Come Ultralytics Platform semplifica il deployment di modelli di computer vision
Vedi come Ultralytics Platform riunisce tutto il necessario per il deployment di modelli di computer vision, dai test alle API pronte per la produzione.
Ultralytics collabora da anni con la community di computer vision, creando modelli e strumenti che rendono la vision AI più accessibile a tutti. Con Ultralytics Platform, facciamo un passo avanti portando l'intero workflow di sviluppo della computer vision in un ambiente unificato, che copre tutto, dalla gestione dei dataset e l'annotazione fino al training, la validazione e il deployment dei modelli.
In particolare, siamo entusiasti di rendere più semplice il deployment dei modelli di computer vision. Poiché la computer vision continua a farsi strada nelle applicazioni del mondo reale, l'analisi di immagini e video al di fuori di ambienti controllati rimane complessa.
A differenza dei test in ambienti con condizioni prevedibili, gli scenari reali comportano luci variabili, input mutevoli e carichi di lavoro imprevedibili, rendendo il deployment una delle parti più impegnative del workflow di vision.
Il deployment non significa solo rendere un modello disponibile per l'uso. Richiede la creazione di processi in grado di gestire dati reali e assicurarsi che tutto funzioni senza intoppi man mano che l'utilizzo cresce e i progetti scalano.
I team devono anche monitorare le prestazioni e mantenere l'affidabilità nel tempo. Questo spesso significa passare da uno strumento AI all'altro per test, integrazione, deployment e monitoraggio, il che può rallentare lo sviluppo del modello e aggiungere una complessità non necessaria.
I workflow finiscono per diventare frammentati. La piattaforma Ultralytics unifica e semplifica questo processo.
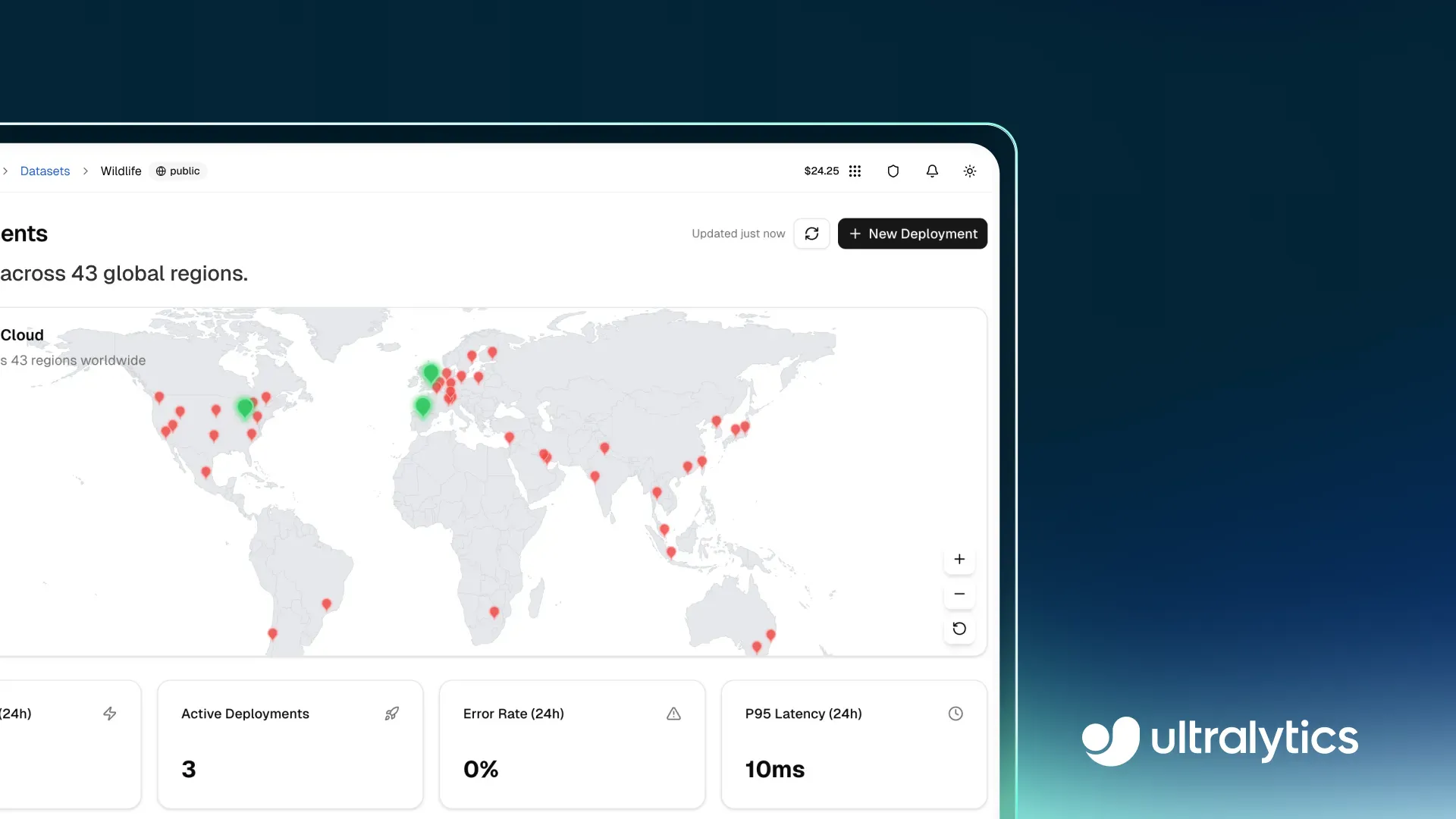
Fornisce supporto integrato per il model serving, il test e il monitoraggio all'interno di un unico ambiente. I team possono validare i modelli tramite inferenza basata su browser, integrarli nelle applicazioni attraverso servizi di inferenza condivisi e distribuirli su endpoint dedicati con funzionalità di monitoraggio delle prestazioni.
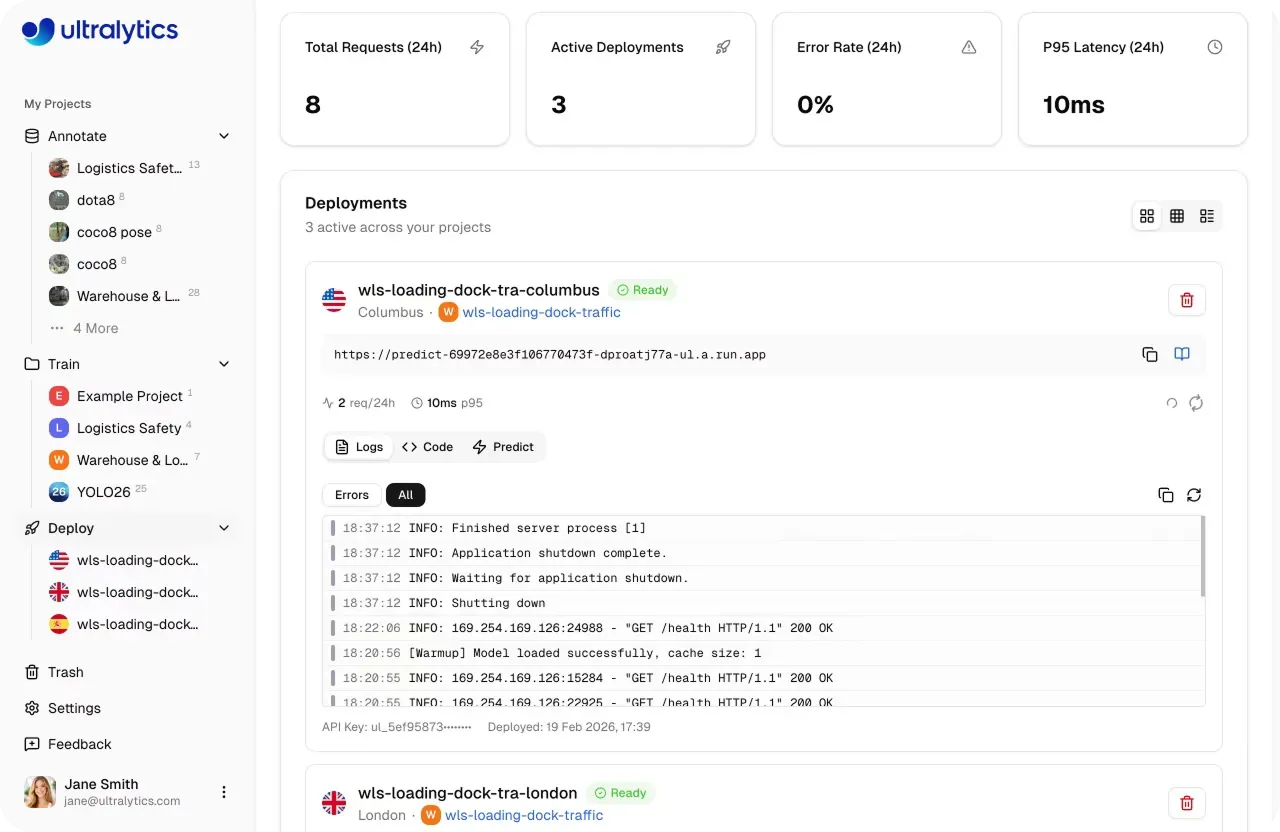
Fig 1. Uno sguardo alla pagina di deployment all'interno della piattaforma Ultralytics (Source)
In questo articolo esploreremo come la piattaforma Ultralytics ridefinisce il model deployment di computer vision, dai test e l'integrazione fino al deployment in produzione e al monitoraggio. Iniziamo!
Link to this sectionUna panoramica sul deployment dei modelli di computer vision#
Nel ciclo di vita del machine learning, il model deployment è la fase in cui un modello passa dalla sperimentazione all'uso reale. Per i computer vision models costruiti utilizzando il deep learning e le reti neurali convoluzionali, questo significa generalmente renderli disponibili per elaborare immagini e video in tempo reale.
Una volta distribuiti, questi modelli acquisiscono nuovi dati, che solitamente passano attraverso fasi di pre-elaborazione come il ridimensionamento, la normalizzazione o la formattazione. I dati elaborati vengono quindi passati al modello, che applica i pattern appresi durante il training per generare predizioni ad alta precisione.
A seconda del caso d'uso, ciò può includere diversi task di computer vision. Ad esempio, i modelli Ultralytics YOLO, come Ultralytics YOLO26, supportano un'ampia gamma di task di vision, inclusi object detection, image classification, instance segmentation, pose estimation e oriented bounding box (OBB) detection.
Per rendere tutto ciò pratico nelle applicazioni del mondo reale, i modelli spesso devono essere integrati in sistemi in grado di gestire sia la pre-elaborazione che l'inferenza in modo efficiente. È qui che l'infrastruttura di deployment diventa essenziale.
Negli ambienti di produzione, i modelli vengono solitamente consultati tramite REST API o sistemi di model-serving. Queste interfacce consentono alle applicazioni di inviare dati e ricevere predizioni in modo programmatico, rendendo più semplice l'integrazione con applicazioni esterne, dispositivi IoT o sistemi robotici che si basano sulla comprensione visiva in tempo reale.
Link to this sectionLimiti degli strumenti tradizionali di deployment per la computer vision#
Il deployment dei modelli di computer vision può sembrare semplice, ma fino ad ora, in pratica, appariva molto diverso. Considera una configurazione comune: i dati vengono prima acquisiti da telecamere o sensori, inviati a un modello per l'inferenza e poi restituiti a un'applicazione come predizioni.
In realtà, ognuno di questi passaggi viene spesso gestito da strumenti e servizi separati. Un sistema può gestire l'acquisizione dei dati, un altro gestisce il model serving, mentre strumenti aggiuntivi vengono utilizzati per lo scaling, il monitoraggio e il logging. Mantenere questi componenti connessi e funzionanti in modo affidabile può diventare rapidamente complesso.
Con la crescita dell'utilizzo, questa complessità aumenta. Gestire l'infrastruttura, gestire le dipendenze e mantenere prestazioni costanti lungo la pipeline end-to-end può rallentare lo sviluppo e rendere più difficile distribuire modelli di computer vision nelle applicazioni reali.
La piattaforma Ultralytics riunisce questi componenti in un unico ambiente unificato. Ciò fornisce un modo più coerente per gestire l'intero workflow di deployment, supportando al contempo prestazioni e affidabilità su scala.
Link to this sectionOpzioni di model deployment abilitate dalla piattaforma Ultralytics#
Oltre a unificare il processo di deployment del modello, la piattaforma Ultralytics offre anche flessibilità nel modo in cui i modelli vengono distribuiti e utilizzati.
Per supportare le diverse fasi del deployment dei modelli di computer vision, la piattaforma offre quattro opzioni: test basati su browser con inferenza istantanea, inferenza condivisa tramite API per lo sviluppo, endpoint dedicati per deployment scalabili in produzione tra regioni globali ed export del modello per eseguire modelli su infrastrutture esterne o dispositivi edge.
Quindi diamo un'occhiata più da vicino a come funziona ciascuna di queste opzioni.
Link to this sectionValida i modelli rapidamente usando la scheda Predict#
Prima di mettere un modello in produzione, è importante capire come si comporta su dati nuovi e mai visti. La piattaforma Ultralytics include una scheda Predict integrata che ti permette di run inference direttamente nel browser senza alcuna configurazione, infrastruttura o dipendenza.
La scheda Predict rende la validazione del modello veloce e interattiva. Puoi caricare immagini, usare esempi precaricati o acquisire input con una webcam, e l'inferenza viene eseguita automaticamente non appena vengono forniti i dati.
I risultati appaiono istantaneamente con visual overlay, punteggi di confidenza e output dettagliati, offrendoti una visione chiara di come si comporta il modello.
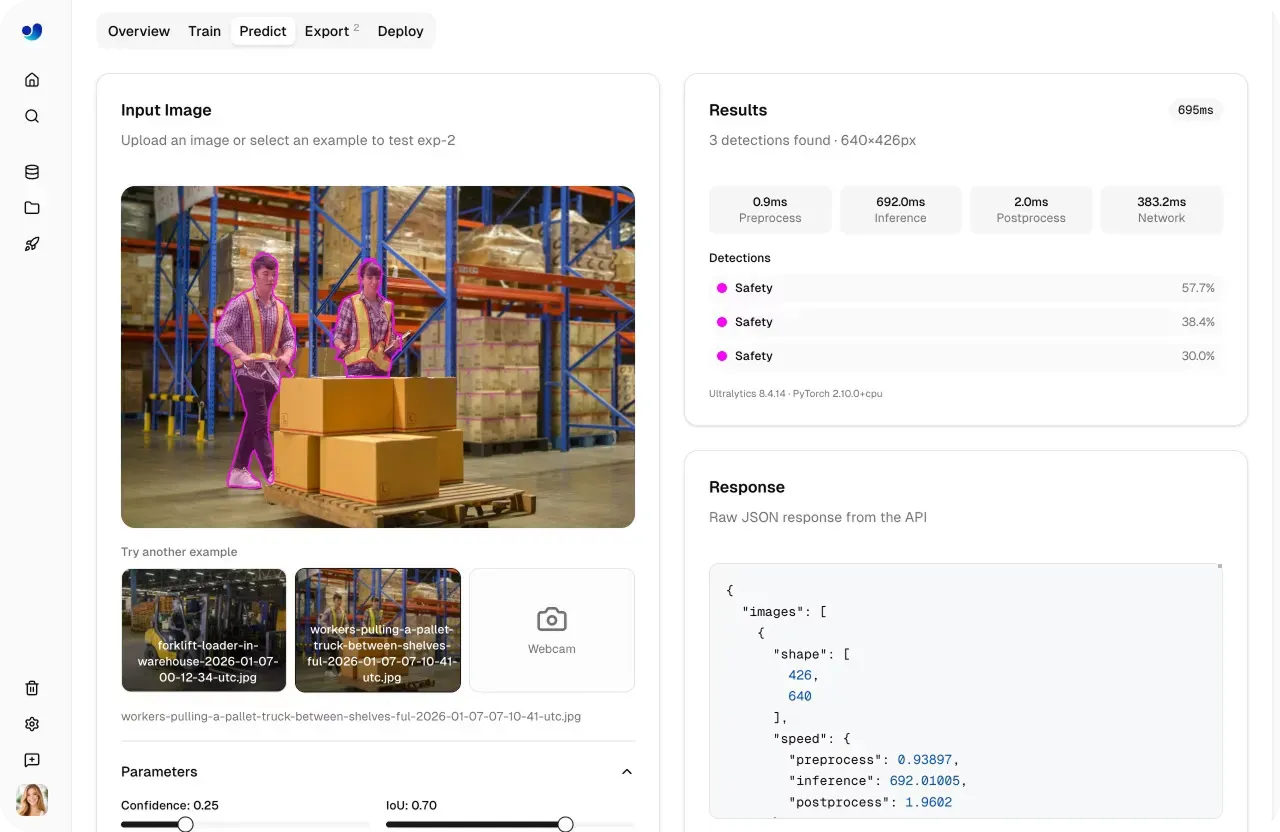
Fig 2. Un esempio di validazione di un modello utilizzando la scheda Predict (Source)
Ciò significa che con pochi clic, puoi testare diversi input, regolare i parametri e valutare le prestazioni all'interno di un'unica interfaccia prima di procedere al deployment.
Link to this sectionEsecuzione di inferenze condivise per test o utilizzo leggero#
Supponiamo che tu abbia addestrato un modello e l'abbia validato usando la scheda Predict. Il passo successivo è spesso iniziare a integrare quel modello in un'applicazione o in un workflow.
Invece di configurare infrastrutture o gestire server, la piattaforma Ultralytics fornisce servizi di inferenza condivisi che ti consentono di inviare dati al tuo modello e ricevere predizioni tramite semplici REST API.
Dietro le quinte, l'inferenza condivisa viene eseguita su un sistema multi-tenant in alcune regioni principali, dove le richieste vengono instradate automaticamente verso il servizio disponibile più vicino. Ciò aiuta a mantenere prestazioni reattive consentendo agli utenti in diverse posizioni di accedere ai modelli in modo coerente.
Puoi inviare input utilizzando normali richieste HTTP e ricevere in cambio output strutturati, rendendo semplice connettere i modelli ad applicazioni, script o workflow di automazione. Questa configurazione è un'ottima opzione per sviluppo, test, integrazioni o un utilizzo più leggero prima di passare a deployment di produzione più scalabili.
Link to this sectionDistribuisci i modelli a livello globale tramite endpoint dedicati#
Una volta che un modello è pronto per la produzione, deve gestire il traffico reale in modo affidabile e su larga scala. La piattaforma Ultralytics supporta questo con dedicated endpoints, dove i modelli vengono eseguiti come servizi single-tenant in 43 global regions. Distribuire vicino agli utenti finali aiuta a ridurre la latenza e mantenere prestazioni costanti in diverse posizioni.
Ogni endpoint viene eseguito con le proprie risorse di calcolo allocate e un URL univoco per le richieste di inferenza. Questo livello di controllo rende semplice ottimizzare i deployment in base alle esigenze di prestazioni, dai casi d'uso leggeri ad applicazioni più impegnative ad alto throughput che necessitano di maggiori risorse computazionali.
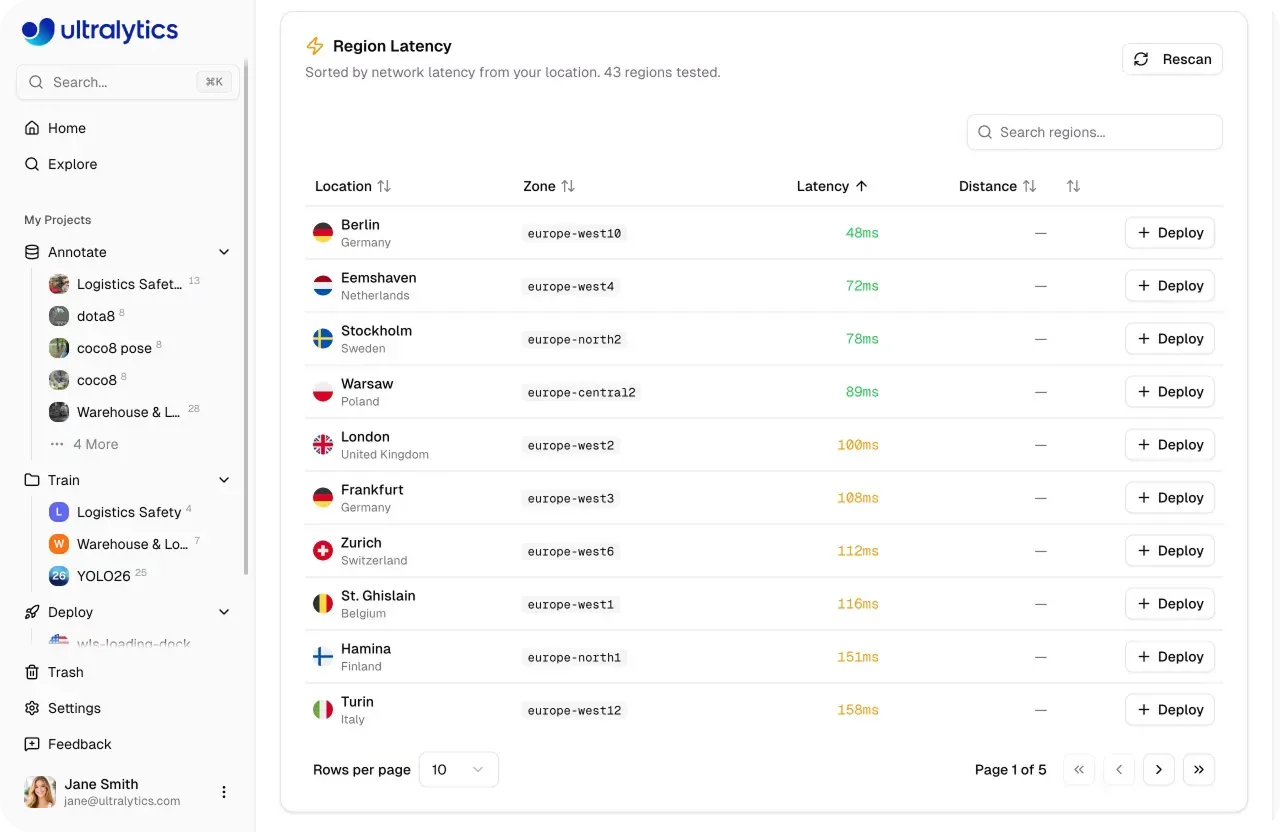
Fig 3. Puoi distribuire modelli in 43 regioni globali utilizzando la piattaforma Ultralytics (Source)
Tuttavia, gli endpoint dedicati sono progettati per gestire autonomamente i carichi di lavoro variabili, con auto-scaling che regola le risorse in base al traffico in entrata. Scalano verso l'alto durante i periodi di alta domanda e verso il basso quando l'utilizzo diminuisce. Con lo scale-to-zero abilitato di default, gli endpoint inattivi si spengono automaticamente e si riavviano quando arrivano nuove richieste, aiutando a ottimizzare l'utilizzo delle risorse senza intervento manuale.
Link to this sectionEsporta il tuo modello facilmente con la piattaforma Ultralytics#
Al giorno d'oggi, l'edge AI sta diventando sempre più essenziale poiché molte applicazioni si basano sull'esecuzione di modelli direttamente su dispositivi come smartphone, telecamere e sistemi embedded. L'esecuzione locale dei modelli può anche aiutare a soddisfare i requisiti di privacy dei dati, poiché dati sensibili come immagini o flussi video possono essere elaborati direttamente sul dispositivo senza essere inviati a server esterni.
In questi scenari, i modelli devono essere eseguiti al di fuori della piattaforma Ultralytics, rendendo l'export del modello una parte cruciale del processo di deployment. I modelli Ultralytics YOLO sono spesso addestrati utilizzando Python e PyTorch e possono quindi essere esportati in oltre 17 formati diversi, inclusi ONNX, TensorRT, CoreML e OpenVINO.
Questa ampia gamma di formati garantisce la compatibilità tra hardware diversi, dalle unità di elaborazione grafica (GPU) ad alte prestazioni ai dispositivi mobili ed embedded. Oltre a questo, l'export consente l'ottimizzazione delle prestazioni per ambienti specifici.
A seconda del formato, i modelli possono ottenere velocità di inferenza più elevate, come migliori prestazioni della GPU con TensorRT o esecuzione CPU ottimizzata con ONNX e OpenVINO. Opzioni come la quantizzazione FP16 e INT8 possono ridurre ulteriormente le dimensioni del modello e migliorare il throughput, il che è particolarmente utile per i deployment edge.
Sulla piattaforma Ultralytics, l'export è integrato direttamente nel workflow, rendendo rapida la generazione di modelli ottimizzati in pochi clic. I team possono passare dal training all'esecuzione dei modelli su sistemi esterni senza aggiungere un sovraccarico extra.
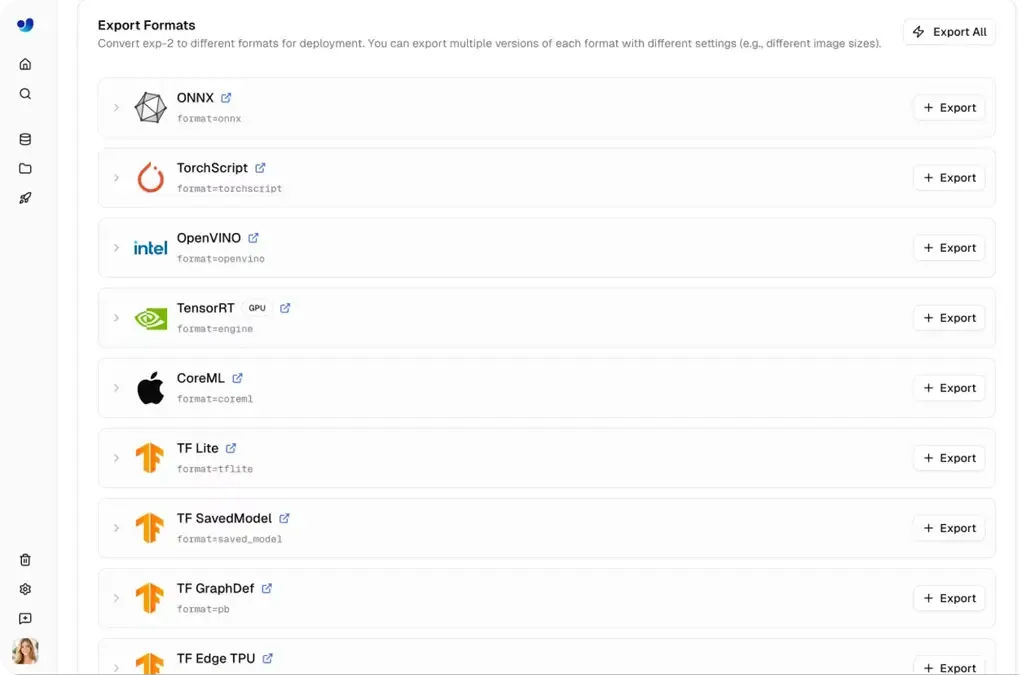
Fig 4. Una selezione di formati di export sulla piattaforma Ultralytics.
Link to this sectionScegliere l'opzione di model deployment corretta#
Ogni opzione di deployment nella piattaforma Ultralytics supporta una fase diversa del workflow, dai primi test all'uso in produzione. Ecco una panoramica su quando potresti usare ognuna di esse:
- Scheda Predict: questa viene solitamente utilizzata subito dopo il training o il fine-tuning, quando vuoi validare le prestazioni di un modello su nuovi dati usando l'inferenza basata su browser.
- Inferenza condivisa: in questa fase, i modelli possono essere integrati nelle applicazioni tramite API, rendendo possibile testare le interazioni del mondo reale durante lo sviluppo.
- Endpoint dedicati: vengono utilizzati per deployment in produzione, dove i modelli necessitano di prestazioni costanti, risorse dedicate e la capacità di scalare tra regioni globali.
- Model export: quando i modelli devono essere eseguiti al di fuori della piattaforma, l'opzione per esportarli consente il deployment su dispositivi edge, app mobili o infrastrutture personalizzate.
I team passano spesso attraverso queste opzioni passo dopo passo, andando dalla validazione all'integrazione e infine al deployment in produzione, il tutto all'interno della piattaforma.
Link to this sectionMonitoraggio dei modelli distribuiti tramite la piattaforma Ultralytics#
Per quanto importante sia il deployment, la pipeline di vision non finisce lì. Una volta che un modello è in esecuzione in produzione, il monitoraggio continuo è fondamentale per assicurarsi che funzioni in modo affidabile nel tempo.
La piattaforma Ultralytics fornisce strumenti di built-in monitoring che offrono ai team una chiara visibilità sul comportamento dei loro modelli di vision AI nel tempo, supportando un workflow di machine learning operations (MLOps) più strutturato.
La pagina Deploy include una dashboard che traccia metriche chiave come richieste totali, deployment attivi, latenza di risposta e tassi di errore. Questi insight aiutano i team a comprendere i pattern di utilizzo, valutare la reattività del sistema e garantire prestazioni a bassa latenza su diversi carichi di lavoro.
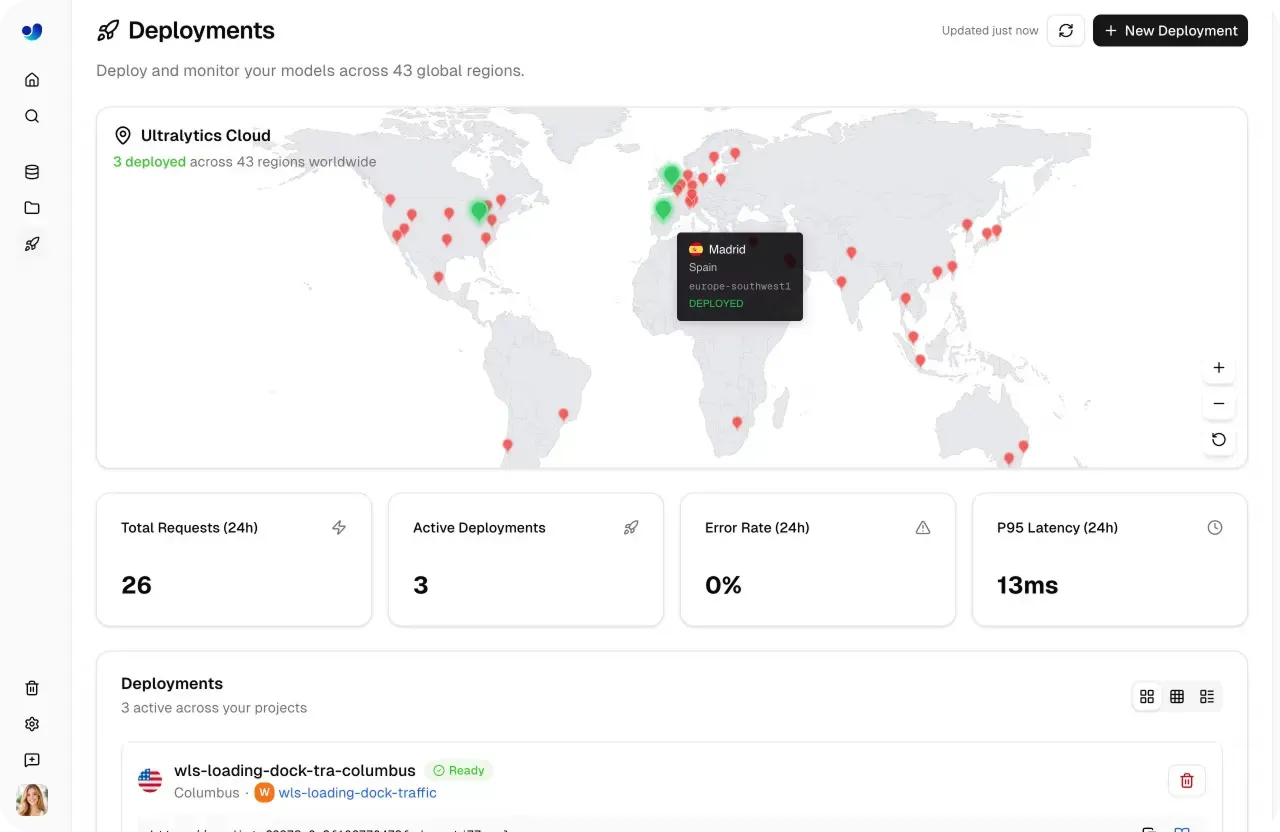
Fig 5. La piattaforma Ultralytics rende facile il monitoraggio dei modelli distribuiti. (Source)
Ogni endpoint dedicato fornisce anche un'osservabilità dettagliata tramite viste di deployment individuali. Ciò include l'accesso ai log, lo stato di salute del modello e i dati sulle prestazioni in tempo reale. I log possono essere utilizzati per eseguire il debug dei problemi, tracciare le richieste fallite e identificare potenziali problemi relativi a dipendenze o infrastruttura.
Man mano che gli ambienti di produzione si evolvono, fattori come la modifica dei dati in input, le richieste di scaling o i cambiamenti nei pattern di utilizzo possono influire sull'accuratezza e sulla robustezza del modello. Monitorando continuamente le metriche delle prestazioni, i team possono rilevare anomalie, identificare colli di bottiglia e intraprendere azioni correttive come l'ottimizzazione del modello o la regolazione delle risorse per mantenere un model serving coerente e affidabile.
Link to this sectionCostruire la scalabilità nei deployment dei modelli di computer vision#
Scalare i sistemi di computer vision ha significato tradizionalmente unire workflow e framework che non sono mai stati progettati per funzionare insieme. Pipeline di dati, loop di training, infrastruttura di deployment e sistemi di monitoraggio spesso risiedono in luoghi separati, creando attrito in ogni fase.
La vera sfida non è solo costruire modelli, ma mantenerli operativi. Passare dai dati alla produzione, adattarsi a nuovi input, gestire la crescente domanda e migliorare continuamente senza rallentare.
Ciò che risalta nella piattaforma Ultralytics è che questo movimento è integrato. Invece di trattare ogni fase come un passaggio separato, li connette in un loop continuo in cui i modelli possono essere sviluppati, distribuiti, osservati e aggiornati nello stesso ambiente.
Quel cambiamento modifica il modo in cui i team scalano. Non si tratta più dell'orchestrazione di strumenti o infrastrutture, ma del mantenimento dello slancio man mano che i sistemi crescono.
Link to this sectionPunti chiave#
Portare modelli di machine learning come quelli di computer vision in applicazioni del mondo reale richiede che siano affidabili, scalabili e facili da gestire. La piattaforma Ultralytics semplifica questo processo combinando varie funzioni, come model serving, deployment e monitoraggio, in un unico ambiente unificato. Con opzioni di deployment flessibili e strumenti integrati, i team possono passare dalla sperimentazione alla produzione più rapidamente e con meno complessità.
Dai un'occhiata alla nostra community ed esplora il nostro GitHub repository per saperne di più. Esplora le nostre pagine di soluzioni per vedere varie applicazioni come AI in healthcare e computer vision in logistics. Scopri le nostre licensing options e inizia a costruire oggi stesso!






