L'impact de la conception plus rapide et orientée périphérie d'Ultralytics YOLO26
Vois comment Ultralytics YOLO26 est plus rapide en périphérie et pourquoi cela compte pour les applications de vision par ordinateur de nouvelle génération qui exigent une faible latence et de l'efficacité.
Plus tôt cette semaine, Ultralytics a officiellement lancé Ultralytics YOLO26, un modèle YOLO plus rapide, plus léger et plus petit qui vise à redéfinir les performances des systèmes de vision par ordinateur à l'edge. YOLO26 prend en charge les mêmes tâches de vision principales que les modèles YOLO précédents, notamment la détection d'objets et la segmentation d'instances.

Fig 1. Un exemple d'utilisation de YOLO26 pour segmenter un objet.
La différence fondamentale entre YOLO26 et les modèles précédents réside dans l'environnement pour lequel il a été conçu. Plutôt que d'optimiser principalement pour les unités de traitement graphique (GPU) dans le cloud ou pour des performances basées sur des benchmarks, YOLO26 a été conçu dès le départ pour un déploiement réel sur des appareils en périphérie (edge) et du matériel embarqué.
À mesure que la vision par ordinateur passe de la recherche à la production, la réalité des contraintes de performance devient plus claire. Les environnements edge sont façonnés par des budgets de latence serrés, une mémoire limitée, des contraintes énergétiques et thermiques, ainsi que par le besoin d'un comportement prévisible sur diverses plateformes.
Dans ces configurations, la performance globale du système ne dépend pas seulement de la vitesse d'inférence brute, mais aussi de l'efficacité avec laquelle fonctionne tout le pipeline. Les frais généraux de post-traitement, la pression sur la mémoire et les chemins d'exécution spécifiques à la plateforme constituent souvent des goulots d'étranglement.
YOLO26 répond à ces défis en adoptant une approche plus rapide et axée sur l'edge qui examine l'ensemble du pipeline d'inférence plutôt que les métriques individuelles du modèle. En se concentrant sur l'optimisation edge, la simplification du pipeline d'inférence et la suppression des étapes de post-traitement inutiles, YOLO26 offre des améliorations de vitesse qui se traduisent par une latence plus faible et un comportement plus fiable en production.
Dans cet article, nous explorerons comment les choix architecturaux de YOLO26 se traduisent par des améliorations de performance concrètes, et pourquoi être plus rapide à l'edge change fondamentalement ce qui est possible pour les applications de vision par ordinateur de nouvelle génération.
Link to this sectionLa réalité du déploiement à l'edge#
Exécuter des modèles de vision par ordinateur à l'edge est très différent de les exécuter dans le cloud. Dans les environnements cloud, les systèmes ont généralement accès à des GPU puissants, à de grandes quantités de mémoire et à du matériel stable. À l'edge, les mêmes hypothèses ne s'appliquent pas.
La plupart des déploiements edge s'exécutent sur des architectures matérielles diverses, et non sur des GPU. Les appareils utilisent généralement plusieurs processeurs spécialisés pour différentes tâches, qui sont optimisés pour l'efficacité et une faible consommation d'énergie plutôt que pour la capacité de calcul brute des GPU cloud.
La latence est une autre contrainte majeure. Les systèmes edge fonctionnent souvent sous des limites strictes de temps réel, où même de petits retards peuvent affecter la réactivité ou la sécurité. Dans ces cas, la latence de bout en bout compte plus que la vitesse d'inférence brute. Un modèle peut être rapide sur le papier mais échouer une fois que le post-traitement et le mouvement des données sont ajoutés.
La mémoire joue également un rôle important. De nombreux appareils edge ont une mémoire limitée et des caches partagés. Les grands tenseurs intermédiaires et une utilisation inefficace de la mémoire peuvent ralentir les systèmes, même lorsque le modèle lui-même est efficace.
Les limites de puissance et thermiques ajoutent des contraintes supplémentaires. Les appareils edge fonctionnent souvent sans refroidissement actif et dans le cadre de budgets énergétiques fixes. La performance doit être efficace et durable, et pas seulement rapide par brefs instants.
En plus de tout cela, les déploiements edge nécessitent de la cohérence. Les modèles doivent se comporter de la même manière sur différents appareils et runtimes. Le code spécifique à la plateforme ou les étapes de post-traitement complexes peuvent introduire des différences subtiles qui rendent les systèmes plus difficiles à déployer et à maintenir.
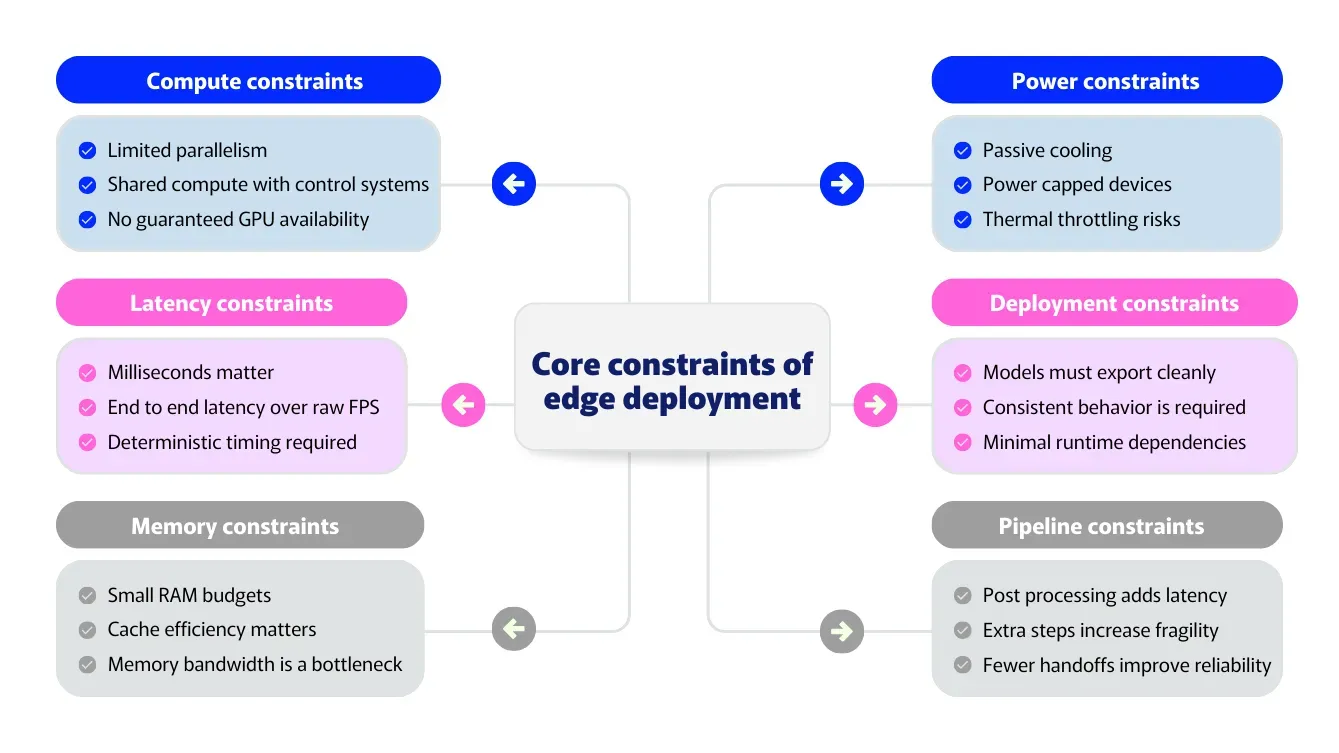
Fig 2. Un aperçu des contraintes du déploiement à l'edge. Image de l'auteur.
Ces contraintes définissent ce que signifie réellement la performance à l'edge. En d'autres termes, la performance est définie par l'ensemble du pipeline, et non par une seule métrique.
Link to this sectionPourquoi la vision à l'edge exige un modèle de performance différent#
Alors, comment les contraintes du déploiement edge sont-elles liées aux exigences d'un modèle de vision par ordinateur conçu pour l'edge ? Le lien devient clair une fois que les modèles passent des environnements de recherche aux systèmes réels.
Dans les environnements cloud, la performance est souvent mesurée à l'aide de benchmarks tels que la vitesse d'inférence et la précision. À l'edge, ces métriques ne racontent qu'une partie de l'histoire. Les systèmes de vision fonctionnent généralement sur du matériel hétérogène, où l'inférence du réseau neuronal est déléguée à des accélérateurs spécialisés tandis que d'autres parties du pipeline s'exécutent sur des processeurs à usage général.
Dans ce contexte, la vitesse du modèle ne suffit pas. La manière dont le système entier fonctionne une fois que le modèle est déployé est essentielle. Un modèle peut sembler rapide seul, mais échouer si le post-traitement, le mouvement des données ou les étapes spécifiques à la plateforme ajoutent des surcharges.
C'est pourquoi la vision à l'edge nécessite un modèle de performance qui se concentre sur l'efficacité au niveau du système plutôt que sur des benchmarks isolés. YOLO26 reflète ce changement en se concentrant sur l'optimisation edge, l'inférence rationalisée et l'exécution de bout en bout conçue pour un déploiement réel.
Link to this sectionLa base de la vitesse : une conception axée sur l'edge#
À l'edge, la performance est définie par la manière dont un modèle s'adapte à l'architecture matérielle réelle de l'appareil. Concevoir pour l'edge dès le départ garantit que les systèmes de vision fonctionnent de manière fiable sur des plateformes réelles, quelle que soit la combinaison spécifique d'unités de traitement disponibles.
Une approche axée sur l'edge donne la priorité à une exécution prévisible et efficace sur du matériel hétérogène, plutôt que d'adapter des modèles optimisés pour les GPU cloud a posteriori. En clair, cela signifie privilégier les opérations qui se traduisent bien sur les accélérateurs de réseaux neuronaux, minimiser le travail non neuronal en dehors du modèle et réduire la complexité inutile qui peut ralentir l'exécution de bout en bout.
YOLO26 a été conçu avec ces contraintes à l'esprit. Son architecture se concentre sur une performance constante plutôt que sur un débit de pointe dans des conditions idéales. En simplifiant les chemins d'exécution et en éliminant les calculs inutiles, YOLO26 réduit la surcharge sur tout le pipeline d'inférence et utilise mieux l'accélération disponible et la hiérarchie mémoire de l'appareil.
Cette approche améliore également la fiabilité. L'optimisation axée sur l'edge conduit à un timing plus prévisible et à moins de pics de performance, ce qui est crucial pour les systèmes en temps réel. Au lieu de s'appuyer sur du matériel spécialisé ou un post-traitement lourd pour atteindre la vitesse, YOLO26 met l'accent sur l'efficacité tout au long du pipeline d'inférence.
Link to this sectionInférence de bout en bout et le coût du post-traitement#
Tu te demandes peut-être ce que signifie éliminer les étapes de post-traitement inutiles. Pour comprendre cela, prenons du recul et examinons comment fonctionnent les systèmes de détection d'objets traditionnels.
Dans de nombreux pipelines de détection d'objets, l'inférence ne s'arrête pas lorsque le modèle produit ses prédictions. Au lieu de cela, le modèle génère un grand nombre de boîtes englobantes qui se chevauchent, qui doivent ensuite être filtrées et affinées avant de pouvoir être utilisées. Ce nettoyage se produit via des étapes de post-traitement qui s'exécutent en dehors du modèle lui-même.
L'une des étapes de post-traitement les plus courantes est la Non-Maximum Suppression, ou NMS. La NMS compare les boîtes englobantes qui se chevauchent et ne conserve que les détections les plus fiables, supprimant les doublons qui font référence au même objet. Bien que cette approche soit efficace, elle introduit des calculs supplémentaires une fois l'inférence terminée.
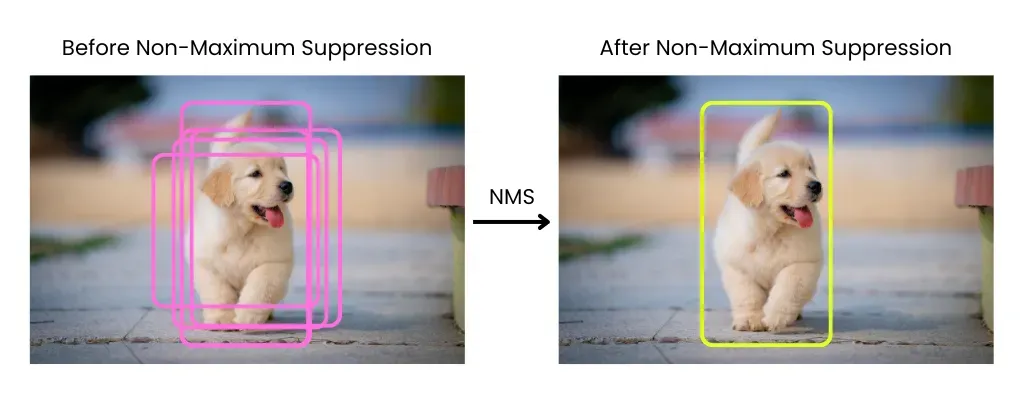
Fig 3. Comprendre la NMS. Image de l'auteur.
À l'edge, ce travail supplémentaire a un coût. Les étapes de post-traitement comme la NMS ne sont pas bien adaptées aux accélérateurs spécialisés utilisés pour l'inférence de réseaux neuronaux, qui sont optimisés pour le calcul neuronal dense plutôt que pour des opérations lourdes en contrôle ou intensives en mémoire.
En conséquence, la NMS introduit une latence et une surcharge mémoire supplémentaires, et son coût augmente à mesure que le nombre de détections augmente. Même lorsque le modèle lui-même est rapide, la NMS peut toujours consommer une part importante du temps d'exécution total.
Le post-traitement augmente également la complexité du système. Comme il vit en dehors du modèle, il doit être implémenté séparément pour différents runtimes et cibles matérielles. Cela conduit souvent à des chemins de code spécifiques à la plateforme, à un comportement incohérent entre les appareils et à des pipelines de déploiement plus fragiles.
Plus important encore, le post-traitement brise l'idée d'une véritable performance de bout en bout. Mesurer la vitesse d'inférence du modèle ne reflète pas la façon dont le système se comporte en production. Ce qui compte en fin de compte, c'est le temps total de l'entrée à la sortie finale, incluant chaque étape du pipeline.
Dans ces situations, le post-traitement devient un goulot d'étranglement caché à l'edge. Il ajoute de la latence, consomme des ressources CPU et complique le déploiement, tout en se situant en dehors du modèle lui-même.
Link to this sectionComment YOLO26 supprime la NMS et pourquoi cela le rend plus rapide#
YOLO26 supprime la NMS en s'attaquant à la cause profonde des détections en double plutôt qu'en les nettoyant après l'inférence. Au lieu de produire de nombreuses prédictions qui se chevauchent et qui doivent être filtrées, le modèle est entraîné pour générer directement un ensemble plus petit de détections finales fiables.
Cela est rendu possible en changeant la façon dont les détections sont apprises pendant l'entraînement. YOLO26 encourage une relation un-à-un plus claire entre les objets et les prédictions, réduisant la redondance à sa source. En conséquence, les détections en double sont résolues à l'intérieur du réseau lui-même plutôt que par un post-traitement externe.
La suppression de la NMS a un impact immédiat sur les performances à l'edge. Comme la NMS ne s'adapte pas bien aux accélérateurs de réseaux neuronaux, son élimination réduit le mouvement de mémoire et évite des étapes de traitement non neuronales coûteuses. Cela réduit la latence de bout en bout et rend la performance plus prévisible, surtout sur les appareils edge où le post-traitement peut autrement consommer une part notable du temps d'exécution total.
Cela simplifie également le pipeline d'inférence. Avec moins d'étapes en dehors du modèle, il y a moins de mouvements de données et moins de transferts entre les composants. La sortie du modèle est déjà le résultat final, ce qui rend l'exécution plus prévisible.
Link to this sectionSuppression de la DFL pour permettre une véritable performance de bout en bout#
Une autre innovation de YOLO26 est la suppression de la Distribution Focal Loss (DFL), qui était utilisée dans les modèles YOLO précédents pour la régression des boîtes englobantes. Au lieu de prédire directement une coordonnée unique, les modèles utilisant la DFL apprenaient une distribution de valeurs possibles, puis déduisaient une boîte englobante finale à partir de cette distribution. Cette approche a aidé à améliorer la précision de la localisation et constituait une étape importante pour les générations précédentes.
Au fil du temps, cependant, la DFL a également introduit des compromis. Prédire des distributions augmente le calcul et ajoute de la complexité à l'architecture du modèle, ce qui peut ralentir l'inférence sur CPU et rendre les modèles plus difficiles à exporter via différents formats de déploiement. La DFL imposait également des plages de régression fixes, ce qui pouvait limiter la flexibilité lors de la détection d'objets très grands.
YOLO26 supprime la DFL dans le cadre de son passage vers une conception plus simple et de bout en bout. La régression des boîtes englobantes est repensée pour être plus directe, réduisant les calculs inutiles tout en maintenant la précision. Ce changement s'aligne avec l'approche sans NMS de YOLO26.
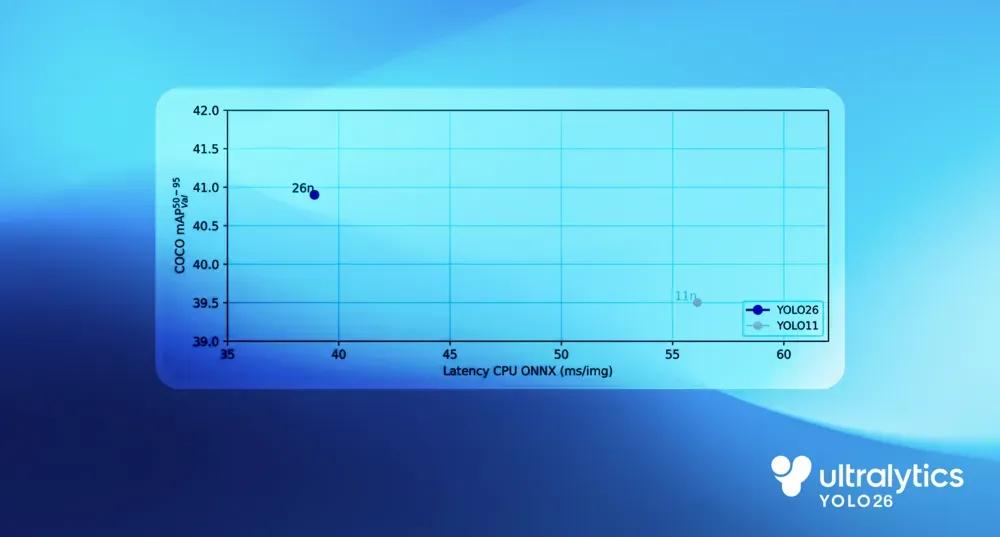
Link to this sectionD'où vient l'inférence CPU 43 % plus rapide#
Dans les benchmarks basés sur CPU, YOLO26 montre une amélioration claire des performances par rapport aux modèles YOLO précédents. Comparé à Ultralytics YOLO11, le modèle YOLO26 nano offre une inférence CPU jusqu'à 43 % plus rapide, une différence qui a un impact significatif dans les déploiements edge réels.
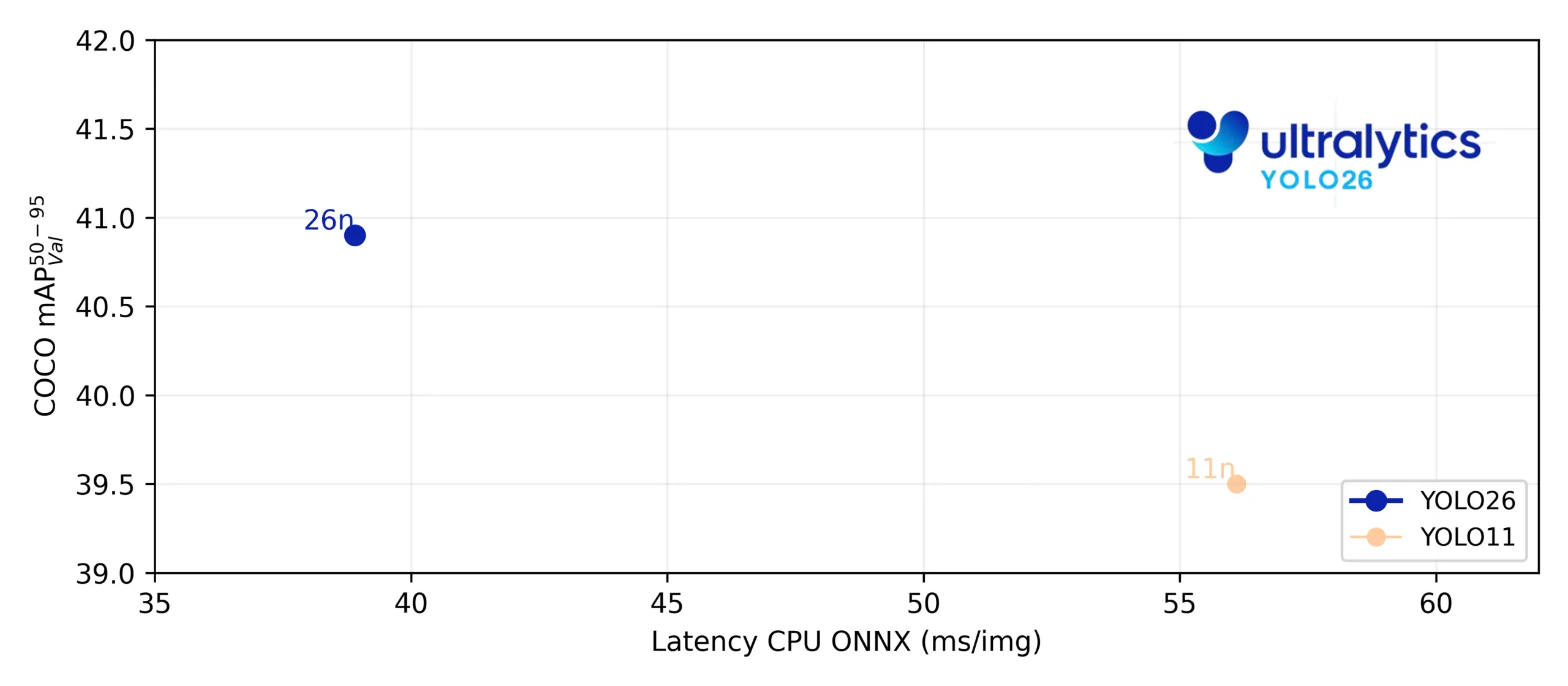
Fig 4. Benchmarking de la vitesse CPU de YOLO26.
Ce gain provient de la simplification du pipeline d'inférence complet plutôt que de l'optimisation d'un seul composant. L'exécution de bout en bout supprime la surcharge de post-traitement, une méthode de régression des boîtes englobantes plus directe réduit le calcul, et les choix de conception axés sur le CPU améliorent l'efficacité de l'exécution sur les processeurs à usage général.
Ensemble, ces changements réduisent la latence, diminuent la charge de travail du CPU et conduisent à une performance plus rapide et plus cohérente sur le matériel edge réel.
Link to this sectionL'impact de YOLO26 sur le déploiement et les exportations à l'edge#
Les gains de performance de YOLO26 s'étendent au-delà d'une inférence plus rapide. En simplifiant le modèle et en réduisant la surcharge mémoire, il devient plus facile à déployer et plus fiable à exécuter dans les environnements edge.
La conception de bout en bout de YOLO26 simplifie également l'exportation. Avec moins de composants auxiliaires et aucune étape de post-traitement externe, les modèles exportés sont entièrement autonomes. Cela réduit les dépendances spécifiques à la plateforme et aide à assurer un comportement cohérent sur les runtimes et les cibles matérielles.
En pratique, cela signifie que YOLO26 peut être déployé plus facilement sur des appareils edge tels que des caméras, des robots et des systèmes embarqués, en utilisant divers formats d'exportation. Ce que tu exportes est ce que tu exécutes, avec moins d'étapes d'intégration et moins de risques de dérive de déploiement.
Link to this sectionUne inférence edge plus rapide permet la robotique et l'IA de vision industrielle#
Jusqu'à présent, nous avons examiné comment la conception axée sur l'edge de YOLO26 améliore les performances au niveau du système. L'impact réel, cependant, réside dans la façon dont il facilite l'intégration de l'IA de vision dans les applications réelles.
Par exemple, en robotique et dans les environnements industriels, les systèmes de vision fonctionnent souvent sous des contraintes strictes de temps réel. Les décisions doivent être prises rapidement et de manière cohérente, en utilisant une puissance de calcul limitée et sans dépendre de la connectivité cloud. Avec Ultralytics YOLO26, répondre à ces exigences devient pratique.
Les applications comme la navigation de robots et la manipulation d'objets bénéficient d'une latence plus faible et d'une inférence plus prévisible, permettant aux robots de répondre en douceur aux changements dans leur environnement. De même, dans les environnements industriels, les modèles de vision peuvent s'exécuter directement sur les lignes de production pour détecter les défauts, suivre les composants et surveiller les processus sans introduire de retards ou de complexité supplémentaire.
En permettant une inférence rapide et fiable sur le matériel edge, YOLO26 aide à faire de l'IA de vision une partie naturelle de la robotique et des systèmes industriels, plutôt qu'un défi à déployer et à maintenir.
Link to this sectionPoints clés#
YOLO26 a été construit pour l'edge, où les contraintes réelles comme la latence, la mémoire et la fiabilité définissent ce qui est possible. En concevant le modèle autour de l'exécution axée sur le CPU, de l'inférence de bout en bout et d'un déploiement plus simple, YOLO26 rend l'IA de vision pratique à intégrer dans des systèmes réels. Cette approche axée sur l'edge permet un large éventail d'applications, de la robotique et la vision industrielle à l'IA embarquée et sur appareil, où la performance et la prévisibilité comptent le plus.
Rejoins notre communauté grandissante et explore notre répertoire GitHub pour des ressources IA pratiques. Pour construire avec l'IA de vision dès aujourd'hui, explore nos options de licence. Apprends comment l'IA en agriculture transforme l'agriculture et comment l'IA de vision dans la santé façonne l'avenir en visitant nos pages de solutions.






