التعرف على Llama 3 من Meta
تم إصدار Llama 3 من Meta مؤخراً وقوبل بحماس كبير من مجتمع الذكاء الاصطناعي. دعونا نتعرف أكثر على Llama 3 - الأحدث في تطورات Meta AI.

عندما قمنا بجمع ابتكارات الذكاء الاصطناعي في الربع الأول من عام 2024، لاحظنا أن النماذج اللغوية الكبيرة (LLMs) كانت تُصدر من قبل مختلف المؤسسات بكثافة. واستمراراً لهذا الاتجاه، أطلقت Meta في 18 أبريل 2024 نموذج Llama 3، وهو نموذج لغوي كبير مفتوح المصدر من الجيل التالي ومتطور للغاية.
قد تفكر: إنه مجرد نموذج لغوي كبير آخر. لماذا يشعر مجتمع الذكاء الاصطناعي بكل هذا الحماس تجاهه؟
بينما يمكنك إجراء الضبط الدقيق لنماذج مثل GPT-3 أو Gemini للحصول على استجابات مخصصة، إلا أنها لا توفر شفافية كاملة فيما يتعلق بآليات عملها الداخلية، مثل بيانات التدريب، أو معاملات النموذج، أو الخوارزميات. في المقابل، يُعد Llama 3 من Meta أكثر شفافية، حيث تتوفر بنية النموذج وأوزانه للتنزيل. بالنسبة لمجتمع الذكاء الاصطناعي، يعني هذا حرية أكبر في التجريب.
في هذه المقالة، سنتعرف على ما يمكن لـ Llama 3 القيام به، وكيف تم تطويره، وتأثيره على مجال الذكاء الاصطناعي. لنبدأ مباشرة!
Link to this sectionتطور نماذج Llama من Meta#
قبل أن نتعمق في Llama 3، دعونا نلقي نظرة على إصداراته السابقة.
أطلقت Meta نموذج Llama 1 في فبراير 2023، والذي جاء في أربعة متغيرات بمعاملات تتراوح من 7 مليار إلى 65 مليار. في تعلم الآلة، تشير "المعاملات" إلى عناصر النموذج التي يتم تعلمها من بيانات التدريب. وبسبب عدد معاملاته الأقل، كان Llama 1 يواجه أحياناً صعوبات في الفهم الدقيق وكان يقدم استجابات غير متسقة.
بعد فترة وجيزة من Llama 1، أطلقت Meta نموذج Llama 2 في يوليو 2023. تم تدريبه على 2 تريليون رمز (token). يمثل الرمز جزءاً من النص، مثل كلمة أو جزء من كلمة، ويُستخدم كوحدة أساسية للبيانات للمعالجة في النموذج. تضمن النموذج أيضاً تحسينات مثل نافذة سياق مضاعفة تبلغ 4096 رمزاً لفهم المقاطع الأطول، وأكثر من مليون تعليق بشري لتقليل الأخطاء. على الرغم من هذه التحسينات، كان Llama 2 لا يزال يحتاج إلى الكثير من قوة الحوسبة، وهو أمر سعت Meta لإصلاحه مع Llama 3.
Link to this sectionتقديم Llama 3 من Meta#
يأتي Llama 3 مع أربعة متغيرات تم تدريبها على عدد مذهل بلغ 15 تريليون رمز. مثلت بيانات التدريب هذه، بنسبة تزيد عن 5% (حوالي 800 مليون رمز)، بيانات بـ 30 لغة مختلفة. يمكن تشغيل جميع متغيرات Llama 3 على أنواع مختلفة من أجهزة المستهلكين، وتمتلك طول سياق يبلغ 8 آلاف رمز.
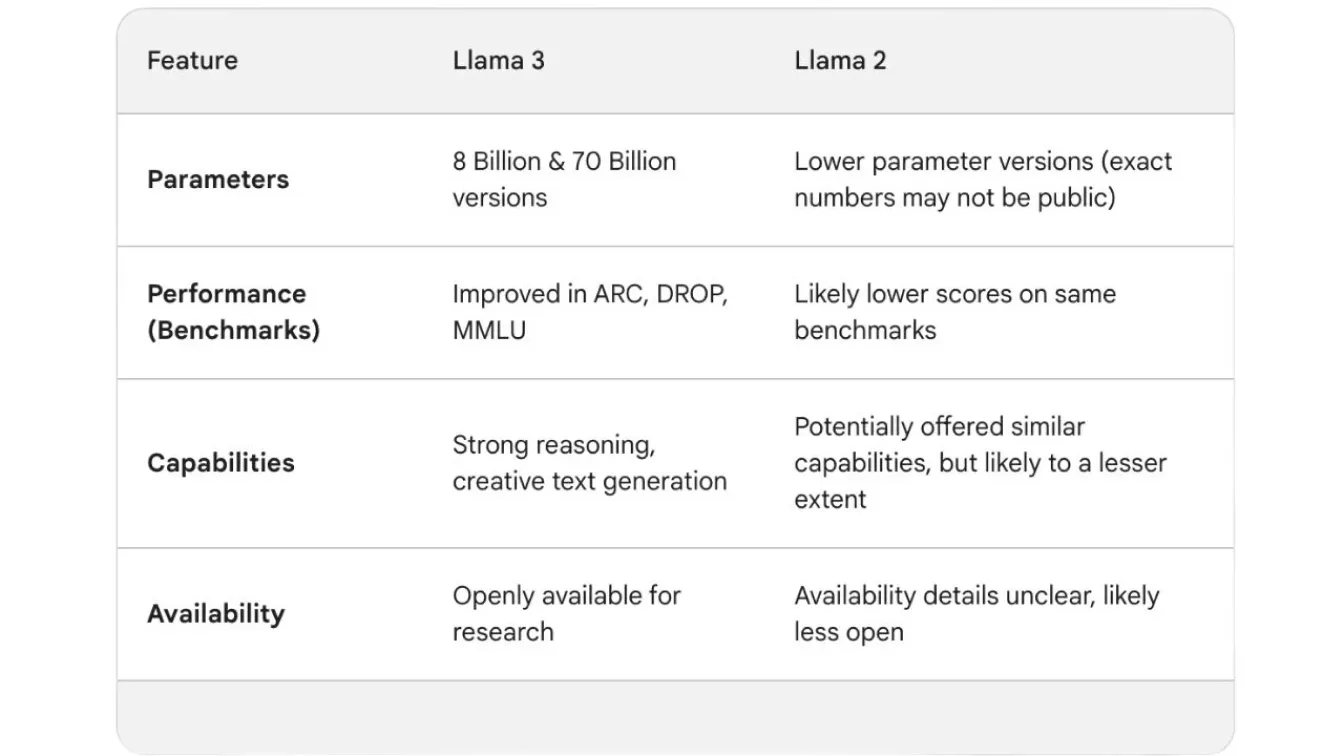
الشكل 1. مقارنة Llama 3 و Llama 2.
تأتي متغيرات النموذج بحجمين: 8B و 70B، مما يشير إلى 8 مليار و 70 مليار معامل على التوالي. هناك أيضاً نسختان: أساسية (base) وتوجيهية (instruct). تشير "الأساسية" إلى النسخة المدربة مسبقاً القياسية. أما "التوجيهية" فهي نسخة تم ضبطها بدقة ومحسنة لتطبيقات أو مجالات معينة من خلال تدريب إضافي على بيانات ذات صلة.
هذه هي متغيرات نموذج Llama 3:
- Meta-Llama-3-8b: يوفر النموذج الأساسي بحجم 8B قدرات ذكاء اصطناعي أساسية، وهو مثالي للمهام العامة مثل تطوير روبوتات الدردشة لخدمة العملاء.
- Meta-Llama-3-8b-instruct: نسخة توجيهية تم ضبطها بدقة من نموذج 8B ومحسنة لمهام محددة. على سبيل المثال، يمكن استخدامها لإنشاء أدوات تعليمية تشرح مواضيع معقدة.
- Meta-Llama-3-70b: تم تصميم النموذج الأساسي بحجم 70B لتطبيقات الذكاء الاصطناعي عالية الأداء. سيعمل هذا النموذج بشكل جيد في تطبيقات مثل معالجة الأدبيات الطبية الحيوية المكثفة لـ اكتشاف الأدوية.
- Meta-Llama-3-70b-instruct: تم ضبط هذه النسخة بدقة من نموذج 70B للتطبيقات فائقة الدقة، مثل تحليل المستندات القانونية أو الطبية، حيث تكون الدقة أمراً حاسماً.
Link to this sectionبنية نموذج Llama 3 من Meta#
كما هو الحال مع أي تطورات أخرى في ذكاء Meta الاصطناعي، تم وضع تدابير صارمة لمراقبة الجودة للحفاظ على سلامة البيانات وتقليل التحيزات أثناء تطوير Llama 3. لذا، فإن المنتج النهائي هو نموذج قوي تم إنشاؤه بمسؤولية.
تتميز بنية نموذج Llama 3 بتركيزها على الكفاءة والأداء في مهام معالجة اللغات الطبيعية. وبناءً على إطار عمل Transformer، فإنها تؤكد على الكفاءة الحسابية، خاصة أثناء توليد النصوص، باستخدام بنية "فك التشفير فقط" (decoder-only).
يولد النموذج المخرجات بناءً على السياق السابق فقط دون الحاجة إلى مُشفّر (encoder) لتشفير المدخلات، مما يجعله أسرع بكثير.
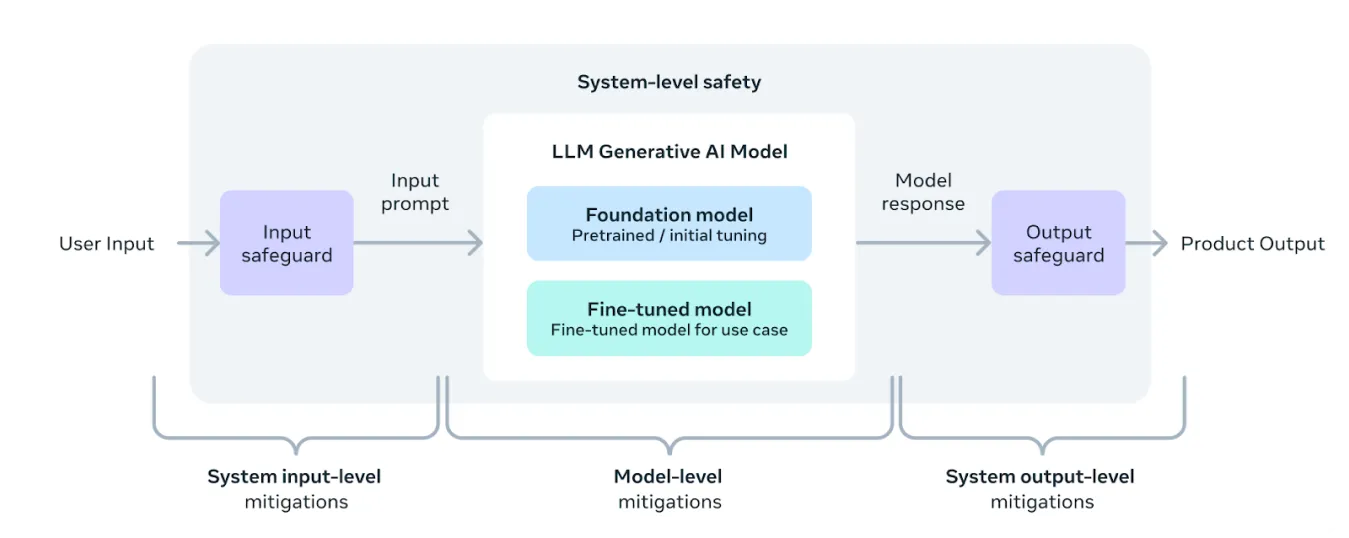
الشكل 2. بنية نموذج Llama 3 المسؤول.
تتميز نماذج Llama 3 بمُرمِّز (tokenizer) بمفردات تبلغ 128 ألف رمز. تعني المفردات الأكبر أن النماذج يمكنها فهم ومعالجة النصوص بشكل أفضل. أيضاً، تستخدم النماذج الآن آلية "تنبيه الاستعلام المجمع" (GQA) لتحسين كفاءة الاستدلال. GQA هي تقنية يمكنك التفكير فيها ككشاف ضوئي يساعد النماذج على التركيز على الأجزاء ذات الصلة من بيانات الإدخال لتوليد استجابات أسرع وأكثر دقة.
إليك بعض التفاصيل الأخرى المثيرة للاهتمام حول بنية نموذج Llama 3:
- معالجة المستندات الواعية بالحدود: يحافظ Llama 3 على الوضوح عبر حدود المستندات، وهو أمر أساسي لمهام مثل التلخيص.
- فهم أفضل للكود: تتضمن بيانات تدريب Llama 3 أربعة أضعاف عينات الكود، مما يعزز قدراته البرمجية.
- مراقبة جودة قوية: تضمن التدابير الصارمة، بما في ذلك المرشحات الاستدلالية وإزالة المحتوى غير اللائق (NSFW)، سلامة البيانات وتقليل التحيزات.
Link to this sectionLlama 3 يغير كيفية تعاملنا مع تدريب النماذج#
لتدريب أكبر نماذج Llama 3، تم دمج ثلاثة أنواع من التوازي: توازي البيانات، وتوازي النموذج، وتوازي خط الأنابيب (pipeline).
يقسم توازي البيانات بيانات التدريب عبر وحدات معالجة رسومية (GPUs) متعددة، بينما يقوم توازي النموذج بتقسيم بنية النموذج لاستخدام القوة الحسابية لكل GPU. ويقسم توازي خط الأنابيب عملية التدريب إلى مراحل متسلسلة، مما يعمل على تحسين الحساب والاتصال.
حقق التنفيذ الأكثر كفاءة استخداماً مذهلاً للحوسبة، متجاوزاً 400 TFLOPS لكل GPU عند التدريب على 16000 GPU في وقت واحد. تم إجراء عمليات التدريب هذه على مجموعتين من الـ GPUs مخصصتين، تضم كل منهما 24000 GPU. وفرت هذه البنية التحتية الحسابية الضخمة القوة اللازمة لتدريب نماذج Llama 3 واسعة النطاق بكفاءة.
لتحقيق أقصى قدر من وقت تشغيل الـ GPU، تم تطوير حزمة تدريب متقدمة جديدة، تعمل على أتمتة اكتشاف الأخطاء، ومعالجتها، وصيانتها. تم تحسين موثوقية الأجهزة وآليات الكشف بشكل كبير لتقليل مخاطر تلف البيانات الصامت. أيضاً، تم تطوير أنظمة تخزين قابلة للتطوير لتقليل تكاليف الفحص (checkpointing) والتراجع.
أدت هذه التحسينات إلى فعالية إجمالية في وقت التدريب تجاوزت 95%. ومجتمعة، زادت من كفاءة تدريب Llama 3 بحوالي ثلاث مرات مقارنة بـ Llama 2. هذه الكفاءة ليست مجرد أمر مثير للإعجاب؛ بل إنها تفتح إمكانيات جديدة لأساليب تدريب الذكاء الاصطناعي.
Link to this sectionفتح الأبواب مع Llama 3#
نظراً لأن Llama 3 مفتوح المصدر، يمكن للباحثين والطلاب دراسة الكود الخاص به، وإجراء التجارب، والمشاركة في مناقشات حول المخاوف الأخلاقية والتحيزات. ومع ذلك، لا يقتصر Llama 3 على الجمهور الأكاديمي فقط. إنه يُحدث تأثيراً في التطبيقات العملية أيضاً. إذ أصبح العمود الفقري لواجهة دردشة Meta AI، حيث يتكامل بسلاسة مع منصات مثل فيسبوك، وإنستغرام، وواتساب، وماسنجر. مع Meta AI، يمكن للمستخدمين المشاركة في محادثات باللغة الطبيعية، والوصول إلى توصيات مخصصة، وأداء المهام، والتواصل مع الآخرين بسهولة.
الشكل 3. Meta AI: مدعوم بنموذج Llama 3.
Link to this sectionمقارنة Llama 3 مع نماذج لغوية كبيرة أخرى#
يؤدي Llama 3 أداءً استثنائياً عبر العديد من المعايير الرئيسية التي تقيم قدرات فهم اللغة والاستدلال المعقدة. إليك بعض المعايير التي تختبر جوانب مختلفة من قدرات Llama 3:
- فهم اللغة متعدد المهام الضخم (MMLU) - يقيس معرفته عبر مجالات متنوعة.
- الإجابة على الأسئلة للأغراض العامة (GPQA) - يقيم قدرة النموذج على توليد إجابات متماسكة وصحيحة لمجموعة واسعة من أسئلة المعرفة العامة.
- HumanEval - يركز على مهام البرمجة وحل المشكلات، ويختبر قدرة النموذج على توليد كود برمجي وظيفي وحل التحديات الخوارزمية.
النتائج المتميزة التي حققها Llama 3 في هذه الاختبارات تميزه بوضوح عن المنافسين مثل Gemma 7B من جوجل، و Mistral 7B من ميسترال، و Claude 3 Sonnet من أنثروبيك. ووفقاً للإحصاءات المنشورة، خاصة لنموذج 70B، يتفوق Llama 3 على هذه النماذج في جميع المعايير المذكورة أعلاه.
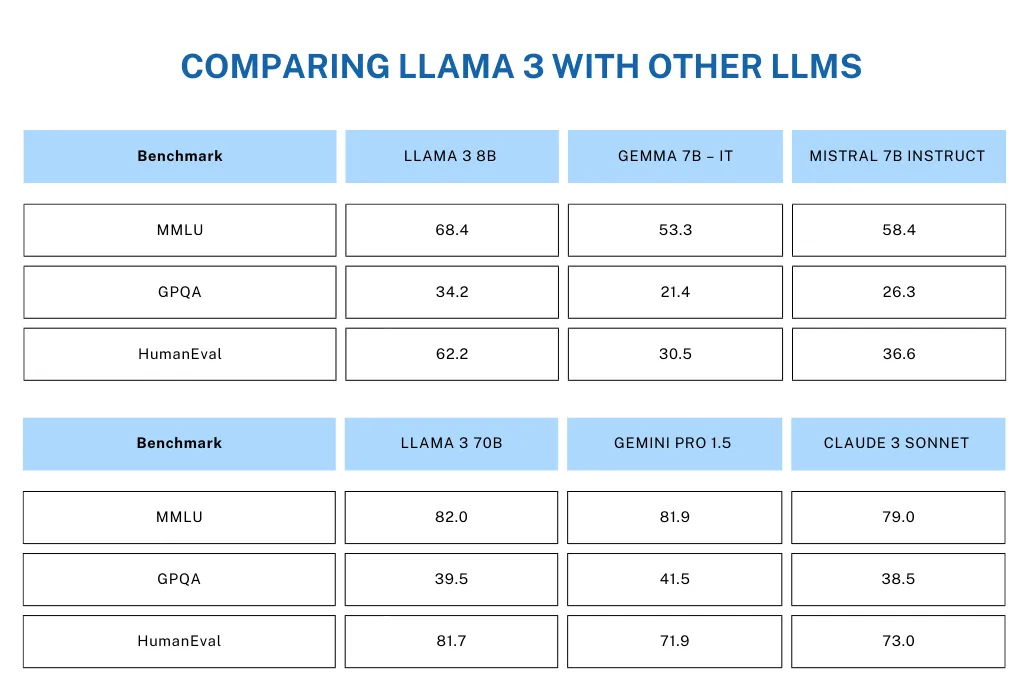
الشكل 4. مقارنة Llama 3 مع نماذج لغوية كبيرة أخرى.
Link to this sectionيتم جعل Meta Llama 3 متاحاً على نطاق واسع#
تقوم Meta بتوسيع نطاق وصول Llama 3 من خلال توفيره عبر مجموعة متنوعة من المنصات لكل من المستخدمين العاديين والمطورين. بالنسبة للمستخدمين اليوميين، تم دمج Llama 3 في منصات Meta الشهيرة مثل واتساب، وإنستغرام، وفيسبوك، وماسنجر. يمكن للمستخدمين الوصول إلى ميزات متقدمة مثل البحث في الوقت الفعلي والقدرة على إنشاء محتوى إبداعي مباشرة داخل هذه التطبيقات.
يتم أيضاً دمج Llama 3 في التقنيات القابلة للارتداء مثل نظارات Ray-Ban Meta الذكية وسماعة الرأس Meta Quest VR لتجارب تفاعلية.
Llama 3 متاح على مجموعة متنوعة من المنصات للمطورين، بما في ذلك AWS، و Databricks، و Google Cloud، و Hugging Face، و Kaggle، و IBM WatsonX، و Microsoft Azure، و NVIDIA NIM، و Snowflake. يمكنك أيضاً الوصول إلى هذه النماذج مباشرة من Meta. تسهل مجموعة الخيارات الواسعة على المطورين دمج قدرات نماذج الذكاء الاصطناعي المتقدمة هذه في مشاريعهم، سواء كانوا يفضلون العمل مباشرة مع Meta أو من خلال منصات شائعة أخرى.
Link to this sectionالخلاصة#
تستمر تطورات تعلم الآلة في تغيير كيفية تفاعلنا مع التكنولوجيا كل يوم. يُظهر Llama 3 من Meta أن النماذج اللغوية الكبيرة لم تعد تتعلق بتوليد النصوص فقط. إذ تعالج هذه النماذج المشكلات المعقدة وتتعامل مع لغات متعددة. بشكل عام، يجعل Llama 3 الذكاء الاصطناعي أكثر قابلية للتكيف وأكثر سهولة في الوصول إليه من أي وقت مضى. وبالنظر إلى المستقبل، تعد الترقيات المخطط لها لـ Llama 3 بقدرات أكبر، مثل التعامل مع نماذج متعددة وفهم سياقات أكبر.
تفقد مستودع GitHub الخاص بنا وانضم إلى مجتمعنا لمعرفة المزيد حول الذكاء الاصطناعي. قم بزيارة صفحات الحلول الخاصة بنا لرؤية كيف يتم تطبيق الذكاء الاصطناعي في مجالات مثل التصنيع و الزراعة.






