Ultralytics PlatformでYOLOモデルの学習を高速化する
データからデプロイへの道のりを加速するために構築されたエンドツーエンド環境であるUltralytics Platformを使って、YOLOモデルをより高速に学習させる方法を見つけましょう。
先週、Ultralyticsは、チームがコンピュータビジョンモデルを構築、トレーニング、デプロイする方法を簡素化するために設計された統合ワークスペースであるUltralytics Platformを発表しました。複数のツールを使い分けるのではなく、このプラットフォームにすべてが集約されます。ビジョンAIモデルのアイデア出しからデプロイまでを、手間なく行えるようになります。
コンピュータビジョンは急速にさまざまな業界の中核的な部分となっており、これは極めて重要です。製造現場での検査、小売分析、自律走行ナビゲーションなどのアプリケーションを支えています。
これらのビジョン対応アプリケーションを信頼性の高いシステムに変えるには、モデルのトレーニングがいかに適切に行われるかが鍵となります。モデルのトレーニングには、ラベル付きデータからの学習が含まれ、それによってモデルはパターンを認識し、正確な予測を行えるようになります。一般的に、トレーニング済みのモデルは、モデルのパフォーマンスを向上させ、実世界のアプリケーションにおいてより信頼性の高い結果をもたらします。
しかし、コンピュータビジョンモデルのトレーニングは、常に単純とは限りません。環境のセットアップ、適切なコンピューティングリソースの選択、ハイパーパラメータの調整、複数のトレーニング実験の追跡など、さまざまな側面から構成されます。これらのステップが異なるツールやシステムに分散していると、トレーニングのワークフローはすぐに複雑化し、管理が困難になります。
Ultralytics Platformは、トレーニングプロセス全体を単一の統合ダッシュボードにまとめることで、この問題を解決します。クラウド、ローカル、Google Colabのいずれで作業していても、トレーニングジョブの設定、実行、監視を1箇所で行うことができます。
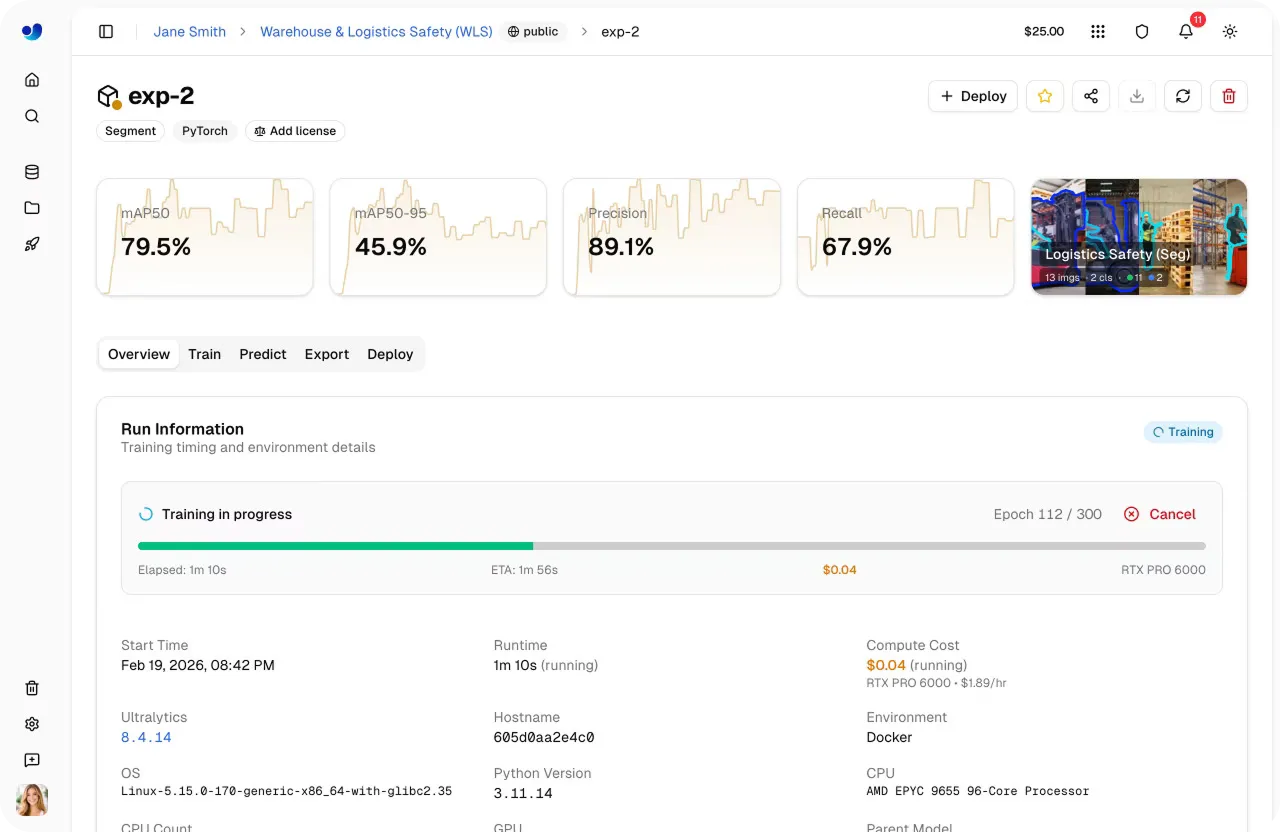
図1:Ultralytics Platformでのモデルトレーニングの様子 (ソース)
この記事では、Ultralytics Platformがどのようにモデルトレーニングを効率化し、なぜビジョンAIプロジェクトで優位性をもたらすのかを解説します。それでは始めましょう!
Link to this sectionコンピュータビジョンモデルは、モデルトレーニングを通じてデータから学習します#
Ultralytics Platformでのモデルトレーニングの仕組みについて詳しく説明する前に、まず一歩下がって、モデルトレーニングとは何か、そして何が必要なのかを確認しましょう。
モデルトレーニングとは、コンピュータビジョンモデルが視覚データを解釈することを学習するプロセスです。画像やビデオを分析し、内部パラメータを段階的に調整することで、物体検出、画像分類、インスタンスセグメンテーションといったビジョンタスクを正確に実行できるようになります。時間が経つにつれて、モデルは目にするデータから直接パターンを学習することで改善されていきます。
トレーニングの品質はデータセットに大きく依存します。データセットは、教師が生徒を訓練するために使用するフラッシュカードのセットのようなものだと考えるとよいでしょう。それぞれの例が、モデルが何を探すべきかを学習する助けとなります。
典型的なコンピュータビジョンデータセットには、通常JPGやPNGなどの形式の画像と、各画像の内容を説明するアノテーションが含まれます。多くの場合JSONやTXTファイルとして保存されるこれらのアノテーションは、モデルが効果的に学習するために必要なラベルとコンテキストを提供します。
しかし、トレーニングは単にデータをモデルに供給するだけではありません。データセットの準備から、適切なモデルの選択、トレーニングプロセスの設定まで、いくつかの重要なステップが含まれます。次に、これらのステップの一部を詳しく見ていきましょう。
Link to this sectionデータセットの準備方法についての解説#
データセットがあればすぐにモデルのトレーニングを開始できると思われがちですが、実際にはデータセットの分割など、最初に行うべきステップがいくつかあります。
一般的に、データセットはトレーニングセット、検証セット、テストセットの3つに分割されます。トレーニング画像はモデルにデータ内のパターンを教えるために使用され、検証セットはトレーニング中のパフォーマンスを監視および微調整するのに役立ちます。
テストセットは、モデルが完全に未知の新しいデータに対してどの程度機能するかを評価するために最後に使用されます。この設定により、モデルがデータを丸暗記するだけでなく、現実世界のシナリオに汎用できることを確認するのに役立ちます。
Link to this sectionトレーニングに適したモデルの選択#
トレーニング前のもう一つの重要なステップは、使用するモデルを選ぶことです。多くの場合、これは事前トレーニング済みのモデルを選択することを意味します。Ultralytics YOLOモデルのようなモデルは、大規模なデータセットで既にトレーニングされており、一般的な視覚パターンを学習済みであるため、強力な出発点となります。
これらのモデルの使用は、既存の知識をベースにして特定のタスクにモデルを適応させる「転移学習」の一例です。このアプローチは、トレーニングのスピードアップと結果の向上に寄与し、特にデータが限られている場合に有効です。
また、これらのモデルにはさまざまなサイズがあり、それぞれが速度と精度のトレードオフを提供します。小さいモデルはより高速で効率的ですが、大きいモデルは精度が高い傾向にあるものの、より多くのコンピューティングリソースを必要とします。
Link to this sectionビジョンモデルのトレーニングパラメータの設定#
準備されたデータセットとモデルを選択したら、次のステップはモデルがどのように学習するかを設定することです。
コンピュータビジョンモデルは、データをどのように処理し、重みを更新し、時間の経過とともに改善していくかを決定する一連のパラメータを使用してトレーニングされます。これらの設定はトレーニング速度と最終的な精度の両方に直接影響するため、優れた結果を達成するために不可欠です。
一般的に使用されるトレーニングパラメータをいくつか紹介します。
- Epochs(エポック数): トレーニング中にモデルがデータセット全体を何回通過するかを表します。エポック数を増やすことで、モデルがデータからパターンを学習する機会が増えます。
- Batch size(バッチサイズ): 1回のトレーニングステップで一緒に処理される画像の数です。バッチサイズを大きくするとトレーニングを高速化できますが、より多くのメモリが必要になります。
- Image size(画像サイズ): トレーニング中に使用される入力画像の解像度を指定します。解像度を高くすると検出精度が向上する可能性がありますが、計算コストも増加します。
- Learning rate(学習率): トレーニング中にモデルが内部パラメータを更新する速度です。値が高すぎたり低すぎたりすると、トレーニングが不安定になる可能性があります。
- Optimizer(オプティマイザー): 各トレーニング反復中に計算された誤差に基づいて、モデルのパラメータを更新する役割を担うアルゴリズムです。
Ultralytics YOLOベースのワークフローでは、これらの設定は通常YAMLファイルで定義されます。このファイルはデータセットのパス、クラス名、データの分割方法を指定します。モデルにデータセットの解釈方法を指示する中心的な設定ファイルとして機能します。
Link to this section断片化されたワークフローからUltralytics Platformによる統合体験へ#
データセットの準備からモデルの選択、トレーニングパラメータの設定まで、コンピュータビジョンモデルのトレーニングに必要な主要なステップについて説明しました。実際には、実験の追跡、複数のトレーニング実行の比較、モデルの継続的な改善など、プロセスはさらに続くことが一般的です。
これらのステップが1箇所で管理されることはほとんどありません。データセットは一つのツールで準備し、トレーニング実行は別の環境で行い、実験の追跡は別々に管理されるといったことがよくあります。プロジェクトが成長するにつれて、この断片化により複雑さが増し、反復スピードが低下し、全体を整理することが困難になります。
Ultralytics Platformは、トレーニングワークフロー全体を単一の環境に統合することで、この複雑さを解消します。ツールを切り替える必要はなく、1箇所でデータセットの管理、トレーニングの設定、実験の実行、結果の監視を行うことができます。
次に、Ultralytics Platformがどのようにモデルトレーニングをよりスマートにするかを見ていきましょう。
Link to this sectionUltralytics Platformでサポートされているトレーニングオプション#
実世界のアプリケーションにおいて、コンピュータビジョンモデルのトレーニングには多くの場合柔軟な環境が必要です。データセットのサイズ、モデルの複雑さ、および利用可能なハードウェアに応じて、クラウド、ローカルマシン、または外部のノートブック環境でトレーニングを実行することを選択できます。
Ultralytics Platformは、これらのニーズに応えるために以下のトレーニングオプションをサポートしています。
- Cloud training(クラウドトレーニング): トレーニングはUltralyticsが管理するクラウドGPU上で実行されます。このオプションは、大規模なデータセットや、多大なコンピューティングリソースを必要とする複雑なモデルに最適です。
- Local training(ローカルトレーニング): このオプションは手元のマシンのハードウェアを使用し、クイックな実験、設定のテスト、または小規模なデータセットでの作業に最適です。よりスケーラブルなワークロードが必要な場合は、AWSやGCPなどの自身のクラウド環境でトレーニングを実行することもできます。
- Google Colab: Ultralytics Platformを使用すると、Google Colabのホスト型ノートブック環境でトレーニングを実行でき、ローカルマシンを設定することなく、柔軟なブラウザベースのワークフローを実現できます。
Link to this sectionUltralytics Platformでのクラウドトレーニングの探索#
コンピュータビジョンプロジェクトにおいて、モデルをローカルやノートブック環境でトレーニングすることは必ずしも簡単ではありません。
例えば、ローカルトレーニングではパフォーマンスが完全に手元のハードウェアに依存するため、計算能力が制限され、実験が遅くなる可能性があります。効率的なトレーニングにはGPUが不可欠ですが、すべてのセットアップでGPUに確実にアクセスできるわけではありません。
Google Colabのようなノートブック環境は、クラウドベースのGPUを提供することで代替案となりますが、セッションは一時的であることが多く、長時間のトレーニング実行が中断される可能性があります。データセットが拡大し、ワークフローが複雑になるにつれて、これらの制限はすぐにボトルネックとなり、トレーニングが遅く、信頼性が低くなる可能性があります。
Ultralytics Platformは、そのクラウドトレーニングオプションでこれに対処します。Pythonの依存関係やPyTorchなどのフレームワークが事前に設定されたすぐに使える環境を提供し、追加の設定なしでトレーニングを開始できます。
単一のダッシュボードから、トレーニングジョブを開始し、進行状況をリアルタイムで監視できます。これにより、インフラストラクチャの管理ではなく、モデルの改善に集中しやすくなります。
それでは、Ultralytics Platformでクラウドトレーニングを始める方法を見ていきましょう。
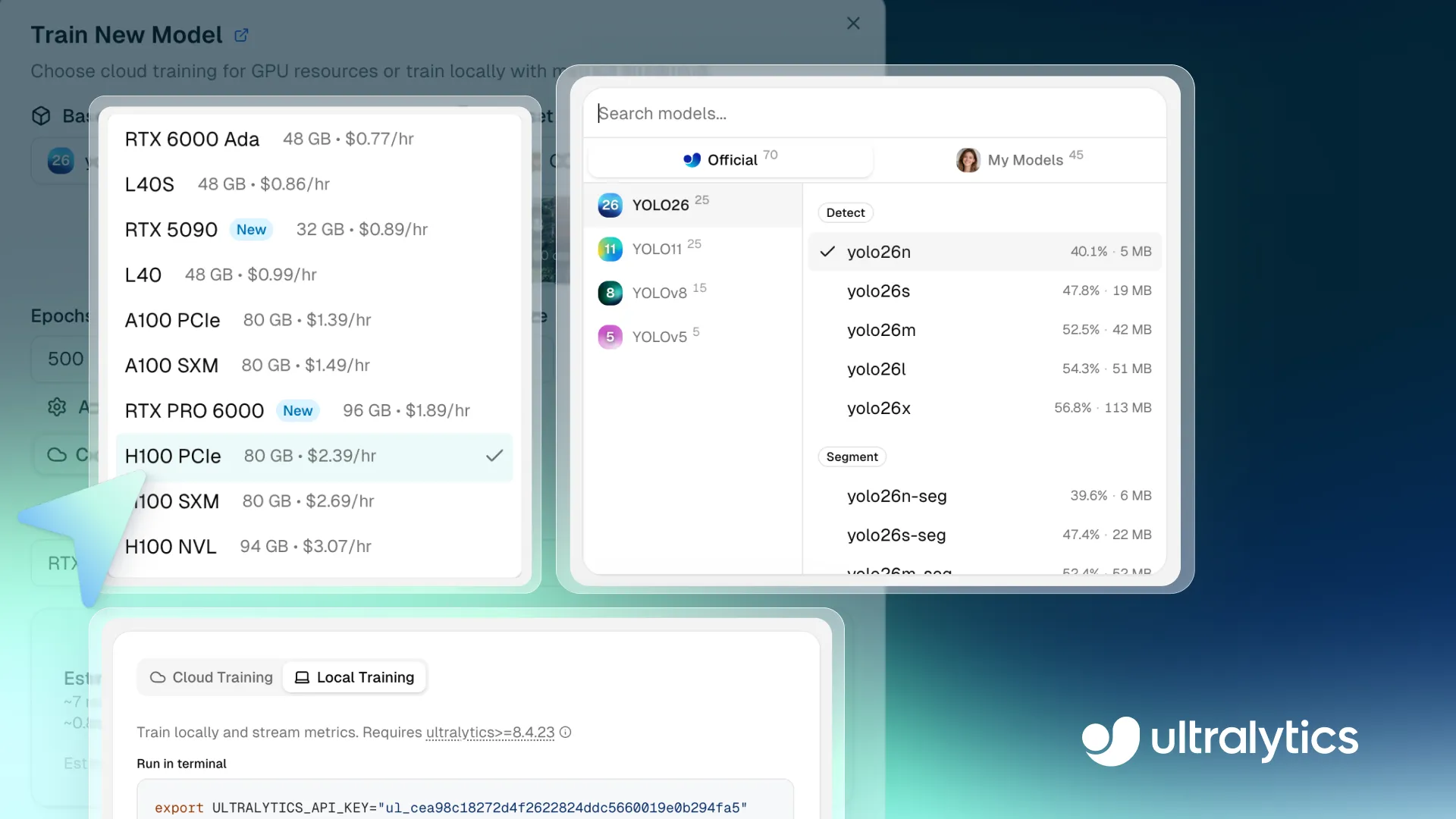
Link to this sectionステップ1:ベースモデルを選択する#
最初のステップは、トレーニング実行のためのベースモデルを選ぶことです。事前トレーニング済みのUltralytics YOLOモデルを選択したり、コミュニティモデルをクローンしたり、独自の事前トレーニング済み重みをアップロードしてカスタム要件を満たしたりできます。
このプラットフォームは、すべてのUltralytics YOLOモデルをサポートしています。これにはUltralytics YOLO26、Ultralytics YOLO11、Ultralytics YOLOv8、Ultralytics YOLOv5が含まれ、それぞれナノ(n)、スモール(s)、ミディアム(m)、ラージ(l)、エキストララージ(x)などの異なるサイズバリエーションが利用可能です。異なるモデルバリエーションが速度と精度の間で異なるバランスを提供するので、パフォーマンスと計算要件に適合するモデルを選択できます。
これらのモデルは、Ultralytics YOLOユーザーにおなじみの幅広いコンピュータビジョンタスクをサポートしており、物体検出、インスタンスセグメンテーション、画像分類、指向性バウンディングボックス(OBB)検出、姿勢推定などがあります。
カスタム要件がある場合は、独自の事前トレーニング済みモデルの重みをアップロードすることもできます。これは、ゼロから始めるのではなく、プラットフォーム内で既存のモデルを継続してトレーニングしたり、ファインチューニングしたりできることを意味します。他の場所で既にモデルをトレーニング済みの場合や、より具体的なユースケースにモデルを適応させたい場合に特に便利です。
Link to this sectionステップ2:データセットを選択する#
次のステップは、トレーニング用のデータセットを選択することです。Ultralytics Platformでは、COCOデータセットなどの既存のデータセットを使用したり、コミュニティからデータセットをクローンしたり、特定のアプリケーションに合わせてカスタマイズした独自のデータセットをアップロードしたりできます。
プラットフォームはUltralytics YOLOやCOCOなどの一般的なアノテーション形式をサポートしており、プラットフォーム上で直接カスタムデータにアノテーションを付ける予定であれば、生の画像アップロードにも対応しています。
アップロードされたデータセットは、検証、正規化、ラベル解析、統計生成を含めて自動的に処理されます。これにより、クラス分布やデータセット構造など、データの内容を一目で把握でき、すべてがトレーニングの準備ができていることを確認できます。
データセットはトレーニング実行にも自動的にリンクされるため、各モデルにどのデータが使用されたかを追跡し、実験全体で一貫性を保つことができます。
Link to this sectionステップ3:トレーニングパラメータを設定する#
データセットを選択した後、モデルがどのように学習するかを制御するトレーニングパラメータを設定できます。これにはエポック数、バッチサイズ、画像サイズ、トレーニングログ用の実行名などが含まれます。これらのパラメータの多くは、トレーニング時間とモデルの最終的なパフォーマンスの両方に影響します。
より制御されたトレーニングのために、プラットフォームでは学習率、オプティマイザータイプ、色拡張設定、その他のトレーニングオプションなどの詳細パラメータを調整することもできます。これらの設定により、トレーニングプロセスを微調整してモデルの精度と安定性を向上させることができます。
Link to this sectionステップ4:GPUを選択する#
次に、トレーニング実行のためのGPU設定を選択できます。適切なGPUを選択することは、データセットサイズ、バッチサイズ、画像解像度、モデルの複雑さといった要因に依存します。適切なバランスを見つけることで、必要以上の計算リソースを使わずにトレーニングを効率的に保つことができます。
Ultralytics Platformでは、異なるVRAM(GPUメモリ)と計算能力を持つ22種類のGPUオプションを提供しており、小さなタスクから大規模なワークロードまでをサポートします。
これを利用することで、軽量モデルのトレーニングであれ、大規模で複雑なデータセットの処理であれ、特定のニーズにハードウェアを合わせることができます。詳細については、UltralyticsのPlatformトレーニングドキュメントページで利用可能なGPUのリストを確認してください。
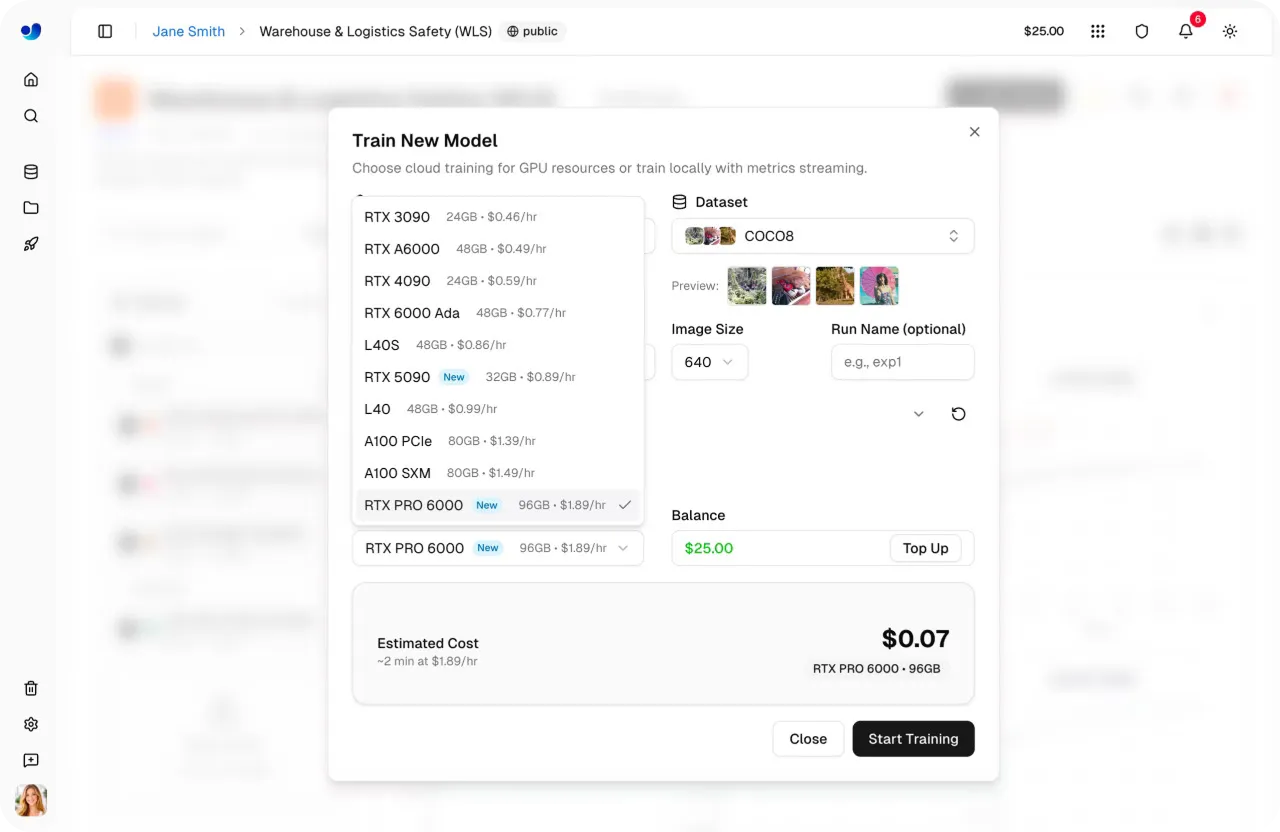
図2:Ultralytics Platformで利用可能な一部のGPUオプション (ソース)
Link to this sectionステップ5:クラウドトレーニングを開始する#
モデル、データセット、トレーニングパラメータ、計算オプションを選択したら、トレーニング実行の開始は迅速です。ダッシュボードからワンクリックでトレーニングを開始でき、あとはプラットフォームが環境を初期化して選択したGPUでジョブを実行してくれます。
トレーニングが開始されると、プラットフォーム内で直接進行状況を監視できます。「Train(トレーニング)」タブでは、パフォーマンス指標、損失曲線、システム使用状況、ライブトレーニングログなどの重要な指標をリアルタイムで確認できます。
Ultralytics PlatformでのローカルトレーニングやGoogle Colabの使用方法については、公式のUltralytics Platformドキュメント内の他のチュートリアルを参照してください。
Link to this sectionUltralytics Platformでのモデルの評価と比較#
トレーニングが完了したら、次のステップはモデルのパフォーマンスを評価することです。Ultralytics Platformでは、プロジェクト内の複数のトレーニング実行を比較でき、異なる実験がどのようなパフォーマンスを示しているかを明確に把握できます。
モデルを開発する際、結果を向上させるために学習率、バッチサイズ、モデルサイズなどの設定を変更しながら、トレーニングが何度も繰り返されることがよくあります。これらの実行のそれぞれが少しずつ異なるモデルを生成するため、それらを比較することが重要です。
プロジェクトは、モデルと実験が一緒に整理される中心的なハブとして機能します。異なるツールやビューを切り替えることなく、進行状況の追跡、結果のレビュー、作業への集中を維持できます。
この統合ビューから、精度(precision)、再現率(recall)、mAP(平均適合率)などの主要なパフォーマンス指標を分析し、モデルが異なるクラス間でどのように機能するかを理解できます。また、トレーニング実行を並べて比較し、どの設定が最高の結果をもたらすかを特定することも可能です。
これらの指標を補完するものとして、「Predict(予測)」タブを使用してサンプル画像やデータに対してトレーニング済みモデルを素早くテストし、視覚的にパフォーマンスを検証して潜在的な問題を特定するのに役立てることができます。
これらの知見をもとに、通常「best.pt」チェックポイントとして保存される最高性能のモデルを選択し、さらなる評価、推論への使用、あるいはプラットフォームを通じたモデルデプロイといった次のステージに進むことができます。
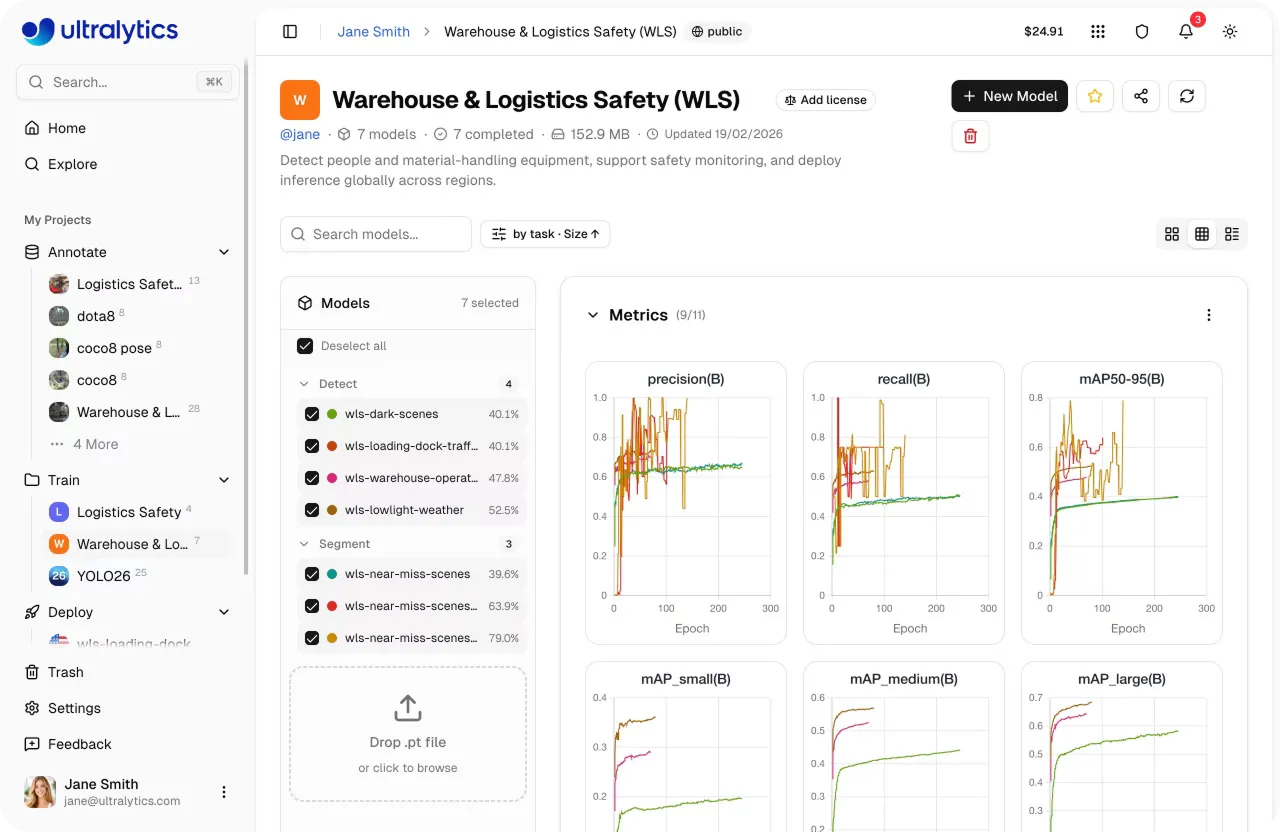
図3:Ultralytics Platformでの指標表示例 (ソース)
Link to this sectionUltralytics Platform内でのトレーニングコストの見積もり#
クラウドでの物体検出モデルのトレーニングには、特に高性能なGPUにアクセスする場合、計算コストが発生します。これをより便利にするため、Ultralytics Platformはトレーニング開始前にコストの見積もりを提供します。
予測される使用状況を明確に把握できるため、ワークロードの計画、予算の管理が可能になり、トレーニングジョブを開始する前に予期せぬ出費を避けることができます。トレーニング開始前に見積もりコストを確認する方法は以下の通りです。
Link to this sectionトレーニング時間の見積もり方法#
コストを正確に見積もるために、プラットフォームはまず1つのトレーニングエポックにかかる時間を計算します。これは、データセットサイズ、モデルサイズ、画像解像度、バッチサイズ、選択したGPUの速度などの要因に依存します。
これらの入力を使用して、1エポックあたりの推定時間を決定し、フルトレーニング実行にスケールアップします。総時間は、全エポックの合計時間にわずかなスタートアップオーバーヘッドを加えて計算されます。
オーバーヘッドには、環境の初期化、データセットの読み込み、GPUの準備などのタスクが含まれ、見積もりがトレーニングループだけでなく、トレーニングプロセス全体を反映するようにしています。
Link to this sectionトレーニングコストの計算方法#
トレーニングの総時間が推定されると、プラットフォームはそれを選択したGPUの時間単価を使用してコストに変換します。
トレーニング期間とGPU価格を組み合わせることで、実行開始前であっても、実行にどれくらいの費用がかかるかを明確に見積もることができます。
事前に把握できることで、トレーニングパラメータの調整や別のGPUの選択など、セットアップの変更が容易になり、パフォーマンスとコストをより効果的にバランスさせることができます。
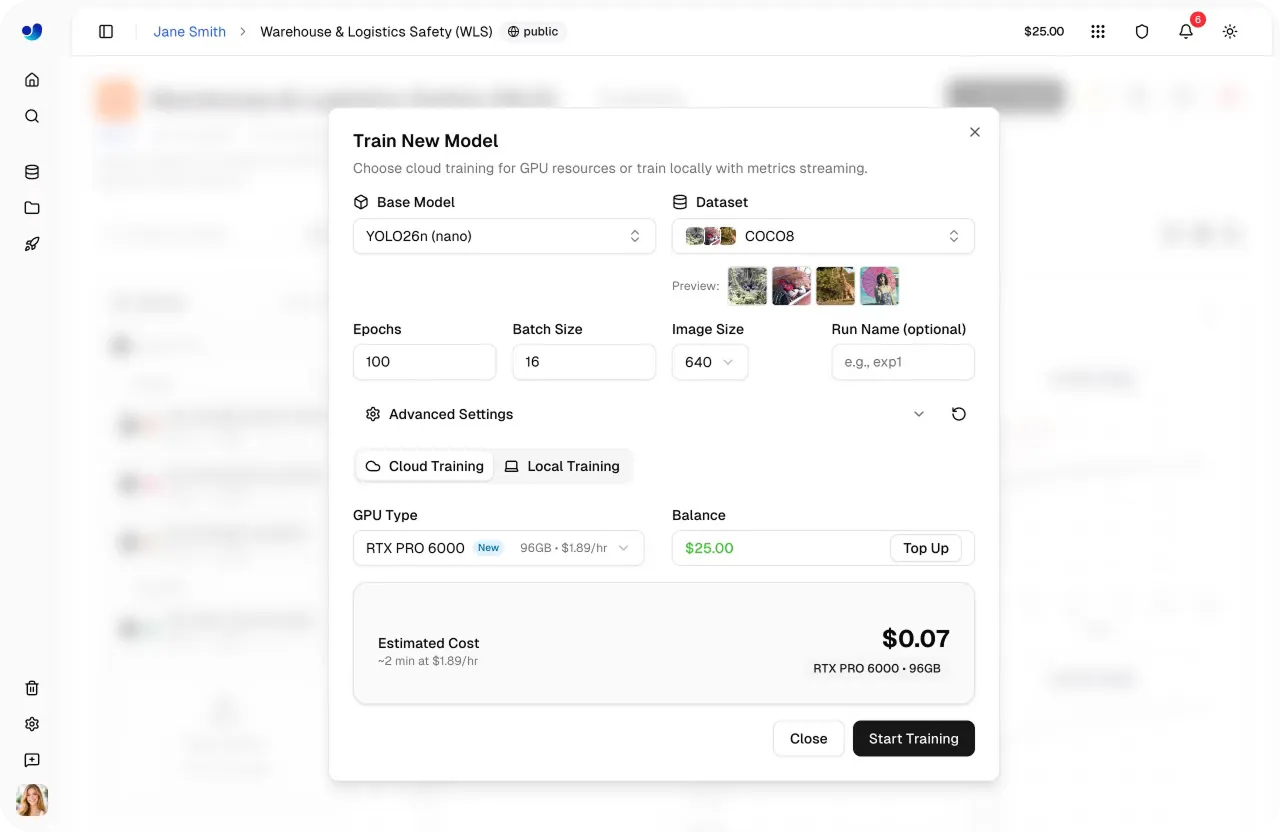
図4:Ultralytics Platform内でのモデルトレーニングの設定とコスト見積もり (ソース)
Link to this sectionUltralytics Platformをモデルトレーニングに使用する主な利点#
ここまで、コンピュータビジョンモデルのトレーニングに含まれる重要なステップと、それらがUltralytics Platform上でどのようにまとめられるかを説明してきました。
これらの主要機能以外にも、トレーニングワークフローを強化する追加機能があります。Ultralytics Platformをモデルトレーニングに使用する主な利点の概要を以下に示します。
- 組み込みの実験再現性: すべてのトレーニング実行は、モデル、データセット、パラメータ、コンピューティング設定を含む全構成とともに自動的にログ記録されます。これにより、実験を再検討したり、結果を確実に再現したりすることが容易になります。
- 時間の経過に伴うトレーニングの洞察: 最終的な結果を確認するだけでなく、エポックごとのパフォーマンスの推移を追跡できるため、トレーニング中のモデルの挙動をより深く理解するのに役立ちます。
- 運用オーバーヘッドの削減: 環境のセットアップ、依存関係の管理、インフラストラクチャをバックグラウンドで処理することで、セットアップに費やす時間を減らし、モデル開発により集中できるようになります。
- 実験の一元管理: プロジェクトはモデル、データセット、トレーニング実行を一元管理する場所として機能し、ワークフローが複雑化しても実験を構造化し続けることができます。
Link to this section重要なポイント#
トレーニングは機械学習モデルのライフサイクルにおいて最も重要な段階の1つです。これは、モデルが視覚データをどれほど正確に認識し、解釈できるかを決定します。
トレーニングデータの構成、監視、実験の比較、コストの見積もりを1つの環境に統合することで、Ultralytics Platformは高性能なコンピュータビジョンモデルを構築し、デプロイに向けて準備するプロセスを効率化します。
コンピュータービジョンについてさらに学ぶには、成長を続ける私たちのコミュニティやGitHubリポジトリをチェックしてください。ビジョンソリューションの構築を検討されている場合は、私たちのライセンスオプションをご覧ください。製造業におけるコンピュータービジョンや農業におけるAIの利点については、ソリューションページで詳細を確認できます。






