Ultralytics Platformがコンピュータビジョンモデルのデプロイを簡素化する仕組み
Ultralytics Platformが、テストから本番対応のAPIに至るまで、コンピュータビジョンモデルのデプロイメントに必要なすべてをどのように統合しているかをご覧ください。
Ultralyticsは長年にわたりコンピュータビジョンコミュニティと連携し、誰もがビジョンAIを利用しやすくするためのモデルやツールを開発してきました。私たちはUltralytics Platformによって、データセット管理やアノテーションから、モデルのトレーニング、バリデーション、そしてデプロイに至るまで、コンピュータビジョンの開発ワークフロー全体を一つの統一された環境に集約し、さらに一歩先へと進めています。
特に、コンピュータビジョンモデルのデプロイをより容易にすることに注力しています。コンピュータビジョンが実世界のアプリケーションへと浸透し続ける中で、管理されていない環境下での画像や動画の解析は依然として複雑です。
条件が予測可能なテスト環境とは異なり、実世界のシナリオには、変化する照明、入力の変動、予測不可能なワークロードなどが伴います。このため、デプロイはビジョンワークフローにおいて最も困難な部分の一つとなっています。
デプロイには、モデルを利用可能な状態にする以上の作業が必要です。実世界のデータを処理できるプロセスを構築し、利用の拡大やプロジェクトの規模拡大に合わせてすべてがスムーズに機能することを保証する必要があります。
また、チームはパフォーマンスを追跡し、長期にわたって信頼性を維持しなければなりません。これには、多くの場合、テスト、統合、デプロイ、監視といった異なるAIツール間を切り替える必要があり、モデル開発の遅延や不必要な複雑化を招く可能性があります。
結果としてワークフローは断片化してしまいます。Ultralytics Platformはこのプロセスを統合し、簡素化します。
単一の環境内でモデルのサービング、テスト、監視のための組み込みサポートを提供します。チームはブラウザベースの推論を使用してモデルを検証し、共有推論サービスを通じてアプリケーションに統合し、パフォーマンス監視機能を備えた専用エンドポイントへデプロイできます。
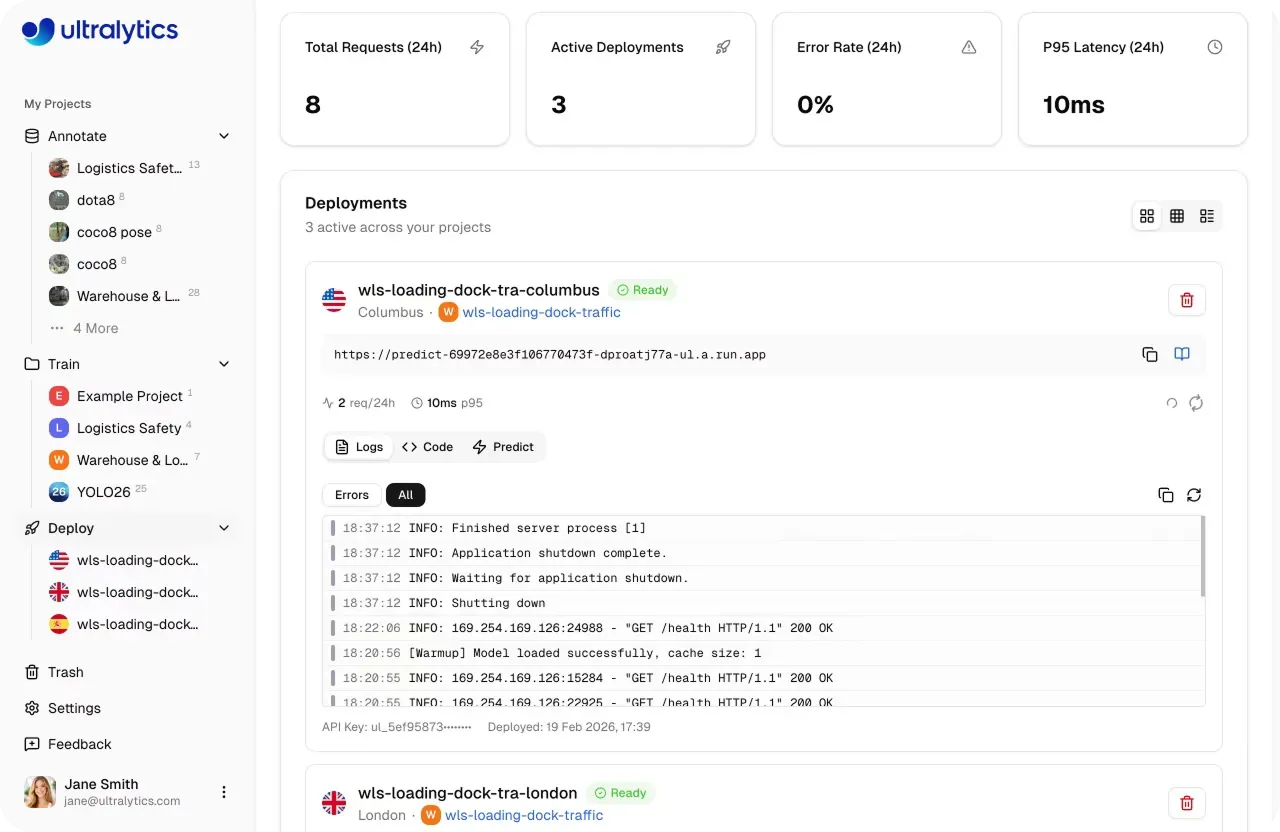
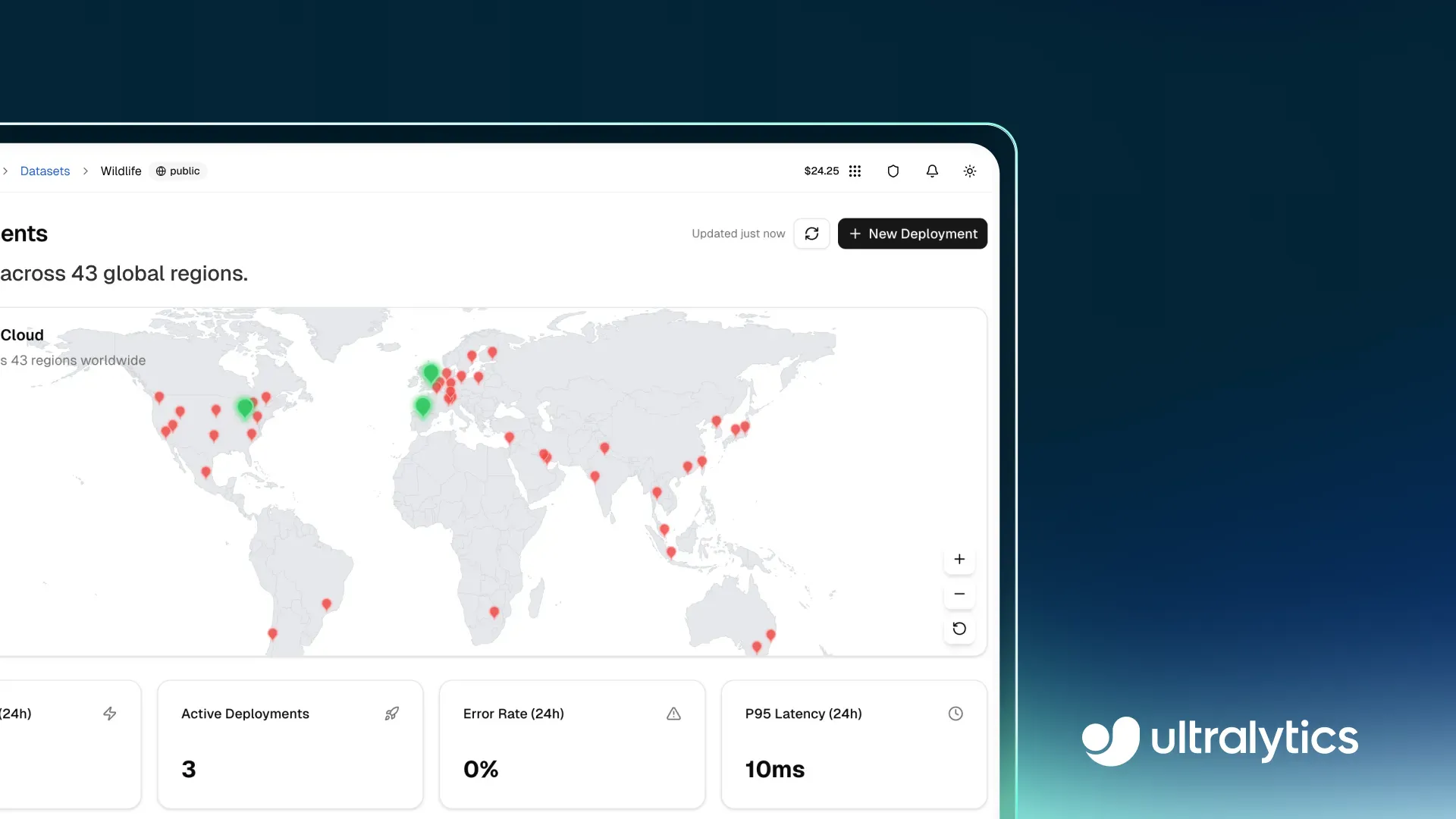
図1. Ultralytics Platform内のデプロイページの様子 (ソース)
この記事では、Ultralytics Platformが、テストや統合から本番環境へのデプロイや監視に至るまで、どのようにコンピュータビジョンのモデルデプロイを再定義しているのかを探ります。それでは始めましょう!
Link to this sectionコンピュータビジョンモデルのデプロイの概要#
機械学習のライフサイクルにおいて、モデルデプロイとはモデルが実験段階から実世界の利用へと移行する段階を指します。ディープラーニングと畳み込みニューラルネットワークを用いて構築されたコンピュータビジョンモデルにとって、これは一般的に、リアルタイムで画像や動画を処理できるようにすることを意味します。
一度デプロイされると、これらのモデルは新しいデータを取り込みます。通常、そのデータはリサイズ、正規化、フォーマットなどの前処理ステップを経ます。処理されたデータはモデルに渡され、トレーニング中に学習したパターンを適用することで高精度の予測が生成されます。
ユースケースに応じて、さまざまなコンピュータビジョンのタスクが含まれます。例えば、Ultralytics YOLO26などのUltralytics YOLOモデルは、物体検出、画像分類、インスタンスセグメンテーション、ポーズ推定、指向性バウンディングボックス(OBB)検出など、幅広いビジョンタスクをサポートしています。
実世界のアプリケーションでこれを実用化するためには、前処理と推論の両方を効率的に処理できるシステムにモデルを統合する必要があります。ここで、デプロイのインフラストラクチャが不可欠になります。
本番環境では、モデルは一般的にREST APIやモデルサービングシステムを通じてアクセスされます。これらのインターフェースにより、アプリケーションはプログラムを介してデータを送信し、予測結果を受け取ることができます。これにより、リアルタイムの視覚理解を必要とする外部アプリケーション、IoTデバイス、またはロボットシステムとの統合が容易になります。
Link to this section従来のコンピュータビジョンデプロイツールの制限#
コンピュータビジョンモデルのデプロイは単純に聞こえるかもしれませんが、これまでは実際には全く異なる様子でした。一般的なセットアップを考えてみましょう。データがカメラやセンサーからキャプチャされ、推論のためにモデルに送信され、予測としてアプリケーションに返されます。
現実には、これらのステップの各々が別々のツールやサービスによって処理されることがよくあります。あるシステムがデータキャプチャを担当し、別のシステムがモデルサービングを管理し、スケーリング、監視、ログ記録にはさらに別のツールが使用されます。これらのコンポーネントを接続し、確実に稼働させ続けることは、すぐに複雑化してしまう可能性があります。
利用が拡大するにつれて、この複雑さは増大します。インフラストラクチャの管理、依存関係の処理、エンドツーエンドのパイプライン全体での一貫したパフォーマンスの維持は、開発を鈍化させ、実世界のアプリケーションへのコンピュータビジョンモデルのデプロイをより困難にする可能性があります。
Ultralytics Platformはこれらのコンポーネントを一つの統一された環境にまとめます。これにより、パフォーマンスと信頼性を規模に応じてサポートしながら、デプロイワークフロー全体を管理する、より一貫性のある方法が提供されます。
Link to this sectionUltralytics Platformで可能になるモデルデプロイの選択肢#
Ultralytics Platformはモデルデプロイのプロセスを統合するだけでなく、モデルのデプロイ方法と利用方法にも柔軟性をもたらします。
コンピュータビジョンモデルのデプロイのさまざまな段階をサポートするために、本プラットフォームは4つのオプションを提供しています。インスタント推論によるブラウザベースのテスト、開発用のAPIを介した共有推論、世界中のリージョンにわたるスケーラブルな本番デプロイのための専用エンドポイント、そして外部インフラストラクチャやエッジデバイス上でモデルを実行するためのモデルエクスポートです。
それでは、これらの各オプションがどのように機能するかを詳しく見ていきましょう。
Link to this sectionPredictタブを使用した迅速なモデルのバリデーション#
モデルを本番環境へ移行する前に、新しい未知のデータに対してどのように動作するかを理解することが重要です。Ultralytics Platformには、セットアップ、インフラストラクチャ、依存関係なしで直接ブラウザ内で推論を実行できる、組み込みのPredictタブが含まれています。
Predictタブにより、モデルのバリデーションは高速かつ対話的になります。画像をアップロードしたり、あらかじめ読み込まれた例を使用したり、ウェブカメラで入力をキャプチャしたりすることができ、データが提供されるとすぐに推論が自動的に実行されます。
結果はビジュアルオーバーレイ、信頼度スコア、詳細な出力とともに即座に表示され、モデルの動作を明確に把握できます。
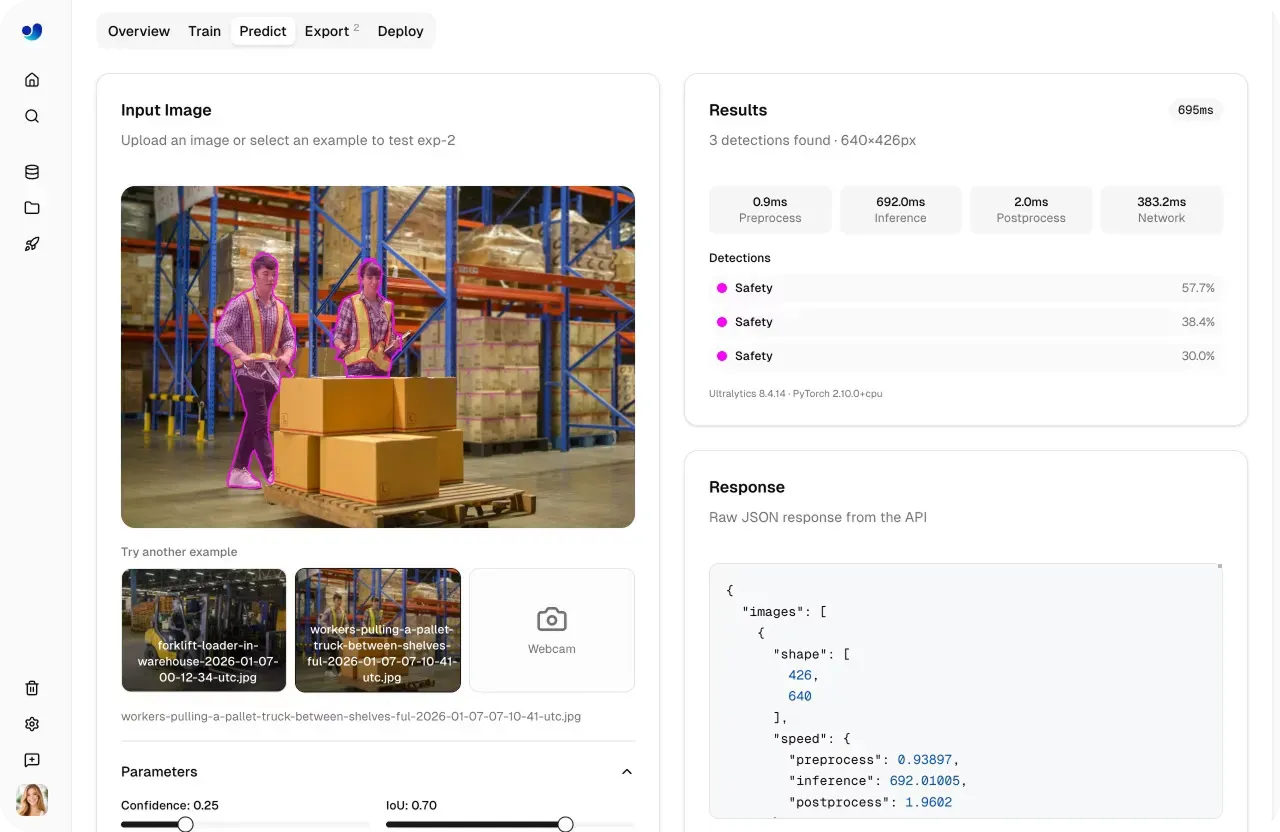
図2. Predictタブを使用したモデルのバリデーションの例 (ソース)
つまり、数回クリックするだけで、さまざまな入力をテストし、パラメータを調整し、デプロイに進む前に単一のインターフェース内でパフォーマンスを評価できるということです。
Link to this sectionテストや小規模な利用のための共有推論の実行#
モデルをトレーニングし、Predictタブを使用して検証したとします。次のステップは、多くの場合、そのモデルをアプリケーションやワークフローに統合し始めることです。
インフラストラクチャをセットアップしたりサーバーを管理したりする代わりに、Ultralytics Platformは共有推論サービスを提供しており、シンプルなREST APIを通じてモデルにデータを送信し、予測を受け取ることができます。
裏側では、共有推論はいくつかのコアリージョンにわたるマルチテナントシステム上で実行され、リクエストは最も近い利用可能なサービスに自動的にルーティングされます。これにより、応答性の高いパフォーマンスを維持しながら、異なる場所にいるユーザーがモデルに一貫してアクセスできるようになります。
標準的なHTTPリクエストを使用して入力を送信し、構造化された出力を返信として受け取ることができるため、モデルをアプリケーション、スクリプト、または自動化ワークフローに接続することが簡単になります。このセットアップは、よりスケーラブルな本番デプロイに移行する前の、開発、テスト、統合、または小規模な利用に適した優れたオプションです。
Link to this section専用エンドポイントを通じたグローバルなモデルデプロイ#
モデルの準備が本番環境で整ったら、リアルワールドのトラフィックを確実に、かつ大規模に処理する必要があります。Ultralytics Platformは専用エンドポイントでこれをサポートしています。ここでは、モデルは43のグローバルリージョンにわたるシングルテナントサービスとして実行されます。エンドユーザーに近い場所でデプロイすることで、レイテンシを削減し、異なる場所で一貫したパフォーマンスを維持できます。
各エンドポイントは、独自の割り当てられたコンピューティングリソースと、推論リクエスト用の一意のURLで実行されます。このレベルの制御により、軽量なユースケースから、より多くのコンピューティングリソースを必要とする高スループットなアプリケーションに至るまで、パフォーマンスのニーズに合わせてデプロイを容易に調整できます。
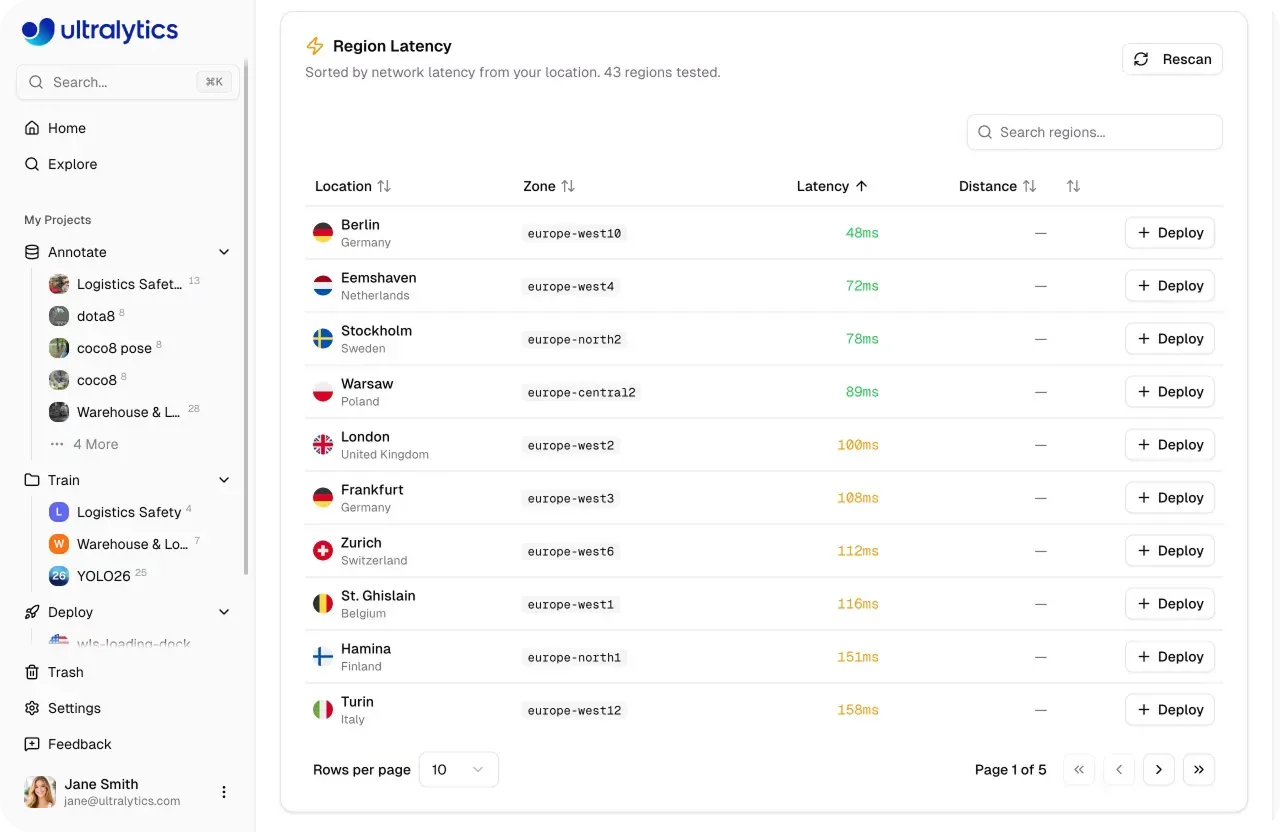
図3. Ultralytics Platformを使用して43のグローバルリージョンにモデルをデプロイできます (ソース)
ただし、専用エンドポイントはそれ自体で変化するワークロードを処理するように設計されており、入力トラフィックに基づいてリソースを調整するオートスケーリングを備えています。需要が高い期間にはスケールアップし、利用が減少するとスケールダウンします。デフォルトで有効になっているスケール・トゥ・ゼロにより、アイドル状態のエンドポイントは自動的にシャットダウンし、新しいリクエストが到着すると再起動するため、手動で介入することなくリソース使用量を最適化するのに役立ちます。
Link to this sectionUltralytics Platformで簡単にモデルをエクスポート#
今日、スマートフォン、カメラ、組み込みシステムなどのデバイス上で直接モデルを実行することに依存するアプリケーションが増えており、エッジAIはますます不可欠になっています。また、モデルをローカルで実行することは、機密性の高いデータ(画像や動画ストリームなど)を外部サーバーに送信することなくオンデバイスで直接処理できるため、データプライバシーの要件を満たすのにも役立ちます。
このようなシナリオでは、モデルはUltralytics Platformの外で実行される必要があるため、モデルのエクスポートがデプロイプロセスにおいて重要な役割を果たします。Ultralytics YOLOモデルは通常PythonとPyTorchを使用してトレーニングされ、その後ONNX、TensorRT、CoreML、OpenVINOなど、17以上の異なるフォーマットにエクスポートできます。
この幅広いフォーマットにより、高性能なグラフィックス処理ユニット(GPU)からモバイルおよび組み込みデバイスに至るまで、多様なハードウェア間での互換性が確保されます。さらに、エクスポートすることで特定の環境に合わせたパフォーマンスチューニングが可能になります。
フォーマットに応じて、モデルは高速な推論速度を実現できます。例えば、TensorRTによるGPUパフォーマンスの向上や、ONNXおよびOpenVINOによる最適化されたCPU実行などです。FP16やINT8の量子化のようなオプションを使用すれば、モデルサイズをさらに削減し、スループットを向上させることができ、これは特にエッジデプロイで役立ちます。
Ultralytics Platformでは、エクスポート機能がワークフローに直接組み込まれているため、わずか数クリックで最適化されたモデルを迅速に生成できます。チームは追加の負荷をかけることなく、トレーニングから外部システムでのモデル実行へと移行できます。
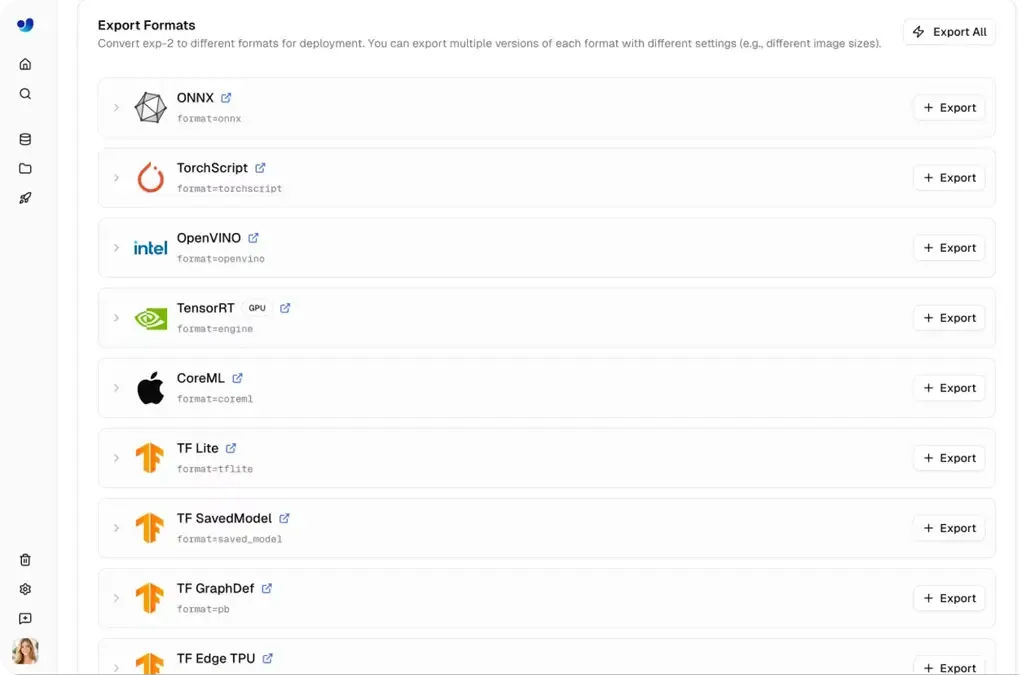
図4. Ultralytics Platformでのエクスポートフォーマットの選択
Link to this section適切なモデルデプロイオプションの選択#
Ultralytics Platformの各デプロイオプションは、初期のテストから本番利用まで、ワークフローの異なる段階をサポートします。以下に各オプションをいつ使用するかについての概要を示します:
- Predictタブ: これは通常、トレーニングやファインチューニングの直後に、ブラウザベースの推論を使用してモデルが新しいデータに対してどのように動作するかを検証したい場合に使用されます。
- 共有推論: この段階では、モデルをAPIを通じてアプリケーションに統合でき、開発中に実世界のインタラクションをテストすることが可能になります。
- 専用エンドポイント: これらは本番デプロイ用であり、モデルが一貫したパフォーマンス、専用のリソース、そしてグローバルなリージョン全体でスケーリングする能力を必要とする場合に使用されます。
- モデルエクスポート: モデルをプラットフォーム外で実行する必要がある場合、エクスポートオプションを使用することで、エッジデバイス、モバイルアプリ、またはカスタムインフラストラクチャへのデプロイが可能になります。
チームは多くの場合、これらのオプションを段階的に活用し、バリデーションから統合、そして最終的な本番デプロイへと、すべてプラットフォーム内で移行していきます。
Link to this sectionUltralytics Platformを通じたデプロイ済みモデルの監視#
デプロイが重要であるのと同様に、ビジョンパイプラインはそこで終わりではありません。モデルが本番環境で実行された後は、時間の経過とともに確実に動作することを保証するために継続的な監視が不可欠です。
Ultralytics Platformは、チームがビジョンAIモデルの挙動を長期的に把握できるようにするための組み込み監視ツールを提供しており、より構造化された機械学習オペレーション(MLOps)ワークフローをサポートしています。
Deployページには、総リクエスト数、アクティブなデプロイ、応答レイテンシ、エラー率などの主要なメトリクスを追跡するダッシュボードが含まれています。これらのインサイトは、チームが利用パターンを理解し、システムの応答性を評価し、さまざまなワークロード全体で低レイテンシのパフォーマンスを確保するのに役立ちます。
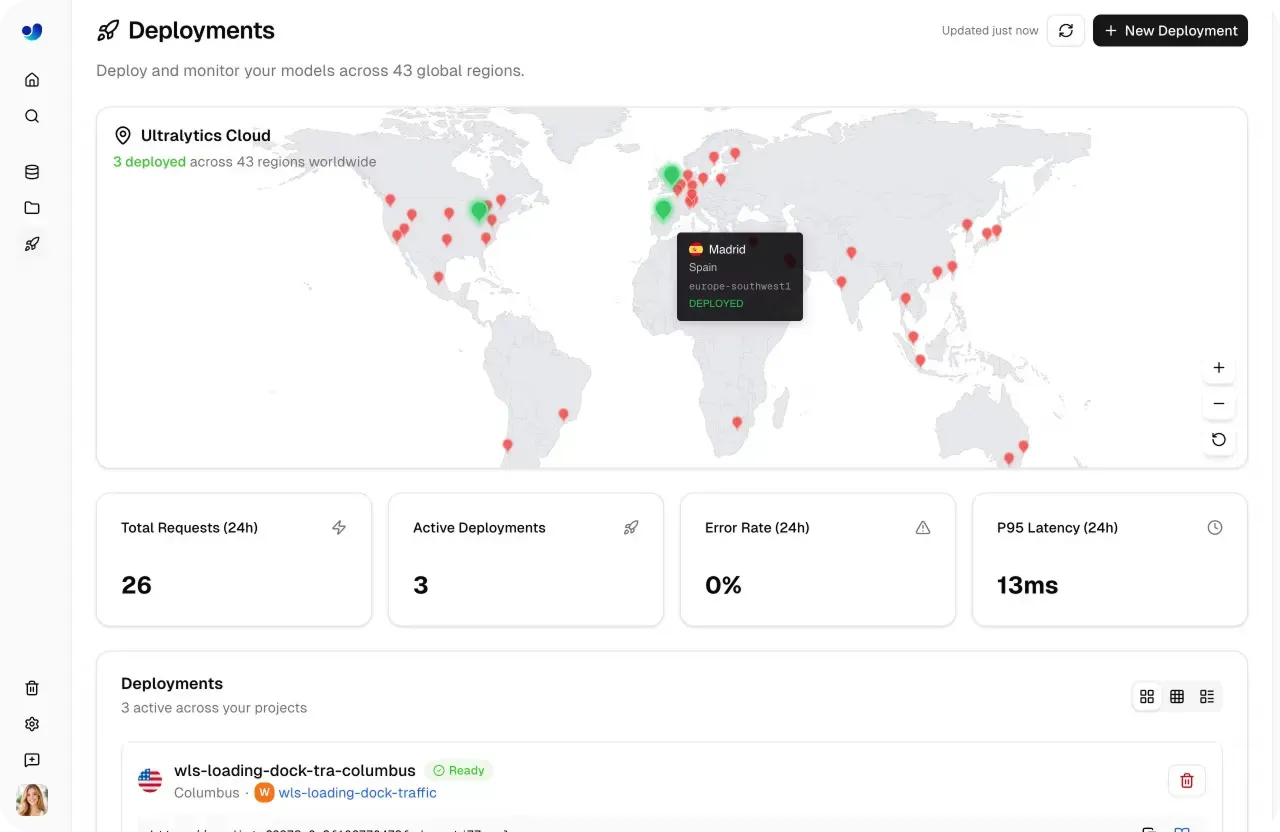
図5. Ultralytics Platformはデプロイ済みモデルの監視を容易にします。 (ソース)
各専用エンドポイントは、個別のデプロイビューを通じて詳細な可観測性も提供します。これには、ログ、モデルの健全性ステータス、リアルタイムのパフォーマンスデータへのアクセスが含まれます。ログは、問題をデバッグし、失敗したリクエストを追跡し、依存関係やインフラストラクチャに関連する潜在的な問題を特定するために使用できます。
本番環境が進化するにつれて、入力データの変化、スケーリングの需要、あるいは利用パターンの変動がモデルの精度や堅牢性に影響を与える可能性があります。パフォーマンスメトリクスを継続的に監視することで、チームは異常を検出し、ボトルネックを特定し、一貫した信頼性の高いモデルサービングを維持するためのモデル最適化やリソース調整といった是正措置を講じることができます。
Link to this sectionコンピュータビジョンモデルのデプロイへのスケーラビリティの構築#
コンピュータビジョンシステムをスケーリングすることは、伝統的には、本来統合されるようには設計されていないワークフローやフレームワークを継ぎ合わせることを意味していました。データパイプライン、トレーニングループ、デプロイインフラストラクチャ、および監視システムは、多くの場合別々の場所に存在し、あらゆる段階で摩擦を生んでいました。
真の課題は単にモデルを構築することではなく、それらを動かし続けることにあります。データから本番環境へ移行し、新しい入力に適応し、増大する需要を処理し、速度を落とすことなく継続的に改善していくことが求められます。
Ultralytics Platformが際立っているのは、この動きが組み込まれているという点です。各段階を別々のステップとして扱うのではなく、同じ環境内でモデルを開発、デプロイ、監視、更新できる連続的なループに接続します。
その変化はチームのスケーリング方法を変えます。それはツールやインフラストラクチャのオーケストレーションについてではなく、システムが成長するにつれて勢いを維持することについてです。
Link to this section重要なポイント#
コンピュータビジョンモデルのような機械学習モデルを実世界のアプリケーションに導入するには、それらが信頼性が高く、スケーラブルで、管理しやすいものである必要があります。Ultralytics Platformは、モデルサービング、デプロイ、監視といったさまざまな機能を一つの統一された環境にまとめることで、このプロセスを簡素化します。柔軟なデプロイオプションと組み込みツールにより、チームはより迅速かつ少ない複雑さで、実験から本番環境へと移行できます。
詳細については、コミュニティをチェックし、GitHubリポジトリをご覧ください。AI in healthcareやcomputer vision in logisticsなどの多様なアプリケーションを確認するには、ソリューションページをご覧ください。ライセンスオプションを確認して、今すぐ構築を始めましょう!






