Entraîne des modèles YOLO plus rapidement avec la plateforme Ultralytics
Découvre comment entraîner des modèles YOLO plus rapidement avec la plateforme Ultralytics, un environnement de bout en bout conçu pour accélérer le chemin des données au déploiement.
La semaine dernière, Ultralytics a lancé Ultralytics Platform, un espace de travail unifié conçu pour simplifier la façon dont les équipes créent, entraînent et déploient des modèles de vision par ordinateur. Au lieu de jongler avec plusieurs outils, la plateforme rassemble tout au même endroit. Passer de l'idée au déploiement avec des modèles de vision par IA devient simple.
Ceci est crucial car la vision par ordinateur devient rapidement un élément central de diverses industries. Elle alimente des applications comme l'inspection dans la fabrication, l'analyse commerciale et la navigation autonome.
Transformer ces applications activées par la vision en systèmes fiables dépend de la qualité de l'entraînement des modèles. L'entraînement d'un modèle implique l'apprentissage à partir de données étiquetées afin que le modèle puisse reconnaître des modèles et faire des prédictions précises. En général, des modèles bien entraînés mènent à une meilleure performance et à des résultats plus fiables dans les applications du monde réel.
Cependant, entraîner un modèle de vision par ordinateur n'est pas toujours simple. Cela consiste en divers aspects, tels que la configuration des environnements, la sélection des ressources de calcul appropriées, le réglage des hyperparamètres et le suivi de multiples expériences d'entraînement. Lorsque ces étapes sont réparties sur différents outils et systèmes, le flux de travail d'entraînement devient rapidement complexe et difficile à gérer.
Ultralytics Platform résout ce problème en intégrant tout le processus d'entraînement dans un tableau de bord unique et unifié. Tu peux configurer, exécuter et surveiller des tâches d'entraînement au même endroit, que tu travailles dans le cloud, localement ou sur Google Colab.
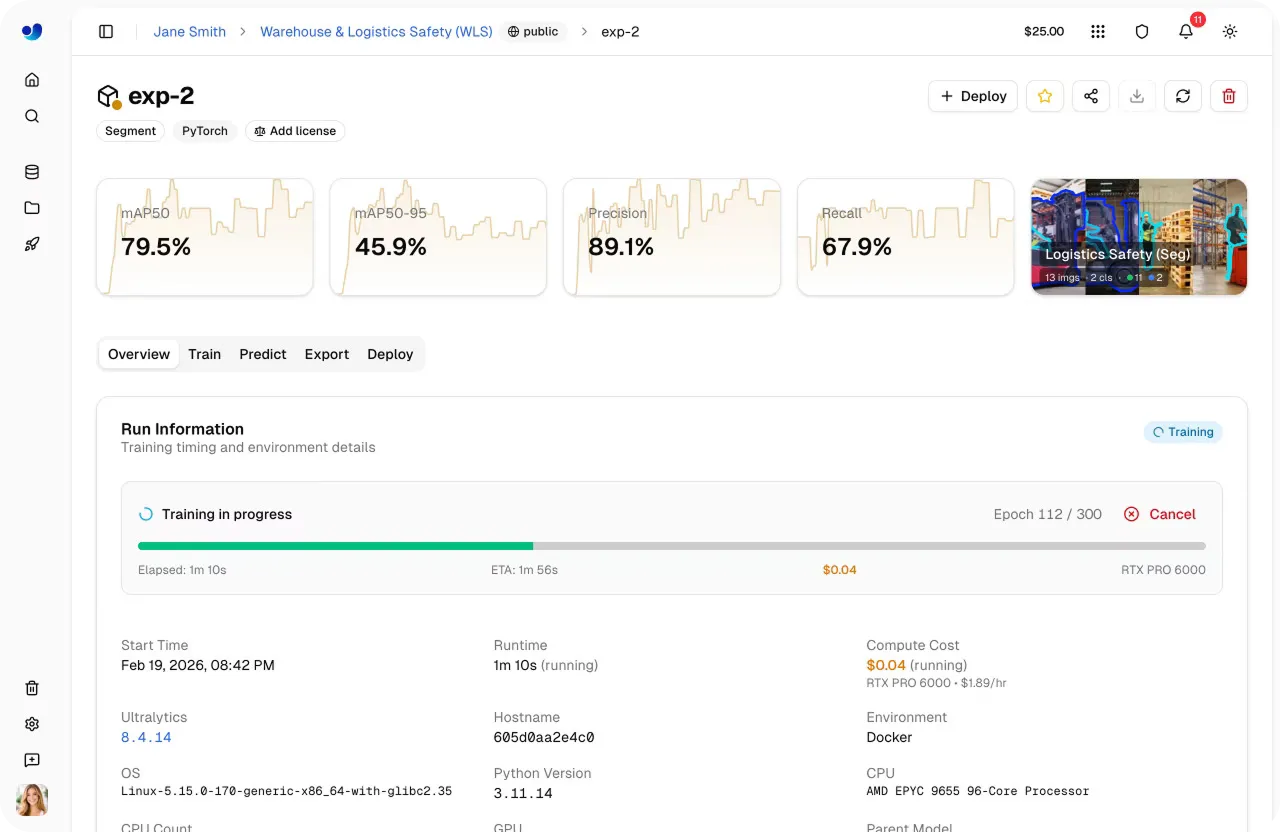
Fig 1. Un aperçu de l'entraînement de modèle au sein d'Ultralytics Platform (Source)
Dans cet article, nous explorerons comment Ultralytics Platform rationalise l'entraînement de modèle et pourquoi cela peut te donner un avantage dans tes projets de vision par IA. Commençons !
Link to this sectionLes modèles de vision par ordinateur apprennent à partir des données grâce à l'entraînement de modèles#
Avant de plonger dans le fonctionnement de l'entraînement de modèles sur Ultralytics Platform, prenons d'abord du recul et parcourons ce qu'est l'entraînement de modèle et ce qu'il implique.
L'entraînement de modèle est le processus par lequel un modèle de vision par ordinateur apprend à interpréter des données visuelles. Il analyse des images ou des vidéos et ajuste progressivement ses paramètres internes pour effectuer des tâches de vision comme la détection d'objets, la classification d'images et la segmentation d'instances avec précision. Au fil du temps, le modèle s'améliore en apprenant des modèles directement à partir des données qu'il voit.
La qualité de l'entraînement dépend fortement des jeux de données. Tu peux concevoir un jeu de données comme une série de cartes mémo qu'un professeur utiliserait pour former un étudiant, où chaque exemple aide le modèle à apprendre ce qu'il doit rechercher.
Un jeu de données typique de vision par ordinateur inclut des images, généralement dans des formats comme JPG ou PNG, et des annotations qui décrivent ce qui se trouve dans chaque image. Ces annotations, souvent stockées sous forme de fichiers JSON ou TXT, fournissent les étiquettes et le contexte dont le modèle a besoin pour apprendre efficacement.
Mais l'entraînement ne consiste pas seulement à alimenter un modèle avec des données. Cela implique plusieurs étapes clés, de la préparation du jeu de données à la sélection du bon modèle et à la configuration du processus d'entraînement. Ensuite, examinons de plus près quelques-unes de ces étapes.
Link to this sectionUn aperçu de la façon dont les jeux de données sont préparés#
Il peut sembler qu'une fois que tu as un jeu de données, tu peux immédiatement commencer à entraîner un modèle, mais il y a quelques étapes que tu dois suivre d'abord, comme le découpage du jeu de données.
Généralement, un jeu de données est divisé en trois parties : jeu d'entraînement, jeu de validation et jeu de test. Les images d'entraînement sont utilisées pour enseigner au modèle les modèles dans les données, tandis que le jeu de validation aide à surveiller et à ajuster les performances pendant l'entraînement.
Le jeu de test est utilisé à la fin pour évaluer les performances du modèle sur des données totalement nouvelles et invisibles. Cette configuration aide à garantir que le modèle ne se contente pas de mémoriser les données, mais peut se généraliser à des scénarios réels.
Link to this sectionSélection du bon modèle pour l'entraînement#
Une autre étape importante avant l'entraînement est de choisir le modèle que tu souhaites utiliser. Dans de nombreux cas, cela signifie sélectionner un modèle pré-entraîné. Des modèles comme les modèles Ultralytics YOLO sont déjà entraînés sur de grands jeux de données et ont appris des modèles visuels généraux, ce qui en fait un excellent point de départ.
L'utilisation de ces modèles est un exemple d'apprentissage par transfert, où tu construis sur des connaissances existantes et adaptes le modèle à ta tâche spécifique. Cette approche aide à accélérer l'entraînement et à améliorer les résultats, surtout lorsque tu travailles avec des données limitées.
Ces modèles existent également en différentes tailles, chacun offrant un compromis entre vitesse et précision. Les modèles plus petits sont plus rapides et plus efficaces, tandis que les modèles plus grands ont tendance à offrir une meilleure précision mais nécessitent plus de calcul.
Link to this sectionConfiguration des paramètres d'entraînement pour les modèles de vision#
Après avoir préparé ton jeu de données et sélectionné un modèle, l'étape suivante consiste à configurer la façon dont le modèle apprend.
Un modèle de vision par ordinateur est entraîné en utilisant un ensemble de paramètres qui déterminent comment il traite les données, met à jour ses poids et s'améliore au fil du temps. Ces réglages impactent directement à la fois la vitesse d'entraînement et la précision finale, ce qui les rend essentiels pour obtenir des résultats solides.
Voici quelques-uns des paramètres d'entraînement les plus couramment utilisés :
- Epochs : Cela représente le nombre de fois que le modèle parcourt l'ensemble du jeu de données pendant l'entraînement. Augmenter le nombre d'époques donne au modèle plus d'opportunités d'apprendre des modèles à partir des données.
- Batch size : C'est le nombre d'images traitées ensemble lors d'une seule étape d'entraînement. Des tailles de lots plus grandes peuvent accélérer l'entraînement mais nécessitent plus de mémoire.
- Image size : Cela spécifie la résolution des images d'entrée utilisées pendant l'entraînement. Des résolutions plus élevées peuvent améliorer la précision de la détection mais augmentent le coût computationnel.
- Learning rate : C'est le taux auquel le modèle met à jour ses paramètres internes pendant l'entraînement. Des valeurs trop élevées ou trop basses peuvent rendre l'entraînement instable.
- Optimizer : C'est l'algorithme responsable de la mise à jour des paramètres du modèle en fonction de l'erreur calculée lors de chaque itération d'entraînement.
Dans les flux de travail basés sur Ultralytics YOLO, ces configurations sont généralement définies dans un fichier YAML. Ce fichier spécifie les chemins des jeux de données, les noms des classes et la façon dont les données sont divisées. Il agit comme une configuration centrale qui indique au modèle comment interpréter le jeu de données.
Link to this sectionDes flux de travail fragmentés vers une expérience unifiée avec Ultralytics Platform#
Nous venons de discuter de certaines des étapes clés impliquées dans l'entraînement d'un modèle de vision par ordinateur, de la préparation des jeux de données à la sélection d'un modèle et à la configuration des paramètres d'entraînement. En pratique, le processus va souvent plus loin, incluant le suivi des expériences, la comparaison de multiples exécutions d'entraînement et l'amélioration continue des modèles au fil du temps.
Ces étapes sont rarement gérées au même endroit. Les jeux de données peuvent être préparés dans un outil, les exécutions d'entraînement effectuées dans un autre environnement, et le suivi des expériences géré séparément. À mesure que les projets grandissent, cette fragmentation ajoute de la complexité, ralentit l'itération et rend plus difficile l'organisation de l'ensemble.
Ultralytics Platform supprime cette complexité en intégrant tout le flux de travail d'entraînement dans un seul environnement. Au lieu de basculer entre les outils, tu peux gérer les jeux de données, configurer l'entraînement, exécuter des expériences et surveiller les résultats, tout au même endroit.
Ensuite, plongeons dans la façon dont Ultralytics Platform rend l'entraînement de modèles plus intelligent.
Link to this sectionOptions d'entraînement prises en charge par Ultralytics Platform#
Dans les applications réelles, entraîner un modèle de vision par ordinateur nécessite souvent des environnements flexibles. Selon la taille de ton jeu de données, la complexité du modèle et le matériel disponible, tu peux choisir d'exécuter l'entraînement dans le cloud, sur une machine locale ou via des environnements de notebook externes.
Ultralytics Platform prend en charge les options d'entraînement suivantes pour répondre à ces besoins :
- Cloud training : L'entraînement s'exécute sur des unités de traitement graphique (GPU) dans le cloud gérées par Ultralytics. Cette option est idéale pour les jeux de données plus grands ou les modèles plus complexes qui nécessitent des ressources computationnelles importantes.
- Local training : Cette option utilise le matériel disponible sur ta machine et est idéale pour les expériences rapides, le test de configurations ou le travail avec des jeux de données plus petits. Pour des charges de travail plus évolutives, l'entraînement peut également être effectué dans ton propre environnement cloud, tel qu'AWS ou GCP.
- Google Colab : Avec Ultralytics Platform, tu peux exécuter l'entraînement dans l'environnement de notebook hébergé de Google Colab, permettant un flux de travail flexible basé sur le navigateur sans configurer une machine locale.
Link to this sectionExplorer l'entraînement cloud sur Ultralytics Platform#
En ce qui concerne les projets de vision par ordinateur, entraîner des modèles localement ou via des environnements de notebook n'est pas toujours facile.
Par exemple, avec l'entraînement local, les performances dépendent entièrement de ton matériel, ce qui peut limiter la puissance de calcul et ralentir l'expérimentation. Les GPU sont essentiels pour un entraînement efficace, mais chaque configuration n'a pas forcément un accès fiable à ceux-ci.
Bien que les environnements de notebook comme Google Colab offrent une alternative en fournissant des GPU dans le cloud, les sessions sont souvent temporaires et peuvent interrompre les exécutions d'entraînement plus longues. À mesure que les jeux de données grandissent et que les flux de travail deviennent plus complexes, ces limitations peuvent rapidement devenir des goulots d'étranglement, rendant l'entraînement plus lent et moins fiable.
Ultralytics Platform résout cela avec son option d'entraînement cloud. Elle fournit un environnement prêt à l'emploi où les dépendances Python et les frameworks comme PyTorch sont pré-configurés, te permettant de commencer l'entraînement sans configuration supplémentaire.
Depuis un tableau de bord unique, tu peux lancer des tâches d'entraînement et surveiller la progression en temps réel. Cela facilite la concentration sur l'amélioration de tes modèles au lieu de la gestion de l'infrastructure.
Maintenant, voyons comment commencer avec l'entraînement cloud sur Ultralytics Platform.
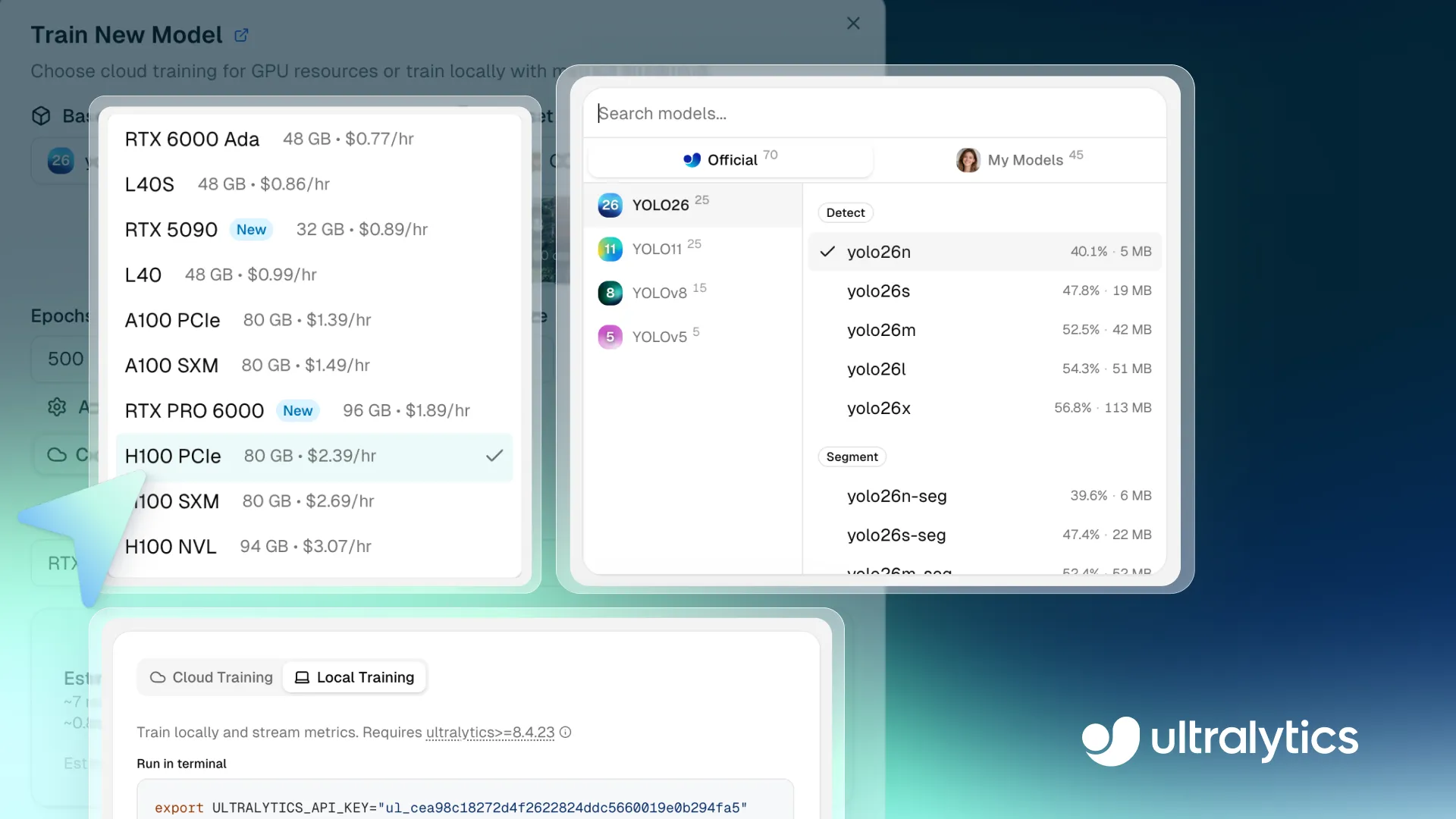
Link to this sectionÉtape 1 : Sélectionne un modèle de base#
La première étape consiste à choisir un modèle de base pour ton exécution d'entraînement. Tu peux sélectionner un modèle Ultralytics YOLO pré-entraîné, cloner un modèle communautaire ou télécharger tes propres poids pré-entraînés pour répondre à des exigences personnalisées.
La plateforme prend en charge tous les modèles Ultralytics YOLO, y compris Ultralytics YOLO26, Ultralytics YOLO11, Ultralytics YOLOv8, et Ultralytics YOLOv5, chacun disponible en différentes variantes de taille telles que nano (n), small (s), medium (m), large (l), et extra-large (x). Avec différentes variantes de modèles offrant un compromis entre vitesse et précision, tu peux choisir un modèle qui correspond à tes exigences de performance et de calcul.
Ces modèles prennent en charge une gamme de tâches de vision par ordinateur que les utilisateurs d'Ultralytics YOLO connaissent déjà, y compris la détection d'objets, la segmentation d'instances, la classification d'images, la détection de boîtes englobantes orientées (OBB) et l'estimation de pose.
Si tu as des exigences personnalisées, tu peux également télécharger tes propres poids de modèle pré-entraînés. Cela signifie que tu peux continuer l'entraînement ou affiner un modèle existant comme un détecteur d'objets au sein de la plateforme, plutôt que de repartir de zéro. C'est particulièrement utile si tu as déjà entraîné un modèle ailleurs ou si tu souhaites adapter un modèle à un cas d'utilisation plus spécifique.
Link to this sectionÉtape 2 : Sélectionne un jeu de données#
L'étape suivante consiste à sélectionner un jeu de données pour l'entraînement. Sur Ultralytics Platform, tu peux utiliser des jeux de données préexistants comme le jeu de données COCO, cloner des jeux de données de la communauté ou télécharger ton propre jeu de données personnalisé adapté à ton application spécifique.
La plateforme prend en charge les formats d'annotation courants tels qu'Ultralytics YOLO et COCO, et peut également gérer les téléchargements d'images brutes si tu prévois d'annoter des données personnalisées directement sur la plateforme.
Une fois téléchargés, les jeux de données sont automatiquement traités, incluant la validation, la normalisation, l'analyse des étiquettes et la génération de statistiques. Cela te donne une visibilité immédiate sur tes données, y compris les distributions de classes et la structure du jeu de données, et aide à garantir que tout est prêt pour l'entraînement.
Les jeux de données sont également automatiquement liés aux exécutions d'entraînement, te permettant de suivre quelles données ont été utilisées pour chaque modèle et de maintenir la cohérence entre les expériences.
Link to this sectionÉtape 3 : Configure les paramètres d'entraînement#
Après avoir choisi le jeu de données, tu peux configurer les paramètres d'entraînement qui contrôlent la façon dont le modèle apprend. Ceux-ci incluent les époques, la taille du lot, la taille de l'image et le nom de l'exécution pour le journal d'entraînement. Beaucoup de ces paramètres influencent à la fois la durée de l'entraînement et la performance finale du modèle.
Pour un entraînement plus contrôlé, la plateforme te permet également d'ajuster des paramètres avancés tels que le taux d'apprentissage, le type d'optimiseur, les paramètres d'augmentation de couleur et d'autres options d'entraînement. Ces réglages peuvent affiner le processus d'entraînement pour améliorer la précision et la stabilité du modèle.
Link to this sectionÉtape 4 : Sélectionne un GPU#
Ensuite, tu peux sélectionner la configuration GPU pour ton exécution d'entraînement. Choisir le bon GPU dépend de facteurs tels que la taille du jeu de données, la taille du lot, la résolution de l'image et la complexité du modèle. Trouver le bon équilibre aide à maintenir un entraînement efficace sans utiliser plus de calcul que nécessaire.
Ultralytics Platform propose 22 options de GPU avec différents niveaux de VRAM (mémoire sur un GPU) et de puissance de calcul, prenant en charge tout, des petites tâches aux charges de travail à grande échelle.
En utilisant cela, tu peux faire correspondre le matériel à tes besoins spécifiques, que tu entraînes des modèles légers ou que tu travailles avec de grands jeux de données complexes. Pour en savoir plus, consulte la liste des GPU disponibles sur la page de documentation sur l'entraînement de la plateforme d'Ultralytics.
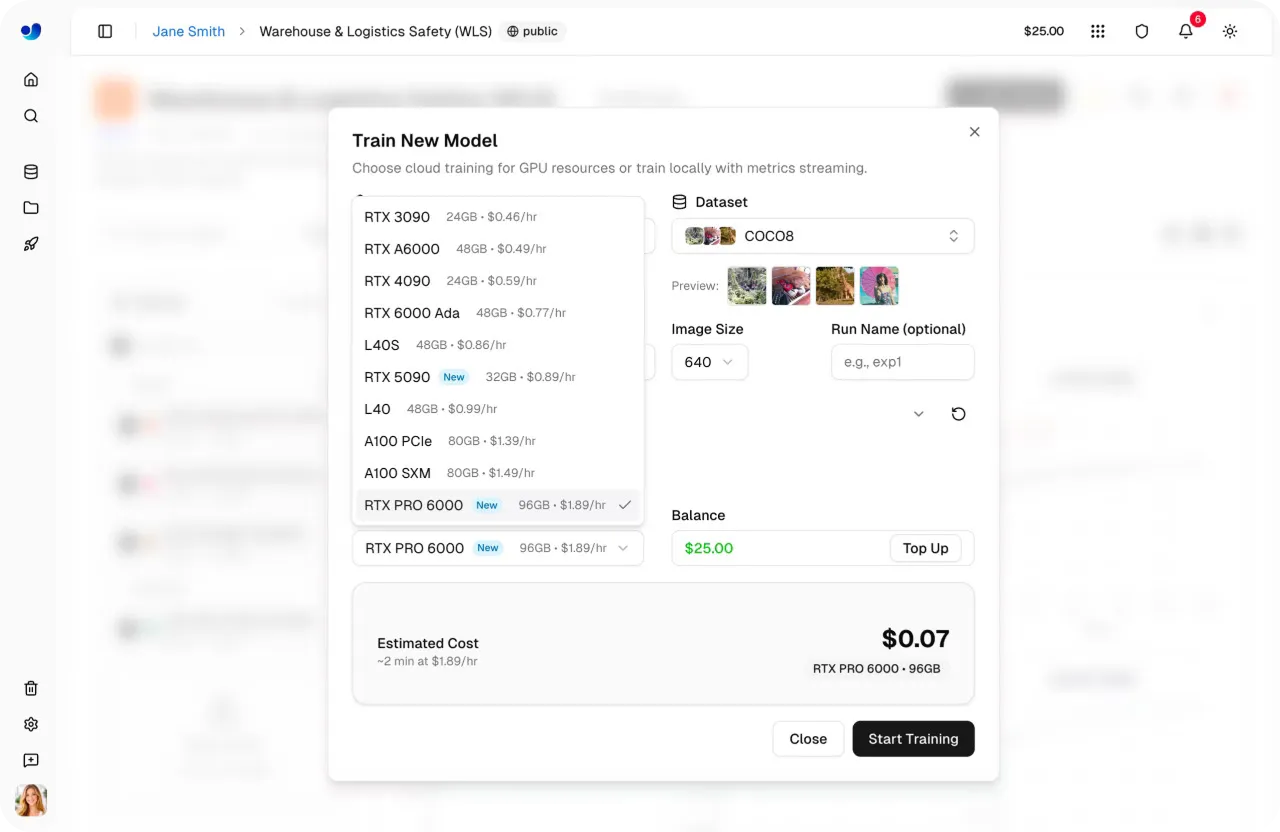
Fig 2. Certaines des options GPU activées via Ultralytics Platform (Source)
Link to this sectionÉtape 5 : Démarre l'entraînement cloud#
Une fois que tu as sélectionné le modèle, le jeu de données, les paramètres d'entraînement et l'option de calcul, démarrer une exécution d'entraînement est rapide. Depuis le tableau de bord, tu peux lancer l'entraînement en un seul clic, et la plateforme gère le reste en initialisant l'environnement et en exécutant la tâche sur le GPU sélectionné.
Dès que l'entraînement commence, tu peux surveiller la progression directement au sein de la plateforme. L'onglet Train offre une visibilité en temps réel sur les métriques clés, y compris les métriques de performance, les courbes de perte, l'utilisation du système et les journaux d'entraînement en direct.
Pour en savoir plus sur l'entraînement local ou l'utilisation de Google Colab avec Ultralytics Platform, tu peux explorer d'autres tutoriels au sein de la documentation officielle d'Ultralytics Platform.
Link to this sectionÉvaluation et comparaison de modèles sur Ultralytics Platform#
Une fois l'entraînement terminé, l'étape suivante consiste à évaluer les performances de ton modèle. Sur Ultralytics Platform, tu peux comparer plusieurs exécutions d'entraînement au sein d'un projet, te donnant une vision claire de la façon dont différentes expériences se comportent.
Lors du développement de modèles, l'entraînement est souvent répété plusieurs fois avec des paramètres différents, tels que la modification du taux d'apprentissage, de la taille du lot ou de la taille du modèle, pour améliorer les résultats. Chacune de ces exécutions produit un modèle légèrement différent, c'est pourquoi les comparer est vital.
Les projets agissent comme un centre névralgique où les modèles et les expériences sont organisés ensemble. Tu peux suivre les progrès, examiner les résultats et rester concentré sans basculer entre différents outils ou vues.
Depuis cette vue unifiée, tu peux également analyser des métriques de performance clés telles que la précision, le rappel et le mAP (précision moyenne) pour comprendre comment ton modèle se comporte à travers différentes classes. Tu peux aussi comparer des exécutions d'entraînement côte à côte pour identifier quelles configurations offrent les meilleurs résultats.
Pour compléter ces métriques, tu peux utiliser l'onglet Predict pour tester rapidement les modèles entraînés sur des images ou des données d'exemple, t'aidant à valider visuellement les performances et à repérer les problèmes potentiels.
Avec ces informations, tu peux sélectionner le modèle le plus performant, généralement enregistré sous forme de point de contrôle “best.pt”, et passer à l'étape suivante, qu'il s'agisse d'une évaluation approfondie, de l'utilisation du modèle pour exécuter l'inférence ou du déploiement du modèle via la plateforme.
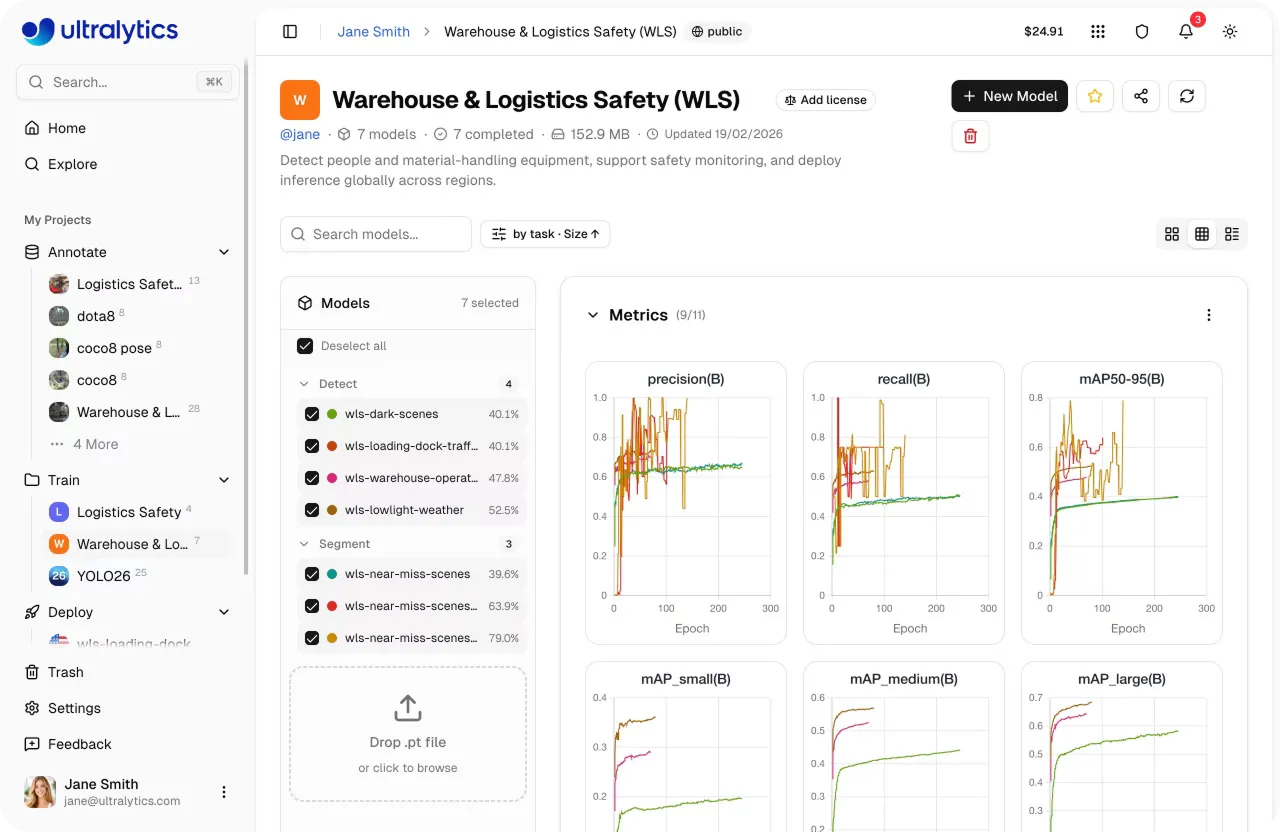
Fig 3. Un exemple de visualisation des métriques sur Ultralytics Platform (Source)
Link to this sectionEstimation du coût de l'entraînement au sein d'Ultralytics Platform#
L'entraînement de modèles de détection d'objets dans le cloud entraîne des coûts de calcul, surtout lorsque tu accèdes à des GPU haute performance. Pour rendre cela plus pratique, Ultralytics Platform fournit une estimation de coût avant que l'entraînement ne commence.
Cela te donne une visibilité claire sur l'utilisation attendue, t'aidant à planifier les charges de travail, à gérer les budgets et à éviter les dépenses imprévues avant de lancer une tâche d'entraînement. Voici comment tu peux vérifier les coûts estimés avant de commencer l'entraînement.
Link to this sectionComment le temps d'entraînement est estimé#
Pour estimer le coût avec précision, la plateforme calcule d'abord combien de temps prendra une seule époque d'entraînement. Cela dépend de facteurs comme la taille du jeu de données, la taille du modèle, la résolution de l'image, la taille du lot et la vitesse du GPU sélectionné.
En utilisant ces entrées, elle détermine le temps estimé par époque et l'extrapole à l'exécution complète de l'entraînement. La durée totale est calculée en combinant le temps sur toutes les époques avec une légère surcharge de démarrage.
La surcharge prend en compte des tâches telles que l'initialisation de l'environnement, le chargement des jeux de données et la préparation du GPU, garantissant que l'estimation reflète le processus d'entraînement complet, pas seulement la boucle d'entraînement.
Link to this sectionComment le coût de l'entraînement est calculé#
Une fois que la durée totale de l'entraînement est estimée, la plateforme la convertit en coût en utilisant le tarif horaire du GPU sélectionné.
En combinant la durée de l'entraînement avec la tarification du GPU, nous pouvons obtenir une estimation claire du coût de l'exécution avant même qu'elle ne commence.
Avoir une visibilité immédiate permet d'ajuster facilement ta configuration, comme le réglage des paramètres d'entraînement ou la sélection d'un GPU différent, afin que tu puisses équilibrer les performances et le coût plus efficacement.
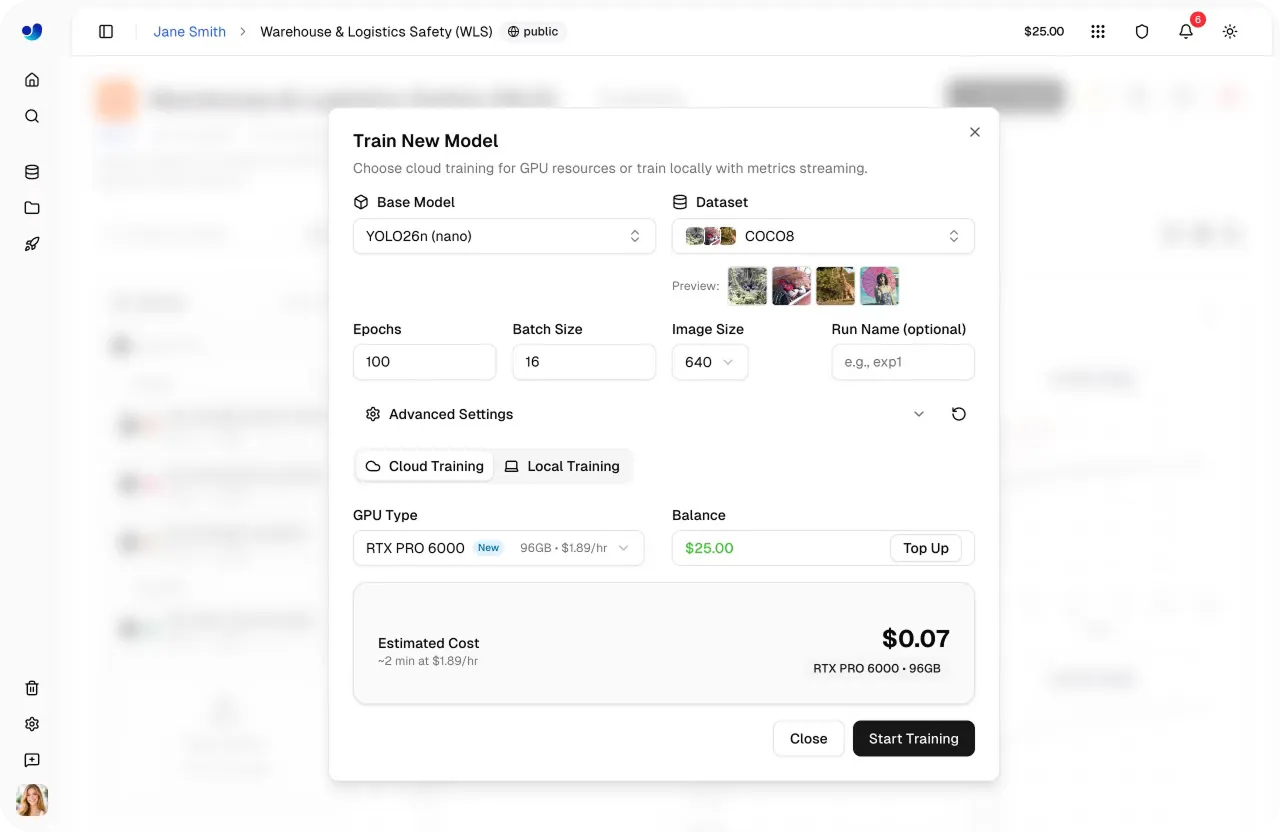
Fig 4. Configuration de l'entraînement de modèle et estimation du coût au sein d'Ultralytics Platform (Source)
Link to this sectionAvantages clés de l'utilisation d'Ultralytics Platform pour l'entraînement de modèles#
Jusqu'ici, nous avons parcouru les étapes clés impliquées dans l'entraînement de modèles de vision par ordinateur et comment elles s'assemblent sur Ultralytics Platform.
Au-delà de ces fonctionnalités principales, il existe des capacités supplémentaires qui améliorent le flux de travail d'entraînement. Voici un aperçu de certains des avantages clés de l'utilisation d'Ultralytics Platform pour l'entraînement de modèles :
- Reproductibilité des expériences intégrée : Chaque exécution d'entraînement est automatiquement enregistrée avec sa configuration complète, y compris le modèle, le jeu de données, les paramètres et la configuration de calcul. Cela rend simple la révision des expériences et la reproduction fiable des résultats.
- Aperçus de l'entraînement au fil du temps : Au lieu de simplement voir les résultats finaux, tu peux suivre l'évolution des performances au fil des époques, ce qui t'aide à mieux comprendre le comportement du modèle pendant l'entraînement.
- Réduction de la charge opérationnelle : En gérant la configuration de l'environnement, la gestion des dépendances et l'infrastructure en arrière-plan, la plateforme te permet de te concentrer davantage sur le développement du modèle et moins sur la configuration.
- Organisation centralisée des expériences : Les projets servent d'endroit unique pour gérer tes modèles, jeux de données et exécutions d'entraînement, aidant ainsi à maintenir tes expériences structurées à mesure que tes workflows deviennent plus complexes.
Link to this sectionPoints clés#
L'entraînement est l'une des étapes les plus importantes du cycle de vie d'un modèle de machine learning. Il détermine avec quelle précision un modèle peut reconnaître et interpréter des données visuelles.
En combinant la configuration des données d'entraînement, la surveillance, la comparaison des expériences et l'estimation des coûts dans un seul environnement, la plateforme Ultralytics simplifie le processus de création de modèles de vision par ordinateur performants et leur préparation pour le déploiement.
Découvre notre communauté grandissante et notre dépôt GitHub pour en savoir plus sur la vision par ordinateur. Si tu cherches à créer des solutions de vision, jette un œil à nos options de licence. Explore nos pages de solutions pour en savoir plus sur les avantages de la vision par ordinateur dans la fabrication et de l'IA dans l'agriculture.






