Entrena modelos YOLO más rápido con la Ultralytics Platform
Descubre cómo entrenar modelos YOLO más rápido con la Ultralytics Platform, un entorno integral diseñado para acelerar el camino desde los datos hasta el despliegue.
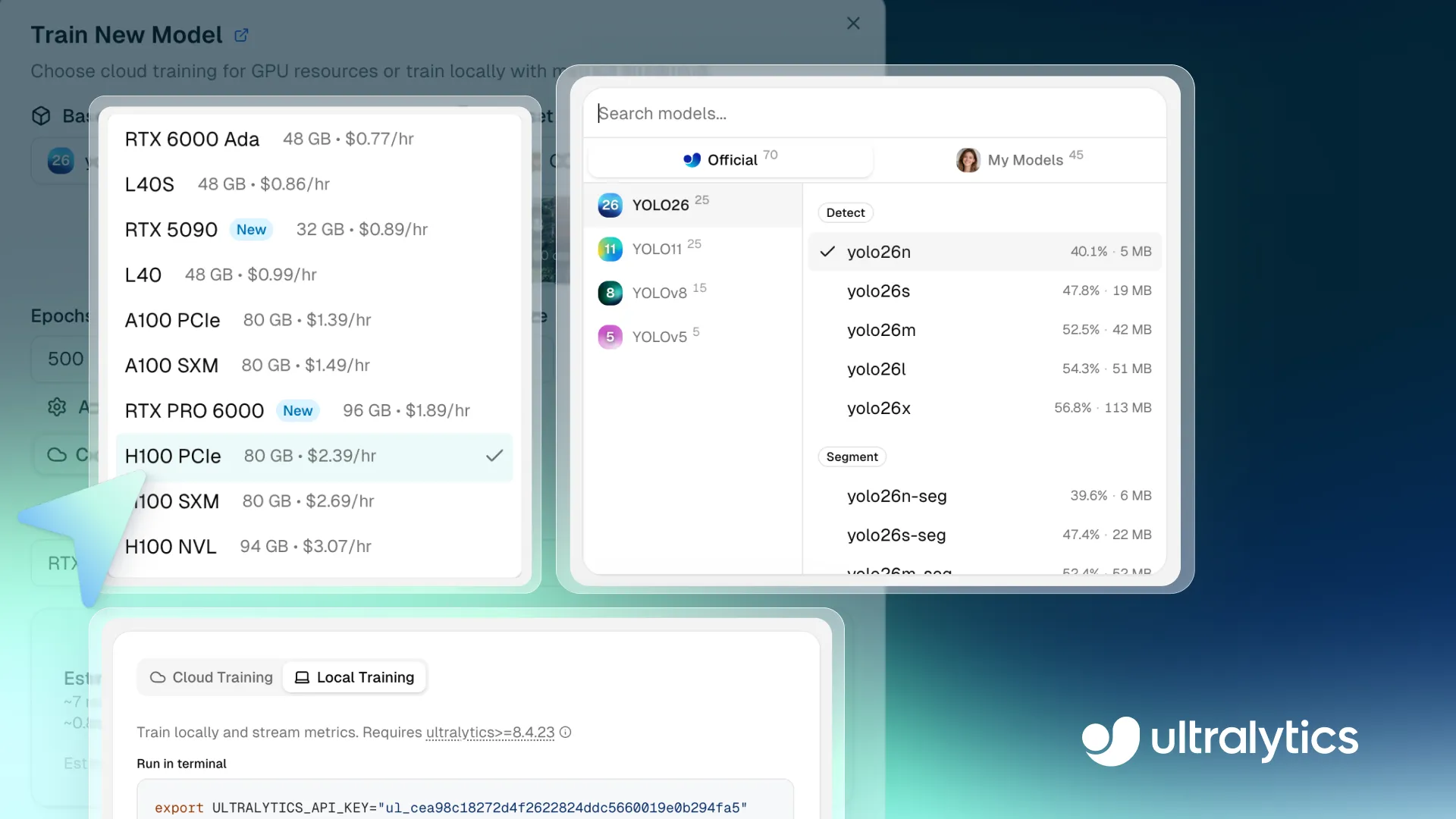
La semana pasada, Ultralytics presentó Ultralytics Platform, un espacio de trabajo unificado diseñado para simplificar la forma en que los equipos crean, entrenan y despliegan modelos de visión artificial. En lugar de hacer malabarismos con múltiples herramientas, la plataforma reúne todo en un solo lugar. Pasar de la idea al despliegue con modelos de visión IA se vuelve sencillo.
Esto es crucial porque la visión artificial se está convirtiendo rápidamente en una parte fundamental de diversas industrias. Impulsa aplicaciones como la inspección en fabricación, el análisis minorista y la navegación autónoma.
Convertir estas aplicaciones habilitadas por visión en sistemas fiables depende de lo bien que se entrenen los modelos. El entrenamiento de modelos implica aprender de datos etiquetados para que el modelo pueda reconocer patrones y realizar predicciones precisas. Por lo general, los modelos bien entrenados conducen a un mejor rendimiento y a resultados más fiables en aplicaciones del mundo real.
Sin embargo, entrenar un modelo de visión artificial no siempre es sencillo. Consiste en varios aspectos, como la configuración de entornos, la selección de recursos de cómputo adecuados, el ajuste de hiperparámetros y el seguimiento de múltiples experimentos de entrenamiento. Cuando estos pasos se dispersan entre diferentes herramientas y sistemas, el flujo de trabajo de entrenamiento se vuelve rápidamente complejo y difícil de gestionar.
Ultralytics Platform resuelve esto llevando todo el proceso de entrenamiento a un panel de control único y unificado. Puedes configurar, ejecutar y supervisar trabajos de entrenamiento en un solo lugar, ya sea que trabajes en la nube, localmente o en Google Colab.
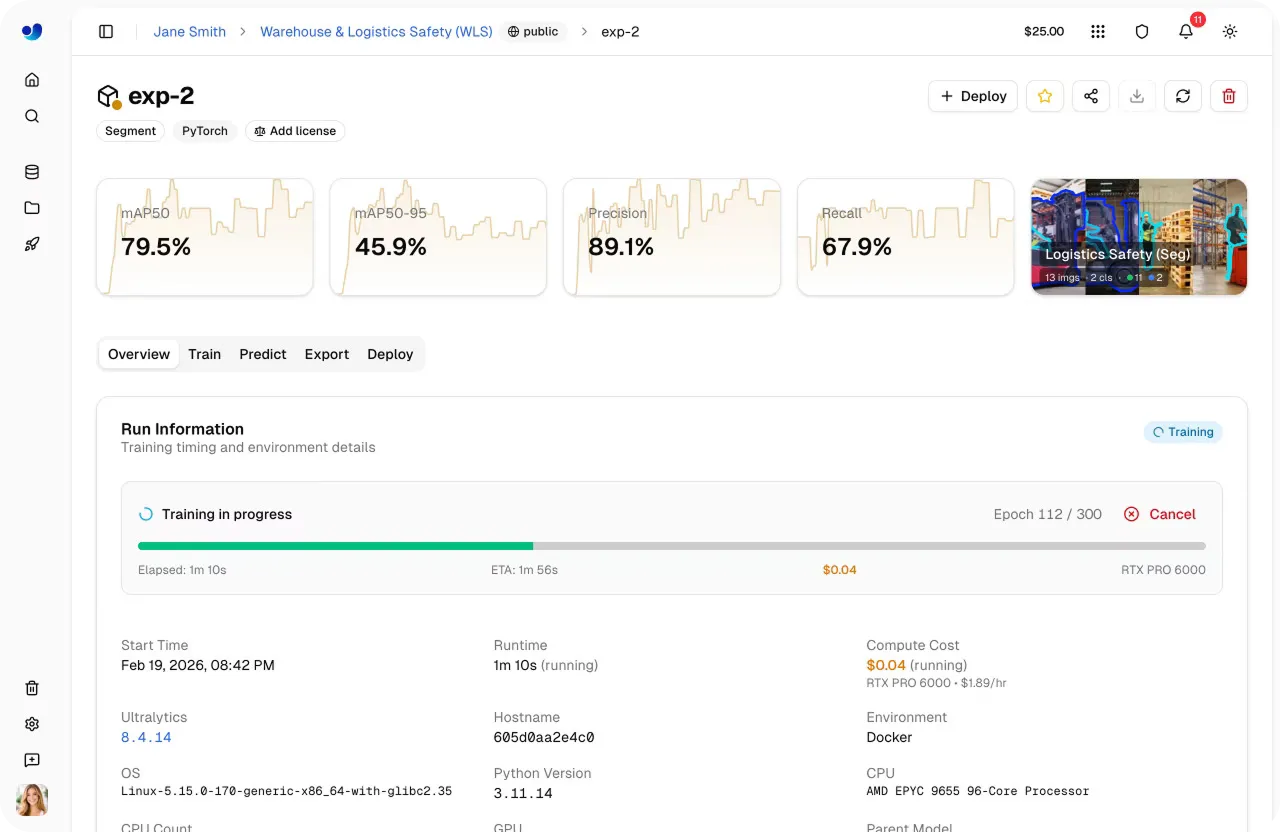
Fig 1. Un vistazo al entrenamiento de modelos dentro de Ultralytics Platform (Fuente)
En este artículo, exploraremos cómo Ultralytics Platform agiliza el entrenamiento de modelos y por qué puede darte una ventaja en tus proyectos de visión IA. ¡Empecemos!
Link to this sectionLos modelos de visión artificial aprenden de los datos a través del entrenamiento de modelos#
Antes de sumergirnos en cómo funciona el entrenamiento de modelos en Ultralytics Platform, demos un paso atrás y veamos qué es el entrenamiento de modelos y qué implica.
El entrenamiento de modelos es el proceso mediante el cual un modelo de visión artificial aprende a interpretar datos visuales. Analiza imágenes o vídeos y ajusta gradualmente sus parámetros internos para realizar tareas de visión como la detección de objetos, la clasificación de imágenes y la segmentación de instancias con precisión. Con el tiempo, el modelo mejora aprendiendo patrones directamente de los datos que ve.
La calidad del entrenamiento depende en gran medida de los datasets. Puedes pensar en un dataset como un conjunto de tarjetas didácticas que un profesor usaría para entrenar a un alumno, donde cada ejemplo ayuda al modelo a aprender qué buscar.
Un dataset de visión artificial típico incluye imágenes, generalmente en formatos como JPG o PNG, y anotaciones que describen qué hay en cada imagen. Estas anotaciones, a menudo almacenadas como archivos JSON o TXT, proporcionan las etiquetas y el contexto que el modelo necesita para aprender eficazmente.
Pero el entrenamiento no consiste solo en introducir datos en un modelo. Implica varios pasos clave, desde la preparación del dataset hasta la selección del modelo correcto y la configuración del proceso de entrenamiento. A continuación, analicemos más de cerca algunos de estos pasos.
Link to this sectionUn vistazo a cómo se preparan los datasets#
Podría parecer que una vez que tienes un dataset, puedes empezar a entrenar un modelo inmediatamente, pero hay algunos pasos que debes seguir primero, como la división del dataset.
Por lo general, un dataset se divide en tres partes: conjunto de entrenamiento, conjunto de validación y conjunto de pruebas. Las imágenes de entrenamiento se utilizan para enseñar al modelo patrones en los datos, mientras que el conjunto de validación ayuda a supervisar y ajustar el rendimiento durante el entrenamiento.
El conjunto de pruebas se utiliza al final para evaluar cómo funciona el modelo con datos completamente nuevos y desconocidos. Esta configuración ayuda a garantizar que el modelo no solo memorice los datos, sino que pueda generalizar a escenarios del mundo real.
Link to this sectionSelección del modelo adecuado para el entrenamiento#
Otro paso importante antes del entrenamiento es elegir el modelo que quieres utilizar. En muchos casos, esto significa seleccionar un modelo preentrenado. Los modelos como los modelos de Ultralytics YOLO ya están entrenados en grandes datasets y han aprendido patrones visuales generales, lo que los convierte en un punto de partida sólido.
Utilizar estos modelos es un ejemplo de aprendizaje por transferencia, donde construyes sobre el conocimiento existente y adaptas el modelo a tu tarea específica. Este enfoque ayuda a acelerar el entrenamiento y mejorar los resultados, especialmente cuando se trabaja con datos limitados.
Estos modelos también vienen en diferentes tamaños, cada uno ofreciendo un equilibrio entre velocidad y precisión. Los modelos más pequeños son más rápidos y eficientes, mientras que los modelos más grandes tienden a ofrecer una mayor precisión pero requieren más cómputo.
Link to this sectionConfiguración de parámetros de entrenamiento para modelos de visión#
Después de preparar el dataset y seleccionar un modelo, el siguiente paso es configurar cómo aprende el modelo.
Un modelo de visión artificial se entrena usando un conjunto de parámetros que determinan cómo procesa los datos, actualiza sus pesos y mejora con el tiempo. Estos ajustes afectan directamente tanto a la velocidad de entrenamiento como a la precisión final, lo que los hace esenciales para lograr resultados sólidos.
Aquí tienes algunos de los parámetros de entrenamiento más utilizados:
- Epochs: Representa cuántas veces el modelo recorre todo el dataset durante el entrenamiento. Aumentar el número de epochs le da al modelo más oportunidades para aprender patrones de los datos.
- Batch size: Es el número de imágenes procesadas juntas en un solo paso de entrenamiento. Los tamaños de lote (batch size) más grandes pueden acelerar el entrenamiento, pero requieren más memoria.
- Image size: Especifica la resolución de las imágenes de entrada utilizadas durante el entrenamiento. Las resoluciones más altas pueden mejorar la precisión de la detección, pero aumentan el costo computacional.
- Learning rate: Es la tasa a la que el modelo actualiza sus parámetros internos durante el entrenamiento. Los valores que son demasiado altos o demasiado bajos pueden hacer que el entrenamiento sea inestable.
- Optimizer: Es el algoritmo responsable de actualizar los parámetros del modelo basándose en el error calculado durante cada iteración de entrenamiento.
En los flujos de trabajo basados en Ultralytics YOLO, estas configuraciones suelen definirse en un archivo YAML. Este archivo especifica las rutas de los datasets, los nombres de las clases y cómo se dividen los datos. Actúa como una configuración central que le dice al modelo cómo interpretar el dataset.
Link to this sectionDe flujos de trabajo fragmentados a una experiencia unificada con Ultralytics Platform#
Acabamos de discutir algunos de los pasos clave involucrados en el entrenamiento de un modelo de visión artificial, desde la preparación de datasets hasta la selección de un modelo y la configuración de los parámetros de entrenamiento. En la práctica, el proceso a menudo va más allá, incluyendo el seguimiento de experimentos, la comparación de múltiples ejecuciones de entrenamiento y el refinamiento continuo de los modelos a lo largo del tiempo.
Estos pasos rara vez se gestionan en un solo lugar. Los datasets pueden prepararse en una herramienta, las ejecuciones de entrenamiento realizarse en otro entorno y el seguimiento de experimentos gestionarse por separado. A medida que crecen los proyectos, esta fragmentación añade complejidad, ralentiza la iteración y dificulta mantener todo organizado.
Ultralytics Platform elimina esta complejidad integrando todo el flujo de trabajo de entrenamiento en un solo entorno. En lugar de cambiar entre herramientas, puedes gestionar datasets, configurar el entrenamiento, ejecutar experimentos y supervisar resultados en un solo lugar.
A continuación, veamos cómo Ultralytics Platform hace que el entrenamiento de modelos sea más inteligente.
Link to this sectionOpciones de entrenamiento admitidas por Ultralytics Platform#
En aplicaciones del mundo real, entrenar un modelo de visión artificial a menudo requiere entornos flexibles. Dependiendo del tamaño de tu dataset, la complejidad del modelo y el hardware disponible, puedes optar por ejecutar el entrenamiento en la nube, en una máquina local o a través de entornos de notebook externos.
Ultralytics Platform admite las siguientes opciones de entrenamiento para adaptarse a estas necesidades:
- Cloud training: Las ejecuciones de entrenamiento se realizan en unidades de procesamiento gráfico (GPUs) en la nube gestionadas por Ultralytics. Esta opción es ideal para datasets más grandes o modelos más complejos que requieren importantes recursos computacionales.
- Local training: Esta opción utiliza el hardware disponible en tu máquina y es ideal para experimentos rápidos, probar configuraciones o trabajar con datasets más pequeños. Para cargas de trabajo más escalables, el entrenamiento también se puede ejecutar en tu propio entorno en la nube, como AWS o GCP.
- Google Colab: Con Ultralytics Platform, puedes ejecutar el entrenamiento en el entorno de notebook alojado de Google Colab, lo que permite un flujo de trabajo flexible basado en navegador sin necesidad de configurar una máquina local.
Link to this sectionExploración del entrenamiento en la nube en Ultralytics Platform#
Cuando se trata de proyectos de visión artificial, entrenar modelos localmente o a través de entornos de notebook no siempre es fácil.
Por ejemplo, con el entrenamiento local, el rendimiento depende completamente de tu hardware, lo que puede limitar la potencia de cómputo y ralentizar la experimentación. Las GPUs son esenciales para un entrenamiento eficiente, pero no todas las configuraciones tienen acceso fiable a ellas.
Aunque los entornos de notebook como Google Colab ofrecen una alternativa al proporcionar GPUs en la nube, las sesiones suelen ser temporales y pueden interrumpir las ejecuciones de entrenamiento más largas. A medida que los datasets crecen y los flujos de trabajo se vuelven más complejos, estas limitaciones pueden convertirse rápidamente en cuellos de botella, haciendo que el entrenamiento sea más lento y menos fiable.
Ultralytics Platform soluciona esto con su opción de entrenamiento en la nube. Proporciona un entorno listo para usar donde las dependencias de Python y marcos como PyTorch están preconfigurados, permitiéndote empezar a entrenar sin necesidad de una configuración adicional.
Desde un único panel de control, puedes lanzar trabajos de entrenamiento y supervisar el progreso en tiempo real. Esto facilita centrarse en mejorar tus modelos en lugar de gestionar la infraestructura.
Ahora, veamos cómo empezar con el entrenamiento en la nube en Ultralytics Platform.
Link to this sectionPaso 1: Seleccionar un modelo base#
El primer paso es elegir un modelo base para tu ejecución de entrenamiento. Puedes seleccionar un modelo de Ultralytics YOLO preentrenado, clonar un modelo de la comunidad o cargar tus propios pesos preentrenados para cumplir con requisitos personalizados.
La plataforma admite todos los modelos de Ultralytics YOLO, incluyendo Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8 y Ultralytics YOLOv5, cada uno disponible en diferentes variantes de tamaño como nano (n), small (s), medium (m), large (l) y extra-large (x). Con diferentes variantes de modelos que ofrecen un equilibrio entre velocidad y precisión, puedes elegir un modelo que se ajuste a tus requisitos de rendimiento y cómputo.
Estos modelos admiten una gama de tareas de visión artificial con las que los usuarios de Ultralytics YOLO ya están familiarizados, incluyendo detección de objetos, segmentación de instancias, clasificación de imágenes, detección de cuadros delimitadores orientados (OBB) y estimación de poses.
Si tienes requisitos personalizados, también puedes cargar tus propios pesos de modelos preentrenados. Esto significa que puedes continuar entrenando o ajustar (fine-tune) un modelo existente, como un detector de objetos, dentro de la plataforma en lugar de empezar desde cero. Es especialmente útil si ya has entrenado un modelo en otra parte o quieres adaptar un modelo a un caso de uso más específico.
Link to this sectionPaso 2: Seleccionar un dataset#
El siguiente paso es seleccionar un dataset para el entrenamiento. En Ultralytics Platform, puedes utilizar datasets preexistentes como el dataset COCO, clonar datasets de la comunidad o cargar tu propio dataset personalizado adaptado a tu aplicación específica.
La plataforma admite formatos de anotación comunes como Ultralytics YOLO y COCO, y también puede manejar cargas de imágenes sin procesar si planeas anotar datos personalizados directamente en la plataforma.
Una vez cargados, los datasets se procesan automáticamente, incluyendo validación, normalización, análisis de etiquetas y generación de estadísticas. Esto te da visibilidad inmediata sobre tus datos, incluyendo distribuciones de clases y estructura del dataset, y ayuda a asegurar que todo esté listo para el entrenamiento.
Los datasets también se vinculan automáticamente a las ejecuciones de entrenamiento, permitiéndote rastrear qué datos se utilizaron para cada modelo y mantener la consistencia en todos los experimentos.
Link to this sectionPaso 3: Configurar los parámetros de entrenamiento#
Después de elegir el dataset, puedes configurar los parámetros de entrenamiento que controlan cómo aprende el modelo. Estos incluyen epochs, batch size, image size y el nombre de la ejecución para el registro de entrenamiento. Muchos de estos parámetros influyen tanto en la duración del entrenamiento como en el rendimiento final del modelo.
Para un entrenamiento más controlado, la plataforma también te permite ajustar parámetros avanzados como la tasa de aprendizaje (learning rate), el tipo de optimizador, los ajustes de aumentación de color y otras opciones de entrenamiento. Estos ajustes pueden refinar el proceso de entrenamiento para mejorar la precisión y la estabilidad del modelo.
Link to this sectionPaso 4: Seleccionar una GPU#
A continuación, puedes seleccionar la configuración de GPU para tu ejecución de entrenamiento. Elegir la GPU adecuada depende de factores como el tamaño del dataset, el tamaño del lote (batch size), la resolución de la imagen y la complejidad del modelo. Encontrar el equilibrio adecuado ayuda a mantener el entrenamiento eficiente sin usar más cómputo del necesario.
Ultralytics Platform ofrece 22 opciones de GPU con diferentes niveles de VRAM (memoria en una GPU) y potencia de cómputo, soportando desde tareas pequeñas hasta cargas de trabajo a gran escala.
Usando esto, puedes adaptar el hardware a tus necesidades específicas, ya sea que estés entrenando modelos ligeros o trabajando con datasets grandes y complejos. Para obtener más información, consulta la lista de GPUs disponibles en la página de documentación de entrenamiento de Platform de Ultralytics.
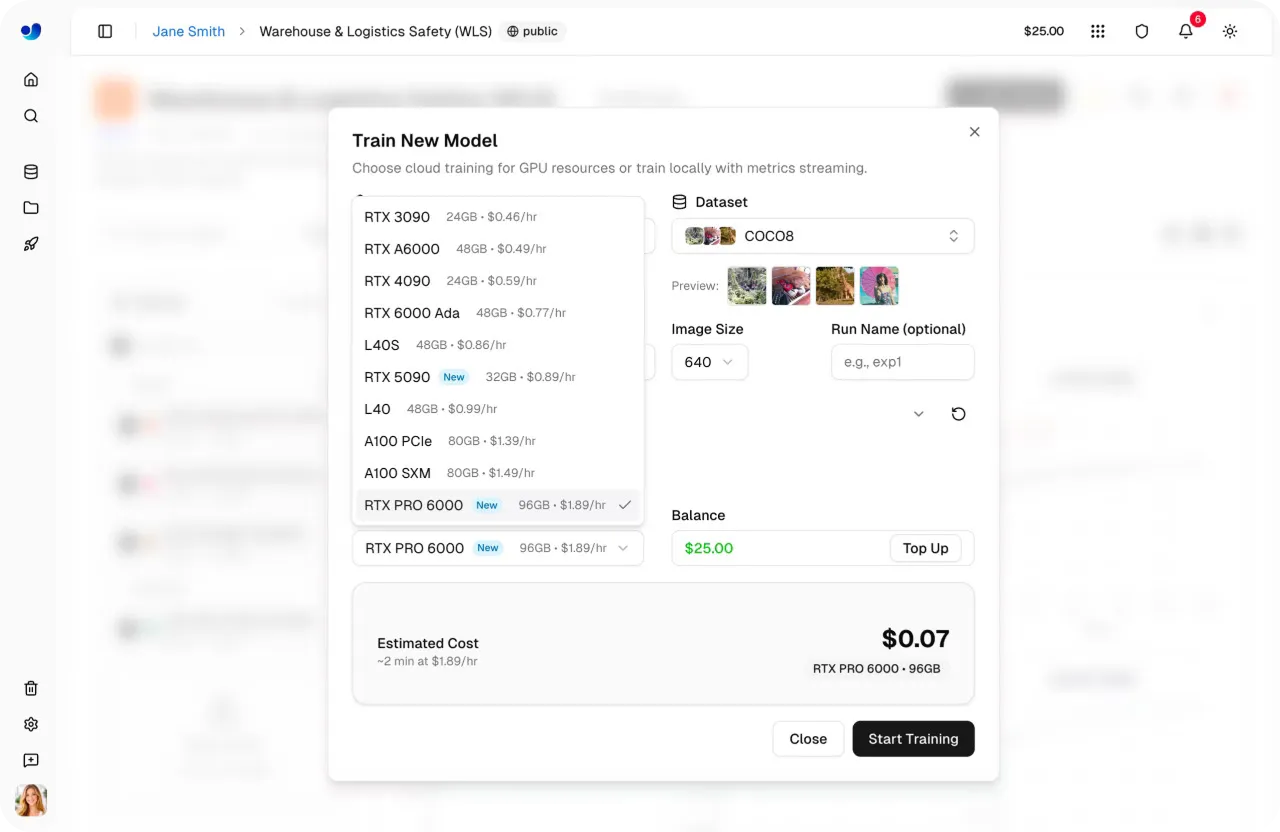
Fig 2. Algunas de las opciones de GPU habilitadas a través de Ultralytics Platform (Fuente)
Link to this sectionPaso 5: Iniciar el entrenamiento en la nube#
Una vez que has seleccionado el modelo, el dataset, los parámetros de entrenamiento y la opción de cómputo, iniciar una ejecución de entrenamiento es rápido. Desde el panel de control, puedes lanzar el entrenamiento con un solo clic, y la plataforma se encarga del resto inicializando el entorno y ejecutando el trabajo en la GPU seleccionada.
A medida que comienza el entrenamiento, puedes supervisar el progreso directamente dentro de la plataforma. La pestaña Train proporciona visibilidad en tiempo real de métricas clave, incluyendo métricas de rendimiento, curvas de pérdida, uso del sistema y registros de entrenamiento en directo.
Para obtener más información sobre cómo entrenar localmente o usar Google Colab con Ultralytics Platform, puedes explorar más tutoriales dentro de la documentación de Platform oficial de Ultralytics.
Link to this sectionEvaluación y comparación de modelos en Ultralytics Platform#
Una vez completado el entrenamiento, el siguiente paso es evaluar cómo funciona tu modelo. En Ultralytics Platform, puedes comparar múltiples ejecuciones de entrenamiento dentro de un proyecto, dándote una visión clara de cómo funcionan los diferentes experimentos.
Al desarrollar modelos, el entrenamiento a menudo se repite varias veces con diferentes configuraciones, como cambiar la tasa de aprendizaje, el tamaño del lote o el tamaño del modelo, para mejorar los resultados. Cada una de estas ejecuciones produce un modelo ligeramente diferente, que es por lo que compararlas es vital.
Los proyectos actúan como un centro neurálgico donde los modelos y los experimentos se organizan juntos. Puedes realizar un seguimiento del progreso, revisar los resultados y mantenerte enfocado sin cambiar entre diferentes herramientas o vistas.
Desde esta vista unificada, también puedes analizar métricas de rendimiento clave como la precisión (precision), la recuperación (recall) y el mAP (precisión media media) para entender cómo funciona tu modelo en diferentes clases. También puedes comparar ejecuciones de entrenamiento lado a lado para identificar qué configuraciones ofrecen los mejores resultados.
Para complementar estas métricas, puedes utilizar la pestaña Predict para probar rápidamente los modelos entrenados en imágenes o datos de muestra, ayudándote a validar visualmente el rendimiento y detectar posibles problemas.
Con estos conocimientos, puedes seleccionar el modelo de mejor rendimiento, normalmente guardado como el punto de control “best.pt”, y pasar a la siguiente etapa, ya sea una evaluación adicional, usar el modelo para ejecutar inferencia o el despliegue del modelo a través de la plataforma.
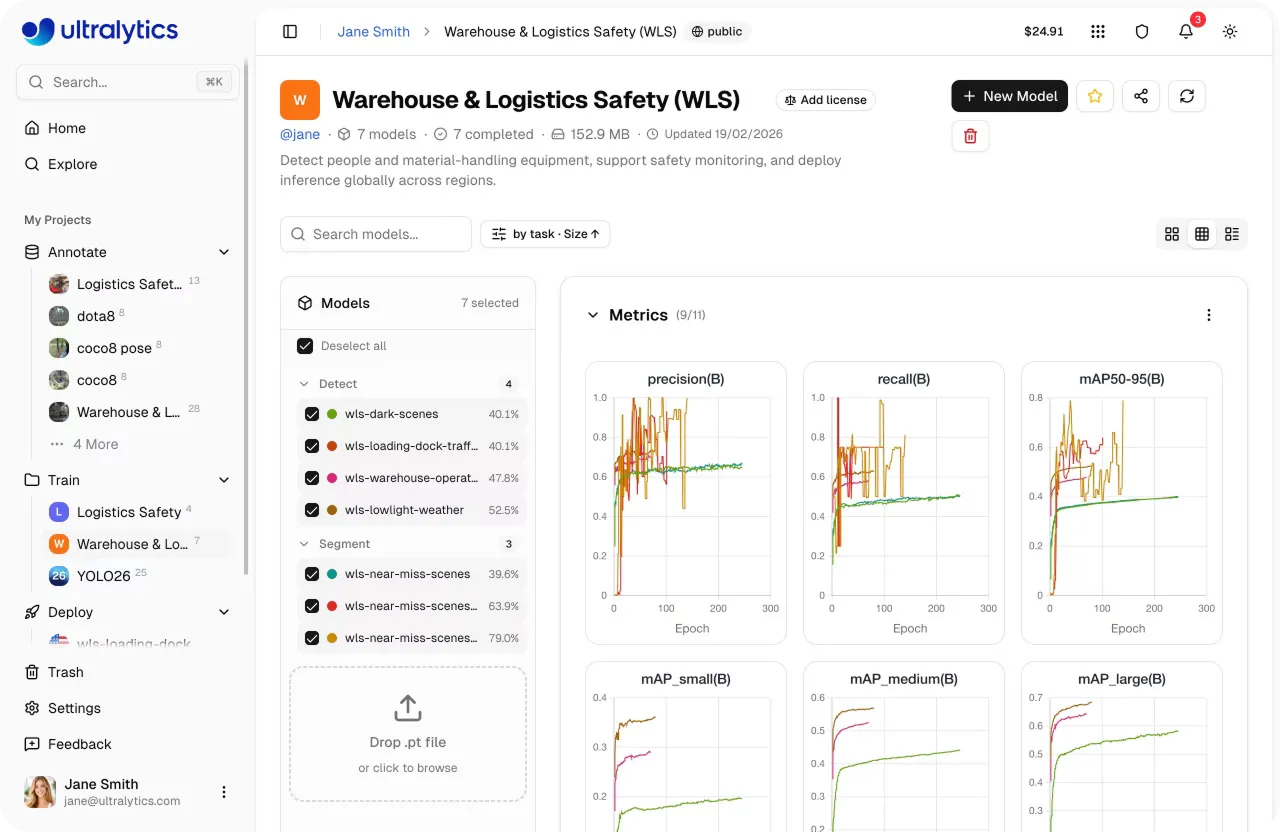
Fig 3. Un ejemplo de visualización de métricas en Ultralytics Platform (Fuente)
Link to this sectionEstimación del costo de entrenamiento dentro de Ultralytics Platform#
Entrenar modelos de detección de objetos en la nube conlleva costos de cómputo, especialmente cuando accedes a GPUs de alto rendimiento. Para hacerlo más cómodo, Ultralytics Platform proporciona una estimación de costos antes de que comience el entrenamiento.
Te ofrece una visibilidad clara del uso esperado, ayudándote a planificar cargas de trabajo, gestionar presupuestos y evitar gastos inesperados antes de lanzar un trabajo de entrenamiento. Aquí tienes cómo puedes comprobar los costos estimados antes de empezar el entrenamiento.
Link to this sectionCómo se estima el tiempo de entrenamiento#
Para estimar el costo con precisión, la plataforma calcula primero cuánto tiempo llevará una sola epoch de entrenamiento. Esto depende de factores como el tamaño del dataset, el tamaño del modelo, la resolución de la imagen, el tamaño del lote y la velocidad de la GPU seleccionada.
Usando estas entradas, determina el tiempo estimado por epoch y lo escala a toda la ejecución de entrenamiento. La duración total se calcula combinando el tiempo de todas las epochs con una pequeña sobrecarga inicial de puesta en marcha.
La sobrecarga tiene en cuenta tareas como inicializar el entorno, cargar datasets y preparar la GPU, asegurando que la estimación refleje el proceso de entrenamiento completo, no solo el bucle de entrenamiento.
Link to this sectionCómo se calcula el costo de entrenamiento#
Una vez que se estima el tiempo total de entrenamiento, la plataforma lo convierte a costo utilizando la tarifa por hora de la GPU seleccionada.
Al combinar la duración del entrenamiento con el precio de la GPU, podemos obtener una estimación clara de cuánto costará la ejecución incluso antes de que comience.
Tener visibilidad por adelantado hace que sea fácil ajustar tu configuración, como ajustar los parámetros de entrenamiento o seleccionar una GPU diferente, para que puedas equilibrar el rendimiento y el costo de manera más eficaz.
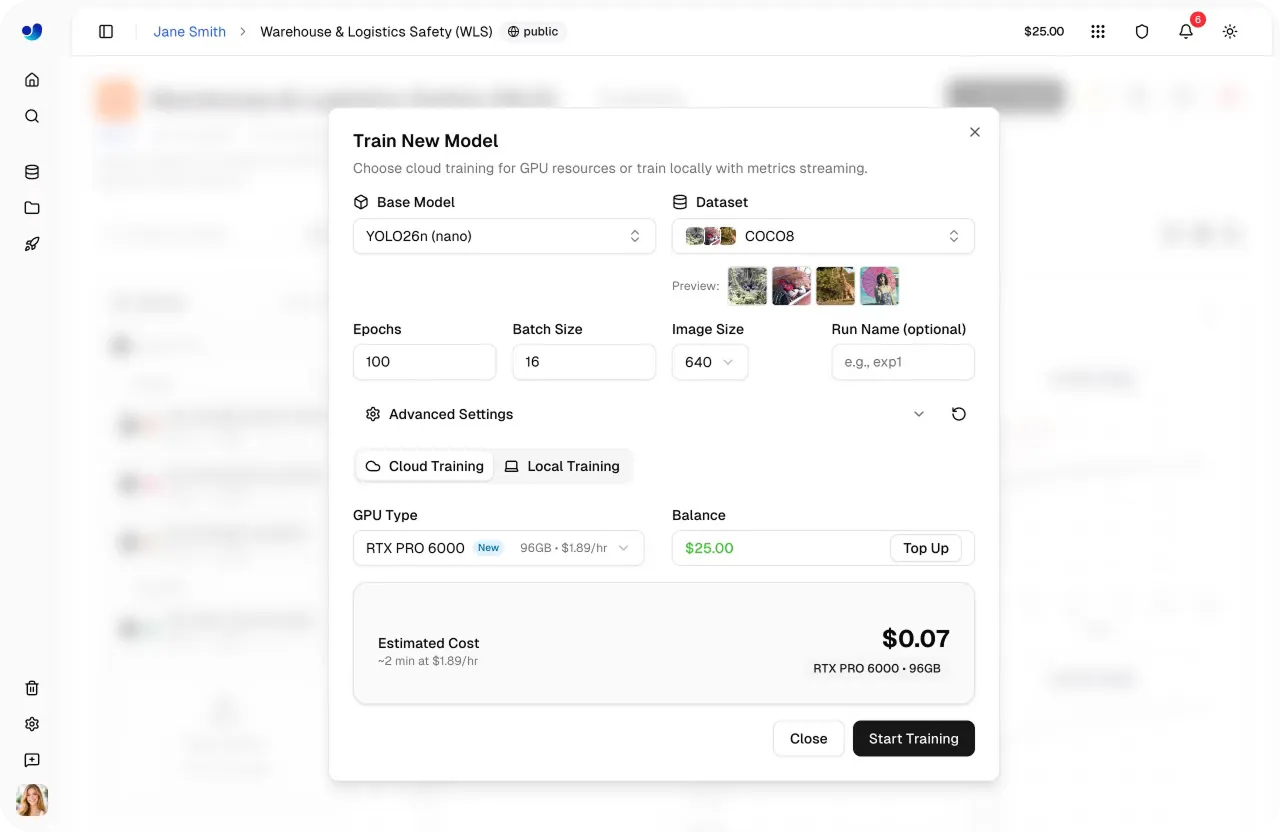
Fig 4. Configuración del entrenamiento de modelos y estimación de costos dentro de Ultralytics Platform (Fuente)
Link to this sectionVentajas clave de usar Ultralytics Platform para el entrenamiento de modelos#
Hasta ahora, hemos repasado los pasos clave involucrados en el entrenamiento de modelos de visión artificial y cómo se unen en Ultralytics Platform.
Más allá de estas funciones principales, hay capacidades adicionales que mejoran el flujo de trabajo de entrenamiento. Aquí tienes una visión general de algunos de los beneficios clave de usar Ultralytics Platform para el entrenamiento de modelos:
- Reproducibilidad de experimentos incorporada: Cada ejecución de entrenamiento se registra automáticamente con su configuración completa, incluyendo el modelo, el dataset, los parámetros y la configuración de cómputo. Esto hace que sea sencillo volver a visitar experimentos y reproducir resultados de manera fiable.
- Perspectivas de entrenamiento a lo largo del tiempo: en lugar de solo ver los resultados finales, puedes realizar un seguimiento de cómo evoluciona el rendimiento a través de las épocas, lo que te ayuda a entender mejor el comportamiento del modelo durante el entrenamiento.
- Menor carga operativa: al gestionar la configuración del entorno, la gestión de dependencias y la infraestructura en segundo plano, la plataforma te permite centrarte más en el desarrollo del modelo y menos en la configuración.
- Organización centralizada de experimentos: los proyectos actúan como un lugar único para gestionar modelos, conjuntos de datos y ejecuciones de entrenamiento, lo que ayuda a mantener los experimentos estructurados a medida que los flujos de trabajo se vuelven más complejos.
Link to this sectionConclusiones clave#
El entrenamiento es una de las etapas más importantes en el ciclo de vida de un modelo de aprendizaje automático. Determina con qué precisión puede un modelo reconocer e interpretar datos visuales.
Al combinar la configuración de datos de entrenamiento, el seguimiento, la comparación de experimentos y la estimación de costes en un único entorno, la Ultralytics Platform optimiza el proceso de creación de modelos de visión artificial de alto rendimiento y su preparación para el despliegue.
Echa un vistazo a nuestra creciente comunidad y GitHub repository para aprender más sobre computer vision. Si buscas construir soluciones de visión, echa un vistazo a nuestras opciones de licencia. Explora nuestras páginas de soluciones para saber más sobre los beneficios de computer vision en fabricación y IA en agricultura.






