OpenAI o1:AI推論のための新しいOpenAIモデルシリーズ
新しく発表されたOpenAI o1モデルについて、その特長をご紹介します。また、その仕組みとAIの未来への影響についても考察します。

AIコミュニティでは、OpenAIのGPTモデルの次なるステップについて、「プロジェクト・ストロベリー(Project Strawberry)」などと呼ばれ、多くの憶測が飛び交っていました。その理由は、GPT-4oに対して、「strawberry」という単語の中に「r」がいくつあるか尋ねると、その単語には「r」が2つあると答えてしまうためです。strawberryという単語には実際には3つあるにもかかわらずです。GPT-4oがこれほど強力であることを考えると不思議に思えるかもしれません。しかし、このモデルは正確な文字数ではなく、サブテキスト(文脈)を処理するように構築されています。次世代モデルはこの問題を解決することを目指すと噂されていました。Sam Altman氏は、自身のX(旧Twitter)アカウントにイチゴの写真を投稿することで、これらの噂をさらに煽りました。
9月12日木曜日に発表されたOpenAIの最新の発表により、ついにその憶測に対する答えが得られました!応答する前に一度立ち止まって思考するように設計された新しいAIモデルシリーズ、OpenAI o1がリリースされました。興味深いことに、OpenAI o1はより優れた推論能力を備えており、イチゴに関する質問にも正しく答えることができます!この記事では、OpenAI o1とは何か、どのように機能するのか、どこで使用できるのか、そしてそれがAIの未来にとって何を意味するのかについて説明します。それでは始めましょう!
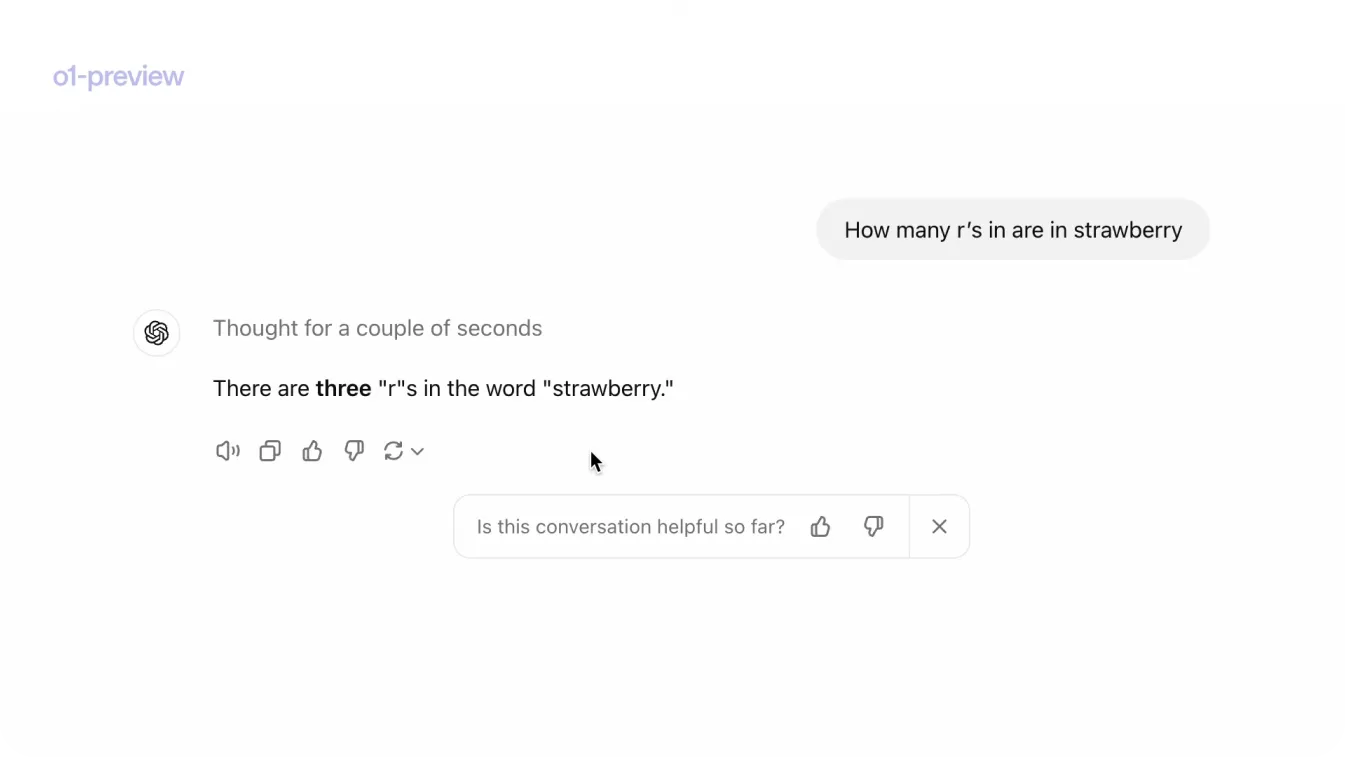
図1 OpenAI o1にイチゴについて尋ねた例。
Link to this sectionOpenAIによるAIの新しい進歩#
2024年7月、OpenAIの幹部は、OpenAIの研究がレベル2のAIと呼ばれる人間レベルの問題解決能力に近づいていると共有しました。OpenAIが新しいモデルシリーズであるOpenAI o1を「回答前に思考する」ものとして紹介していることからも、このレベルが推論に焦点を当てていることは明らかです。OpenAI o1は、新しいLLM(大規模言語モデル)であり、膨大な言語データからパターンを学習することで、人間のようなテキストを理解し生成するAIモデルです。深い推論を必要とする複雑な問題を処理するように設計されています。
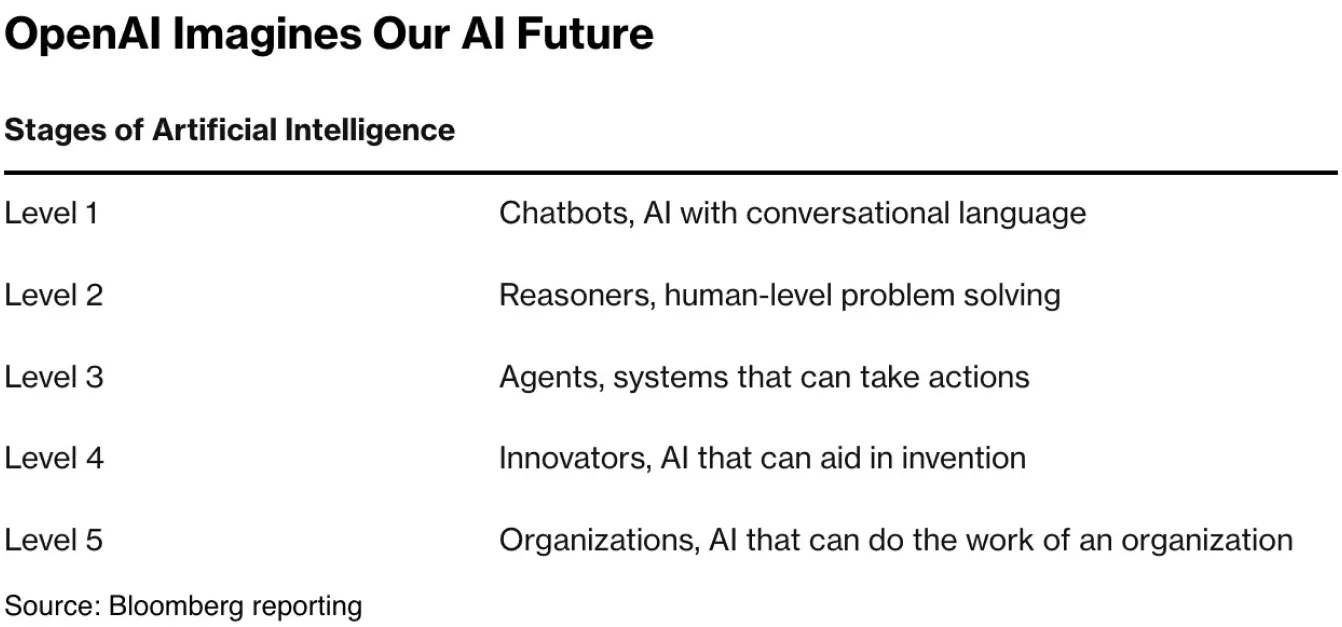
図2 AIの段階に関するOpenAIの視点。
The model has been trained using reinforcement learning, a technique where the model learns to make better decisions through trial and error by receiving rewards or penalties for its actions. The reinforcement learning algorithm helps the model think more effectively by following a chain of thought. OpenAI also shared that o1’s performance keeps improving with more reinforcement learning during training and with more time spent "thinking" during problem-solving, showing that both extended training and thoughtful processing help boost the model's abilities.
OpenAI o1は複雑な推論において重要な進歩ですが、まだ初期段階のモデルであり、ウェブブラウジングやファイル・画像のアップロードなど、ChatGPTを便利にするいくつかの機能が欠けています。多くの一般的なタスクにおいては、現時点ではGPT-4oの方が能力が高いかもしれません。しかし、OpenAI o1はAIが複雑な推論を処理する能力において大きな一歩前進を示すものであり、そのためOpenAIは新シリーズとしてOpenAI o1を打ち出しました。
Link to this section新しいOpenAIモデルがAIの推論を強化する方法#
OpenAI o1は、暗号の解読、プログラミング課題の解決、数学問題の回答、クロスワードへの挑戦、さらには科学、安全、医療といった複雑なトピックの取り扱いなどのタスクに使用できます。プロジェクトのコードネームへの楽しい言及として、OpenAIは「THERE ARE THREE R’S IN STRAWBERRY(ストロベリーにはRが3つある)」というメッセージを明らかにする暗号を解くことで、モデルの推論スキルを実演しました。
暗号解読にとどまらず、OpenAI o1はコーディングにも長けています。プログラマーが時間制限の中で複雑なコーディング問題を解くプラットフォームであるCodeforcesのような競技プログラミングの課題で優れたパフォーマンスを発揮します。これらの課題において、同モデルは高いEloレーティング(他の競技者に対するパフォーマンスに基づいてスキルレベルを測定するスコアリングシステム)を達成し、以前のモデルを上回ります。また、数学においても優れており、American Invitational Mathematics Examination (AIME) のような試験でも優れた結果を残しています。
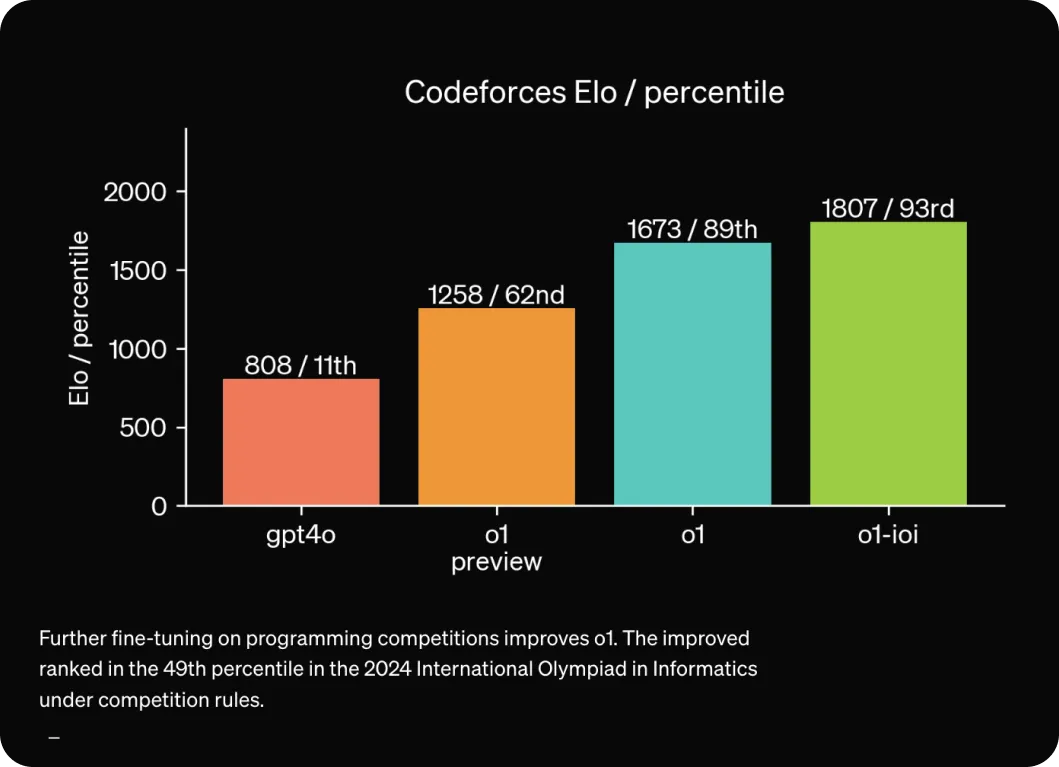
図3 o1のコーディング能力のベンチマーク。
これらの進歩により、OpenAI o1はGPT-4oのような以前のモデルからの重要なアップグレードとして位置付けられています。これはビジネス、開発、研究、医療といった分野でのAIの新しい可能性を切り拓きます。例えば、遺伝学研究において、OpenAI o1は膨大な数の研究論文を迅速に精査し、主要な知見や遺伝的マーカーと疾患の関連性を特定することができます。複雑な科学用語を理解して重要なポイントを要約できるため、研究者が最も関連性の高い情報に集中する手助けをします。
Link to this section思考の連鎖の深掘り#
We saw earlier that OpenAI o1 introduces a "Chain of Thought" reasoning process. It enables the model to tackle complex problems in a manner similar to human cognitive strategies. The model can break down challenges into smaller, manageable steps and iteratively refine its approach. Unlike earlier models that relied on immediate pattern recognition, o1 optimizes its decision-making by exploring multiple reasoning paths, learning from both successes and mistakes through reinforcement learning.
OpenAIは、これらの生の思考の連鎖をユーザーから隠し、すべてのステップを公開することなく、モデルの推論に関する洞察を提供する要約を提供することを選択しました。この決定は、モデルの思考プロセスの悪用を防ぐと同時に、開発者がAIの安全性とアライメントを監視・調整できるようにするためのものです。開発者は内部の隠れた連鎖を観察することで、o1が倫理的ガイドラインを遵守し、有害な行動を避けていることを確認できます。
Link to this sectionOpenAI o1のベンチマーク#
OpenAI o1は、推論と問題解決能力をテストするいくつかのベンチマークにおいて、GPT-4oに対して大きな改善を示しています。トップクラスの高校生向けの難関数学試験であるAmerican Invitational Mathematics Examination (AIME) 2024では、o1は問題あたり1つのサンプルで74%の正答率を達成し、GPT-4oの12%と比較して大幅に向上しました。64のサンプルにわたるコンセンサスでは正答率は83%に上昇し、1,000のサンプルを使用した洗練された再ランキング手法を用いると93%に達し、全米のトップ500人の学生に匹敵する結果となりました。
数学以外でも、o1は化学、物理学、生物学の博士レベルの問題をカバーするGPQA Diamondなど、科学知識をテストするベンチマークでも非常に優れたパフォーマンスを発揮しました。驚くべきことに、o1はこのテストで博士号を持つ人間の専門家を上回り、AIモデルとして初めてこれを達成しました。また、歴史、法律、科学など、多様な科目にわたる理解力をテストするMMLUベンチマークの57カテゴリー中54カテゴリーでGPT-4oを上回りました。
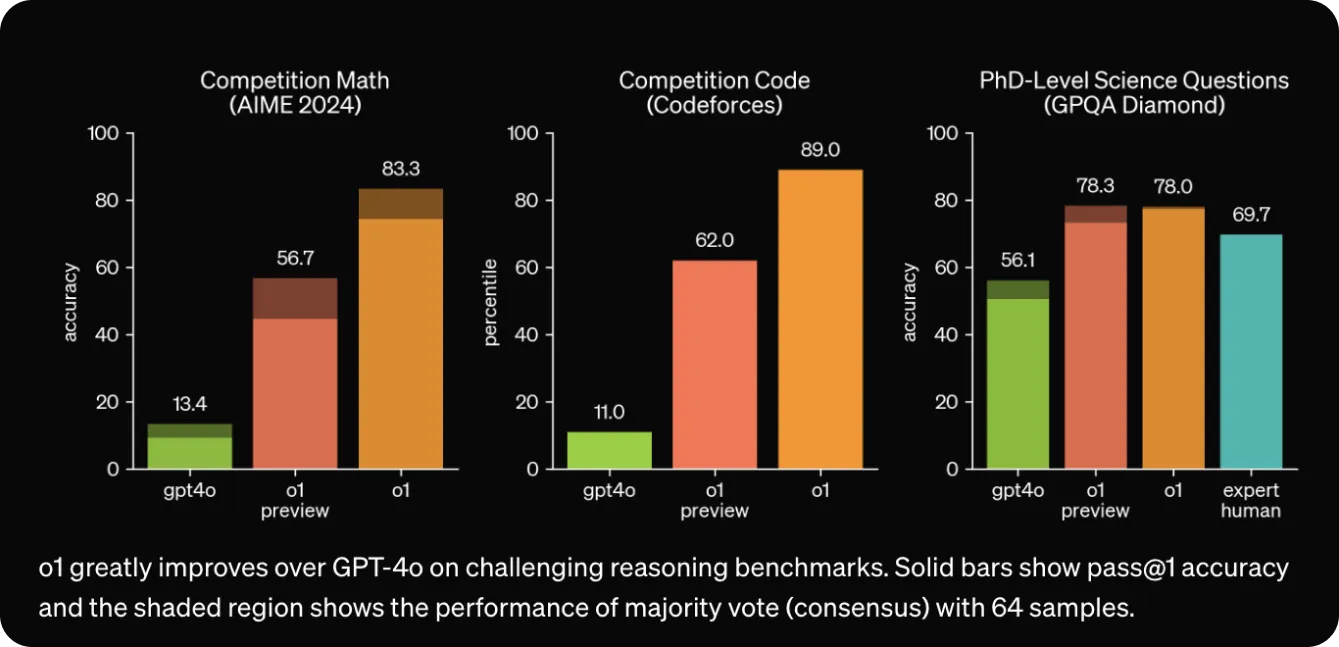
図4 OpenAI o1のベンチマーク。
Link to this sectionOpenAI o1を実際に体験する#
OpenAIは、o1シリーズで2つの新しいAIモデル、o1-previewとo1-miniを導入しました。o1-previewモデルは、応答する前により深く思考するように設計されており、科学、コーディング、数学における複雑な推論タスクに優れています。困難なプロジェクトに取り組むユーザーに対して、高度な問題解決能力を提供します。対照的に、o1-miniはより小型で高速かつ費用対効果の高いモデルで、STEM推論、特に数学とコーディングに特化して最適化されています。世界に関する幅広い知識は少ないかもしれませんが、o1-miniはAIME数学コンペティションやCodeforcesのコーディング課題などの主要な評価において、o1-previewのパフォーマンスにほぼ匹敵し、コストは80%削減されています。
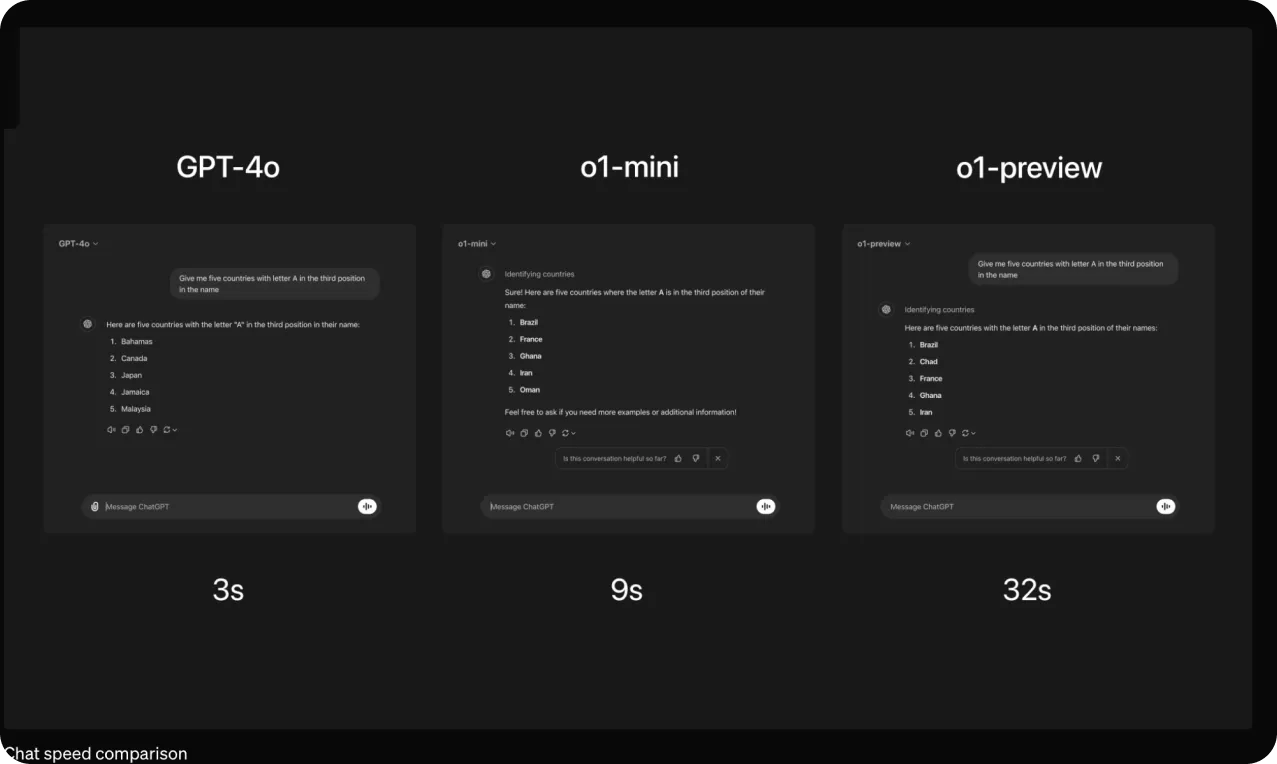
図5 OpenAIモデルの比較。
これらのモデルは、さまざまなOpenAIプラットフォームを通じて試すことができます。ChatGPT PlusおよびTeamのユーザーは、モデルピッカーからo1-previewとo1-miniの両方にアクセスし、ChatGPT内で直接、強化された推論能力を体験できます。API利用ティア5にアクセスできる開発者は、これらのモデルでプロトタイピングを開始できますが、一部の高度な機能はまだ開発中です。OpenAIはまた、o1-miniをすべてのChatGPT Freeユーザーにも間もなく提供する予定です。これらのモデルを探求することで、AI推論の進歩を直接体験し、ニーズに最も合ったモデルを選択することができます。
Link to this sectionOpenAIが行う倫理的なAIへの配慮#
OpenAIは、o1モデルシリーズの開発において倫理と安全性に重点を置いてきました。o1-previewおよびo1-miniモデルをリリースする前に、外部テストや、許可されていないコンテンツ、ハルシネーション(幻覚)、バイアスなどのリスクに対する内部チェックを含む徹底的な評価を実施しました。モデルは安全ルールをよりよく理解し従うために、高度な推論能力を備えるように設計されています。
OpenAIは、リスクを管理するためにブロックリストや安全分類器などのセーフガードも実装しています。o1モデルの全体的なリスク評価は中程度です。サイバーセキュリティやモデルの自律性などの分野では低リスクであり、CBRN(化学、生物、放射線、核)コンテンツや説得などの分野では中程度のリスクがあります。OpenAIの安全諮問グループと取締役会は、モデルが安全かつ倫理的に使用されることを保証するために、これらの安全対策をレビューしました。
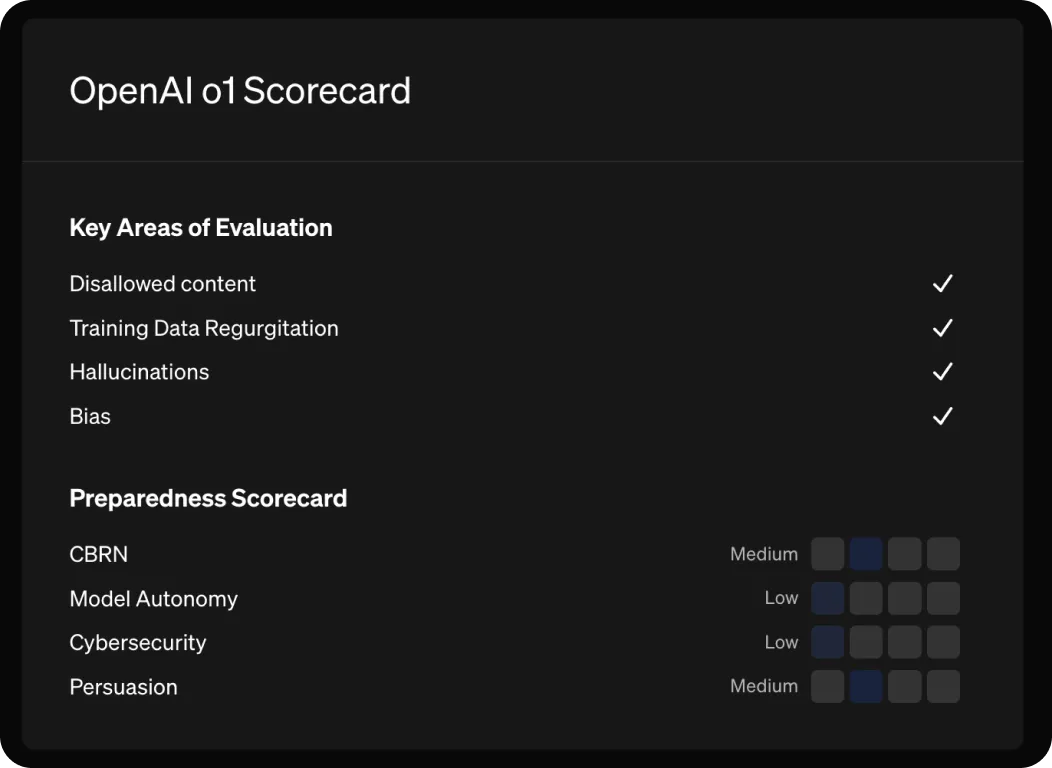
図6 OpenAI o1スコアカード。
Link to this section噂から現実へ:OpenAI o1の登場#
OpenAI o1はAI推論における大きな前進であり、初期の噂の一部を現実に変えました。GPT-4oとは異なり、o1シリーズは「思考の連鎖」アプローチを使用することで、より深く思考し、複雑な問題をより小さなステップに分解してより良い回答を導き出します。現在、ChatGPTとAPIで早期プレビューとして利用可能であり、OpenAIはウェブブラウジングやファイル・画像のアップロードなどの機能を追加する予定です。また、OpenAIは新しいOpenAI o1シリーズに加えて、GPTシリーズのモデルの開発とリリースを継続する意向も共有しました。AIが進化し続ける中で、このような進歩は、人間のニーズをより深く理解しサポートできる、より強力で直感的かつ多機能なAIシステムへの道を切り拓いています。
私たちのコミュニティに参加して、AIの最新情報を入手しましょう!GitHubリポジトリにアクセスして、製造業や医療などの分野で私たちがどのようにAIソリューションの先駆者となっているかをご確認ください。🚀






