ما هو تحسين النماذج؟ دليل سريع
تعرف على كيفية مساعدة تقنيات تحسين النماذج مثل ضبط المعاملات الفائقة (hyperparameter tuning)، وتقليم النماذج (model pruning)، وتكميم النماذج (model quantization) في تشغيل نماذج الرؤية الحاسوبية بكفاءة أكبر.

تحسين النماذج هو عملية تهدف إلى تحسين كفاءة الأداء لنماذج تعلم الآلة. من خلال تنقيح بنية النموذج ووظيفته، يجعل التحسين من الممكن للنماذج تقديم نتائج أفضل بأقل موارد حوسبة وتقليل وقت التدريب والتقييم.
تعد هذه العملية مهمة بشكل خاص في مجالات مثل الرؤية الحاسوبية، حيث تتطلب النماذج غالبًا موارد كبيرة لتحليل الصور المعقدة. في البيئات المحدودة الموارد مثل الأجهزة المحمولة أو أنظمة الحوسبة الطرفية، يمكن للنماذج المحسنة أن تعمل بشكل جيد مع موارد محدودة مع الحفاظ على دقتها.
تُستخدم العديد من التقنيات بشكل شائع لتحقيق تحسين النماذج، بما في ذلك ضبط المعلمات الفائقة، وتقليم النماذج، وتكميم النماذج، والدقة المختلطة. في هذه المقالة، سوف نستكشف هذه التقنيات والفوائد التي تقدمها لـ تطبيقات الرؤية الحاسوبية. لنبدأ!
Link to this sectionفهم تحسين النماذج#
تحتوي نماذج الرؤية الحاسوبية عادةً على طبقات عميقة وهياكل معقدة رائعة للتعرف على الأنماط المعقدة في الصور، ولكنها قد تكون أيضًا متطلبة للغاية من حيث قوة المعالجة. عندما يتم نشر هذه النماذج على أجهزة ذات أجهزة محدودة، مثل الهواتف المحمولة أو الأجهزة الطرفية، فقد تواجه تحديات أو قيودًا معينة.
يمكن أن تؤدي قوة المعالجة والذاكرة والطاقة المحدودة في هذه الأجهزة إلى انخفاض ملحوظ في الأداء، حيث تكافح النماذج لمواكبة العمل. تعد تقنيات تحسين النماذج مفتاحًا لمعالجة هذه المخاوف. فهي تساعد في تبسيط النموذج، وتقليل احتياجاته الحوسبية، وضمان استمرارية عمله بفعالية حتى مع موارد محدودة. يمكن إجراء تحسين النموذج عن طريق تبسيط هندسة النموذج، أو تقليل دقة الحسابات، أو إزالة المكونات غير الضرورية لجعل النموذج أخف وأسرع.
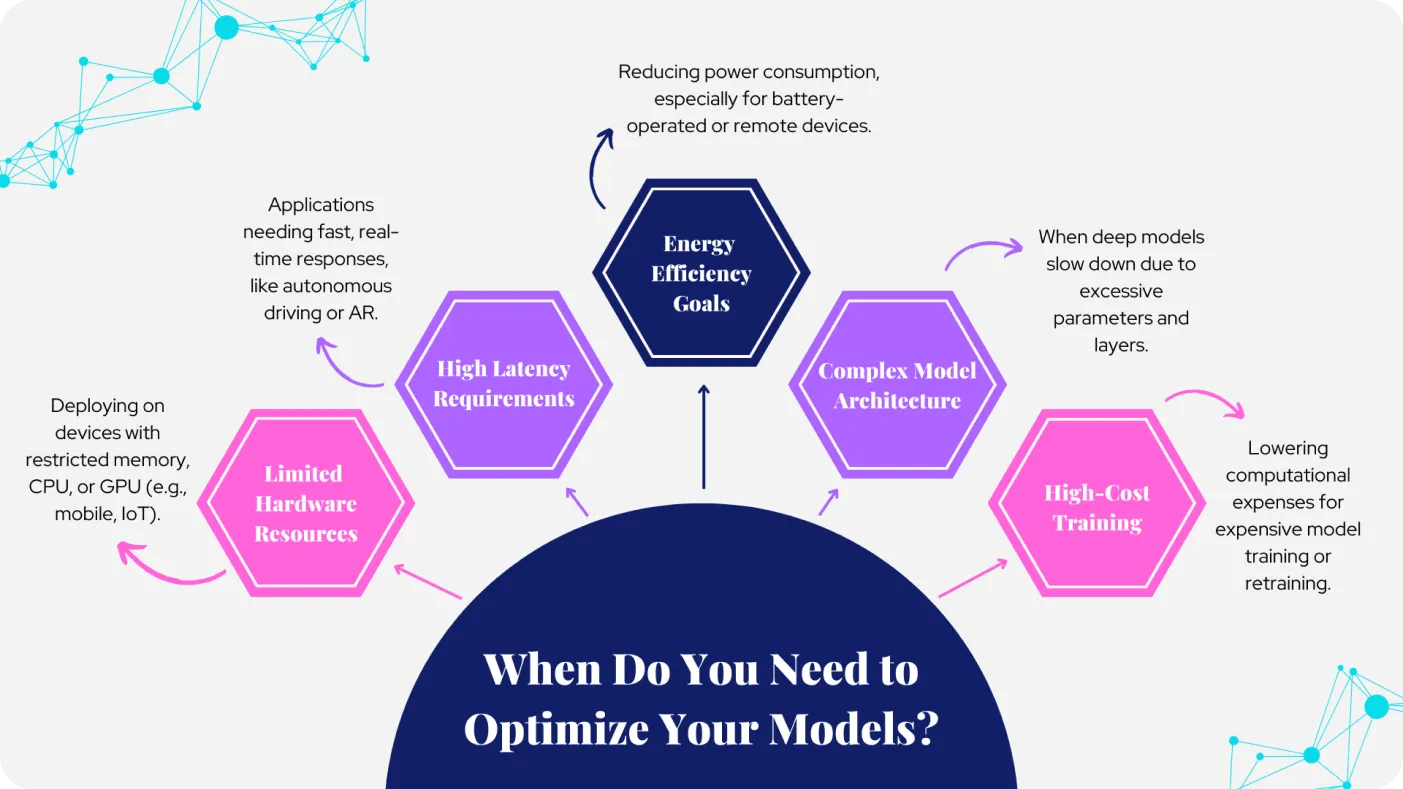
الشكل 1. أسباب تحسين نماذجك. الصورة من تأليف الكاتب.
فيما يلي بعض تقنيات التحسين الأكثر شيوعًا للنماذج، والتي سنستكشفها بمزيد من التفصيل في الأقسام التالية:
- ضبط المعلمات الفائقة: يتضمن ذلك ضبط المعلمات الفائقة بشكل منهجي، مثل معدل التعلم وحجم الدفعة، لتحسين أداء النموذج.
- تقليم النموذج: تعمل هذه التقنية على إزالة الأوزان والوصلات غير الضرورية من الشبكة العصبية، مما يقلل من تعقيدها وتكلفتها الحوسبية.
- تكميم النموذج: يتضمن التكميم تقليل دقة أوزان النموذج وتنشيطاته، عادةً من 32 بت إلى 16 بت أو 8 بت، مما يقلل بشكل كبير من البصمة الذاكرية والمتطلبات الحوسبية.
- تعديلات الدقة: تُعرف أيضًا بالتدريب ذي الدقة المختلطة، وتتضمن استخدام تنسيقات دقة مختلفة لأجزاء مختلفة من النموذج وتحسين استخدام الموارد دون المساس بالدقة.
Link to this sectionشرح: المعلمات الفائقة في نماذج تعلم الآلة#
يمكنك مساعدة النموذج على التعلم والأداء بشكل أفضل من خلال ضبط معلماته الفائقة - وهي إعدادات تشكل كيفية تعلم النموذج من البيانات. ضبط المعلمات الفائقة هو تقنية لتحسين هذه الإعدادات، مما يعزز كفاءة النموذج ودقة نتائجه. على عكس المعلمات التي يتعلمها النموذج أثناء التدريب، فإن المعلمات الفائقة هي قيم مضبوطة مسبقًا توجه عملية التدريب.
دعنا نستعرض بعض الأمثلة للمعلمات الفائقة التي يمكن ضبطها:
- معدل التعلم: يتحكم هذا المعامل في حجم الخطوة التي يتخذها النموذج لضبط أوزانه الداخلية. يمكن أن يؤدي معدل التعلم الأعلى إلى تسريع التعلم ولكنه يخاطر بفقدان الحل الأمثل، بينما قد يكون المعدل الأقل أكثر دقة ولكنه أبطأ.
- حجم الدفعة: يحدد عدد عينات البيانات التي تتم معالجتها في كل خطوة تدريب. توفر أحجام الدفعات الأكبر تعلمًا أكثر استقرارًا ولكنها تحتاج إلى مزيد من الذاكرة. التدريب بدفعات أصغر يكون أسرع ولكنه قد يكون أقل استقرارًا.
- الحقبات (Epochs): يمكنك تحديد عدد المرات التي يرى فيها النموذج مجموعة البيانات الكاملة باستخدام هذا المعامل. يمكن أن تؤدي زيادة عدد الحقبات إلى تحسين الدقة ولكنها تخاطر بـ الإفراط في التخصيص.
- حجم النواة (Kernel size): يحدد حجم المرشح في الشبكات العصبية التلافيفية (CNNs). تلتقط النوى الأكبر أنماطًا أوسع ولكنها تحتاج إلى مزيد من المعالجة؛ بينما تركز النوى الأصغر على التفاصيل الدقيقة.
Link to this sectionكيف يعمل ضبط المعلمات الفائقة#
يبدأ ضبط المعاملات الفائقة (Hyperparameter tuning) عادةً بتحديد نطاق من القيم الممكنة لكل معامل فائق. ثم تقوم خوارزمية بحث باستكشاف مجموعات مختلفة ضمن هذه النطاقات لتحديد الإعدادات التي تنتج أفضل أداء.
تشمل طرق الضبط الشائعة البحث الشبكي، والبحث العشوائي، والتحسين البايزي. يختبر البحث الشبكي كل مجموعة ممكنة من القيم ضمن النطاقات المحددة. يختار البحث العشوائي المجموعات بشكل عشوائي، وغالبًا ما يجد إعدادات فعالة بسرعة أكبر. يستخدم التحسين البايزي نموذجًا احتماليًا للتنبؤ بقيم المعلمات الفائقة الواعدة بناءً على النتائج السابقة. عادةً ما يقلل هذا النهج من عدد التجارب المطلوبة.
في النهاية، يتم تقييم أداء النموذج لكل مجموعة من المعلمات الفائقة. وتُكرر العملية حتى يتم تحقيق النتائج المرجوة.
Link to this sectionالمعلمات الفائقة مقابل معلمات النموذج#
أثناء العمل على ضبط المعلمات الفائقة، قد تتساءل عن الفرق بين المعلمات الفائقة ومعلمات النموذج.
المعلمات الفائقة هي قيم يتم تعيينها قبل التدريب وتتحكم في كيفية تعلم النموذج، مثل معدل التعلم أو حجم الدفعة. هذه الإعدادات ثابتة أثناء التدريب وتؤثر بشكل مباشر على عملية التعلم. من ناحية أخرى، يتم تعلم معلمات النموذج بواسطة النموذج نفسه أثناء التدريب. وتشمل هذه الأوزان والتحيزات، التي يتم ضبطها مع تدريب النموذج وتوجه في النهاية تنبؤاته. باختصار، تشكل المعلمات الفائقة رحلة التعلم، بينما تعد معلمات النموذج هي نتائج عملية التعلم تلك.
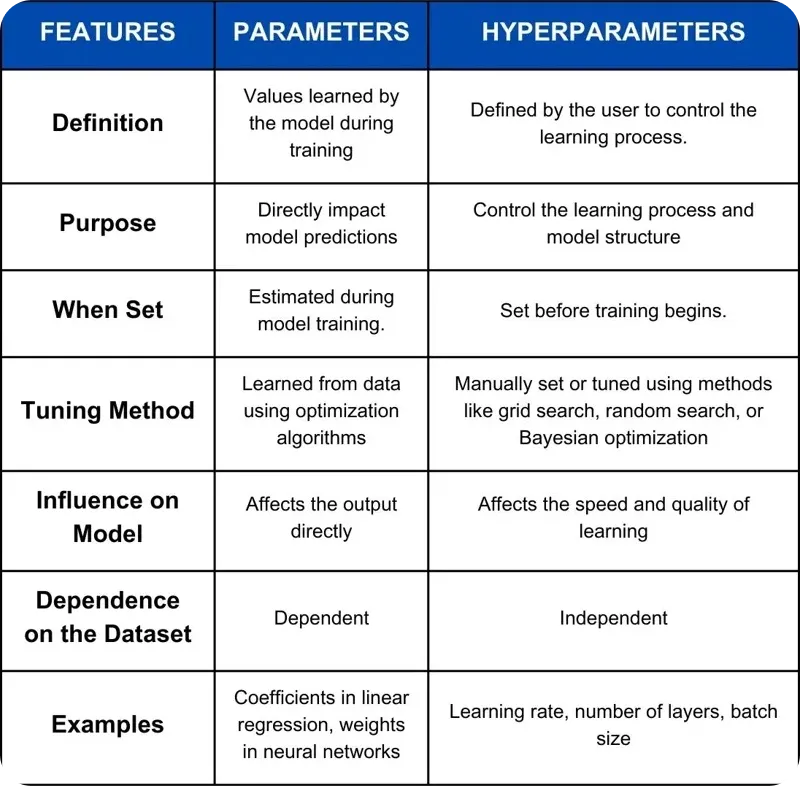
الشكل 2. مقارنة بين المعلمات والمعلمات الفائقة.
Link to this sectionلماذا يعد تقليم النموذج مهمًا في التعلم العميق#
تقليم النموذج هو تقنية لتقليل الحجم تعمل على إزالة الأوزان والمعلمات غير الضرورية من النموذج، مما يجعله أكثر كفاءة. في الرؤية الحاسوبية، خاصة مع الشبكات العصبية العميقة، يمكن أن يؤدي العدد الكبير من المعلمات، مثل الأوزان والتنشيطات (المخرجات الوسيطة التي تساعد في حساب المخرج النهائي)، إلى زيادة التعقيد والمطالب الحوسبية. يساعد التقليم في تبسيط النموذج من خلال تحديد وإزالة المعلمات التي تساهم بشكل ضئيل في الأداء، مما ينتج عنه نموذج أخف وأكثر كفاءة.
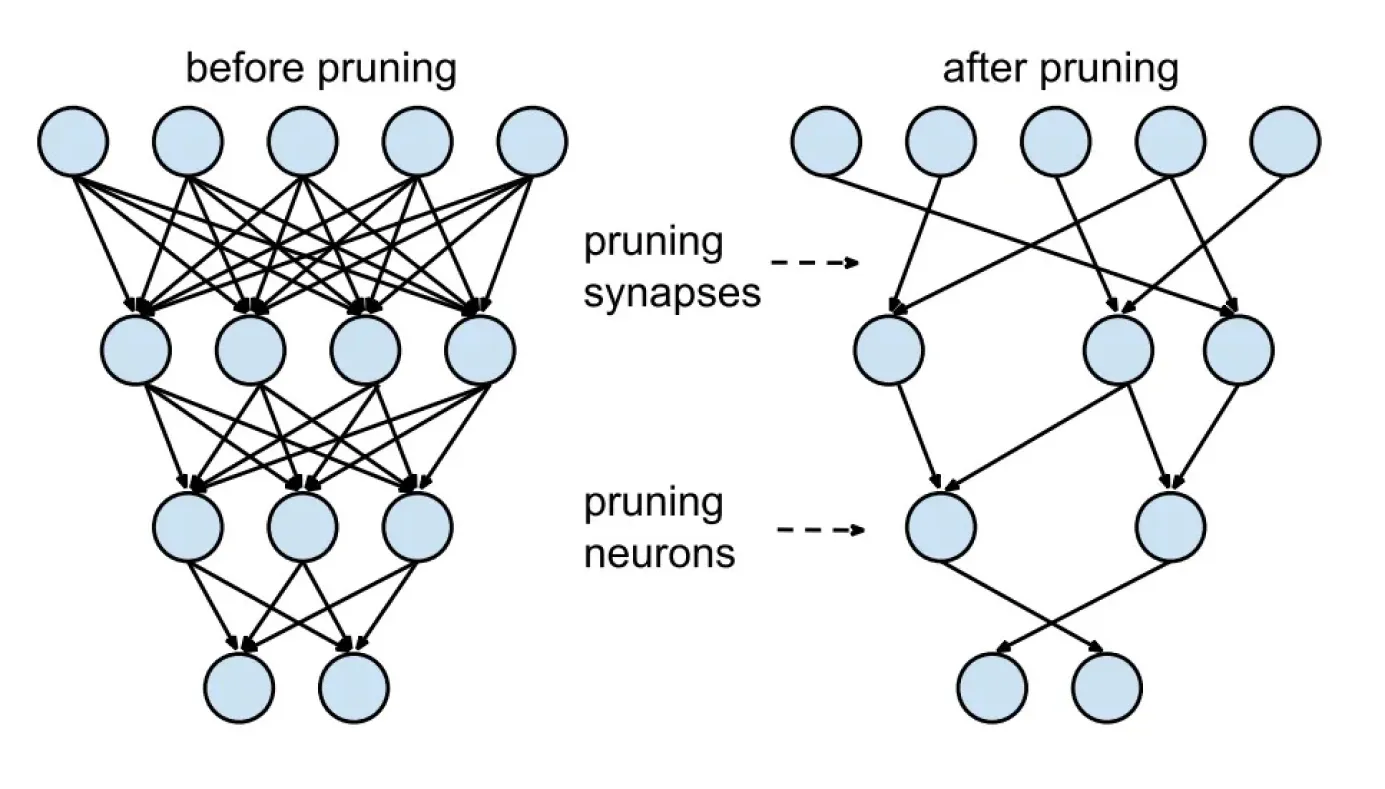
الشكل 3. قبل وبعد تقليم النموذج.
بعد تدريب النموذج، يمكن لتقنيات مثل التقليم القائم على الحجم أو تحليل الحساسية تقييم أهمية كل معلمة. يتم بعد ذلك تقليم المعلمات ذات الأهمية المنخفضة باستخدام واحدة من ثلاث تقنيات رئيسية: تقليم الأوزان، أو تقليم الخلايا العصبية، أو التقليم الهيكلي.
يزيل تقليم الأوزان الروابط الفردية ذات التأثير الأدنى على المخرج. يزيل تقليم الخلايا العصبية خلايا عصبية كاملة تساهم مخرجاتها بشكل ضئيل في وظيفة النموذج. يقضي التقليم الهيكلي على أقسام أكبر، مثل المرشحات التلافيفية أو الخلايا العصبية في الطبقات المتصلة بالكامل، مما يحسن كفاءة النموذج. بمجرد اكتمال التقليم، يتم إعادة تدريب النموذج لـ ضبط المعلمات المتبقية، مما يضمن احتفاظه بدقة عالية في شكل مصغر.
Link to this sectionتقليل زمن الاستجابة في نماذج الذكاء الاصطناعي بالتكميم#
تكميم النموذج يقلل من عدد البتات المستخدمة لتمثيل أوزان النموذج وتنشيطاته. وعادةً ما يحول قيم الفاصلة العائمة عالية الدقة 32 بت إلى دقة أقل، مثل أعداد صحيحة 16 بت أو 8 بت. من خلال تقليل دقة البت، يقلل التكميم بشكل كبير من حجم النموذج، والبصمة الذاكرية، والتكلفة الحوسبية.
في الرؤية الحاسوبية، تعتبر الفواصل العائمة 32 بت معيارية، ولكن التحويل إلى 16 بت أو 8 بت يمكن أن يحسن الكفاءة. هناك نوعان رئيسيان من التكميم: تكميم الأوزان وتكميم التنشيطات. يعمل تكميم الأوزان على خفض دقة أوزان النموذج، مما يوازن بين تقليل الحجم والدقة. يقلل تكميم التنشيطات من دقة التنشيطات، مما يقلل بشكل أكبر من متطلبات الذاكرة والحوسبة.
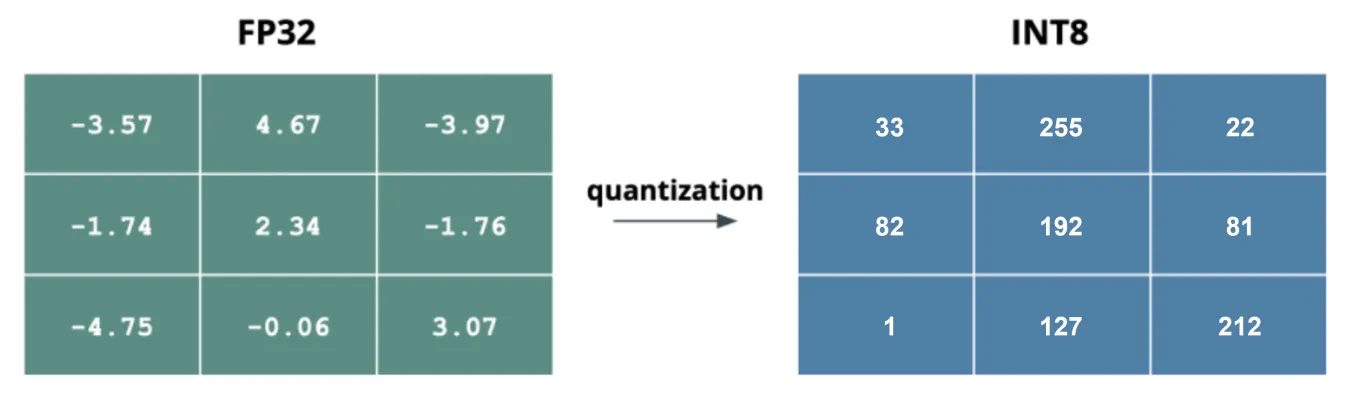
الشكل 4. مثال على التكميم من فاصلة عائمة 32 بت إلى عدد صحيح 8 بت.
Link to this sectionكيف تسرع الدقة المختلطة استنتاجات الذكاء الاصطناعي#
الدقة المختلطة هي تقنية تستخدم دقات عددية مختلفة لأجزاء متنوعة من الشبكة العصبية. من خلال الجمع بين قيم دقة أعلى، مثل الفواصل العائمة 32 بت، مع قيم دقة أقل، مثل الفواصل العائمة 16 بت أو 8 بت، تجعل الدقة المختلطة من الممكن لـ نماذج الرؤية الحاسوبية تسريع التدريب وتقليل استخدام الذاكرة دون التضحية بالدقة.
أثناء التدريب، يتم تحقيق الدقة المختلطة باستخدام دقة أقل في طبقات معينة مع الحفاظ على دقة أعلى حيثما لزم الأمر عبر الشبكة. يتم ذلك من خلال التحويل وتوسيع نطاق الخسارة. يقوم التحويل بتحويل أنواع البيانات بين دقات مختلفة حسب متطلبات النموذج. يعدل توسيع نطاق الخسارة الدقة المنخفضة لمنع التلاشي العددي، مما يضمن تدريبًا مستقرًا. تعد الدقة المختلطة مفيدة بشكل خاص للنماذج الكبيرة وأحجام الدفعات الكبيرة.
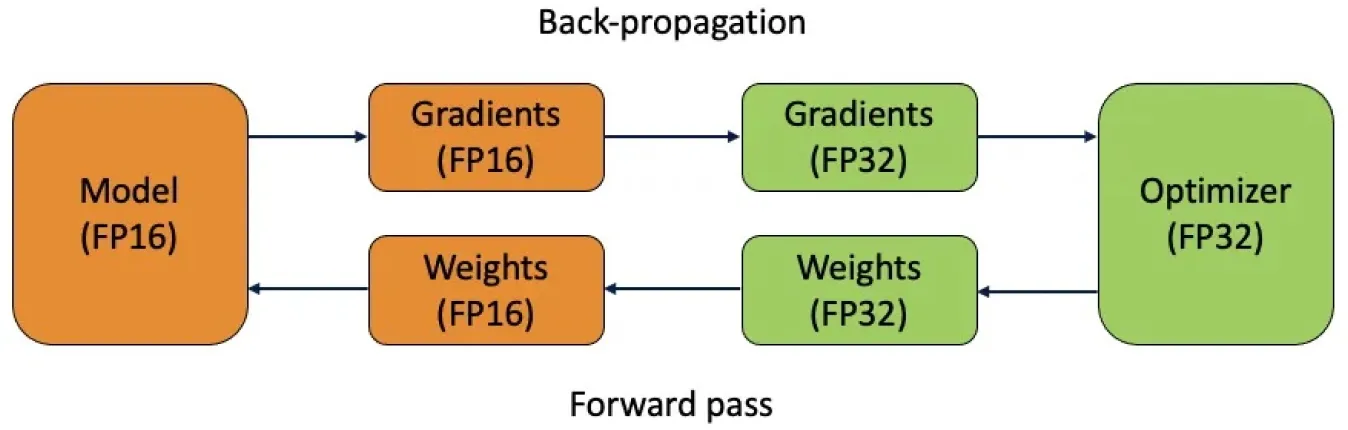
الشكل 5. يستخدم التدريب بالدقة المختلطة كلاً من أنواع الفاصلة العائمة 16 بت (FP16) و32 بت (FP32).
Link to this sectionالموازنة بين دقة النموذج وكفاءته#
الآن بعد أن غطينا العديد من تقنيات تحسين النماذج، دعنا نناقش كيفية تحديد التقنية التي يجب استخدامها بناءً على احتياجاتك المحددة. يعتمد الاختيار على عوامل مثل الأجهزة المتاحة، وقيود الحوسبة والذاكرة لـ بيئة النشر، ومستوى الدقة المطلوب.
على سبيل المثال، النماذج الأصغر والأسرع أكثر ملاءمة للأجهزة المحمولة ذات الموارد المحدودة، بينما يمكن استخدام النماذج الأكبر والأكثر دقة على الأنظمة عالية الأداء. إليك كيفية توافق كل تقنية مع الأهداف المختلفة:
- التقليم: مثالي لتقليل حجم النموذج دون التأثير بشكل كبير على الدقة، مما يجعله مثاليًا للأجهزة محدودة الموارد مثل الهواتف المحمولة أو أجهزة إنترنت الأشياء (IoT).
- التكميم: خيار رائع لتقليص حجم النموذج وتسريع الاستنتاج، خاصة على الأجهزة المحمولة والأنظمة المضمنة ذات الذاكرة وقوة المعالجة المحدودتين. يعمل بشكل جيد للتطبيقات التي تكون فيها انخفاضات الدقة الطفيفة مقبولة.
- الدقة المختلطة: مصممة للنماذج واسعة النطاق، تقلل هذه التقنية من استخدام الذاكرة وتسرع التدريب على أجهزة مثل وحدات معالجة الرسومات (GPUs) ووحدات معالجة التنسور (TPUs) التي تدعم عمليات الدقة المختلطة. غالبًا ما تُستخدم في المهام عالية الأداء حيث تكون الكفاءة مهمة.
- ضبط المعلمات الفائقة: على الرغم من أنها كثيفة الاستخدام للموارد الحوسبية، إلا أنها ضرورية للتطبيقات التي تتطلب دقة عالية، مثل التصوير الطبي أو القيادة الذاتية.
Link to this sectionأبرز النقاط#
يعد تحسين النموذج جزءًا حيويًا من تعلم الآلة، خاصة لنشر الذكاء الاصطناعي في تطبيقات العالم الحقيقي. تساعد تقنيات مثل ضبط المعلمات الفائقة، وتقليم النماذج، والتكميم، والدقة المختلطة في تحسين أداء وكفاءة واستخدام موارد نماذج الرؤية الحاسوبية. تجعل هذه التحسينات النماذج أسرع وأقل استهلاكًا للموارد، وهو أمر مثالي للأجهزة ذات الذاكرة وقوة المعالجة المحدودتين. النماذج المحسنة أسهل أيضًا في التوسع والنشر عبر منصات مختلفة، مما يتيح حلول ذكاء اصطناعي فعالة وقابلة للتكيف مع مجموعة واسعة من الاستخدامات.
تفضل بزيارة مستودع GitHub الخاص بـ Ultralytics وانضم إلى مجتمعنا لمعرفة المزيد عن تطبيقات الذكاء الاصطناعي في التصنيع والزراعة.






