Tối ưu hóa mô hình là gì? Hướng dẫn nhanh
Tìm hiểu cách các kỹ thuật tối ưu hóa mô hình như điều chỉnh siêu tham số (hyperparameter tuning), cắt tỉa mô hình (model pruning) và lượng tử hóa mô hình (model quantization) giúp các mô hình thị giác máy tính vận hành hiệu quả hơn.

Tối ưu hóa model là một quy trình nhằm cải thiện hiệu suất và performance của các model machine learning. Bằng cách tinh chỉnh cấu trúc và chức năng của model, việc tối ưu hóa giúp model mang lại kết quả tốt hơn với computational resources tối thiểu cùng thời gian training và evaluation được rút ngắn.
Quy trình này đặc biệt quan trọng trong các lĩnh vực như computer vision, nơi các models thường đòi hỏi tài nguyên đáng kể để phân tích các complex images. Trong các môi trường bị hạn chế về tài nguyên như mobile devices hoặc các hệ thống edge, các model đã tối ưu hóa có thể hoạt động tốt với tài nguyên hạn hẹp mà vẫn đảm bảo độ chính xác.
Nhiều kỹ thuật thường được sử dụng để đạt được mục tiêu tối ưu hóa model, bao gồm hyperparameter tuning, model pruning, model quantization và mixed precision. Trong bài viết này, chúng ta sẽ khám phá các kỹ thuật này cùng những lợi ích mà chúng mang lại cho các computer vision applications. Hãy cùng bắt đầu nhé!
Link to this sectionTìm hiểu về tối ưu hóa model#
Computer vision models thường có các deep layers và cấu trúc phức tạp, rất hiệu quả trong việc nhận diện các mẫu hình tinh vi trong hình ảnh, nhưng chúng cũng có thể đòi hỏi khắt khe về processing power. Khi các model này được deployed trên các thiết bị có phần cứng hạn chế, như mobile phones hoặc edge devices, chúng có thể gặp phải một số thách thức hoặc hạn chế nhất định.
Tốc độ xử lý, bộ nhớ và năng lượng hạn chế trên các thiết bị này có thể dẫn đến sự sụt giảm performance đáng kể do model khó có thể đáp ứng được yêu cầu. Các kỹ thuật tối ưu hóa model là chìa khóa để giải quyết những vấn đề này. Chúng giúp tinh giản model, giảm computational needs và đảm bảo model vẫn hoạt động hiệu quả dù tài nguyên có hạn. Tối ưu hóa model có thể thực hiện bằng cách đơn giản hóa model architecture, giảm precision của các phép tính, hoặc loại bỏ các thành phần không cần thiết để model trở nên nhẹ và nhanh hơn.
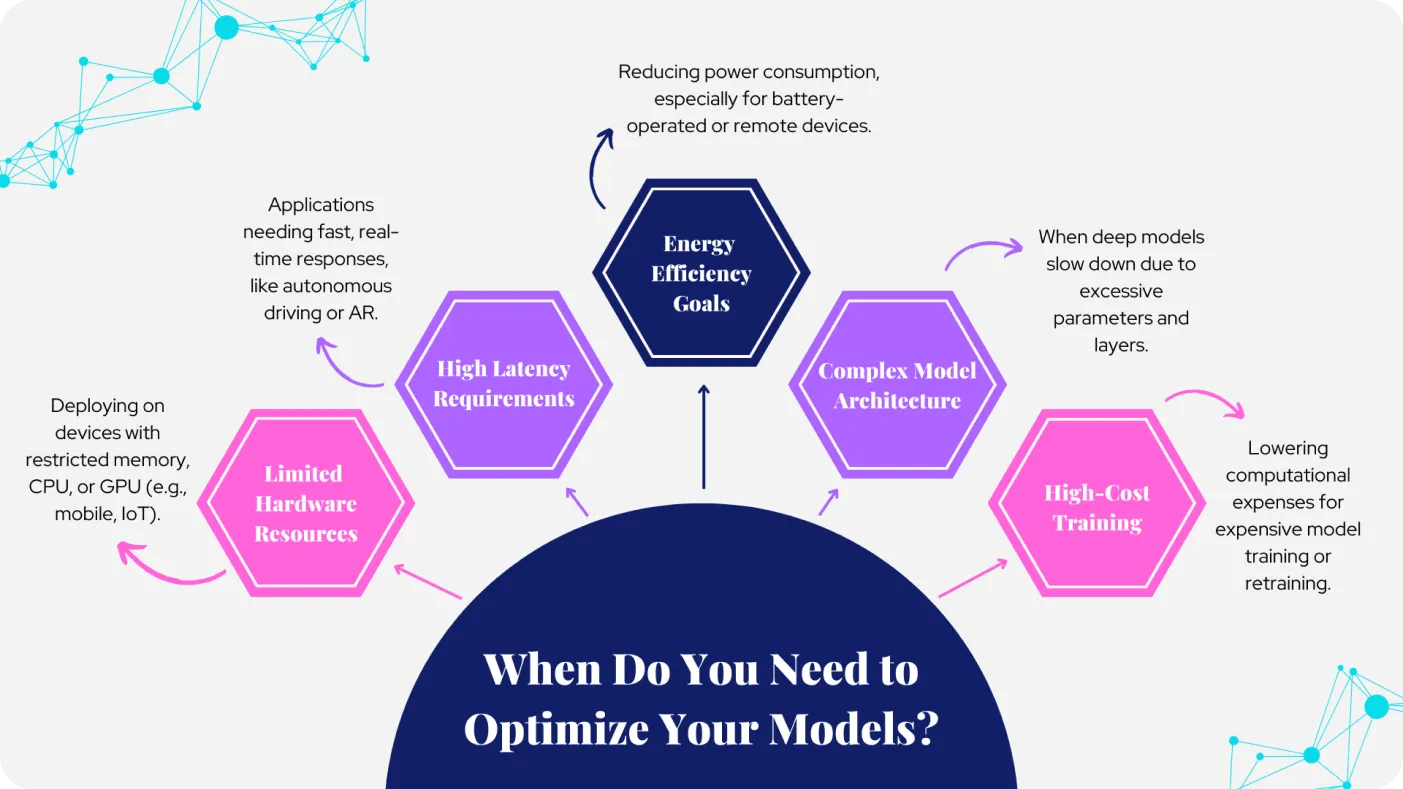
Hình 1. Lý do cần tối ưu hóa các model của bạn. Ảnh bởi tác giả.
Dưới đây là một số kỹ thuật optimization model phổ biến nhất mà chúng ta sẽ tìm hiểu chi tiết hơn trong các phần tiếp theo:
- Hyperparameter tuning: Liên quan đến việc điều chỉnh hệ thống các hyperparameter, chẳng hạn như learning rate và batch size, để cải thiện hiệu suất của model.
- Model pruning: Kỹ thuật này loại bỏ các trọng số và kết nối không cần thiết khỏi neural network, làm giảm độ phức tạp và chi phí tính toán.
- Model quantization: Quantization bao gồm việc giảm độ chính xác của trọng số và activation của model, thường từ 32-bit xuống 16-bit hoặc 8-bit, giúp giảm đáng kể dung lượng bộ nhớ và yêu cầu tính toán.
- Precision adjustments: Còn được gọi là huấn luyện mixed precision, kỹ thuật này sử dụng các định dạng độ chính xác khác nhau cho các phần khác nhau của model để tối ưu hóa việc sử dụng tài nguyên mà không làm ảnh hưởng đến độ chính xác.
Link to this sectionGiải thích: Hyperparameters trong các model machine learning#
Bạn có thể giúp model học và hoạt động tốt hơn bằng cách điều chỉnh các hyperparameter - đây là các thiết lập định hình cách model học từ dữ liệu. Hyperparameter tuning là một kỹ thuật tối ưu hóa các thiết lập này, giúp cải thiện hiệu suất và accuracy của model. Khác với các parameter mà model tự học trong quá trình training, các hyperparameter là các giá trị được đặt trước để dẫn dắt quy trình training.
Hãy cùng xem qua một số ví dụ về hyperparameter có thể điều chỉnh:
- Learning rate: Parameter này kiểm soát kích thước bước nhảy mà model thực hiện để điều chỉnh các trọng số bên trong. Một learning rate cao hơn có thể tăng tốc độ học nhưng có nguy cơ bỏ lỡ giải pháp tối ưu, trong khi một mức thấp hơn có thể chính xác hơn nhưng lại chậm hơn.
- Batch size: Xác định số lượng mẫu dữ liệu được xử lý trong mỗi bước training. Các batch size lớn hơn mang lại quá trình học ổn định hơn nhưng cần nhiều bộ nhớ hơn. Các batch nhỏ hơn giúp training nhanh hơn nhưng có thể kém ổn định hơn.
- Epochs: Bạn có thể xác định số lần model quan sát toàn bộ dataset thông qua parameter này. Nhiều epoch hơn có thể cải thiện độ chính xác nhưng cũng có nguy cơ gây overfitting.
- Kernel size: Xác định kích thước bộ lọc trong các Convolutional Neural Networks (CNNs). Các kernel lớn hơn ghi lại các mẫu hình rộng hơn nhưng cần nhiều năng lực xử lý hơn; các kernel nhỏ hơn tập trung vào các chi tiết tinh vi hơn.
Link to this sectionCách thức hoạt động của hyperparameter tuning#
Việc tinh chỉnh siêu tham số (hyperparameter tuning) thường bắt đầu bằng việc xác định phạm vi các giá trị khả thi cho từng siêu tham số. Sau đó, một thuật toán tìm kiếm sẽ khám phá các tổ hợp khác nhau trong các phạm vi này để xác định những thiết lập mang lại hiệu suất tốt nhất.
Các phương pháp tuning phổ biến bao gồm grid search, random search và Bayesian optimization. Grid search thử nghiệm mọi kết hợp giá trị có thể có trong phạm vi chỉ định. Random search chọn các kết hợp ngẫu nhiên, thường tìm thấy các thiết lập hiệu quả nhanh hơn. Bayesian optimization sử dụng một model xác suất để dự đoán các giá trị hyperparameter triển vọng dựa trên kết quả trước đó. Cách tiếp cận này thường giúp giảm số lần thử nghiệm cần thiết.
Cuối cùng, đối với mỗi kết hợp hyperparameter, hiệu suất của model sẽ được evaluated. Quy trình này được lặp lại cho đến khi đạt được kết quả mong muốn.
Link to this sectionHyperparameters so với model parameters#
Trong khi làm việc với hyperparameter tuning, bạn có thể tự hỏi sự khác biệt giữa hyperparameter và model parameters là gì.
Hyperparameter là các giá trị được thiết lập trước khi training giúp kiểm soát cách model học, chẳng hạn như learning rate hoặc batch size. Các thiết lập này được cố định trong quá trình training và ảnh hưởng trực tiếp đến quy trình học. Ngược lại, model parameter được chính model học trong quá trình training. Chúng bao gồm các trọng số và biases, vốn tự điều chỉnh khi model học và cuối cùng dẫn dắt các predictions. Về cơ bản, hyperparameter định hình hành trình học tập, trong khi model parameter là kết quả của quá trình học tập đó.
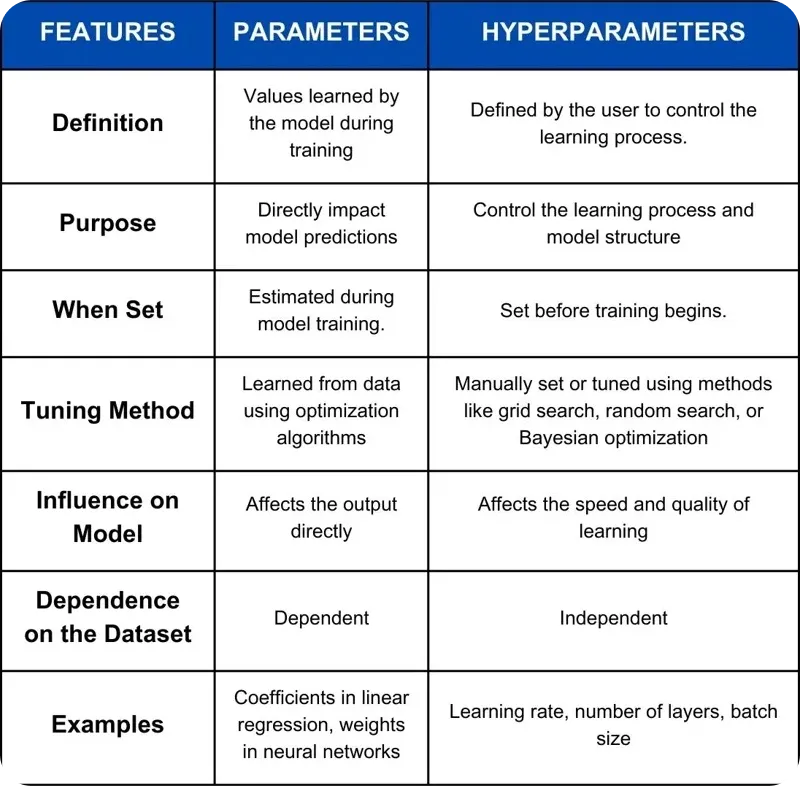
Hình 2. So sánh giữa Parameters và Hyperparameters.
Link to this sectionTại sao model pruning lại quan trọng trong deep learning#
Model pruning là một kỹ thuật giảm kích thước giúp loại bỏ các trọng số và parameter không cần thiết khỏi model, làm cho nó trở nên hiệu quả hơn. Trong computer vision, đặc biệt là với các neural networks sâu, số lượng lớn các parameter như trọng số và activation (các đầu ra trung gian giúp tính toán đầu ra cuối cùng) có thể làm tăng cả độ phức tạp lẫn yêu cầu tính toán. Pruning giúp tinh giản model bằng cách xác định và loại bỏ các parameter đóng góp không đáng kể vào hiệu suất, tạo ra một model nhẹ và hiệu quả hơn.
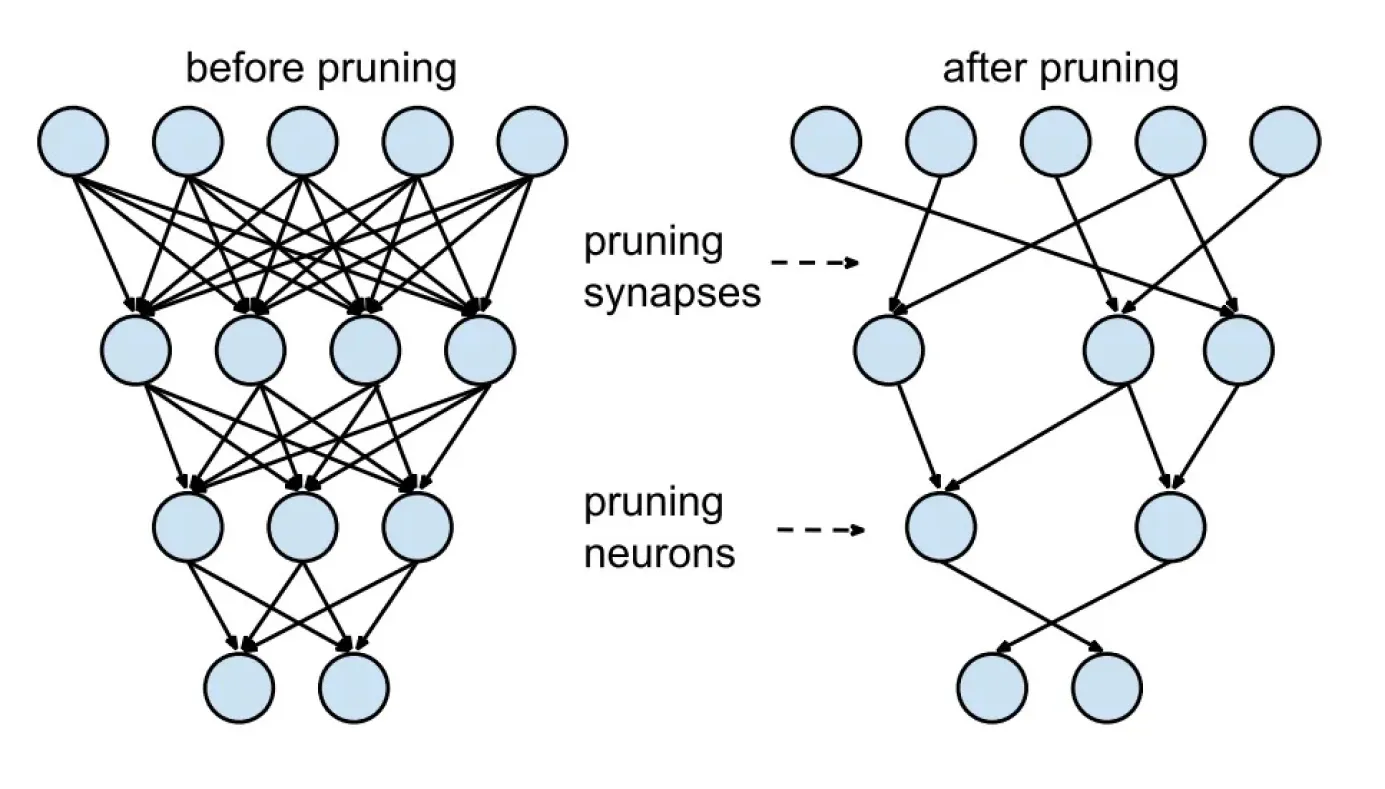
Hình 3. Trước và sau khi model pruning.
Sau khi model được train, các kỹ thuật như magnitude-based pruning hoặc phân tích độ nhạy có thể đánh giá mức độ quan trọng của từng parameter. Các parameter có tầm quan trọng thấp sau đó sẽ được cắt tỉa, sử dụng một trong ba kỹ thuật chính: weight pruning, neuron pruning hoặc structured pruning.
Weight pruning loại bỏ các kết nối riêng lẻ với tác động tối thiểu đến đầu ra. Neuron pruning loại bỏ toàn bộ các neuron có đầu ra đóng góp ít vào chức năng của model. Structured pruning loại bỏ các phần lớn hơn, như bộ lọc convolution hoặc các neuron trong các lớp fully connected, giúp tối ưu hóa hiệu quả của model. Sau khi pruning hoàn tất, model được train lại để fine-tune các parameter còn lại, đảm bảo nó vẫn duy trì độ chính xác cao trong một hình thái rút gọn.
Link to this sectionGiảm độ trễ trong các model AI với quantization#
Model quantization làm giảm số lượng bit được sử dụng để thể hiện các trọng số và activation của model. Kỹ thuật này thường chuyển đổi các giá trị dấu phẩy động 32-bit độ chính xác cao sang các giá trị có độ chính xác thấp hơn, chẳng hạn như số nguyên 16-bit hoặc 8-bit. Bằng cách giảm độ chính xác bit, quantization làm giảm đáng kể model's size, dung lượng bộ nhớ và chi phí tính toán.
Trong computer vision, các số thực 32-bit là tiêu chuẩn, nhưng chuyển đổi sang 16-bit hoặc 8-bit có thể cải thiện hiệu quả. Có hai loại quantization chính: weight quantization và activation quantization. Weight quantization làm giảm độ chính xác của các trọng số trong model, cân bằng giữa việc giảm kích thước và duy trì độ chính xác. Activation quantization làm giảm độ chính xác của các activation, giúp giảm thêm bộ nhớ và yêu cầu tính toán.
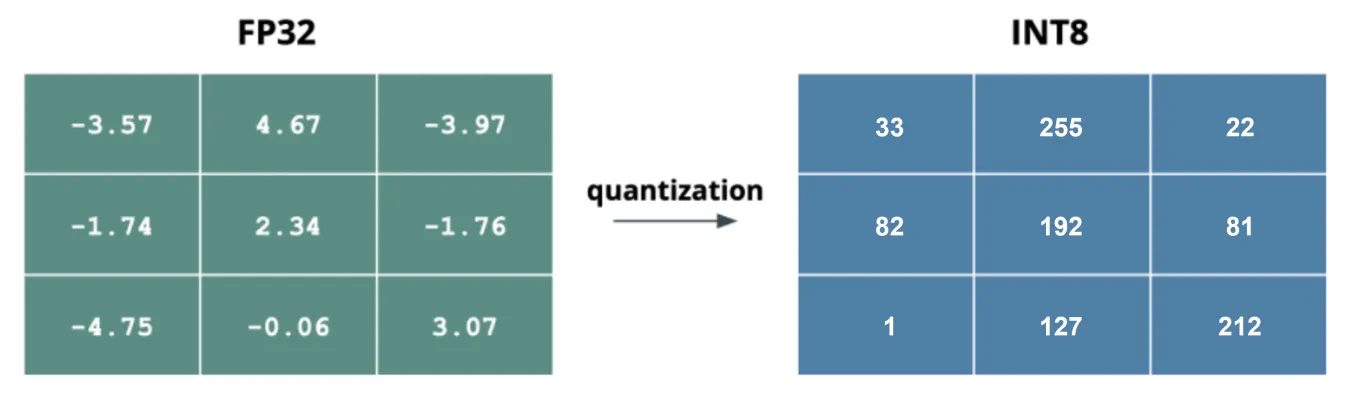
Hình 4. Một ví dụ về quantization từ số thực 32-bit sang số nguyên 8-bit.
Link to this sectionCách mixed precision tăng tốc độ suy luận (inference) cho AI#
Mixed precision là một kỹ thuật sử dụng các độ chính xác số học khác nhau cho các phần khác nhau của một neural network. Bằng cách kết hợp các giá trị độ chính xác cao hơn, chẳng hạn như số thực 32-bit, với các giá trị độ chính xác thấp hơn, như số thực 16-bit hoặc 8-bit, mixed precision cho phép các computer vision models tăng tốc quá trình training và giảm việc sử dụng bộ nhớ mà không làm hy sinh độ chính xác.
Trong quá trình training, mixed precision đạt được bằng cách sử dụng độ chính xác thấp hơn ở các lớp cụ thể trong khi vẫn giữ độ chính xác cao hơn ở những nơi cần thiết trong toàn bộ mạng. Điều này được thực hiện thông qua việc ép kiểu (casting) và chia tỷ lệ tổn thất (loss scaling). Casting chuyển đổi các kiểu dữ liệu giữa các độ chính xác khác nhau theo yêu cầu của model. Loss scaling điều chỉnh độ chính xác đã giảm để ngăn chặn hiện tượng tràn số (numerical underflow), đảm bảo quá trình training ổn định. Mixed precision đặc biệt hữu ích cho các model lớn và các batch size lớn.
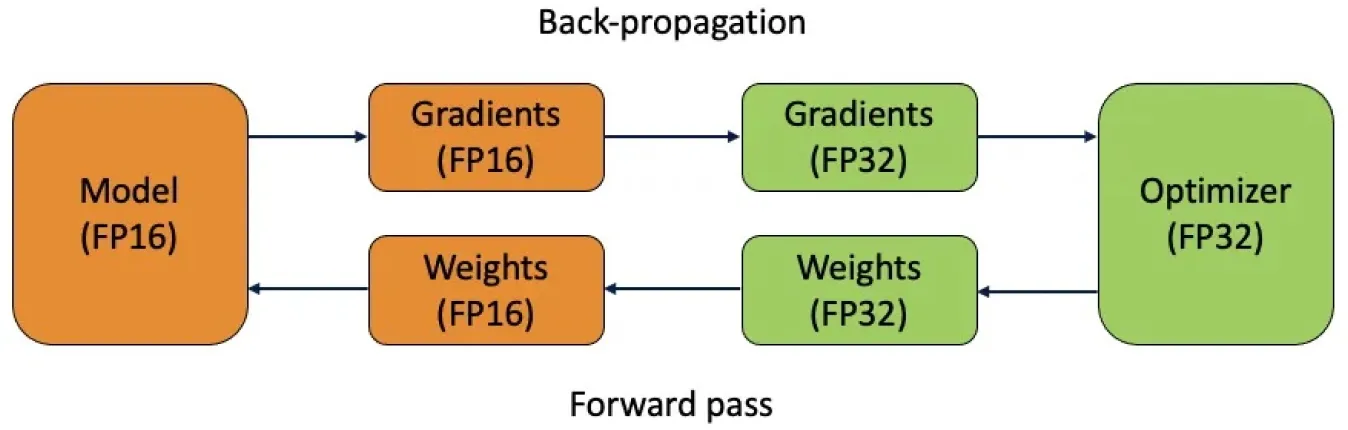
Hình 5. Huấn luyện mixed precision sử dụng cả các kiểu số thực 16-bit (FP16) và 32-bit (FP32).
Link to this sectionCân bằng giữa độ chính xác và hiệu quả của model#
Bây giờ chúng ta đã đề cập đến một số kỹ thuật tối ưu hóa model, hãy thảo luận về cách quyết định kỹ thuật nào để sử dụng dựa trên nhu cầu cụ thể của bạn. Việc lựa chọn phụ thuộc vào các yếu tố như hardware hiện có, các hạn chế về tính toán và bộ nhớ của deployment environment và mức độ chính xác yêu cầu.
Ví dụ, các model nhỏ hơn, nhanh hơn sẽ phù hợp hơn cho các thiết bị di động có tài nguyên hạn chế, trong khi các model lớn hơn, chính xác hơn có thể được sử dụng trên các hệ thống hiệu năng cao. Dưới đây là cách mỗi kỹ thuật phù hợp với different goals:
- Pruning: Lý tưởng để giảm kích thước model mà không làm ảnh hưởng đáng kể đến độ chính xác, khiến nó trở nên hoàn hảo cho các thiết bị bị hạn chế về tài nguyên như điện thoại di động hoặc các thiết bị Internet of Things (IoT).
- Quantization: Một lựa chọn tuyệt vời để thu nhỏ kích thước model và tăng tốc inference, đặc biệt là trên các thiết bị di động và embedded systems có bộ nhớ và tốc độ xử lý hạn chế. Nó hoạt động tốt cho các ứng dụng chấp nhận được việc giảm nhẹ độ chính xác.
- Mixed precision: Được thiết kế cho các model quy mô lớn, kỹ thuật này giảm việc sử dụng bộ nhớ và tăng tốc quá trình training trên các phần cứng như GPU và TPUs hỗ trợ các thao tác mixed-precision. Nó thường được sử dụng trong các tác vụ hiệu năng cao nơi mà hiệu quả là yếu tố quan trọng.
- Hyperparameter tuning: Mặc dù đòi hỏi tài nguyên tính toán cao, kỹ thuật này rất cần thiết cho các ứng dụng yêu cầu độ chính xác cao, chẳng hạn như medical imaging hoặc autonomous driving.
Link to this sectionCác điểm chính cần lưu ý#
Tối ưu hóa model là một phần quan trọng trong machine learning, đặc biệt là đối với việc triển khai AI trong các ứng dụng thực tế. Các kỹ thuật như hyperparameter tuning, model pruning, quantization và mixed precision giúp cải thiện hiệu suất, hiệu quả và mức sử dụng tài nguyên của các computer vision models. Những tối ưu hóa này làm cho model nhanh hơn và ít tiêu tốn tài nguyên hơn, điều này rất lý tưởng cho các thiết bị có bộ nhớ và tốc độ xử lý hạn chế. Các model đã tối ưu hóa cũng dễ dàng mở rộng và triển khai trên các nền tảng khác nhau hơn, cho phép tạo ra các giải pháp AI vừa hiệu quả vừa có khả năng thích ứng với nhiều mục đích sử dụng khác nhau.
Hãy truy cập GitHub repository của Ultralytics và tham gia community của chúng tôi để tìm hiểu thêm về các ứng dụng AI trong manufacturing và agriculture.






