Una guía sobre la arquitectura U-Net y sus aplicaciones
Aprende sobre la arquitectura U-Net, cómo apoya la segmentación de imágenes, sus aplicaciones y por qué es importante en la evolución de la visión artificial.

La visión artificial es una rama de la inteligencia artificial (IA) que se centra en el análisis de datos visuales. Ha abierto el camino a muchos sistemas de vanguardia, como la automatización del proceso de inspección de productos en fábricas y la ayuda a los vehículos autónomos para navegar por las carreteras.
Una de las tareas de visión artificial más conocidas es la detección de objetos. Esta tarea permite a los modelos localizar e identificar objetos dentro de una imagen utilizando cuadros delimitadores (bounding boxes). Aunque los cuadros delimitadores son útiles para diversas aplicaciones, solo proporcionan una estimación aproximada de la ubicación de un objeto.
Sin embargo, en campos como la asistencia sanitaria, donde la precisión es crucial, los casos de uso de la IA de visión dependen de algo más que la mera identificación de un objeto. A menudo, también requieren información relacionada con la forma y la posición exactas de los objetos.
Eso es exactamente lo que hace la tarea de visión artificial llamada segmentación. En lugar de utilizar cuadros delimitadores, los modelos de segmentación detectan objetos a nivel de píxel. Con el paso de los años, los investigadores han desarrollado modelos de visión artificial especializados para la segmentación.
Uno de estos modelos es U-Net. Aunque modelos más nuevos y avanzados han superado su rendimiento, U-Net ocupa un lugar importante en la historia de la visión artificial. En este artículo, analizaremos más de cerca la arquitectura U-Net, cómo funciona, dónde se ha utilizado y cómo se compara con los modelos de segmentación más modernos disponibles hoy en día.
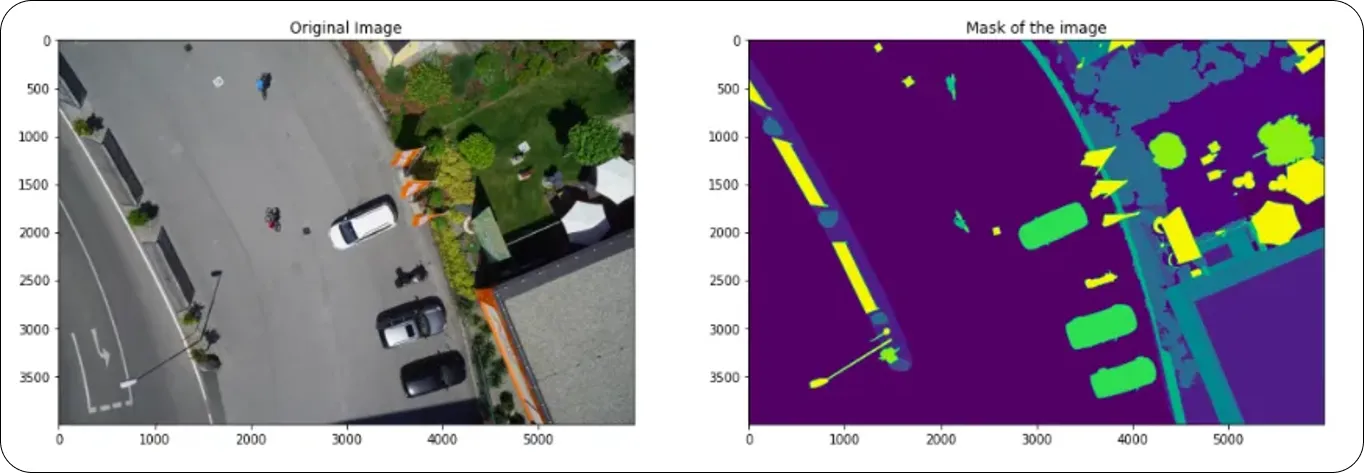
Fig 1. Un ejemplo de segmentación utilizando el modelo de aprendizaje profundo U-Net. (Fuente)
Link to this sectionLa historia de la segmentación de imágenes#
Antes de profundizar en lo que es U-Net, entendamos mejor cómo evolucionaron los modelos de segmentación de imágenes.
Inicialmente, la visión artificial dependía de técnicas tradicionales como la detección de bordes, el umbralado (thresholding) o el crecimiento de regiones para separar objetos en una imagen. Estas técnicas se utilizaban para detectar los límites de los objetos mediante bordes, separar regiones por intensidad de píxeles y agrupar píxeles similares. Funcionaban en casos sencillos, pero a menudo fallaban cuando las imágenes presentaban ruido, formas superpuestas o límites poco claros.
Tras el auge del aprendizaje profundo en 2012, los investigadores introdujeron en 2014 el concepto de redes totalmente convolucionales (FCN) para tareas como la segmentación semántica. Estos modelos sustituyeron partes de una red convolucional para permitir que el equipo analizara una imagen completa a la vez, en lugar de dividirla en piezas más pequeñas. Esto permitió al modelo crear mapas detallados que muestran lo que contiene una imagen de forma más clara.
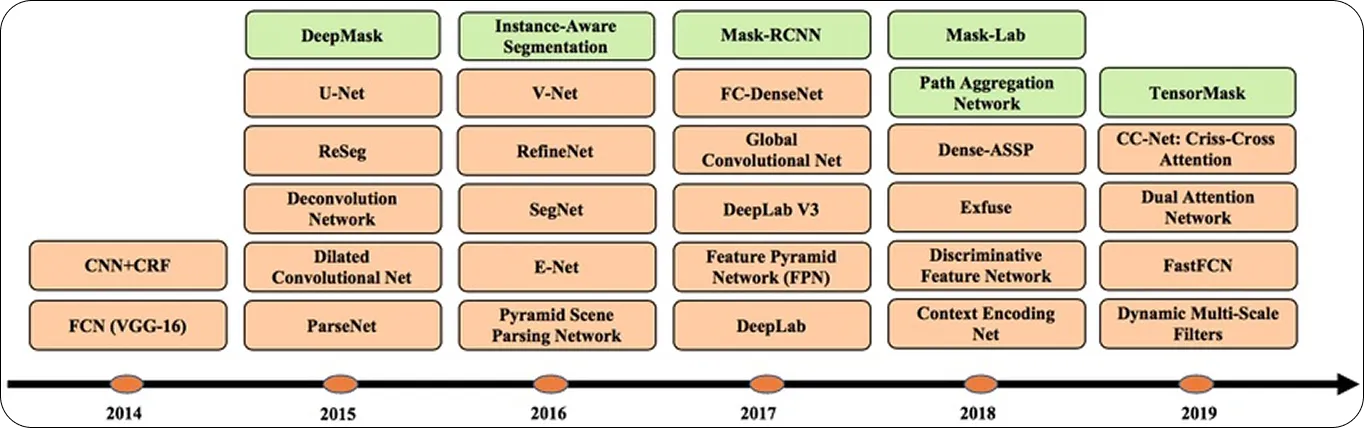
Fig 2. La evolución de los algoritmos de segmentación basados en aprendizaje profundo. (Fuente)
Basándose en las FCN, U-Net fue introducida por investigadores de la Universidad de Friburgo en 2015. Originalmente fue diseñada para la segmentación de imágenes biomédicas. En particular, U-Net se diseñó para obtener un buen rendimiento en situaciones en las que los datos anotados son limitados.
Mientras tanto, versiones posteriores como UNet++ y TransUNet añadieron mejoras como capas de atención y una mejor extracción de características. Las capas de atención ayudan al modelo a centrarse en regiones clave, mientras que la extracción de características mejorada captura información más detallada.
Link to this section¿Qué es U-Net y cómo fluyen las características a través del modelo?#
U-Net es un modelo de aprendizaje profundo diseñado específicamente para la segmentación de imágenes. Toma una imagen como entrada y produce una máscara de segmentación que clasifica cada píxel según el objeto o región al que pertenece.
El modelo recibe su nombre de su arquitectura en forma de U. Consta de dos partes principales: un codificador que comprime la imagen y aprende sus características, y un decodificador que la expande de nuevo al tamaño original. Este diseño crea una forma de U simétrica, lo que ayuda al modelo a comprender tanto la estructura general de una imagen como sus detalles más precisos.
Una característica crucial de U-Net es el uso de conexiones de salto (skip connections), que permiten pasar información directamente del codificador al decodificador. Esto significa que el modelo puede preservar detalles importantes que podrían perderse al comprimir la imagen.
Link to this sectionUna visión general de la arquitectura de U-Net#
Aquí tienes un vistazo a cómo funciona la arquitectura de U-Net:
- Imagen de entrada: U-Net comienza con una imagen 2D, como un escáner médico o una foto de satélite. El objetivo es asignar una etiqueta de clase a cada píxel de la imagen.
- Submuestreo (Downsampling): La imagen pasa a través de capas convolucionales que aprenden características visuales importantes. A medida que la imagen se mueve a través de diferentes capas, su resolución disminuye y el modelo identifica patrones más amplios.
- Capa de cuello de botella (Bottleneck): En el centro de la red, los mapas de características alcanzan su resolución espacial más pequeña mientras capturan características semánticas de alto nivel. En pocas palabras, esta representación comprimida de los mapas de características es el contexto general de la entrada.
- Sobremuestreo (Upsampling): La red reconstruye entonces la imagen aumentando gradualmente la resolución. Las convoluciones transpuestas ayudan a expandir los mapas de características de vuelta hacia el tamaño original.
- Conexiones de salto (Skip connections): Los mapas de características de la ruta de submuestreo se concatenan con los de la ruta de sobremuestreo. Esto ayuda a preservar los detalles espaciales de grano fino mientras se integra información contextual de alto nivel.
- La salida es un mapa de segmentación: La salida final es una máscara de segmentación píxel a píxel que coincide con el tamaño de la entrada. Cada píxel se clasifica en una categoría como objeto, fondo o región de interés.
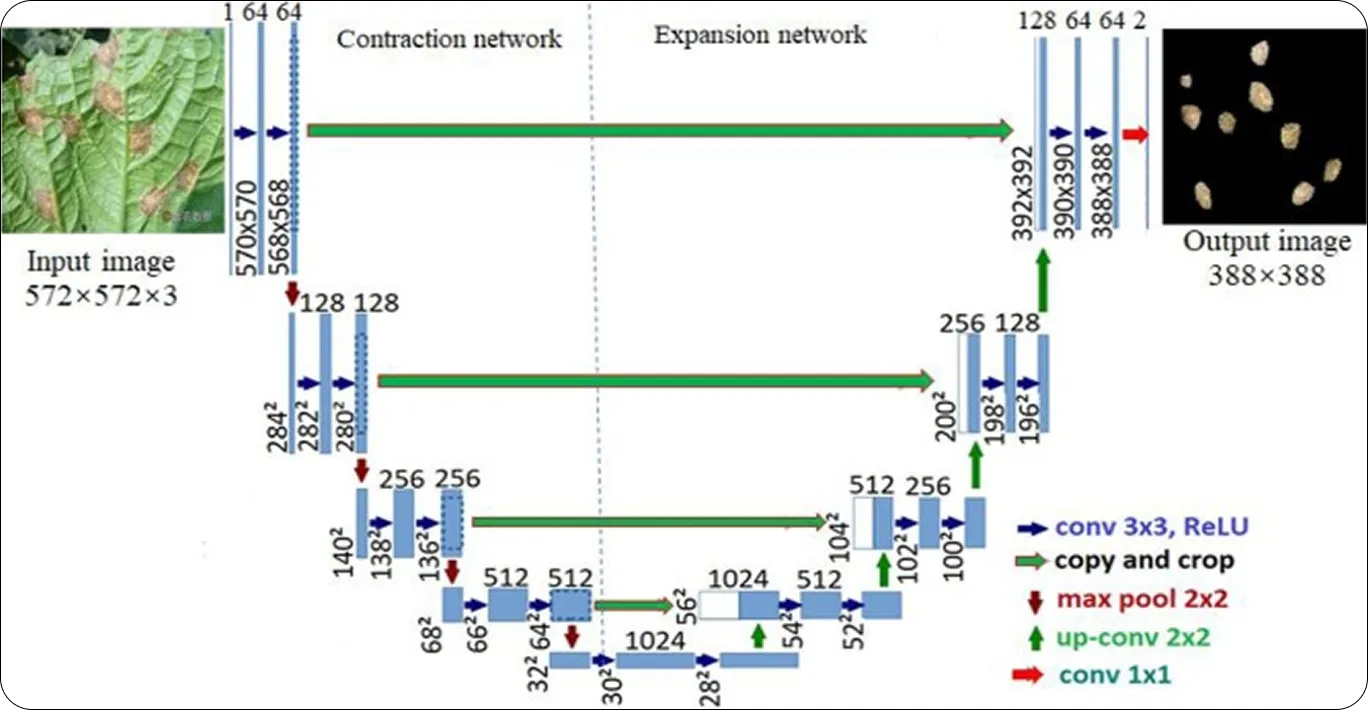
Fig 3. Diagrama de la arquitectura U-Net. (Fuente)
Link to this sectionComprender la diferencia entre ViT y U-Net#
Mientras exploras U-Net, es posible que te preguntes en qué se diferencia de otros modelos de aprendizaje profundo, como el Vision Transformer (ViT), que también puede realizar tareas de segmentación. Aunque ambos modelos pueden realizar tareas similares, difieren en cuanto a cómo están construidos y cómo manejan la segmentación.
U-Net funciona procesando imágenes a nivel de píxel a través de capas convolucionales en una estructura codificador-decodificador. A menudo se utiliza para tareas que requieren una segmentación precisa, como escáneres médicos o escenas de coches autónomos.
Por otro lado, el Vision Transformer (ViT) divide las imágenes en parches y los procesa simultáneamente a través de mecanismos de atención. Utiliza la autoatención (un mecanismo que permite al modelo ponderar la importancia de las diferentes partes de la imagen en relación con las demás) para capturar cómo se relacionan entre sí las diferentes partes de la imagen, a diferencia del enfoque convolucional de U-Net.
Otra diferencia importante es que ViT generalmente necesita más datos para funcionar bien, pero es excelente captando patrones complejos. U-Net, por su parte, funciona bien con conjuntos de datos más pequeños, es más rápido de entrenar y a menudo requiere menos tiempo de entrenamiento.
Link to this sectionAplicaciones del modelo U-Net#
Ahora que entendemos mejor qué es U-Net y cómo funciona, exploremos cómo se ha aplicado U-Net en diferentes dominios.
Link to this sectionSegmentación de hemorragias cerebrales en imágenes médicas#
U-Net se convirtió en un método fiable para la segmentación a nivel de píxel de imágenes médicas complejas, sobre todo durante su apogeo en la investigación. Los investigadores lo utilizaron para resaltar áreas clave en escáneres médicos, como tumores y signos de hemorragia interna en imágenes de TC y RM. Este enfoque hizo avanzar significativamente la precisión de los diagnósticos y agilizó el análisis de datos médicos complejos en entornos de investigación.
Un ejemplo del impacto de U-Net en la investigación sanitaria es su uso para identificar ictus y hemorragias cerebrales en escáneres médicos. Los investigadores pudieron utilizar U-Net para analizar escáneres craneales y resaltar áreas de preocupación, lo que permitió una identificación más rápida de los casos que requerían atención inmediata.
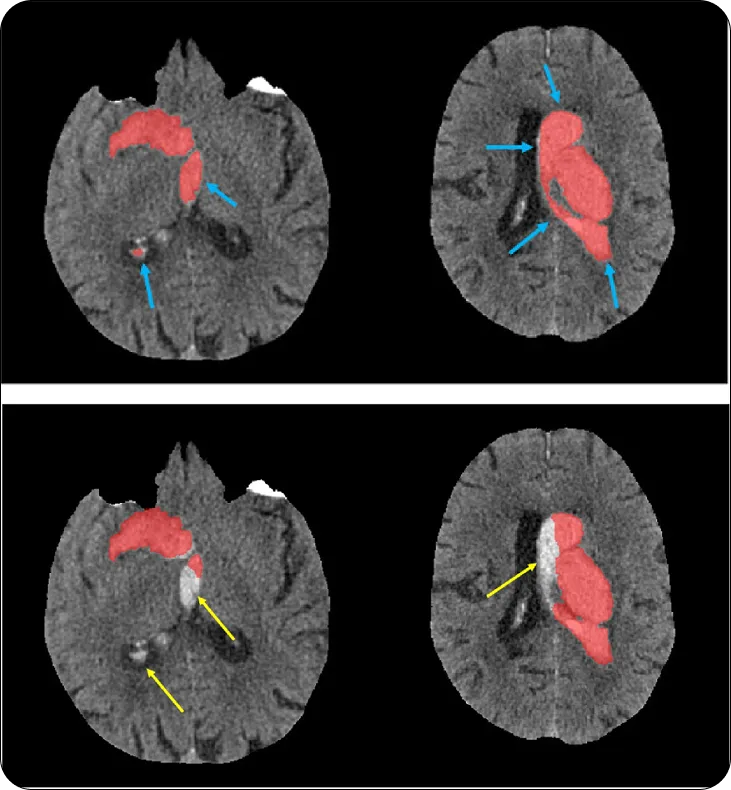
Fig 4. Segmentación de lesiones por ictus hemorrágico mediante U-Net 3D. (Fuente)
Link to this sectionSegmentación de cultivos en agricultura#
Otra área donde los investigadores han utilizado U-Net es en la agricultura, concretamente para segmentar cultivos, malas hierbas y suelo. Ayuda a los agricultores a controlar la salud de las plantas, estimar el rendimiento y tomar mejores decisiones en grandes explotaciones. Por ejemplo, U-Net puede separar los cultivos de las malas hierbas, haciendo que la aplicación de herbicidas sea más eficiente y reduciendo los residuos.
Para abordar retos como el desenfoque por movimiento en imágenes de drones, los investigadores han mejorado U-Net con técnicas de desenfoque de imagen. Esto garantiza una segmentación más clara, incluso cuando los datos se recopilan en movimiento, como durante los levantamientos aéreos.
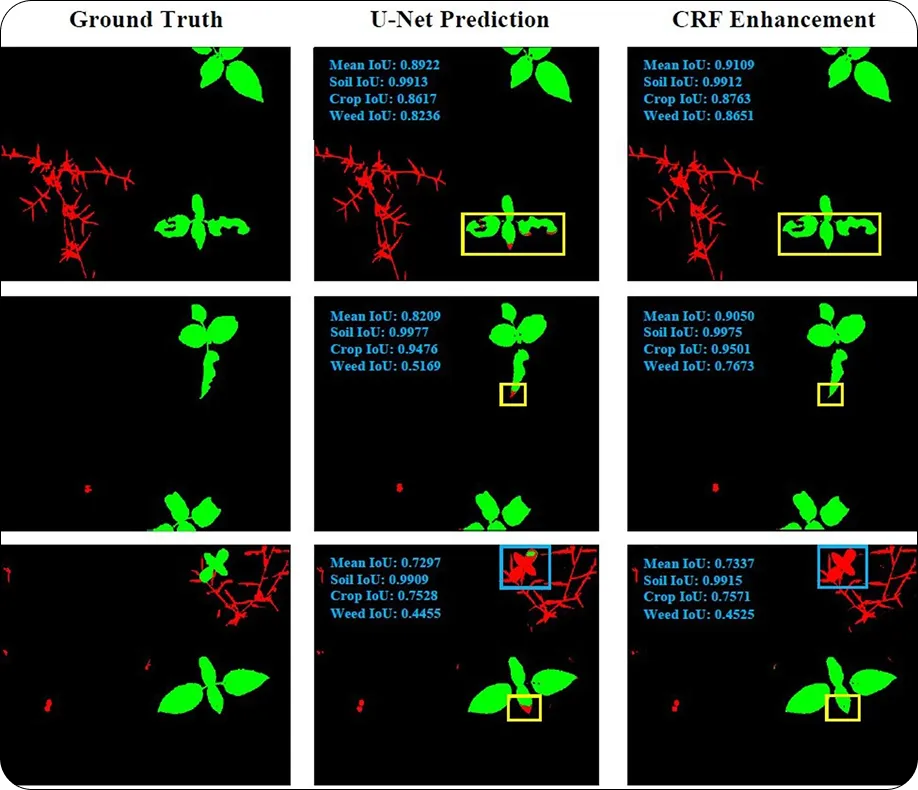
Fig 5. Separación de cultivos de malas hierbas en campos agrícolas con U-Net. (Fuente)
Link to this sectionConducción autónoma#
Antes de que se introdujeran modelos de IA más avanzados, U-Net desempeñó un papel vital en la exploración de cómo la segmentación podía mejorar la conducción autónoma. En los vehículos autónomos, la segmentación semántica de U-Net puede utilizarse para clasificar cada píxel de una imagen en categorías como carretera, vehículo, peatón y marcas de carril. Esto proporciona al coche una visión clara de su entorno, ayudando a una navegación segura y a una toma de decisiones eficaz.
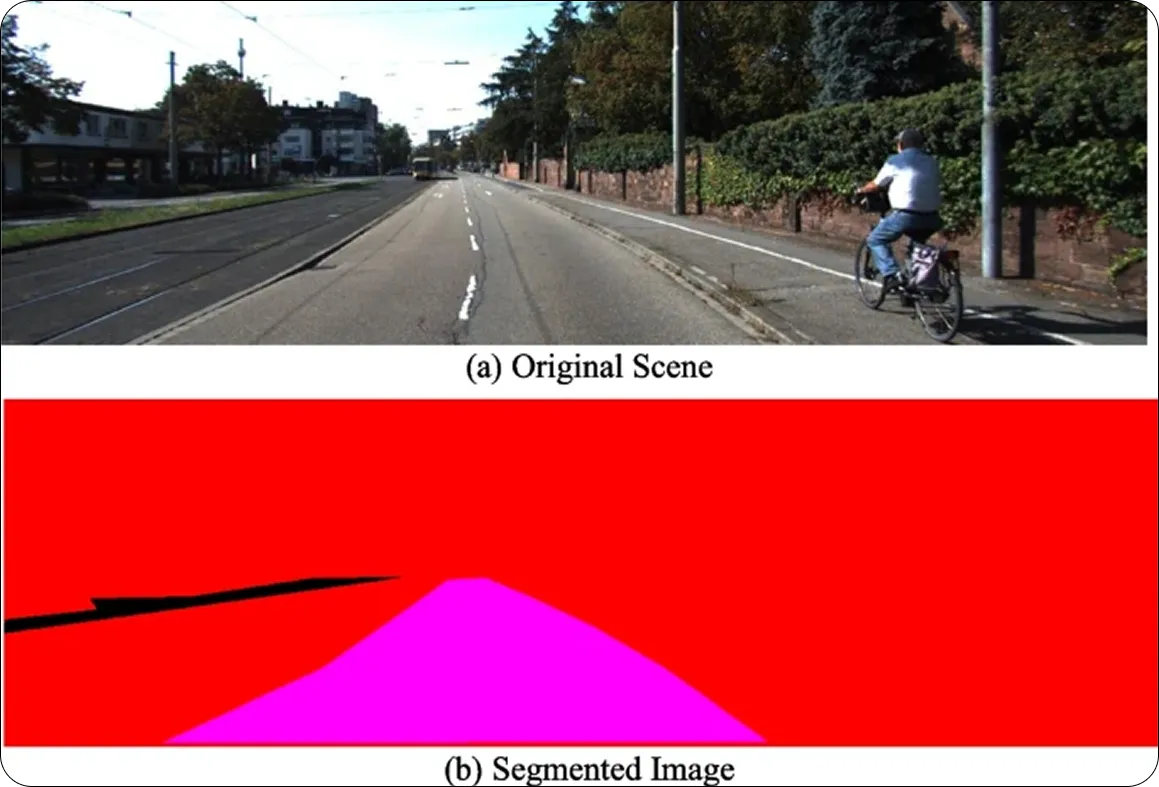
Fig 6. Una escena de carretera donde el área transitable está segmentada utilizando U-Net. (Fuente)
Link to this sectionPros y contras de U-Net#
Incluso hoy en día, U-Net sigue siendo una buena opción para la segmentación de imágenes entre los investigadores debido a su equilibrio de simplicidad, precisión y adaptabilidad. Estas son algunas de las ventajas clave que lo hacen destacar:
- Adaptable a diferentes modalidades: U-Net se ha adaptado a diferentes tipos de datos, incluidos escáneres médicos 3D, imágenes de satélite e incluso fotogramas de vídeo.
- Inferencia rápida cuando está optimizado: Cuando se ajusta correctamente, U-Net puede ejecutarse de forma eficiente, lo que lo hace adecuado para aplicaciones en tiempo real o casi en tiempo real.
- Código abierto y comunidad: U-Net está disponible en las principales bibliotecas de aprendizaje profundo y cuenta con el respaldo de una gran comunidad de desarrolladores e investigadores.
Aunque U-Net tiene muchos puntos fuertes, también hay algunas limitaciones que tener en cuenta. Estos son algunos factores a considerar:
- Sensible a la calidad de los datos: El rendimiento de U-Net puede verse afectado negativamente por datos de mala calidad, como imágenes con ruido o de baja resolución.
- Propenso al sobreajuste (overfitting) con conjuntos de datos pequeños: Aunque U-Net funciona bien con datos limitados, sigue arriesgándose a sufrir sobreajuste si no se regulariza adecuadamente, especialmente cuando el conjunto de datos es demasiado pequeño o carece de diversidad.
- Recursos computacionales: U-Net puede ser costoso desde el punto de vista computacional, especialmente cuando se trabaja con grandes conjuntos de datos, lo que requiere importantes recursos de hardware para el entrenamiento.
Link to this sectionConclusiones clave#
U-Net ha sido un hito clave en la evolución de la segmentación de imágenes. Demostró que los modelos de aprendizaje profundo pueden ofrecer resultados precisos utilizando conjuntos de datos más pequeños, especialmente en áreas como la imagen médica.
Este avance ha allanado el camino para aplicaciones más avanzadas en diversos campos. A medida que la visión artificial sigue evolucionando, los modelos de segmentación como U-Net siguen siendo fundamentales para permitir que las máquinas comprendan e interpreten los datos visuales con gran precisión.
¿Buscas crear tus propios proyectos de visión artificial? Explora nuestro repositorio de GitHub para profundizar en la IA y echa un vistazo a nuestras opciones de licencia. ¡Aprende cómo la visión artificial en el sector sanitario está mejorando la eficiencia y explora el impacto de la IA en el comercio minorista visitando nuestras páginas de soluciones! ¡Únete a nuestra creciente comunidad ahora!






