Les avantages du fait qu'Ultralytics YOLO11 soit un détecteur sans ancres
Comprends comment Ultralytics YOLO11 prend en charge la détection d'objets sans ancres et les avantages que cette architecture de modèle apporte à diverses applications.

Si nous nous penchons sur l'histoire des modèles de Vision AI, le concept de détection d'objets - une tâche fondamentale de vision par ordinateur qui consiste à identifier et localiser des objets au sein d'une image ou d'une vidéo - existe depuis les années 1960. Cependant, la raison principale de son importance dans les innovations de pointe aujourd'hui est que les techniques de détection d'objets et les architectures de modèles ont progressé et se sont rapidement améliorées depuis.
Dans un article précédent, nous avons discuté de l'évolution de la détection d'objets et du chemin qui a mené aux modèles YOLO d'Ultralytics. Aujourd'hui, nous allons nous concentrer sur l'exploration d'une étape plus spécifique de ce parcours : le passage des détecteurs basés sur des ancres aux détecteurs sans ancres.
Les détecteurs basés sur des ancres s'appuient sur des boîtes prédéfinies, appelées "ancres", pour prédire où se trouvent les objets dans une image. À l'inverse, les détecteurs sans ancres ignorent ces boîtes prédéfinies et prédisent directement les emplacements des objets.
Bien que ce changement puisse sembler simple et logique, il a en réalité conduit à des améliorations majeures en termes de précision et d'efficacité de la détection d'objets. Dans cet article, nous comprendrons comment les détecteurs sans ancres ont remodelé la vision par ordinateur grâce à des avancées telles que Ultralytics YOLO11.
Link to this sectionQu'est-ce que les détecteurs basés sur des ancres ?#
Les détecteurs basés sur des ancres utilisent des boîtes prédéfinies, connues sous le nom d'ancres, pour aider à localiser les objets dans une image. Imagine ces ancres comme une grille de boîtes de différentes tailles et formes placées sur l'image. Le modèle ajuste ensuite ces boîtes pour qu'elles s'adaptent aux objets qu'il détecte. Par exemple, si le modèle identifie une voiture, il modifiera la boîte d'ancrage pour correspondre plus précisément à la position et à la taille de la voiture.
Chaque ancre est associée à un objet possible dans l'image, et pendant l'entraînement, le modèle apprend à ajuster les boîtes d'ancrage pour mieux correspondre à l'emplacement, à la taille et au rapport hauteur/largeur de l'objet. Cela permet au modèle de détecter des objets à différentes échelles et orientations. Cependant, la sélection du bon ensemble de boîtes d'ancrage peut prendre du temps, et le processus de réglage fin peut être sujet à des erreurs.
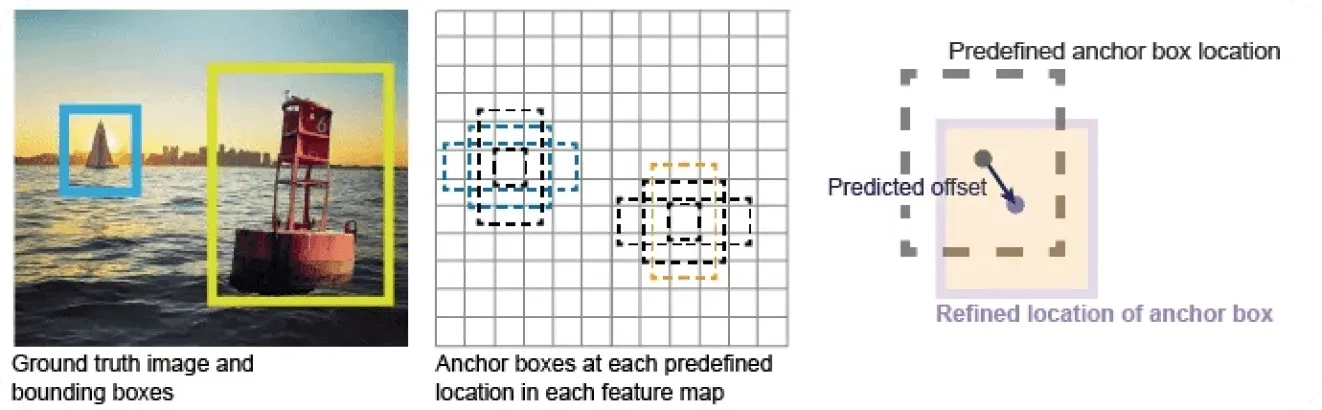
Fig 1. Qu'est-ce qu'une boîte d'ancrage ?
Bien que les détecteurs basés sur des ancres, comme YOLOv4, aient bien fonctionné dans de nombreuses applications, ils présentent certains inconvénients. Par exemple, les boîtes d'ancrage ne s'alignent pas toujours bien avec des objets de formes ou de tailles différentes, ce qui rend plus difficile la détection d'objets petits ou de formes irrégulières par le modèle. Le processus de sélection et de réglage fin des tailles des boîtes d'ancrage peut également être long et nécessiter beaucoup d'efforts manuels. En outre, les modèles basés sur des ancres ont souvent du mal à détecter des objets occlus ou qui se chevauchent, car les boîtes prédéfinies peuvent ne pas bien s'adapter à ces scénarios plus complexes.
Link to this sectionLe passage à la détection d'objets sans ancres#
Les détecteurs sans ancres ont commencé à attirer l'attention en 2018 avec des modèles comme CornerNet et CenterNet, qui ont adopté une nouvelle approche de la détection d'objets en éliminant le besoin de boîtes d'ancrage prédéfinies. Contrairement aux modèles traditionnels qui s'appuient sur des boîtes d'ancrage de différentes tailles et formes pour prédire où se trouvent les objets, les modèles sans ancres prédisent directement les emplacements des objets. Ils se concentrent sur des points clés ou des caractéristiques de l'objet, comme le centre, ce qui simplifie le processus de détection et le rend plus rapide et plus précis.
Voici comment fonctionnent généralement les modèles sans ancres :
- Détection de points clés : Au lieu d'utiliser des boîtes prédéfinies, certains modèles identifient des points importants sur un objet, comme le centre ou des coins spécifiques. Ces points clés aident les modèles à déterminer où se trouve l'objet et quelle est sa taille.
- Prédiction du centre (prediction) : Certains modèles se concentrent sur la prédiction du centre d'un objet. Une fois le centre localisé, le modèle peut prédire la taille et la position de l'objet entier à partir de là.
- Régression par carte thermique : De nombreux modèles sans ancres utilisent des cartes thermiques (heatmaps), où chaque pixel représente un emplacement possible d'un objet. Des valeurs de carte thermique plus fortes indiquent une plus grande confiance dans la présence d'un objet à ce point.
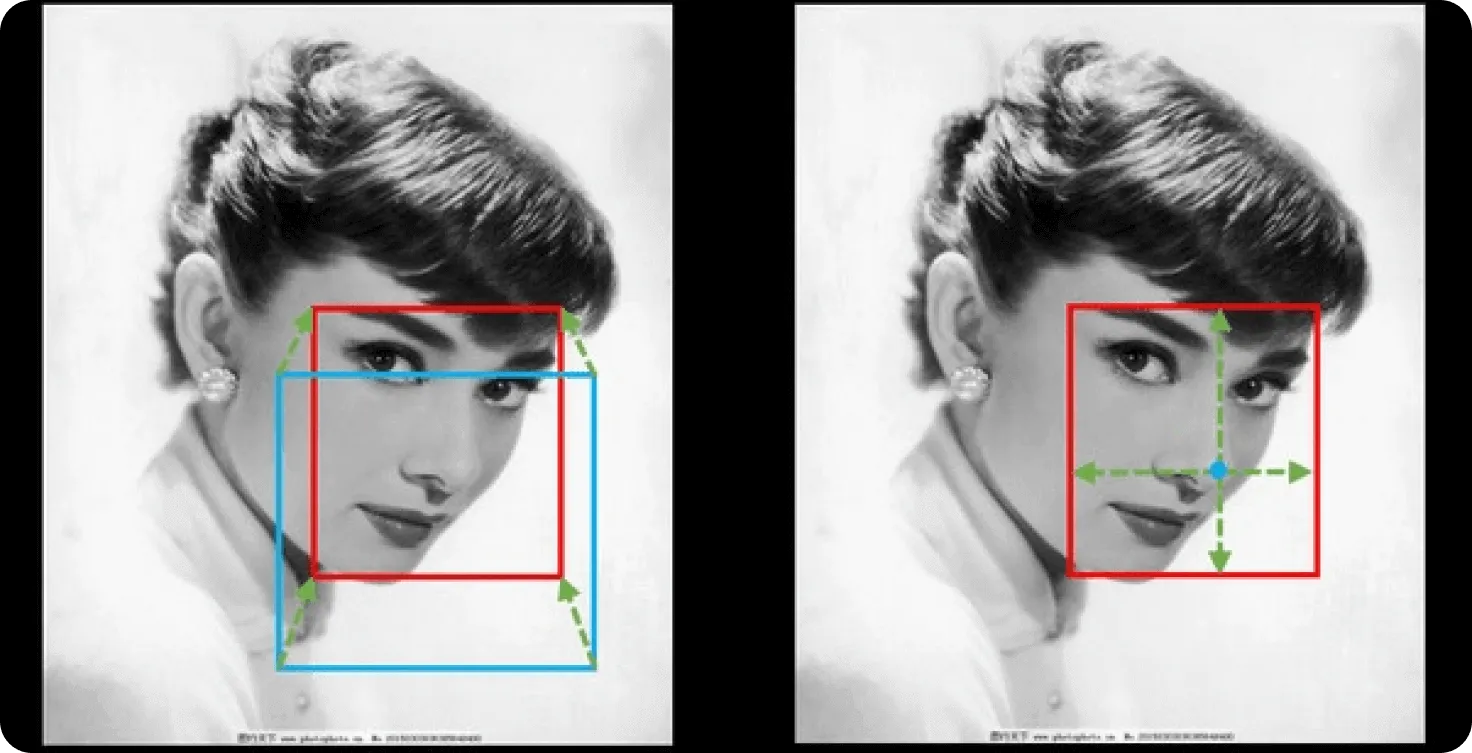
Fig 2. Détection basée sur des ancres Vs. détection sans ancres.
Parce que les modèles sans ancres ne reposent pas sur des boîtes d'ancrage, ils ont une conception plus simple. Cela signifie qu'ils sont plus efficaces sur le plan informatique. Comme ils n'ont pas à traiter plusieurs boîtes d'ancrage, ils peuvent détecter les objets plus rapidement - un avantage important dans les applications en temps réel comme la conduite autonome et la vidéosurveillance.
Les modèles sans ancres sont également bien meilleurs pour gérer les objets petits, irréguliers ou obstrués. Puisqu'ils se concentrent sur la détection de points clés plutôt que d'essayer d'ajuster des boîtes d'ancrage, ils sont beaucoup plus flexibles. Cela leur permet de détecter des objets précisément dans des environnements encombrés ou complexes où les modèles basés sur les ancres peuvent échouer.
Link to this sectionUltralytics YOLO11 : Un détecteur sans ancres#
Conçus à l'origine pour la vitesse et l'efficacité, les modèles YOLO sont progressivement passés des méthodes basées sur des ancres à la détection sans ancres, rendant des modèles comme YOLO11 plus rapides, plus flexibles et mieux adaptés à un large éventail d'applications en temps réel.
Voici un aperçu rapide de la façon dont la conception sans ancres a évolué à travers les différentes versions de YOLO :
- Ultralytics YOLOv5u : A introduit la tête de détection "Anchor-Free Split Ultralytics Head", supprimant le besoin de boîtes d'ancrage prédéfinies. Au lieu de cela, le modèle prédit directement où se trouvent les objets dans une image, simplifiant le processus et améliorant la flexibilité et la vitesse.
- YOLOv6 : Une nouvelle méthode appelée Anchor-Aided Training (AAT) a été utilisée, où les ancres n'étaient utilisées que pendant l'entraînement. Cela a permis au modèle de bénéficier de la structure des méthodes basées sur des ancres pendant l'entraînement, tout en utilisant la détection sans ancres au moment de l'exécution pour une meilleure vitesse et adaptabilité.
- Ultralytics YOLOv8 : Est passé entièrement à la détection sans ancres en utilisant la tête de détection "Anchor-Free Split Ultralytics Head". Cela a rendu le modèle plus rapide et plus précis, en particulier pour les objets petits ou de forme étrange qui ne correspondent pas bien aux boîtes d'ancrage.
- Ultralytics YOLO11 : S'appuie sur l'approche sans ancres de YOLOv8, optimisant encore davantage la détection en éliminant complètement les boîtes d'ancrage. Cela se traduit par une détection plus rapide et plus précise pour les applications en temps réel comme le suivi du comportement animal et l'analyse de détail.
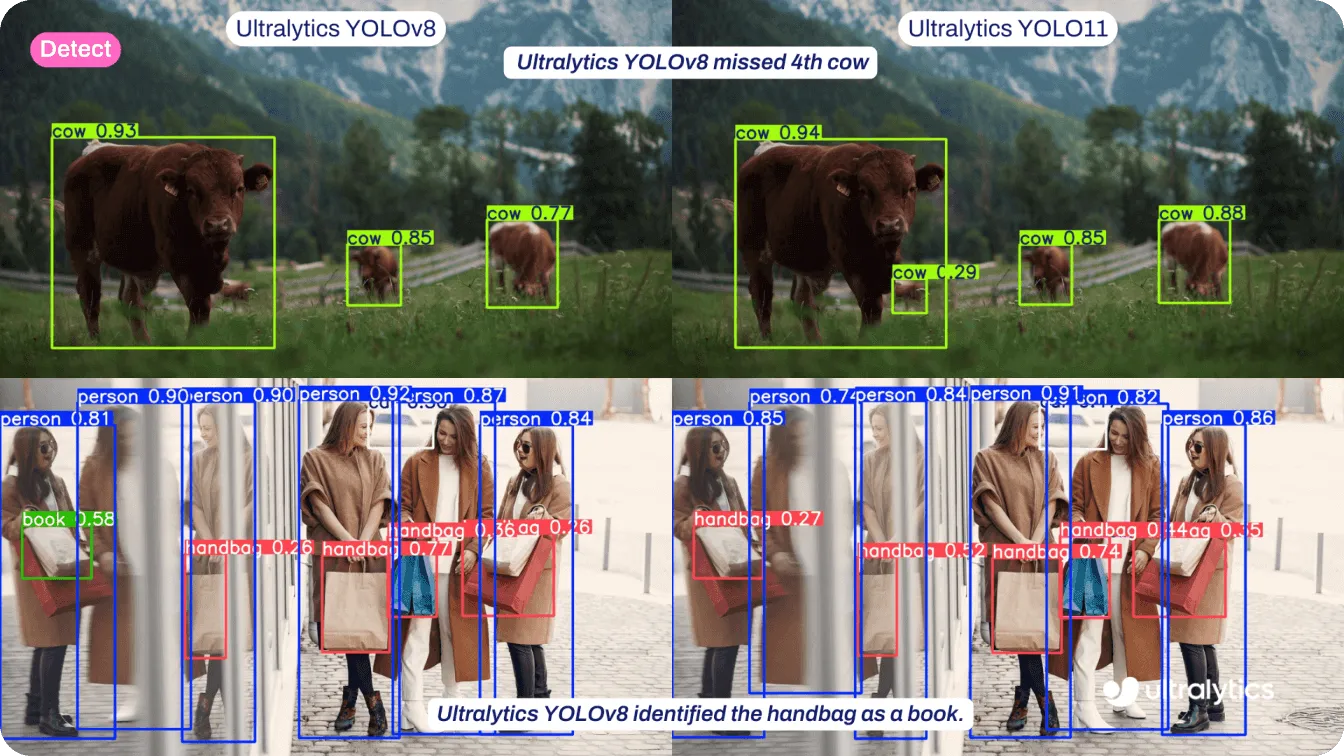
Fig 3. Comparaison d'Ultralytics YOLOv8 et d'Ultralytics YOLO11.
Link to this sectionApplications réelles de YOLO11#
Un excellent exemple des avantages de la détection sans ancres avec YOLO11 se trouve dans les véhicules autonomes. Dans les voitures autonomes, détecter rapidement et précisément les piétons, les autres véhicules et les obstacles est crucial pour la sécurité. L'approche sans ancres de YOLO11 simplifie le processus de détection en prédisant directement les points clés des objets, comme le centre d'un piéton ou les limites d'un autre véhicule, plutôt que de s'appuyer sur des boîtes d'ancrage prédéfinies.

Fig 4. Avantages de la détection sans ancres dans YOLO11 (Image de l'auteur).
YOLO11 n'a pas besoin d'ajuster ou d'adapter une grille d'ancres à chaque objet, ce qui peut être coûteux en calcul et lent. Au lieu de cela, il se concentre sur les caractéristiques clés, ce qui le rend plus rapide et plus efficace. Par exemple, lorsqu'un piéton s'engage sur la trajectoire du véhicule, YOLO11 peut identifier rapidement son emplacement en localisant les points clés, même si la personne est partiellement cachée ou en mouvement. La capacité à s'adapter à des formes et des tailles variables sans boîtes d'ancrage permet à YOLO11 de détecter les objets de manière plus fiable et à des vitesses plus élevées, ce qui est vital pour la prise de décision en temps réel dans les systèmes de conduite autonome.
Parmi les autres applications où les capacités sans ancres de YOLO11 se démarquent vraiment, on peut citer :
- Gestion du commerce de détail et des stocks : YOLO11 facilite la surveillance des produits sur les étagères, même lorsqu'ils sont empilés ou partiellement bloqués. Cela permet un suivi des stocks plus rapide et plus précis et réduit les erreurs.
- Imagerie médicale : YOLO11 est également efficace dans le domaine de la santé, où il peut détecter des tumeurs ou d'autres anomalies dans les examens médicaux. Sa capacité à travailler avec des objets de forme irrégulière aide à améliorer la précision du diagnostic de pathologies complexes.
- Surveillance de la faune : Dans la recherche sur la faune, YOLO11 peut suivre les animaux dans des forêts denses ou sur des terrains difficiles, aidant les chercheurs à surveiller leur comportement ou à protéger les espèces en voie de disparition.
- Analyse sportive : YOLO11 peut être utilisé pour suivre les joueurs, les mouvements du ballon ou d'autres éléments en temps réel lors d'événements sportifs afin de fournir des informations précieuses aux équipes, aux entraîneurs et aux diffuseurs.
Link to this sectionConsidérations à prendre en compte lors du travail avec des modèles sans ancres#
Bien que les modèles sans ancres comme YOLO11 offrent de nombreux avantages, ils présentent certaines limites. L'une des principales considérations pratiques est que même les modèles sans ancres peuvent avoir des difficultés avec les occlusions ou les objets très chevauchants. La raison en est que la vision par ordinateur vise à reproduire la vision humaine, et tout comme nous avons parfois du mal à identifier des objets occlus, les modèles d'IA peuvent rencontrer des défis similaires.
Un autre facteur intéressant est lié au traitement des prédictions du modèle. Bien que l'architecture des modèles sans ancres soit plus simple que celle basée sur les ancres, un affinement supplémentaire devient nécessaire dans certains cas. Par exemple, des techniques de post-traitement comme la non-maximum suppression (NMS) peuvent être nécessaires pour nettoyer les prédictions qui se chevauchent ou améliorer la précision dans des scènes encombrées.
Link to this sectionAncrer l'avenir de l'IA avec YOLO11#
Le passage de la détection basée sur des ancres à la détection sans ancres a constitué une avancée significative dans la détection d'objets. Avec des modèles sans ancres comme YOLO11, le processus est simplifié, ce qui conduit à des améliorations tant en termes de précision que de vitesse.
Grâce à YOLO11, nous avons vu comment la détection d'objets sans ancres excelle dans les applications en temps réel comme les voitures autonomes, la vidéosurveillance et l'imagerie médicale, où une détection rapide et précise est cruciale. Cette approche permet à YOLO11 de s'adapter plus facilement à des tailles d'objets variables et à des scènes complexes, offrant de meilleures performances dans des environnements divers.
À mesure que la vision par ordinateur continue d'évoluer, la détection d'objets ne fera que devenir plus rapide, plus flexible et plus efficace.
Explore notre dépôt GitHub et rejoins notre communauté dynamique pour rester informé de tout ce qui concerne l'IA. Découvre comment la vision par IA impacte des secteurs comme la fabrication et l'agriculture.






