Cómo la Ultralytics Platform simplifica el despliegue de modelos de visión artificial
Mira cómo la Ultralytics Platform reúne todo lo necesario para el despliegue de modelos de visión artificial, desde las pruebas hasta las API listas para producción.
Ultralytics lleva años colaborando con la comunidad de visión artificial, creando modelos y herramientas que hacen que la visión por IA sea más accesible para todo el mundo. Con Ultralytics Platform, damos un paso más allá al integrar todo el flujo de trabajo de desarrollo de visión artificial en un entorno unificado, que cubre desde la gestión y anotación de datasets hasta el entrenamiento, validación y despliegue de modelos.
En particular, nos entusiasma facilitar el despliegue de modelos de visión artificial. A medida que la visión artificial se abre camino en aplicaciones del mundo real, el análisis de imágenes y vídeo fuera de entornos controlados sigue siendo complejo.
A diferencia de los entornos de prueba donde las condiciones son predecibles, los escenarios del mundo real implican una iluminación variable, entradas cambiantes y cargas de trabajo impredecibles, lo que convierte al despliegue en una de las partes más desafiantes del flujo de trabajo de visión.
El despliegue implica mucho más que simplemente poner un modelo a disposición para su uso. Requiere establecer procesos capaces de gestionar datos del mundo real y garantizar que todo funcione sin problemas a medida que aumenta el uso y los proyectos escalan.
Los equipos también necesitan realizar un seguimiento del rendimiento y mantener la fiabilidad a lo largo del tiempo. Esto a menudo significa alternar entre diferentes herramientas de IA para pruebas, integración, despliegue y monitorización, lo cual puede ralentizar el desarrollo del modelo y añadir una complejidad innecesaria.
Los flujos de trabajo terminan fragmentándose. Ultralytics Platform unifica y simplifica este proceso.
Ofrece soporte integrado para el servicio, pruebas y monitorización de modelos dentro de un único entorno. Los equipos pueden validar modelos mediante inferencia basada en navegador, integrarlos en aplicaciones a través de servicios de inferencia compartidos y desplegarlos en puntos de enlace (endpoints) dedicados con capacidades de monitorización de rendimiento.
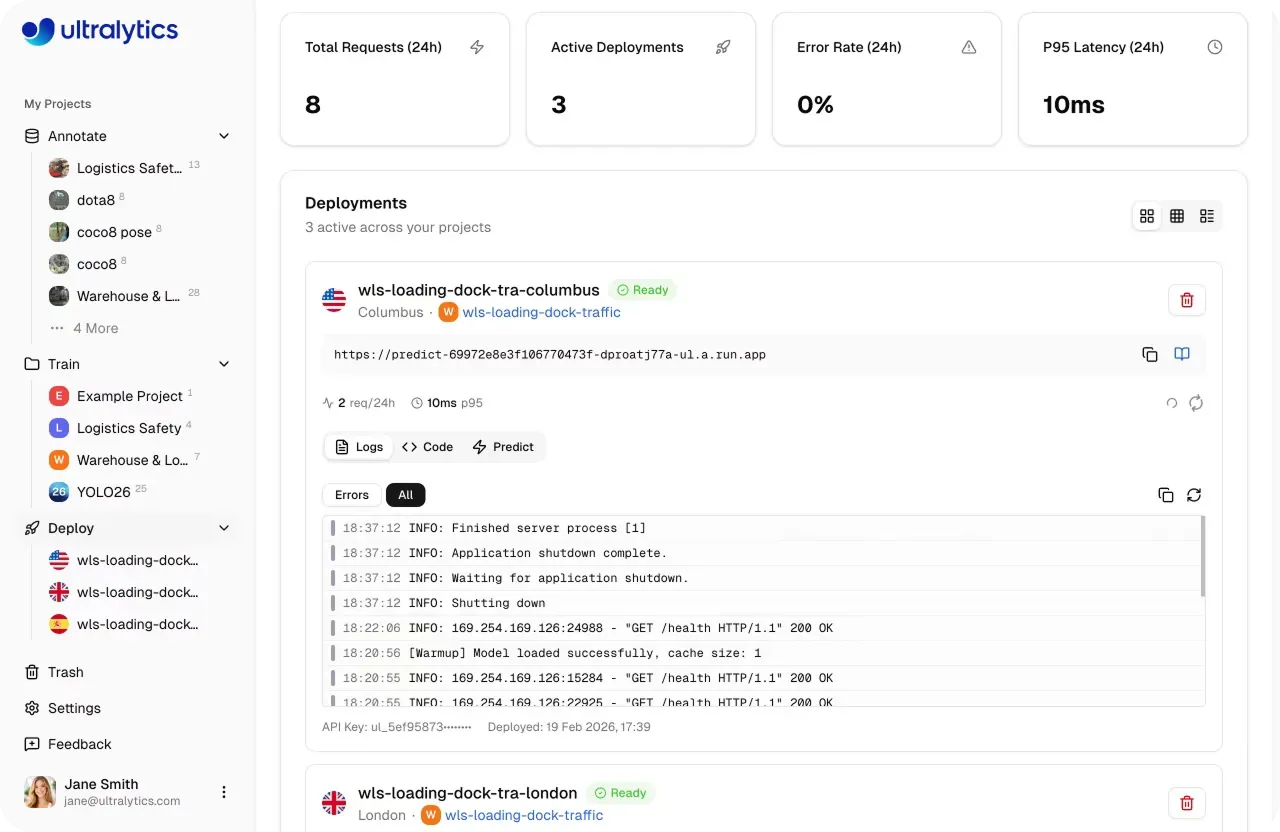
Fig 1. Un vistazo a la página de despliegue dentro de Ultralytics Platform (Fuente)
En este artículo, exploraremos cómo Ultralytics Platform redefine el despliegue de modelos de visión artificial, desde las pruebas y la integración hasta el despliegue en producción y la monitorización. ¡Empecemos!
Link to this sectionUna visión general del despliegue de modelos de visión artificial#
En el ciclo de vida del aprendizaje automático, el despliegue del modelo es la etapa en la que un modelo pasa de la experimentación al uso en el mundo real. Para los modelos de visión artificial creados mediante aprendizaje profundo y redes neuronales convolucionales, esto generalmente significa hacerlos disponibles para procesar imágenes y vídeos en tiempo real.
Una vez desplegados, estos modelos reciben nuevos datos, que normalmente pasan por pasos de preprocesamiento como redimensionamiento, normalización o formateo. Los datos procesados se pasan entonces al modelo, que aplica los patrones aprendidos durante el entrenamiento para generar predicciones de alta precisión.
Dependiendo del caso de uso, esto puede incluir diferentes tareas de visión artificial. Por ejemplo, los modelos Ultralytics YOLO, como Ultralytics YOLO26, admiten una amplia gama de tareas de visión, que incluyen detección de objetos, clasificación de imágenes, segmentación de instancias, estimación de poses y detección de cajas delimitadoras orientadas (OBB).
Para que esto sea práctico en aplicaciones del mundo real, los modelos a menudo necesitan integrarse en sistemas que puedan gestionar tanto el preprocesamiento como la inferencia de manera eficiente. Aquí es donde la infraestructura de despliegue se vuelve esencial.
En entornos de producción, normalmente se accede a los modelos a través de REST APIs o sistemas de servicio de modelos. Estas interfaces permiten a las aplicaciones enviar datos y recibir predicciones de forma programática, facilitando la integración con aplicaciones externas, dispositivos IoT o sistemas robóticos que dependen de la comprensión visual en tiempo real.
Link to this sectionLimitaciones de las herramientas tradicionales de despliegue de visión artificial#
El despliegue de modelos de visión artificial puede parecer sencillo, pero hasta ahora ha sido muy diferente en la práctica. Considera una configuración común: los datos se capturan primero desde cámaras o sensores, se envían a un modelo para su inferencia y luego se devuelven a una aplicación como predicciones.
En realidad, cada uno de estos pasos suele ser gestionado por herramientas y servicios separados. Un sistema puede gestionar la captura de datos, otro gestiona el servicio de modelos, mientras que se utilizan herramientas adicionales para el escalado, la monitorización y el registro (logging). Mantener estos componentes conectados y funcionando de forma fiable puede volverse complejo rápidamente.
A medida que crece el uso, esta complejidad aumenta. Gestionar la infraestructura, manejar las dependencias y mantener un rendimiento constante en toda la cadena de extremo a extremo puede ralentizar el desarrollo y dificultar el despliegue de modelos de visión artificial en aplicaciones del mundo real.
Ultralytics Platform reúne estos componentes en un entorno único y unificado. Esto proporciona una forma más cohesionada de gestionar todo el flujo de trabajo de despliegue, al tiempo que admite rendimiento y fiabilidad a escala.
Link to this sectionOpciones de despliegue de modelos habilitadas por Ultralytics Platform#
Además de unificar el proceso de despliegue de modelos, Ultralytics Platform también aporta flexibilidad a la forma en que se despliegan y utilizan los modelos.
Para admitir diferentes etapas del despliegue de modelos de visión artificial, la plataforma ofrece cuatro opciones: pruebas basadas en navegador con inferencia instantánea, inferencia compartida a través de APIs para el desarrollo, puntos de enlace dedicados para despliegues de producción escalables en regiones globales y exportación de modelos para ejecutar modelos en infraestructura externa o dispositivos de borde (edge).
Echemos un vistazo más de cerca a cómo funciona cada una de estas opciones.
Link to this sectionValida modelos rápidamente usando la pestaña Predict#
Antes de pasar un modelo a producción, es importante entender cómo funciona con datos nuevos y desconocidos. Ultralytics Platform incluye una pestaña Predict integrada que te permite ejecutar inferencias directamente en el navegador sin ninguna configuración, infraestructura o dependencia.
La pestaña Predict hace que la validación del modelo sea rápida e interactiva. Puedes cargar imágenes, usar ejemplos precargados o capturar entradas con una cámara web, y la inferencia se ejecuta automáticamente tan pronto como se proporcionan los datos.
Los resultados aparecen al instante con superposiciones visuales, puntuaciones de confianza y salidas detalladas, dándote una visión clara de cómo se comporta el modelo.
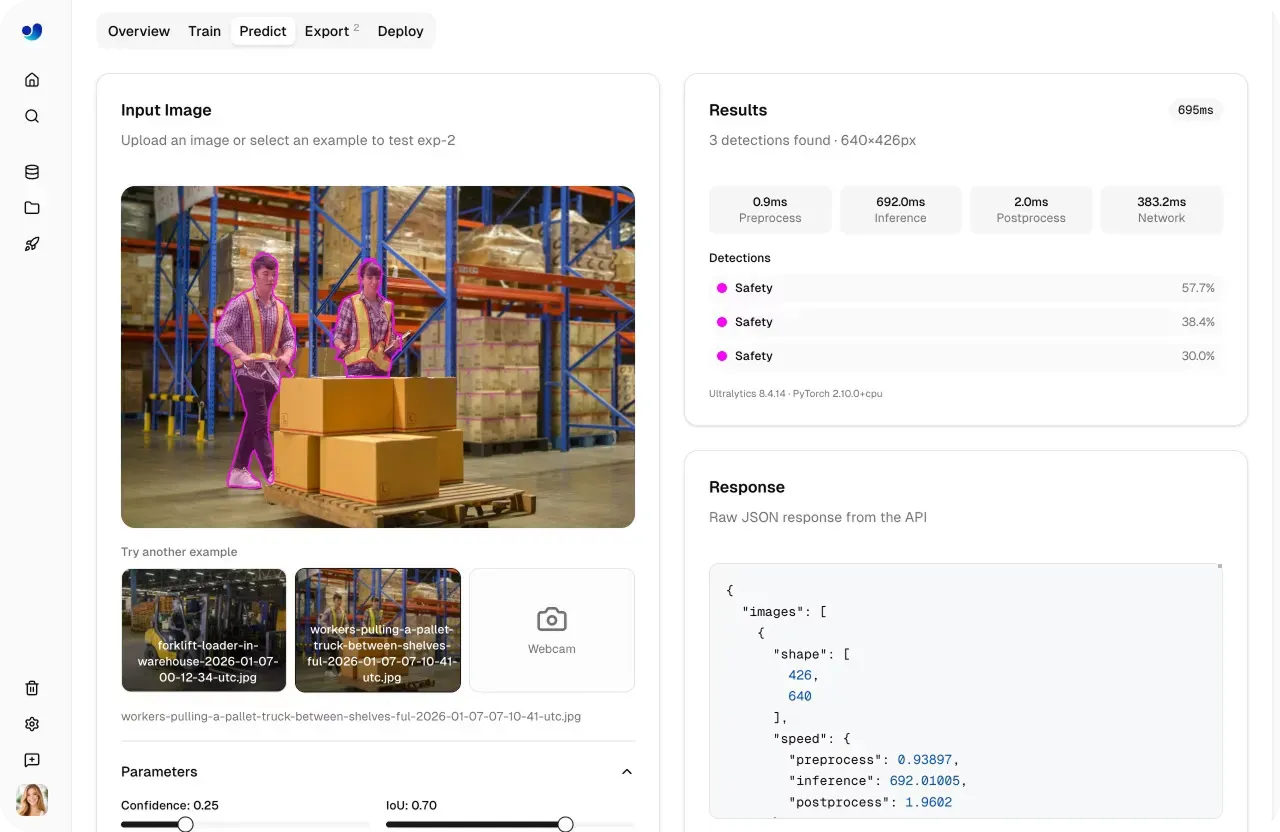
Fig 2. Un ejemplo de validación de un modelo usando la pestaña Predict (Fuente)
Esto significa que, con unos pocos clics, puedes probar diferentes entradas, ajustar parámetros y evaluar el rendimiento dentro de una única interfaz antes de pasar al despliegue.
Link to this sectionEjecución de inferencias compartidas para pruebas o uso ligero#
Digamos que has entrenado un modelo y lo has validado usando la pestaña Predict. El siguiente paso es a menudo empezar a integrar ese modelo en una aplicación o flujo de trabajo.
En lugar de configurar infraestructura o gestionar servidores, Ultralytics Platform proporciona servicios de inferencia compartidos que te permiten enviar datos a tu modelo y recibir predicciones a través de REST APIs sencillas.
Entre bastidores, la inferencia compartida se ejecuta en un sistema multiinquilino a través de unas pocas regiones centrales, donde las solicitudes se dirigen automáticamente al servicio disponible más cercano. Esto ayuda a mantener un rendimiento receptivo y, al mismo tiempo, permite a los usuarios en diferentes ubicaciones acceder a los modelos de forma coherente.
Puedes enviar entradas usando solicitudes HTTP estándar y recibir salidas estructuradas a cambio, lo que hace sencillo conectar modelos a aplicaciones, scripts o flujos de trabajo de automatización. Esta configuración es una excelente opción para el desarrollo, pruebas, integraciones o un uso más ligero antes de pasar a despliegues de producción más escalables.
Link to this sectionDespliega modelos globalmente a través de puntos de enlace dedicados#
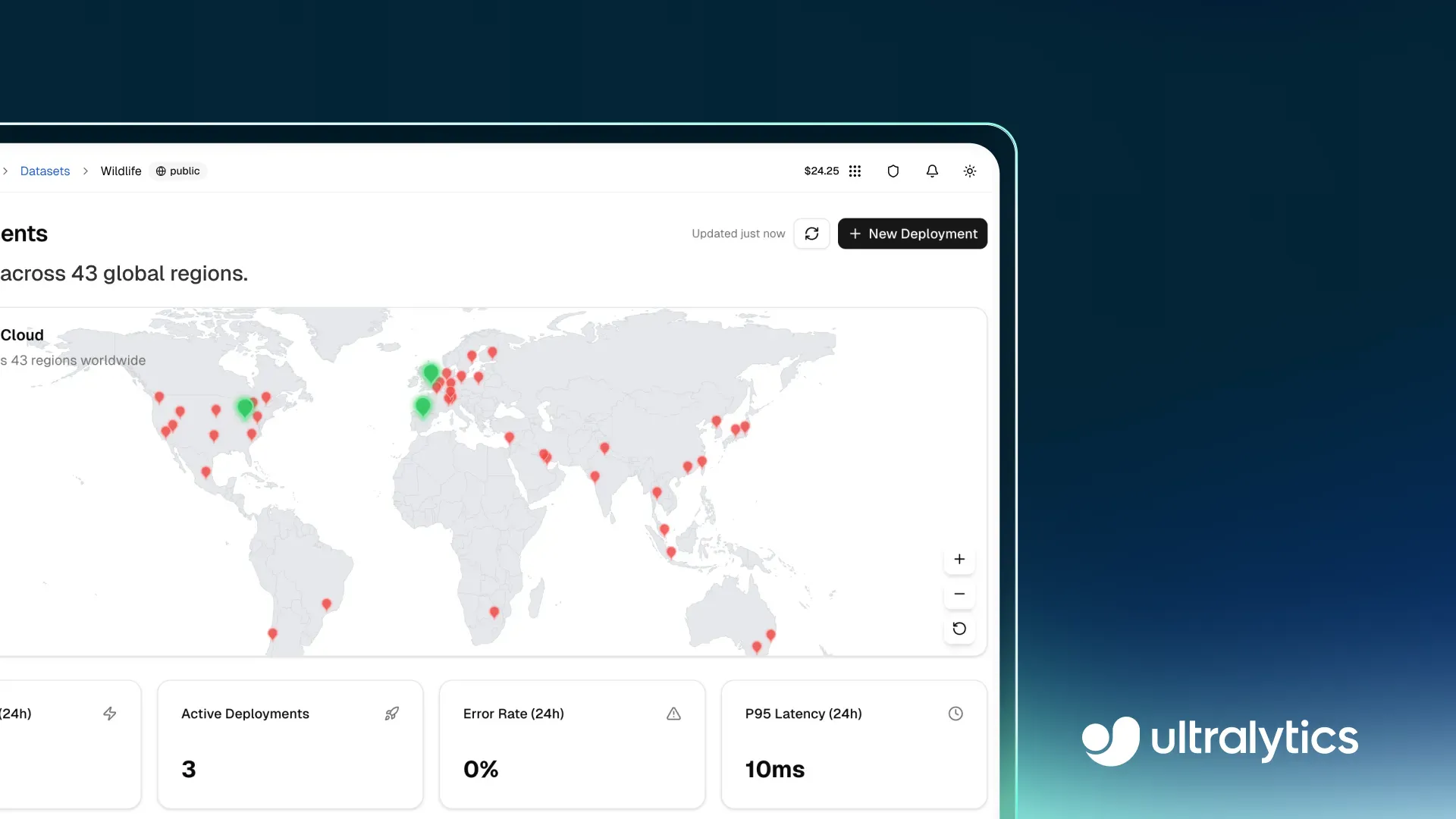
Una vez que un modelo está listo para producción, necesita manejar el tráfico del mundo real de forma fiable y a escala. Ultralytics Platform admite esto con puntos de enlace (endpoints) dedicados, donde los modelos se ejecutan como servicios de inquilino único en 43 regiones globales. Desplegar más cerca de los usuarios finales ayuda a reducir la latencia y a mantener un rendimiento constante en diferentes ubicaciones.
Cada punto de enlace se ejecuta con sus propios recursos de computación asignados y una URL única para las solicitudes de inferencia. Este nivel de control facilita ajustar los despliegues según las necesidades de rendimiento, desde casos de uso ligeros hasta aplicaciones más exigentes de alto rendimiento que requieren más recursos computacionales.
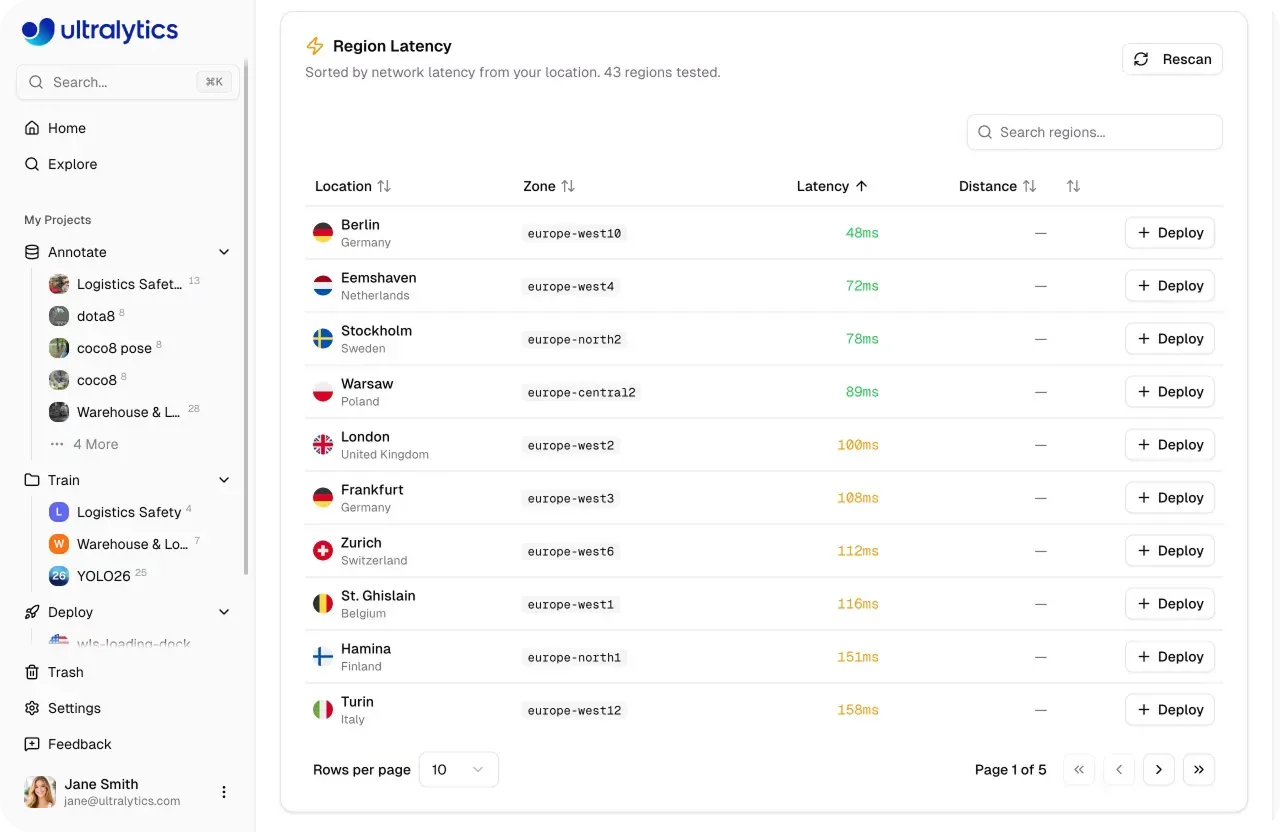
Fig 3. Puedes desplegar modelos en 43 regiones globales usando Ultralytics Platform (Fuente)
Sin embargo, los puntos de enlace dedicados están diseñados para gestionar las cargas de trabajo cambiantes por sí mismos, con un escalado automático que ajusta los recursos según el tráfico entrante. Escalan hacia arriba durante períodos de alta demanda y hacia abajo cuando el uso cae. Con el escalado a cero habilitado por defecto, los puntos de enlace inactivos se apagan automáticamente y se reinician cuando llegan nuevas solicitudes, ayudando a optimizar el uso de recursos sin intervención manual.
Link to this sectionExporta tu modelo fácilmente con Ultralytics Platform#
Hoy en día, la IA de borde es cada vez más esencial a medida que más aplicaciones dependen de ejecutar modelos directamente en dispositivos como teléfonos inteligentes, cámaras y sistemas integrados. Ejecutar modelos localmente también puede ayudar a abordar los requisitos de privacidad de datos, ya que los datos sensibles, como imágenes o secuencias de vídeo, pueden procesarse directamente en el dispositivo sin ser enviados a servidores externos.
En estos escenarios, los modelos necesitan ejecutarse fuera de Ultralytics Platform, lo que hace que la exportación de modelos sea una parte crucial del proceso de despliegue. Los modelos Ultralytics YOLO a menudo se entrenan usando Python y PyTorch, y luego pueden exportarse a más de 17 formatos diferentes, incluyendo ONNX, TensorRT, CoreML y OpenVINO.
Esta amplia gama de formatos garantiza la compatibilidad entre diversos hardware, desde unidades de procesamiento gráfico (GPUs) de alto rendimiento hasta dispositivos móviles e integrados. Además de esto, la exportación permite el ajuste del rendimiento para entornos específicos.
Dependiendo del formato, los modelos pueden alcanzar velocidades de inferencia más rápidas, como un mejor rendimiento de GPU con TensorRT o una ejecución de CPU optimizada con ONNX y OpenVINO. Opciones como la cuantización FP16 e INT8 pueden reducir aún más el tamaño del modelo y mejorar el rendimiento, lo cual es especialmente útil para despliegues de borde.
En Ultralytics Platform, la exportación está integrada directamente en el flujo de trabajo, lo que permite generar rápidamente modelos optimizados con solo unos clics. Los equipos pueden pasar del entrenamiento a la ejecución de modelos en sistemas externos sin añadir sobrecarga adicional.
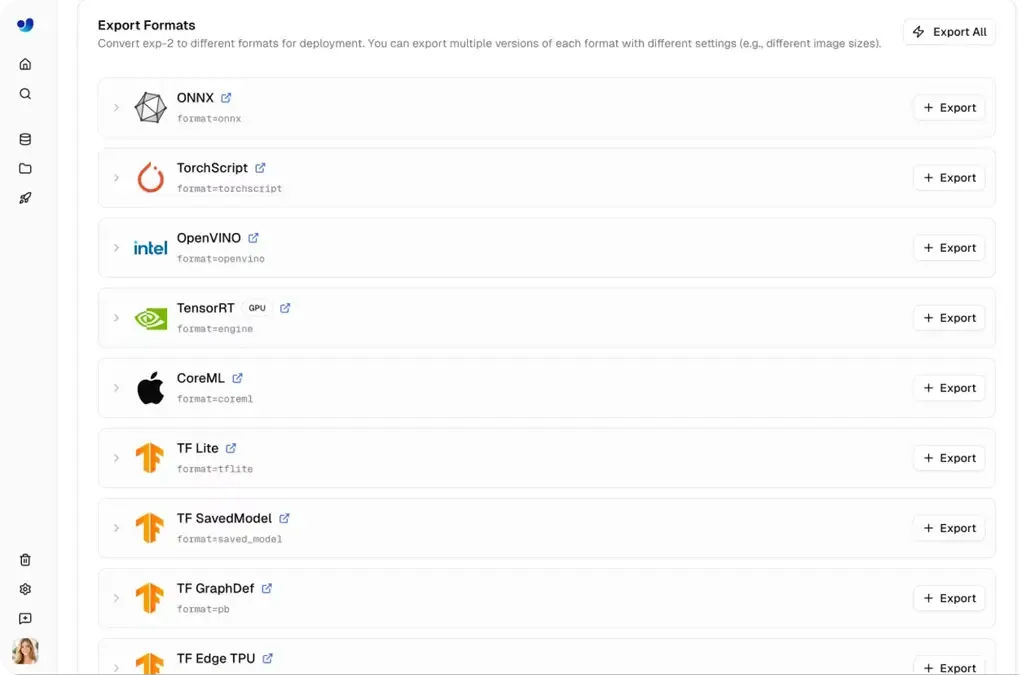
Fig 4. Una selección de formatos de exportación en Ultralytics Platform.
Link to this sectionElección de la opción de despliegue de modelo adecuada#
Cada opción de despliegue en Ultralytics Platform admite una etapa diferente del flujo de trabajo, desde las pruebas iniciales hasta el uso en producción. Aquí tienes una visión general de cuándo podrías usar cada una:
- Pestaña Predict: Se utiliza normalmente justo después del entrenamiento o ajuste fino, cuando quieres validar cómo funciona un modelo con datos nuevos usando inferencia basada en navegador.
- Inferencia compartida: En esta etapa, los modelos se pueden integrar en aplicaciones a través de APIs, lo que permite probar interacciones del mundo real durante el desarrollo.
- Puntos de enlace dedicados: Se utilizan para despliegues de producción, donde los modelos necesitan un rendimiento constante, recursos dedicados y la capacidad de escalar en regiones globales.
- Exportación de modelo: Cuando los modelos necesitan ejecutarse fuera de la plataforma, la opción de exportarlos permite el despliegue en dispositivos de borde, aplicaciones móviles o infraestructura personalizada.
Los equipos suelen avanzar por estas opciones paso a paso, pasando de la validación a la integración y finalmente al despliegue en producción, todo dentro de la plataforma.
Link to this sectionMonitorización de modelos desplegados a través de Ultralytics Platform#
Por muy importante que sea el despliegue, la cadena de visión no termina ahí. Una vez que un modelo está en producción, la monitorización continua es clave para asegurarse de que funcione de forma fiable a lo largo del tiempo.
Ultralytics Platform proporciona herramientas de monitorización integradas que ofrecen a los equipos una visibilidad clara de cómo se comportan sus modelos de visión por IA a lo largo del tiempo, lo que respalda un flujo de trabajo de operaciones de aprendizaje automático (MLOps) más estructurado.
La página Deploy incluye un panel que rastrea métricas clave como el total de solicitudes, despliegues activos, latencia de respuesta y tasas de error. Estos conocimientos ayudan a los equipos a entender los patrones de uso, evaluar la capacidad de respuesta del sistema y garantizar un rendimiento de baja latencia en diferentes cargas de trabajo.
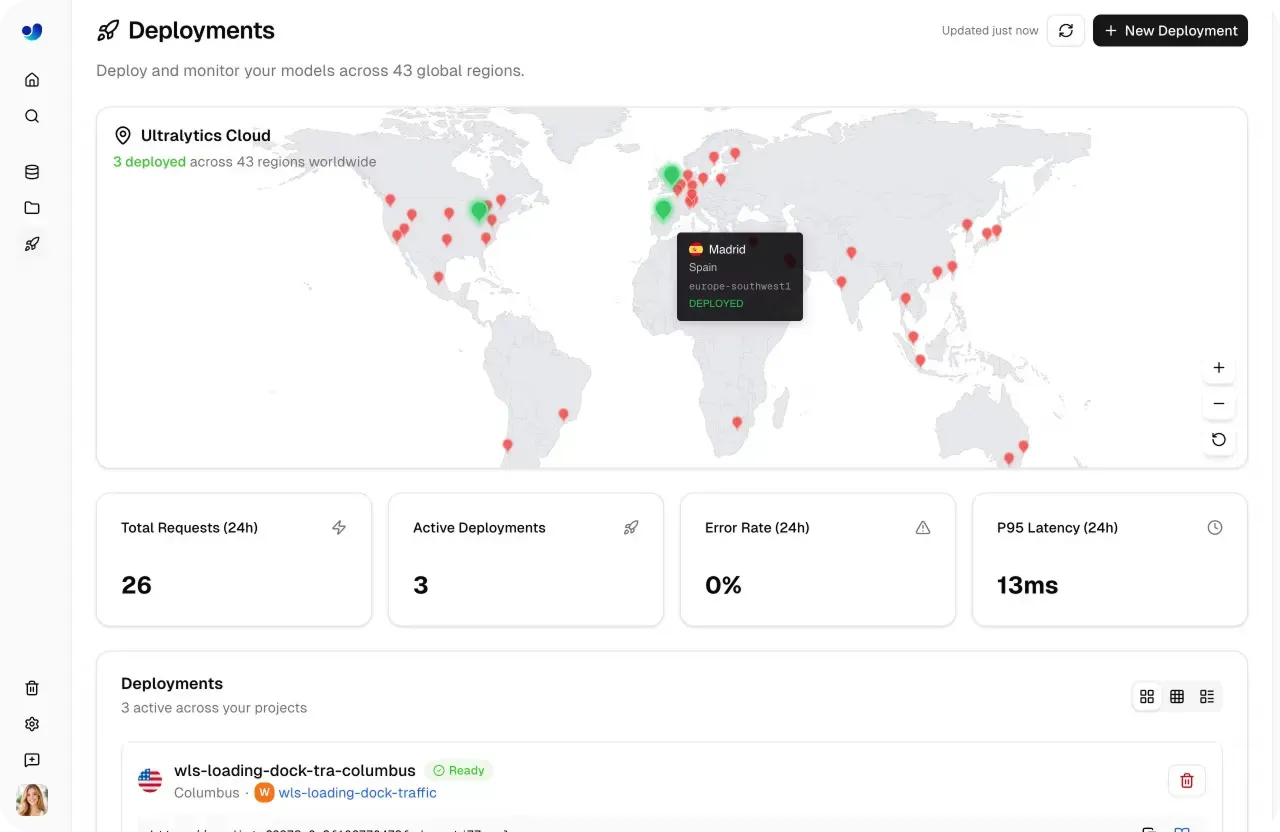
Fig 5. Ultralytics Platform facilita la monitorización de modelos desplegados. (Fuente)
Cada punto de enlace dedicado también proporciona una observabilidad detallada a través de vistas de despliegue individuales. Esto incluye acceso a registros (logs), estado de salud del modelo y datos de rendimiento en tiempo real. Los registros se pueden usar para depurar problemas, rastrear solicitudes fallidas e identificar posibles problemas relacionados con dependencias o infraestructura.
A medida que evolucionan los entornos de producción, factores como los cambios en los datos de entrada, las demandas de escalado o los patrones de uso cambiantes pueden afectar la precisión y robustez del modelo. Mediante la monitorización continua de las métricas de rendimiento, los equipos pueden detectar anomalías, identificar cuellos de botella y tomar acciones correctivas como la optimización del modelo o ajustes de recursos para mantener un servicio de modelo constante y fiable.
Link to this sectionIntegración de la escalabilidad en los despliegues de modelos de visión artificial#
Escalar sistemas de visión artificial ha significado tradicionalmente unir flujos de trabajo y marcos de trabajo que nunca fueron diseñados para funcionar como uno solo. Las cadenas de datos, los bucles de entrenamiento, la infraestructura de despliegue y los sistemas de monitorización a menudo residen en lugares separados, creando fricción en cada etapa.
El verdadero desafío no es solo construir modelos, sino mantenerlos en movimiento. Pasar de los datos a la producción, adaptarse a nuevas entradas, manejar la demanda creciente y mejorar continuamente sin ralentizarse.
Lo que destaca de Ultralytics Platform es que este movimiento está integrado. En lugar de tratar cada etapa como un paso separado, las conecta en un bucle continuo donde los modelos se pueden desarrollar, desplegar, observar y actualizar dentro del mismo entorno.
Ese cambio transforma la forma en que los equipos escalan. Ya no se trata de la orquestación de herramientas o infraestructura, sino de mantener el impulso a medida que los sistemas crecen.
Link to this sectionConclusiones clave#
Llevar modelos de aprendizaje automático, como los modelos de visión artificial, a aplicaciones del mundo real requiere que sean fiables, escalables y fáciles de gestionar. Ultralytics Platform simplifica este proceso combinando varias funciones, como el servicio de modelos, el despliegue y la monitorización, en un único entorno unificado. Con opciones de despliegue flexibles y herramientas integradas, los equipos pueden pasar de la experimentación a la producción más rápidamente y con menos complejidad.
Echa un vistazo a nuestra comunidad y explora nuestro repositorio de GitHub para aprender más. Explora nuestras páginas de soluciones para ver diversas aplicaciones como IA en el sector sanitario y visión artificial en logística. ¡Descubre nuestras opciones de licencia y empieza a construir hoy mismo!






