetti agiscono come un hub centrale dove i modelli e gli esperimenti sono organizzati insieme. Puoi tracciare i progressi, rivedere i risultati e rimanere concentrato senza passare da uno strumento o da una visualizzazione all'altra.
Da questa vista unificata, puoi anche analizzare metriche di prestazione chiave come precision, recall e mAP (mean average precision) per capire come funziona il tuo modello tra le diverse classi. Puoi anche confrontare i cicli di addestramento fianco a fianco per identificare quali configurazioni offrono i risultati migliori.
Per completare queste metriche, puoi utilizzare la scheda Predict per testare rapidamente i modelli addestrati su immagini o dati campione, aiutandoti a convalidare visivamente le prestazioni e individuare potenziali problemi.
Con queste informazioni, puoi selezionare il modello con le migliori prestazioni, solitamente salvato come checkpoint “best.pt”, e passare alla fase successiva, che si tratti di un'ulteriore valutazione, dell'utilizzo del modello per eseguire l'inferenza o della distribuzione del modello tramite la piattaforma.
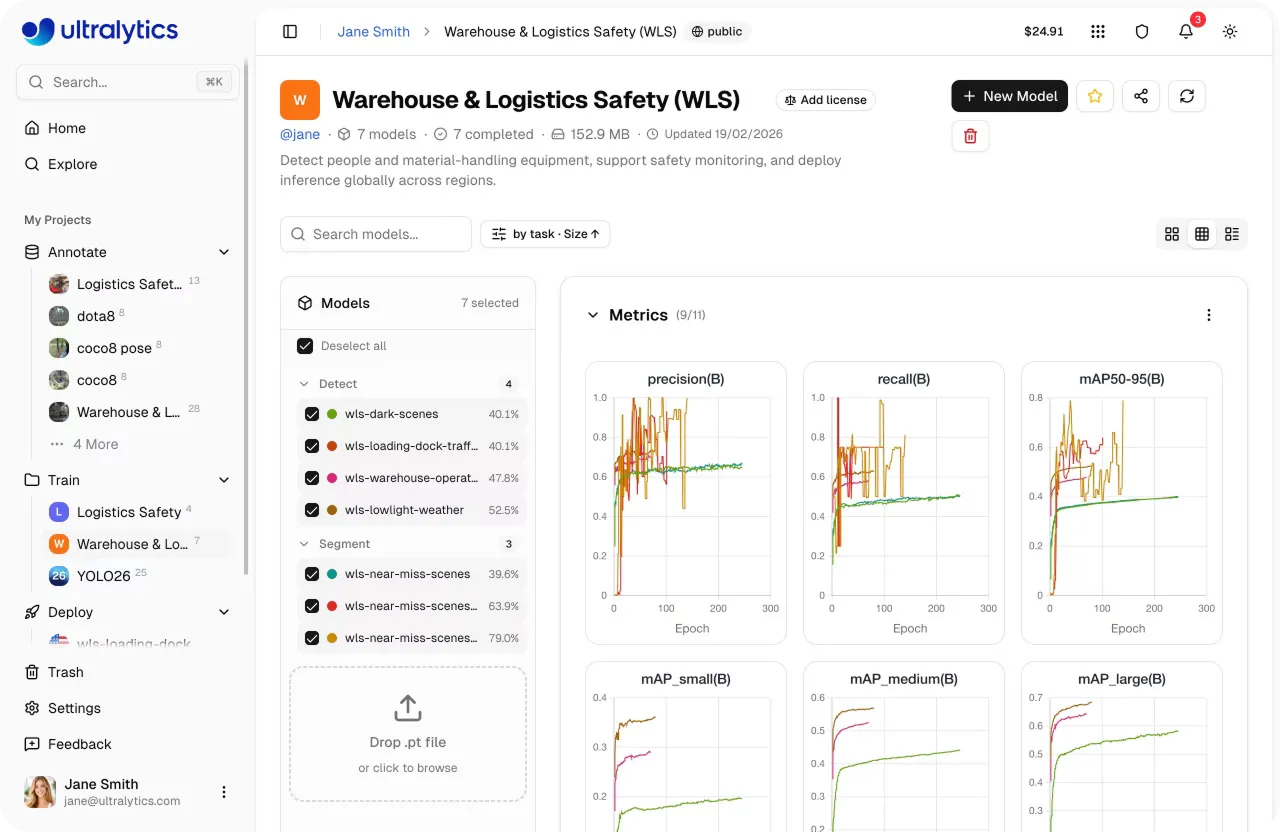
Fig 3. Un esempio di visualizzazione delle metriche sulla Ultralytics Platform (Fonte)
Link to this sectionStimare il costo dell'addestramento all'interno della Ultralytics Platform#
L'addestramento di modelli di rilevamento oggetti nel cloud comporta costi di calcolo, specialmente quando accedi a GPU ad alte prestazioni. Per rendere tutto più comodo, la Ultralytics Platform fornisce una stima dei costi prima che inizi l'addestramento.
Ti offre una chiara visibilità sull'utilizzo previsto, aiutandoti a pianificare i carichi di lavoro, gestire i budget ed evitare spese impreviste prima di avviare un lavoro di addestramento. Ecco come puoi controllare i costi stimati prima di iniziare l'addestramento.
Link to this sectionCome viene stimato il tempo di addestramento#
Per stimare il costo con precisione, la piattaforma calcola prima quanto tempo richiederà una singola epoca di addestramento. Questo dipende da fattori come la dimensione del dataset, la dimensione del modello, la risoluzione dell'immagine, la batch size e la velocità della GPU selezionata.
Utilizzando questi input, determina il tempo stimato per epoca e lo scala sull'intero ciclo di addestramento. La durata totale viene calcolata combinando il tempo di tutte le epoche con un piccolo sovraccarico iniziale.
Il sovraccarico tiene conto di attività come l'inizializzazione dell'ambiente, il caricamento dei dataset e la preparazione della GPU, garantendo che la stima rifletta il processo di addestramento completo, non solo il ciclo di addestramento.
Link to this sectionCome viene calcolato il costo dell'addestramento#
Una volta stimato il tempo totale di addestramento, la piattaforma lo converte in costo utilizzando la tariffa oraria della GPU selezionata.
Combinando la durata dell'addestramento con il prezzo della GPU, possiamo ottenere una stima chiara di quanto costerà il ciclo prima ancora che inizi.
Avere una visibilità anticipata rende facile regolare la tua configurazione, come la regolazione dei parametri di addestramento o la selezione di una GPU diversa, così da poter bilanciare meglio prestazioni e costo.
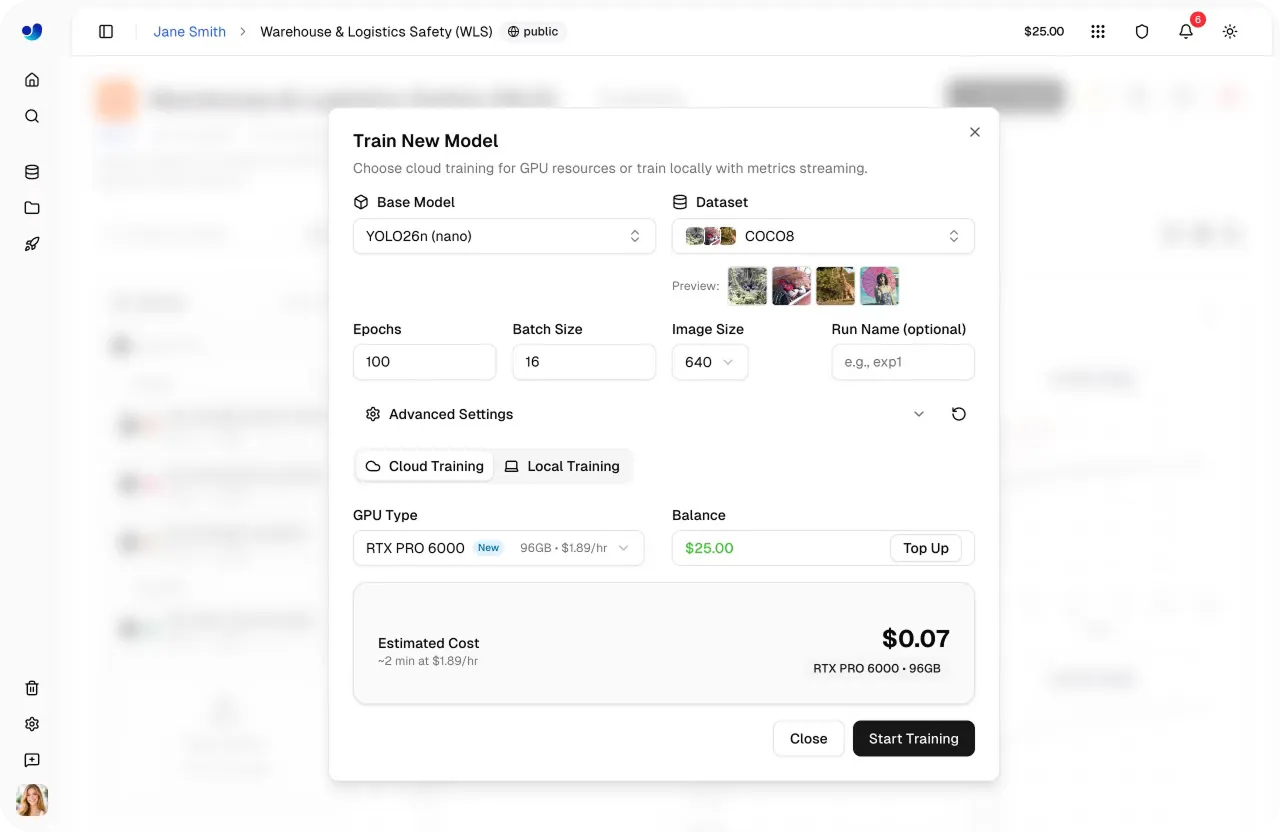
Fig 4. Configurazione dell'addestramento del modello e stima del costo all'interno della Ultralytics Platform (Fonte)
Link to this sectionPrincipali vantaggi dell'utilizzo della Ultralytics Platform per l'addestramento dei modelli#
Finora, abbiamo esaminato i passaggi chiave coinvolti nell'addestramento dei modelli di computer vision e come si uniscono sulla Ultralytics Platform.
Oltre a queste funzionalità principali, ci sono capacità aggiuntive che migliorano il flusso di lavoro di addestramento. Ecco una panoramica di alcuni dei principali vantaggi dell'utilizzo della Ultralytics Platform per l'addestramento dei modelli:
- Riproducibilità integrata degli esperimenti: Ogni ciclo di addestramento viene registrato automaticamente con la sua configurazione completa, incluso modello, dataset, parametri e configurazione del calcolo. Questo rende semplice rivisitare gli esperimenti e riprodurre i risultati in modo affidabile.
- Approfondimenti sull'addestramento nel tempo: Invece di visualizzare solo i risultati finali, puoi monitorare come le prestazioni si evolvono nel corso delle epoche, aiutandoti a comprendere meglio il comportamento del modello durante l'addestramento.
- Riduzione del carico operativo: Gestendo in background la configurazione dell'ambiente, la gestione delle dipendenze e l'infrastruttura, la piattaforma ti consente di concentrarti maggiormente sullo sviluppo del modello e meno sulla configurazione.
- Organizzazione centralizzata degli esperimenti: I progetti fungono da luogo unico per gestire modelli, dataset ed esecuzioni di addestramento, aiutando a mantenere gli esperimenti strutturati man mano che i flussi di lavoro diventano più complessi.
Link to this sectionPunti chiave#
L'addestramento è una delle fasi più importanti nel ciclo di vita di un modello di machine learning. Determina con quanta precisione un modello riesce a riconoscere e interpretare dati visivi.
Combinando configurazione dei dati di addestramento, monitoraggio, confronto tra esperimenti e stima dei costi in un unico ambiente, la Ultralytics Platform semplifica il processo di creazione di modelli di computer vision ad alte prestazioni e la loro preparazione per il deployment.
Dai un'occhiata alla nostra community in crescita e al nostro repository GitHub per saperne di più sulla visione artificiale. Se stai cercando di costruire soluzioni di visione, dai un'occhiata alle nostre opzioni di licenza. Esplora le nostre pagine delle soluzioni per saperne di più sui vantaggi della visione artificiale nella produzione e dell'IA nell'agricoltura.






