Vai trò của học máy và khai thác dữ liệu trong thị giác máy tính
Khám phá cách học máy và khai thác dữ liệu hỗ trợ thị giác máy tính, thúc đẩy tiến bộ trong chăm sóc sức khỏe, thương mại điện tử, xe tự lái và ra quyết định thời gian thực.

Trí tuệ nhân tạo (AI) là một công nghệ mạnh mẽ, cực kỳ hiệu quả trong việc phân tích các loại dữ liệu khác nhau và học hỏi từ chúng theo thời gian. Ví dụ, computer vision, một nhánh của AI, tập trung vào việc hiểu dữ liệu hình ảnh. Một lĩnh vực quan trọng khác là machine learning (ML), cùng với data mining, đóng vai trò lớn trong việc cải thiện các computer vision models. Data mining tập trung vào việc tìm kiếm các mẫu hữu ích trong các datasets lớn, trong khi machine learning sử dụng các mẫu này để huấn luyện các AI models thực hiện các tác vụ mà không cần hướng dẫn chi tiết.
Những công nghệ này đang trở nên phổ biến hơn trong các ngành công nghiệp như xe tự lái, tài chính và sản xuất vì chúng đã phát triển mạnh mẽ trong những năm gần đây. Trong bài viết này, chúng tôi sẽ phân tích data mining và machine learning là gì, cách chúng được sử dụng trong computer vision, và cách chúng phối hợp với nhau để thúc đẩy sự tiến bộ trong các lĩnh vực như chăm sóc sức khỏe. Hãy bắt đầu nào!
Link to this sectionMachine learning là gì?#
Machine learning cho phép máy móc học theo cách tương tự con người, sử dụng dữ liệu và các thuật toán để xác định các mẫu và đưa ra quyết định với sự hướng dẫn tối thiểu từ con người. Khi các hệ thống này tiếp xúc với dữ liệu theo thời gian, chúng dần đưa ra các dự đoán chính xác hơn.
Quy trình này hoạt động bằng cách sử dụng các thuật toán để đưa ra dự đoán hoặc classifications dựa trên dữ liệu đầu vào. Thuật toán trước tiên xác định các mẫu và đưa ra một phỏng đoán hoặc inference có cơ sở. Để đánh giá độ chính xác, một hàm lỗi sẽ so sánh output của model với các ví dụ đã biết, sau đó hệ thống điều chỉnh các parameters để giảm thiểu sai số. Chu kỳ đánh giá và điều chỉnh này tiếp tục tự động cho đến khi model đạt được mức performance mong muốn.
Nhìn chung có bốn loại machine learning: supervised, unsupervised, semi-supervised và reinforcement learning. Hãy cùng xem qua từng loại:
-
Supervised learning: Các thuật toán học từ dữ liệu được gán nhãn để dự đoán output cho các input mới. Các hệ thống lọc thư rác trên dịch vụ email sử dụng supervised learning.
-
Unsupervised learning: Khác với supervised learning, phương pháp này làm việc với dữ liệu không được gán nhãn. Thuật toán xác định các mẫu hoặc nhóm dữ liệu dựa trên sự tương đồng mà không cần hướng dẫn. Nó thường được sử dụng cho các tác vụ như phát hiện bất thường.
-
Semi-supervised learning: Phương pháp này kết hợp một lượng nhỏ dữ liệu được gán nhãn với một tập hợp lớn hơn dữ liệu chưa gán nhãn. Thuật toán học từ cả hai để cải thiện độ chính xác, giúp nó trở nên hữu ích khi dữ liệu được gán nhãn khan hiếm hoặc đắt đỏ.
-
Reinforcement learning: Ở đây, thuật toán học bằng cách tương tác với môi trường của nó và nhận phần thưởng hoặc hình phạt dựa trên hành động của mình. Nó tiếp tục cải thiện bằng cách nhắm tới việc tối đa hóa phần thưởng và thường được sử dụng trong các lĩnh vực như robot, trò chơi và xe tự lái.
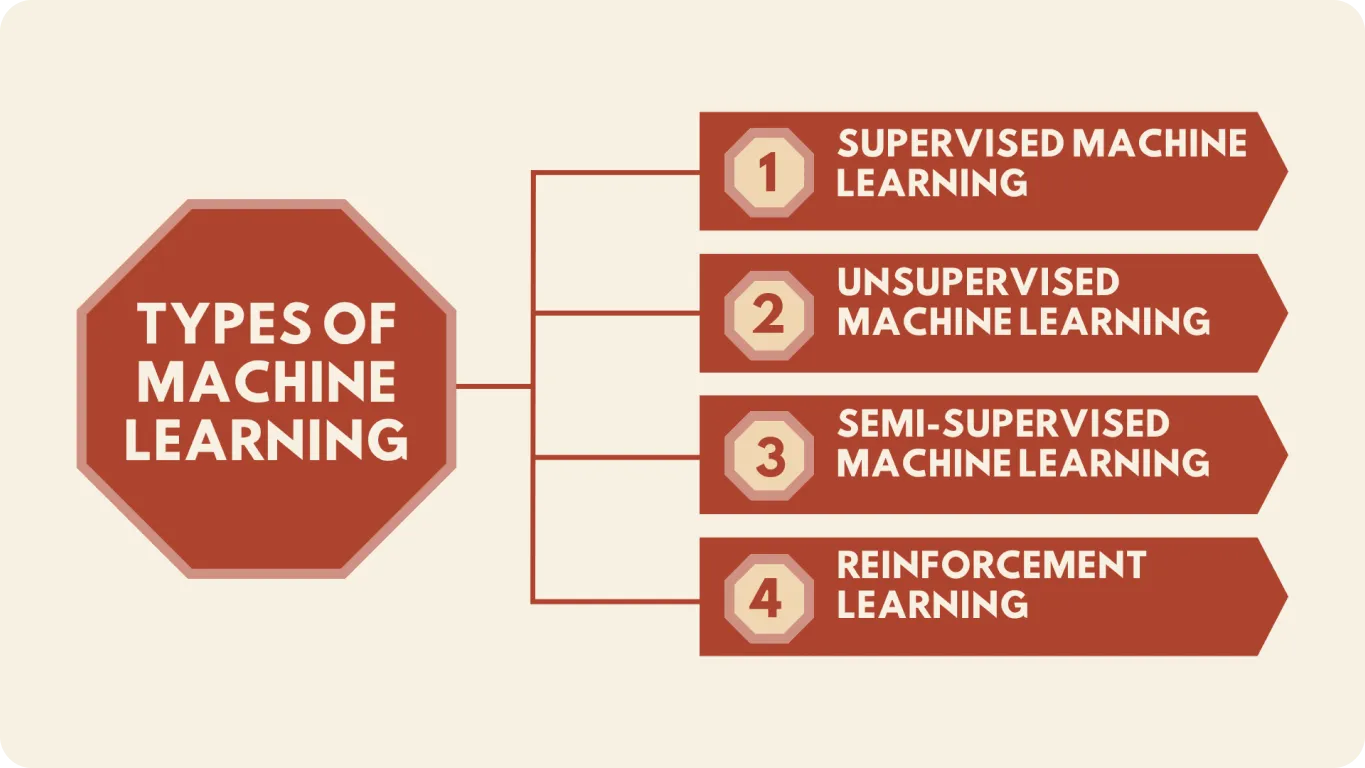
Hình 1. Các loại machine learning.
Link to this sectionData mining là gì?#
Data mining là quá trình khám phá và phân tích các datasets lớn để tìm ra các mẫu ẩn, xu hướng và thông tin chi tiết có giá trị không thể nhìn thấy ngay lập tức. Nó bao gồm việc chuyển đổi dữ liệu thô thành thông tin hữu ích bằng cách sử dụng kết hợp các kỹ thuật thống kê, machine learning và các công cụ quản lý cơ sở dữ liệu để xác định các mối liên hệ và mẫu trong dữ liệu.
Quá trình bắt đầu bằng việc thu thập dữ liệu từ các nguồn khác nhau, như cơ sở dữ liệu hoặc bảng tính, và tổ chức chúng thành một định dạng có cấu trúc. Sau đó, dữ liệu được làm sạch để loại bỏ bất kỳ lỗi, sự không nhất quán hoặc thông tin thiếu sót nào nhằm đảm bảo tính chính xác. Khi dữ liệu đã sẵn sàng, các thuật toán nâng cao và phương pháp thống kê sẽ được sử dụng để phân tích.
Dưới đây là một số kỹ thuật phổ biến nhất được sử dụng để phân tích dữ liệu:
- Classification: Phân nhóm dữ liệu vào các danh mục được xác định trước dựa trên các mẫu đã xác định.
- Clustering: Gom các điểm dữ liệu tương tự lại với nhau để xác định các nhóm tự nhiên trong dữ liệu.
- Association: Xác định mối quan hệ giữa các biến, chẳng hạn như tìm các mẫu các mặt hàng thường được mua cùng nhau.
Những kỹ thuật này giúp trích xuất các mẫu và thông tin chi tiết có ý nghĩa từ dữ liệu. Các kết quả sau đó được diễn giải và trình bày theo cách giúp chúng trở nên dễ hiểu và có thể thực thi, biến dữ liệu thô thành những hiểu biết có giá trị để giúp bạn đưa ra quyết định sáng suốt.
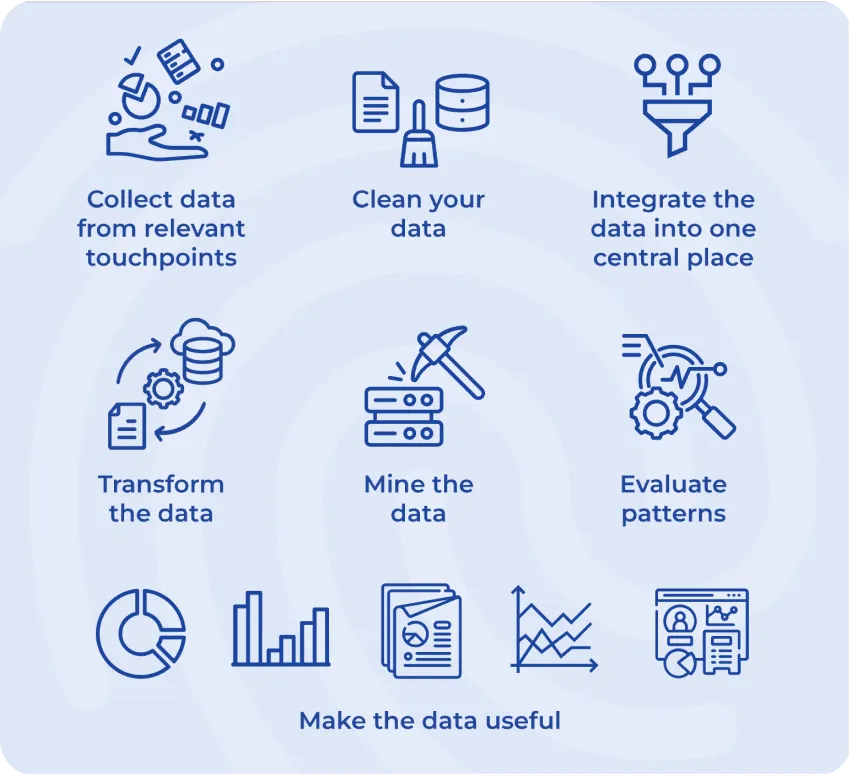
Hình 2. Các bước thực hiện data mining.
Link to this sectionTìm hiểu các ứng dụng của machine learning và data mining#
Có rất nhiều ứng dụng trong nhiều ngành công nghiệp mà tại đó machine learning và data mining có thể tạo ra sự khác biệt lớn. Để hiểu tác động của những công nghệ này, chúng ta sẽ lấy ngành bán lẻ làm ví dụ.
Machine learning có thể đặc biệt hữu ích cho các nhà bán lẻ dựa vào doanh số trực tuyến. Các doanh nghiệp lớn như eBay và Amazon đang sử dụng các công cụ machine learning tích hợp trên toàn bộ vòng đời bán hàng của họ. Một trong những cách chính mà các doanh nghiệp bán lẻ sử dụng nó là để khớp sản phẩm. Nó liên quan đến việc xác định và liên kết các mặt hàng giống hệt nhau trên các danh mục khác nhau, điều này hữu ích cho việc so sánh giá, tạo các trang sản phẩm hợp nhất và phát hiện các thiếu hụt sản phẩm. Trong khi việc khớp thủ công chỉ hiệu quả với các danh mục nhỏ, ML giúp xử lý các danh mục lớn hơn nhiều một cách hiệu quả. Nó cũng tạo điều kiện cho các loại khớp sản phẩm khác nhau, như khớp chính xác, khớp gần đúng, khớp hình ảnh, khớp thuộc tính, khớp danh mục và khớp liên miền.
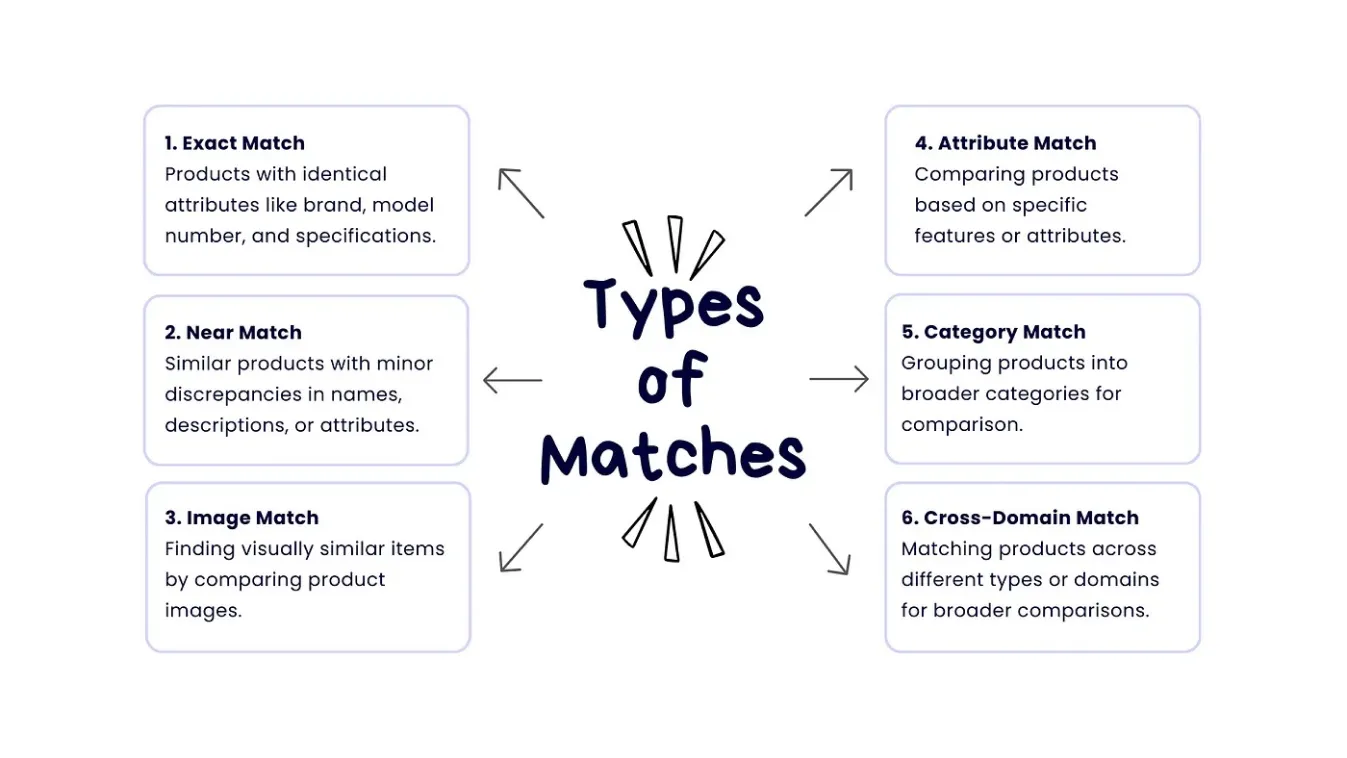
Hình 3. Các loại khớp sản phẩm.
Một ứng dụng thú vị của data mining trong bán lẻ là hiểu hành vi khách hàng, đặc biệt là thông qua phân khúc khách hàng. Khách hàng có thể được nhóm dựa trên các đặc điểm chung, như nhân khẩu học, mô hình mua sắm, lịch sử mua hàng trước đó, v.v. Các nhà bán lẻ có thể sử dụng các nhóm này để tạo ra các chiến lược tiếp thị mới nhằm tiếp cận khách hàng hiện tại và tương lai.
Nói về hành vi khách hàng, một trường hợp sử dụng quan trọng khác của data mining trong bán lẻ là phân tích tỷ lệ khách hàng rời bỏ (churn analysis), còn được gọi là sự suy giảm hoặc mất mát khách hàng. Các nhà bán lẻ có thể hiểu rõ hơn về loại khách hàng nào đang rời đi, tại sao họ rời đi và cách cải thiện tỷ lệ giữ chân. Mặc dù một mức độ rời bỏ nhất định là không thể tránh khỏi, nhưng việc xác định các mẫu thông qua data mining giúp các nhà bán lẻ có thể thực hiện các bước chủ động, như cung cấp các ưu đãi đặc biệt hoặc phiếu giảm giá để giảm thiểu sự mất mát khách hàng.
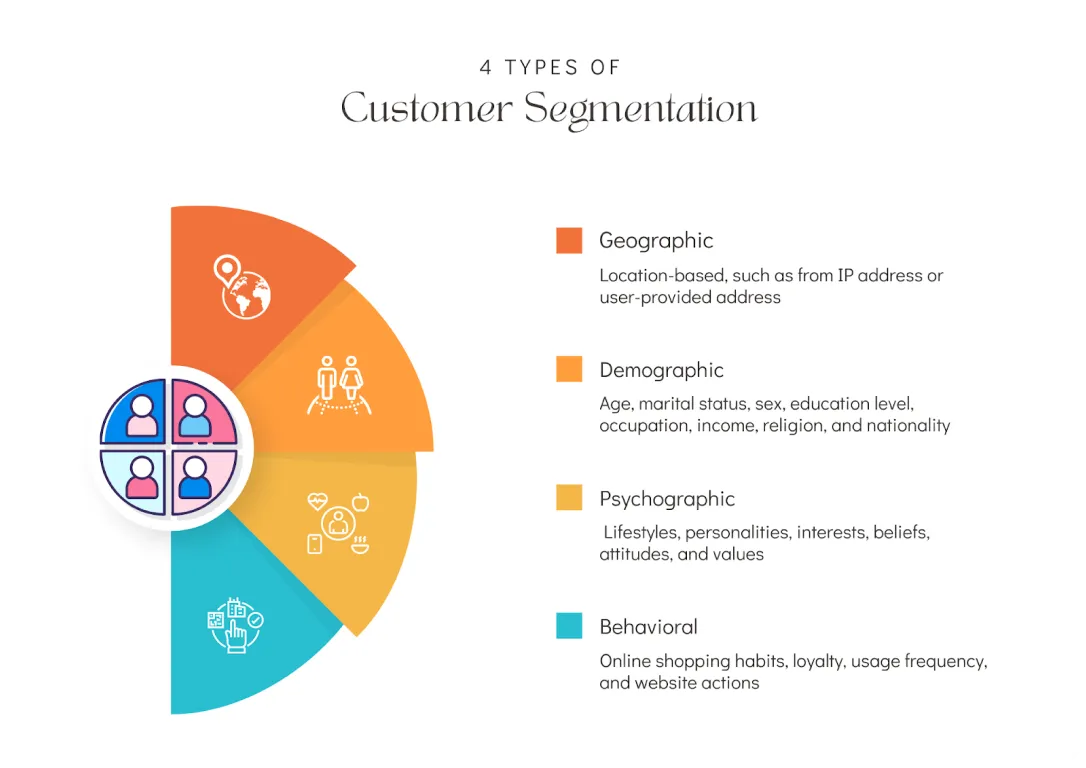
Hình 4. Phân khúc khách hàng.
Link to this sectionMối liên hệ giữa ML, data mining và computer vision#
Computer vision thực chất là một tập con của machine learning, tập trung vào việc dạy máy tính diễn giải dữ liệu hình ảnh từ hình ảnh và video. Trong khi đó, data mining có thể hỗ trợ các computer vision applications bằng cách phân tích lượng lớn dữ liệu thô để xác định những hình ảnh phù hợp nhất cho model training. Điều này rất quan trọng vì nó giúp đảm bảo rằng model học hỏi từ những ví dụ tốt nhất, cắt giảm dữ liệu không cần thiết và giúp nó tập trung vào những gì quan trọng. Kết quả là, data mining giúp các computer vision models hoạt động hiệu quả và chính xác hơn, cải thiện các tasks như object detection, image classification và instance segmentation.
Link to this sectionKhám phá các ứng dụng sử dụng ML, data mining và computer vision#
Để hiểu sự cộng hưởng của ML, data mining và computer vision, hãy cùng xem qua một ví dụ về ứng dụng trong lĩnh vực chăm sóc sức khỏe.
Machine learning, data mining và computer vision đang thúc đẩy những tiến bộ lớn trong chăm sóc sức khỏe. Các tổ chức y tế như Johns Hopkins Medicine tại Mỹ đang sử dụng các công nghệ này để phân tích medical images và phát hiện các bệnh tật cũng như bất thường như khối u từ sớm. Các computer vision models như Ultralytics YOLOv8 có thể được sử dụng để phân tích hình ảnh nhằm xác định bất kỳ điểm bất thường nào, trong khi machine learning có thể tìm thấy các mẫu trong hồ sơ bệnh nhân có thể chỉ ra các vấn đề sức khỏe tiềm ẩn. Sau đó, data mining có thể vào cuộc để tìm kiếm trong khối lượng lớn dữ liệu liên quan để giúp tìm ra các phương pháp điều trị hiệu quả hoặc các phương pháp chữa trị khả thi. Bằng cách kết hợp các công nghệ này, các chuyên gia chăm sóc sức khỏe có thể chẩn đoán tình trạng bệnh chính xác hơn và phát triển các kế hoạch điều trị tốt hơn, cuối cùng là cải thiện kết quả điều trị cho bệnh nhân.
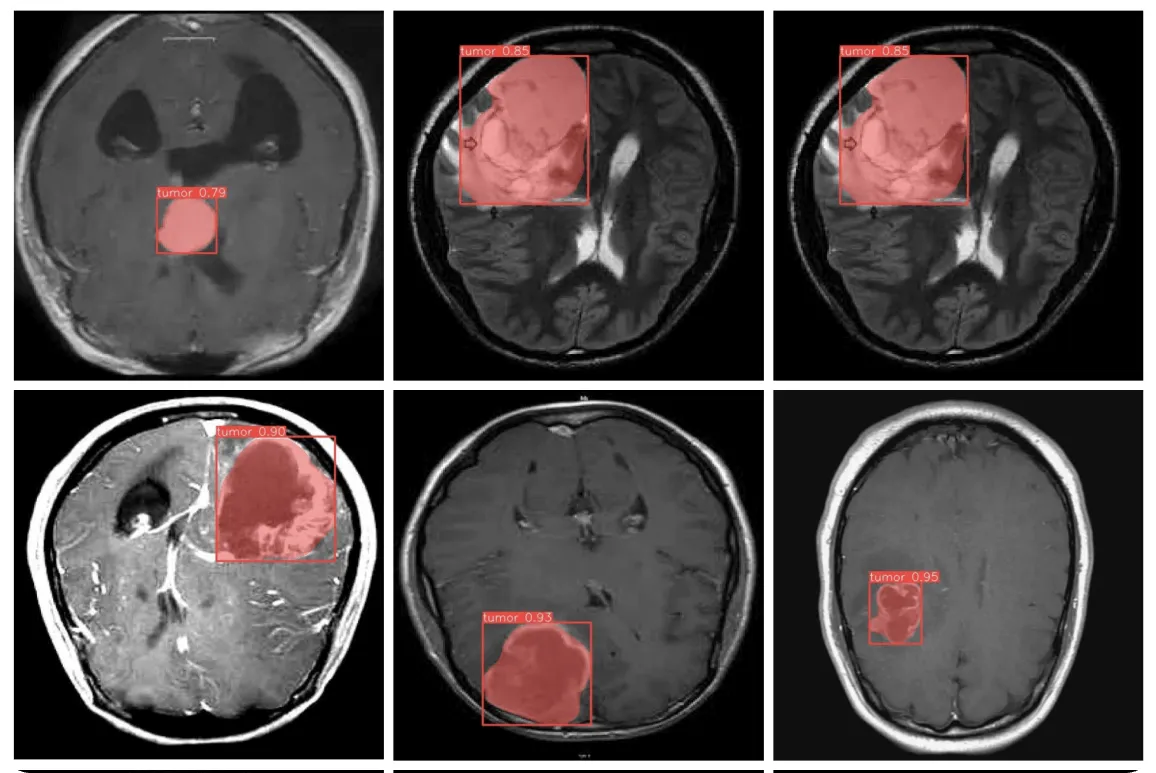
Hình 5. Sử dụng YOLOv8 để phát hiện khối u.
Link to this sectionThách thức và hướng đi trong tương lai#
Mặc dù các ứng dụng sử dụng computer vision, data mining và machine learning mang lại nhiều lợi ích, nhưng vẫn có một số hạn chế cần xem xét. Những đổi mới này thường cần khối lượng dữ liệu khổng lồ để hoạt động tốt, và quyền riêng tư dữ liệu có thể là một mối quan tâm. Ví dụ, các hệ thống computer vision trong các cửa hàng bán lẻ có thể thu thập và xử lý dữ liệu người tiêu dùng, và việc thông báo cho người tiêu dùng rằng dữ liệu của họ đang được thu thập là rất quan trọng.
Ngoài các vấn đề về quyền riêng tư dữ liệu, sự phức tạp của các computer vision models là một vấn đề khác. Có thể khó hiểu cách các model này đưa ra một kết quả đầu ra nhất định khi cố gắng đưa ra các quyết định sáng suốt. Bất chấp những thách thức này, ngày càng có nhiều biện pháp được áp dụng nhằm làm cho các AI solutions có trách nhiệm hơn và liền mạch hơn. Ví dụ, các kỹ thuật như federated learning đang trở nên phổ biến hơn vì chúng cho phép phát triển AI trong khi vẫn đảm bảo bảo vệ quyền riêng tư.
Federated learning là một phương pháp giúp các model học hỏi từ dữ liệu trong khi vẫn giữ dữ liệu ở vị trí ban đầu của nó. Thay vì tập hợp tất cả dữ liệu vào một cơ sở dữ liệu trung tâm, model được huấn luyện trực tiếp trên các thiết bị hoặc máy chủ cá nhân lưu giữ dữ liệu đó. Các thiết bị này sau đó chỉ gửi lại các bản cập nhật model thay vì dữ liệu thực tế. Các bản cập nhật model sau đó được tính đến để cải thiện model tổng thể.
Link to this sectionCác điểm chính cần lưu ý#
Cả machine learning và data mining đều đóng vai trò rất quan trọng trong computer vision. Chúng giúp phân tích khối lượng lớn dữ liệu hình ảnh, khám phá những hiểu biết quan trọng và cải thiện các lĩnh vực khác nhau như chăm sóc sức khỏe, mua sắm trực tuyến và xe tự lái. Mặc dù có những thách thức, chẳng hạn như bảo vệ quyền riêng tư và hiểu các model phức tạp, nhưng các phương pháp mới như federated learning đang giúp giải quyết các vấn đề này. Khi các công nghệ này tiếp tục phát triển, chúng có khả năng dẫn đến việc ra quyết định tốt hơn và nhiều đổi mới hơn trong nhiều lĩnh vực, giúp cuộc sống của chúng ta hiệu quả và kết nối hơn.
Bạn tò mò về AI? Hãy xem kho lưu trữ GitHub của chúng tôi để biết những đóng góp của chúng tôi cho AI, và đừng quên tham gia với cộng đồng của chúng tôi. Khám phá cách chúng tôi đang định nghĩa lại các ngành công nghiệp như sản xuất và chăm sóc sức khỏe bằng công nghệ AI tiên tiến.






